为什么使用服务器CPU运算Tensorflow、Pytorch代码会导致近百个逻辑核心的CPU使用率高达100%呢
2022年11月10日更新
本文所提问题与CPU的向量计算(simd)关系并不大,主要原因就是CPU多线程并行计算所导致的。不过CPU的SIMD导致CPU功耗大幅度上升并且导致CPU降频运行也确实会影响CPU的整体运行性能,但是本文所提问题主要在于服务器由于CPU核心多因此框架运行启动的线程数量也同样变多,所以导致CPU使用率较高。
===================================================
可能现在搞机器学习的人如果使用过服务器(Intel Xeon系列CPU)都会遇到过这样的一个问题,就是使用普通的家用电脑(Intel i7 之类的)跑Tensorflow 、Pytorch代码虽然只有8物理核心或者10物理核心的CPU来跑代码,其CPU使用率都不一定会达到100%,然而我们使用服务器(Xeon CPU)跑同样的代码,几十个物理核心的CPU其使用率立刻升高到100%,就这造成了十分要人迷惑的现象。
大致的总结以下这个现象就是:
同样的Tensorflow、PyTorch代码使用家用10核心左右的CPU其使用率为百分之几十,但是如果使用服务器(Xeon 系统)100核心左右的CPU其使用率不但没有降低反而升高甚至可能达到100%。
其实这个问题我一开始也没有想明白,按道理来说CPU资源更多了同样的代码跑起来其使用率应该会下降而不是上升,而这一下是大幅度上升甚至飙到了接近100%。后来分析了一下Tensorflow和Pytorch的代码的计算任务类别和CPU的指令集就发现原因所在了。
首先,我们需要知道 Tensorflow、Pytorch运行的代码一般都是矢量计算或是叫向量计算。
其次,我们需要知道 服务器CPU向量计算一般使用 avx-512 什么的,而家用CPU进行向量计算一般都是用AVX2指令集。换句话就是说家用电脑做向量计算性能较低,由于指令集不支持所以CPU使用率上不去,但是服务器cpu对向量计算支持较好,一旦用服务器CPU进行向量计算其性能会有大幅度提升,而且会充分利用CPU的资源,因此使用服务器CPU进行同样的向量计算其使用率不仅没有降低反而会有大幅度的提升,甚至会达到100%的可能利用率,当然伴随着服务器CPU使用率的高数值,整体的计算时间也会得到大幅缩短。
具体例子:linux , top命令后
CPU: xeon GOLD版本

上面的是服务器上运行的两个程序,都是pytorch的代码。
服务器90个核心,单cpu使用率为 4797,其整体CPU利用率为4797/9000约等于50%,单cpu使用率为 100,其整体CPU利用率为100/9000约等于1%。
其中,第一个程序跑的是一个三层的CNN网络,网络训练使用的是CPU,此时为使用CPU进行矢量计算。
第二个程序跑的是一个五层的CNN网络,网络训练使用的是GPU,此时为使用GPU进行矢量计算,CPU仅进行标量计算。
由此可以看到即使使用服务器CPU进行一个计算量不太大的向量计算就可以完全使用掉45个左右的逻辑CPU,而此时一个只进行标量计算的任务其CPU使用率最多消耗掉一个CPU核心。
再举一个例子:
代码:
import ctypes
import time
import multiprocessing
import numpy as np #NUM_PROCESS = multiprocessing.cpu_count()
NUM_PROCESS = 4 size = 1000000 def worker(index):
main_nparray = np.frombuffer(shared_array_base[index], dtype=ctypes.c_double)
for i in range(10000):
main_nparray[:] = index + i
return index if __name__ == "__main__":
shared_array_base = []
for _ in range(NUM_PROCESS):
shared_array_base.append(multiprocessing.Array("d", size, lock=False)) pool = multiprocessing.Pool(processes=NUM_PROCESS) a = time.time()
result = pool.map(worker, range(NUM_PROCESS))
b = time.time()
print(b-a)
#print(result) for i in range(NUM_PROCESS):
main_nparray = np.frombuffer(shared_array_base[i], dtype=ctypes.c_double)
print(main_nparray)
print(type(main_nparray))
print(main_nparray.shape)
代码为使用4个核心(4个进程)进行多进程向量计算。
使用家用i7 主频4.6Ghz的CPU,运行时间:
16.208305835723877 秒
使用服务器 Xeon 系列 2.3 Ghz的CPU ,运行时间:
4.703573226928711 秒
可以看到即使是服务器CPU主频为家用CPU的一半,而且都是使用相同物理核心的个数,最后服务器进行向量计算的时间不仅比家用CPU的快甚至还快了3倍速度左右。
看来使用服务器CPU进行向量计算即使主频低最终性能也完全碾压家用CPU,当然如果是进行标量计算的话这时就要看主频了,如果进行标量计算那么家用CPU将会比服务器CPU快不到一倍,因为此时看的主要是主频大小了。
=========================================
补充内容:
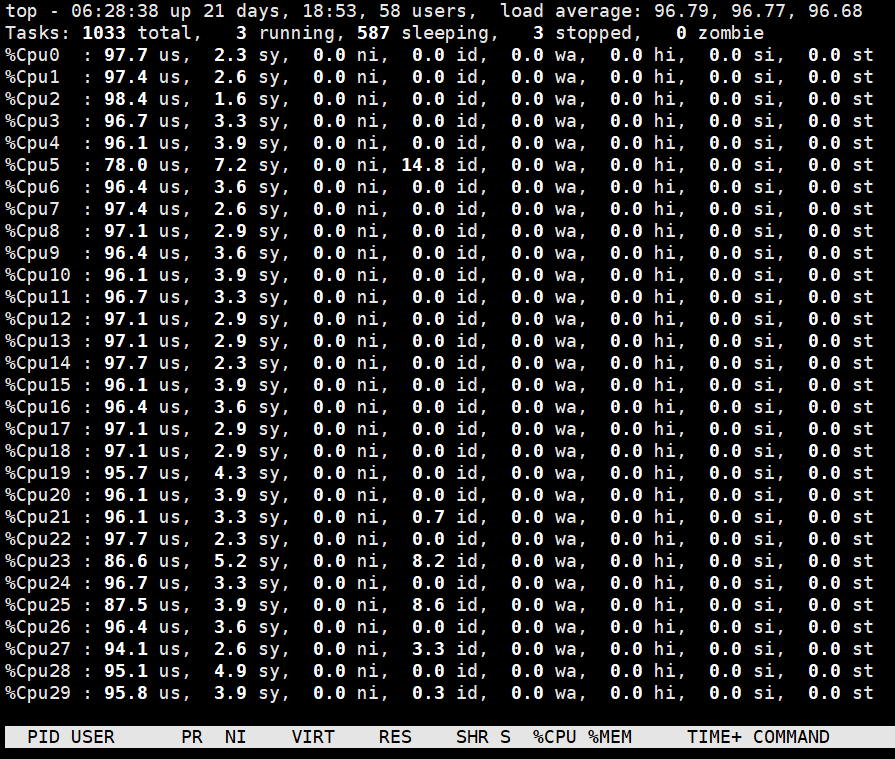
上面的分析只是一小部分,并且没有说到真正的核心问题,那就是Tensorflow和Pytorch都是用C++写的底层并且是单进程多线程的,可以在linux系统中使用top命令+1 来查看所有核心的使用情况。
使用
ps -T -p 进程号
我们可以查看某进程下的线程情况:
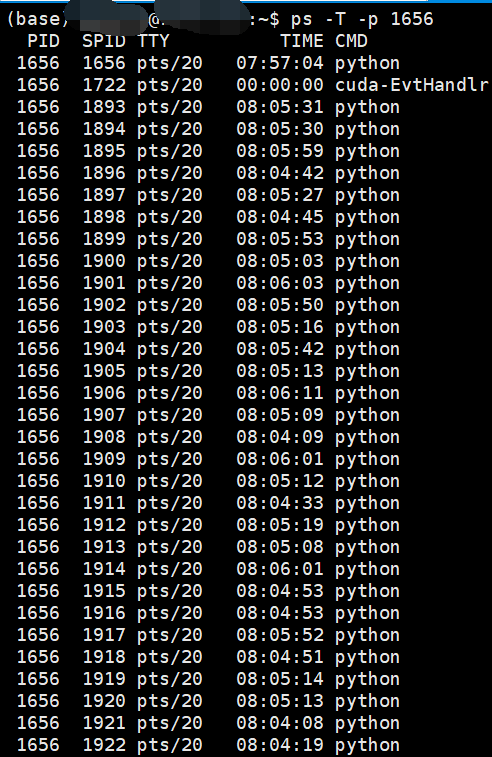
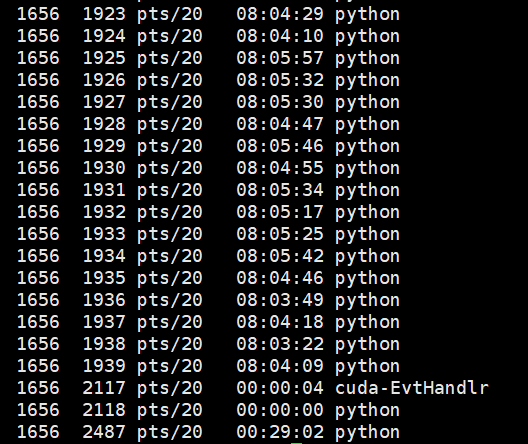
在linux中的top命令下使用H按键可以查看所有线程和进程的使用情况。

可以看到一个进程下的多个线程都已经到达了100%的使用率。
总结来说就是虽然服务器CPU由于更好的支持向量计算所以单核心的利用更加充分,但是最为重要的是这些进程本身就是多线程的,而这些线程基本每一个都是可以达到100%的利用率,这才是真正的最为关键的原因。
在linux系统下top命令默认只用进程来现实利用率,因此一个具有几十个线程的进程在top命令下也是默认只显示进程信息的,系统计算进程的利用率是要把所有线程的利用率都算在进程上的而系统默认又不显示线程信息,也正是由于有众多的线程的高负荷运行所以就有了单进程使用率大于100%的现象。
====================================================
(下面的文字需要添加说明,下面的向量计算是指单进程下多线程的SIMD,不是单进程单线程的SIMD,在Tensorflow和Pytorch中都是多线程的SIMD进行向量计算)
虽然使用服务器CPU进行向量计算可以大幅度提高计算效率,但是我们需要知道以下几个问题:
1. 使用服务器CPU(如果不是天河超算,太湖之光什么的,不是那种非一致内存访问的服务器架构,而仅仅是那种一个服务器主板上安装两个Xeon版本CPU的话),你所能利用的向量计算的CPU计算资源的上限比较低,换句话说就是你一个几十万的服务器你要是用CPU跑两个三层网络的CNN基本可以保证服务器使用率达到100%,此时服务器上如果用人用GPU进行计算,那GPU的使用率会从100%掉到5%以内,其原因就是CPU被占满没有计算资源给GPU计算做调度了。
也就是说如果你不是使用什么太湖之光,华为昇腾这种非一致内存访问的服务器架构,你只需要跑一些简单的向量计算代码整个服务器就不能做别的了,就像我现在负责管理的GPU计算服务器,经常需要看看有没有人一下子偷偷的把CPU全部吃掉,毕竟随便找个向量计算的代码就轻松把几十万的服务器CPU全部吃掉,此时你就是有16个泰坦GPU在计算都得歇菜,因为你CPU已经没有计算能力了。
当然,如果你是独占使用服务器,那另一说。
2. 由于像Xeon这种CPU的向量计算上限比较低,如果你是做机器学习中的感知学习,那么你用CPU计算并不会给你提升太多速度(假设你服务器上同时还有泰坦显卡的情况),这个时候完全可以用GPU计算,因为如果矢量计算量大过某一值后GPU的向量计算能力是要高于CPU的,毕竟GPU的向量计算核心都是几千上万个,Xeon的CPU再好毕竟向量计算核心也就百十个。
当然,如果你要是做决策学习的话,而且是那种在线的(online reinforcement learning), 那么使用CPU进行向量计算是要快于GPU的,因为此时向量计算的量正好是CPU快于GPU的时候(一般决策学习,reinforcement learning的向量计算不太大,一般三层CNN就差不多了),而且如果是online的,需要实时与CPU的仿真环境交互的话,那么使用CPU进行决策学习确实要比GPU快,当然这也是一直我想要解决的问题,就是如何使GPU进行决策学习的性能高于CPU呢?这是我的一个想解决的问题。但是即使使用CPU进行决策学习要快于GPU但是对服务器整体CPU使用率的大幅度占用还是很有可能影响其他人使用的,这也是我们需要注意的一个问题,比较第一个问题中我们也说明了使用CPU进行向量计算会大幅度占用CPU的整体计算资源。
=====================================================
为什么使用服务器CPU运算Tensorflow、Pytorch代码会导致近百个逻辑核心的CPU使用率高达100%呢的更多相关文章
- tensorflow/pytorch/mxnet的pip安装,非源代码编译,基于cuda10/cudnn7.4.1/ubuntu18.04.md
os安装 目前对tensorflow和cuda支持最好的是ubuntu的18.04 ,16.04这种lts,推荐使用18.04版本.非lts的版本一般不推荐. Windows倒是也能用来装深度GPU环 ...
- 数据库访问优化漏斗法则- 四、减少数据库服务器CPU运算
数据库访问优化漏斗法则这个优化法则归纳为5个层次:1.减少数据访问次数(减少磁盘访问)2.返回更少数据(减少网络传输或磁盘访问)3.减少交互次数(减少网络传输)4.减少服务器CPU开销(减少CPU及内 ...
- (转载)PyTorch代码规范最佳实践和样式指南
A PyTorch Tools, best practices & Styleguide 中文版:PyTorch代码规范最佳实践和样式指南 This is not an official st ...
- PyTorch代码调试利器: 自动print每行代码的Tensor信息
本文介绍一个用于 PyTorch 代码的实用工具 TorchSnooper.作者是TorchSnooper的作者,也是PyTorch开发者之一. GitHub 项目地址: https://github ...
- 如何将tensorflow1.x代码改写为pytorch代码(以图注意力网络(GAT)为例)
之前讲解了图注意力网络的官方tensorflow版的实现,由于自己更了解pytorch,所以打算将其改写为pytorch版本的. 对于图注意力网络还不了解的可以先去看看tensorflow版本的代码, ...
- Win10下Anaconda3安装CPU版本TensorFlow并使用Pycharm开发
环境:windows10 软件:Anaconda3 1.安装Anaconda 选择相应的Anaconda进行安装,下载地址点击这里,下载对应系统版本的Anaconda3. 运行 开始菜单->An ...
- 操作系统 | 结合 CPU 理解一行 Java 代码是怎么执行的
根据冯·诺依曼思想,计算机采用二进制作为数制基础,必须包含:运算器.控制器.存储设备,以及输入输出设备,如下图所示. 我们先来分析 CPU 的工作原理,现代 CPU 芯片中大都集成了,控制单元,运算单 ...
- 残差网络resnet理解与pytorch代码实现
写在前面 深度残差网络(Deep residual network, ResNet)自提出起,一次次刷新CNN模型在ImageNet中的成绩,解决了CNN模型难训练的问题.何凯明大神的工作令人佩服 ...
- git将本地代码 和服务器git@osc 上的代码 关联
将本地代码 和服务器git@osc 上的代码 关联 要使用git 首先,你得安装一个git 下载 http://git-scm.com/downloads 安装完成后,需要简单的配置一下,打开 Git ...
- Netty实现高性能IOT服务器(Groza)之精尽代码篇中
运行环境: JDK 8+ Maven 3.0+ Redis 技术栈: SpringBoot 2.0+ Redis (Lettuce客户端,RedisTemplate模板方法) Netty 4.1+ M ...
随机推荐
- vue bus传参
新建一个js文件,命名为bus.js.bus.js文件的内容为: import Vue from 'vue' const bus = new Vue() export default bus 页面de ...
- Lakehouse 还是 Warehouse?(2/2).md
这篇博文包括 Onehouse 首席执行官 Vinoth Chandar 于 2022 年 3 月在奥斯汀数据委员会发表的重要演讲的后半部分.本文是第 2 部分,比较了架构的功能和性价比特征.最后,它 ...
- 05-Python函数
函数定义与调用 函数由以下几个部分组成: 函数名 函数参数 函数体 返回值 定义一个函数: def showMyName(name): #定义函数 print(name) showMyName(&qu ...
- VS Code Go开发环境配置
1.安装Go 下载网址:https://go.dev/doc/install 根据自己的操作系统来进行安装,官网针对Windows.Linux.macOS都有对应教程.安装完成后打开终端,输入go v ...
- 搭建redis-sentinel(哨兵)
1.先创建redis一主两从的配置文件 2.编辑配置文件 cat >> /data/8012/redis.conf <<EOF port 8012 daemonize yes ...
- 使用kafka作为生产者生产数据到hdfs
关键:查看kafka官网的userGuide 配置文件: agent.sources = r1agent.sinks = k1agent.channels = c1 ## sources config ...
- Salt安装部署
Salt安装部署 一:salt简介 早期运维人员会根据自己的生产环境来写特定脚本完成大量重复性工作,这些脚本复杂且难以维护.系统管理员面临的问题主要是1.系统配置管理,2.远程执行命令,因此诞生了 ...
- Centos7安装nacos详细步骤(配置开机自启)
Nacos 解压文件 创建数据库nacos,导入nacos的sql文件 创建数据库nacos,导入nacos的sql文件 修改启动文件(根据系统选择) [root@localhost bin]# cd ...
- 面试官:Dubbo一次RPC请求经历哪些环节?
大家好,我是三友~~ 今天继续探秘系列,扒一扒一次RPC请求在Dubbo中经历的核心流程. 本文是基于Dubbo3.x版本进行讲解 一个简单的Demo 这里还是老样子,为了保证文章的完整性和连贯性,方 ...
- django信号中的条件判断不符合时如何提示错误并返回
在Django中,如果你在信号(Signal)处理函数中需要进行条件判断,如果条件不符合,你可以触发一个异常,并在视图或其他地方捕获这个异常,然后返回相应的错误提示. 以下是一个简单的例子,演示如何在 ...