Apache Hudi 在 B 站构建实时数据湖的实践
简介: B 站选择 Flink + Hudi 的数据湖技术方案,以及针对其做出的优化。
本文作者喻兆靖,介绍了为什么 B 站选择 Flink + Hudi 的数据湖技术方案,以及针对其做出的优化。主要内容为:
- 传统离线数仓痛点
- 数据湖技术方案
- Hudi 任务稳定性保障
- 数据入湖实践
- 增量数据湖平台收益
- 社区贡献
- 未来的发展与思考
一、传统离线数仓痛点
1. 痛点
之前 B 站数仓的入仓流程大致如下所示:
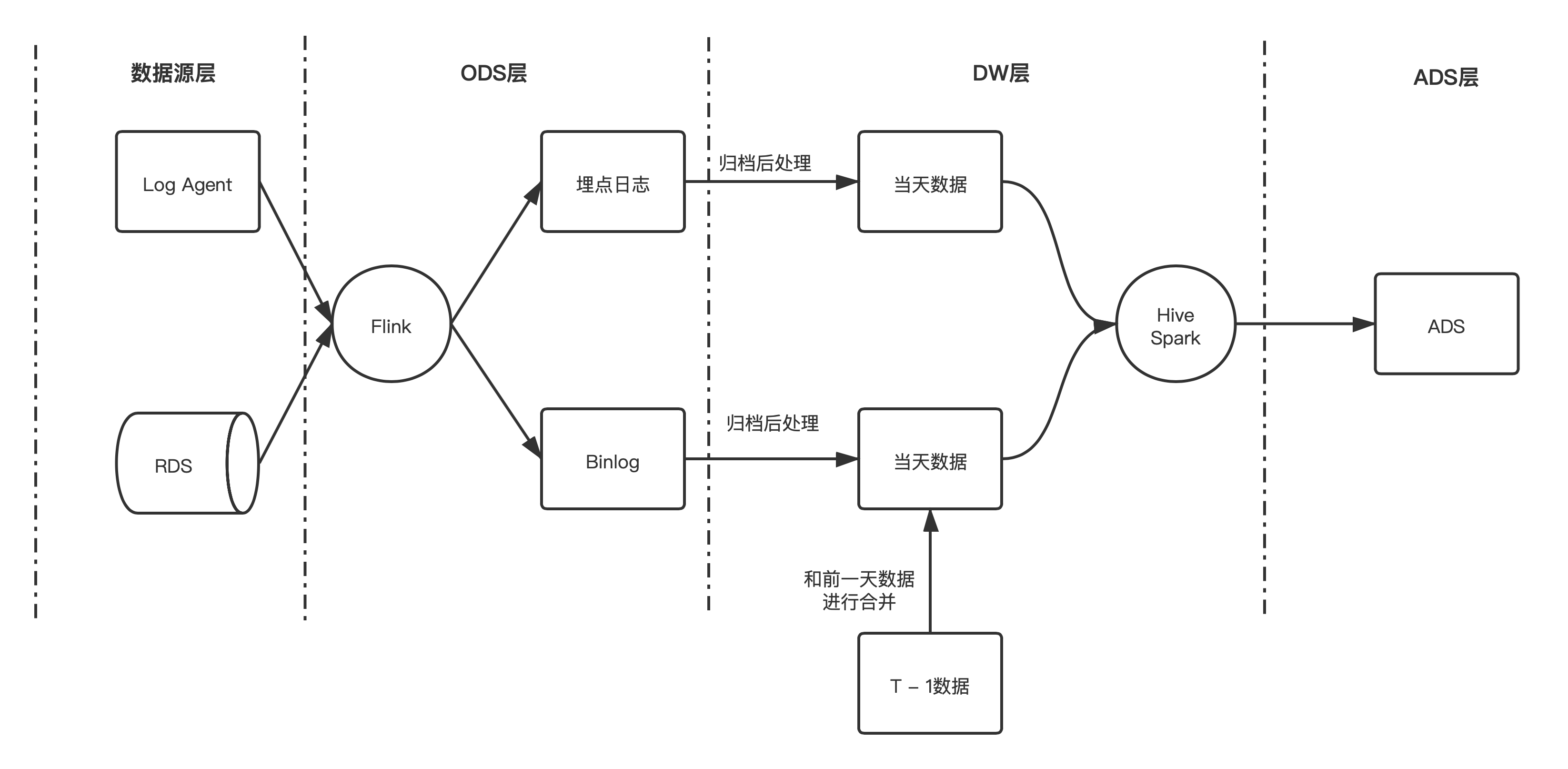
在这种架构下产生了以下几个核心痛点:
- 大规模的数据落地 HDFS 后,只能在凌晨分区归档后才能查询并做下一步处理;
- 数据量较大的 RDS 数据同步,需要在凌晨分区归档后才能处理,并且需要做排序、去重以及 join 前一天分区的数据,才能产生出当天的数据;
- 仅能通过分区粒度读取数据,在分流等场景下会出现大量的冗余 IO。
总结一下就是:
- 调度启动晚;
- 合并速度慢;
- 重复读取多。
2. 痛点思考
- 调度启动晚
思路:既然 Flink 落 ODS 是准实时写入的,有明确的文件增量概念,可以使用基于文件的增量同 步,将清洗、补维、分流等逻辑通过增量的方式进行处理,这样就可以在 ODS 分区未归档的时 候就处理数据,理论上数据的延迟只取决于最后一批文件的处理时间。
- 合并速度慢
思路:既然读取已经可以做到增量化了,那么合并也可以做到增量化,可以通过数据湖的能力结 合增量读取完成合并的增量化。
- 重复读取多
思路:重复读取多的主要原因是分区的粒度太粗了,只能精确到小时/天级别。我们需要尝试一 些更加细粒度的数据组织方案,将 Data Skipping 可以做到字段级别,这样就可以进行高效的数 据查询了。
3. 解决方案: Magneto - 基于 Hudi 的增量数据湖平台
以下是基于 Magneto 构建的入仓流程:
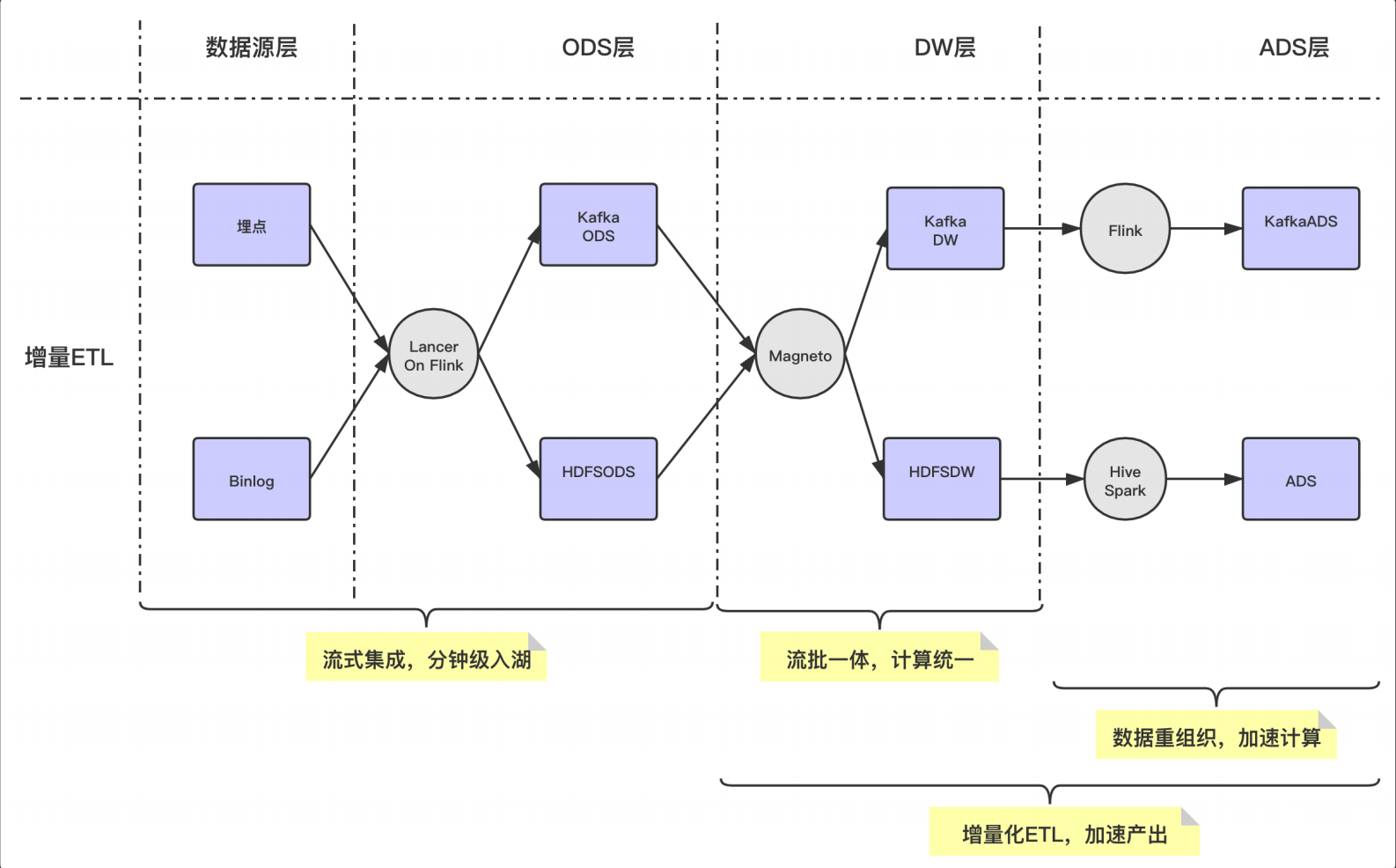
Flow
- 使用流式 Flow 的方式,统一离线和实时的 ETL Pipline
Organizer
- 数据重组织,加速查询
- 支持增量数据的 compaction
Engine
- 计算层使用 Flink,存储层使用 Hudi
Metadata
- 提炼表计算 SQL 逻辑
- 标准化 Table Format 计算范式
二、数据湖技术方案
1. Iceberg 与 Hudi 的取舍
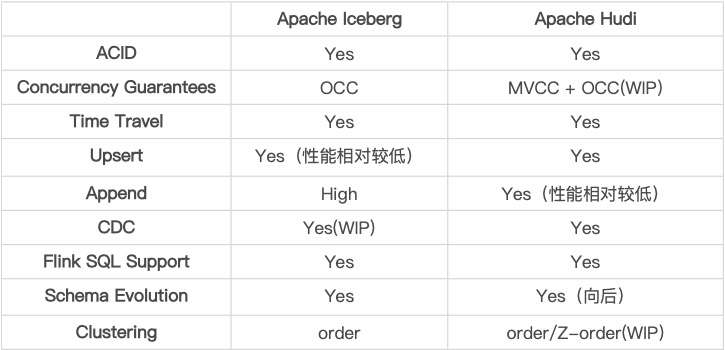
1.1 技术细节对比
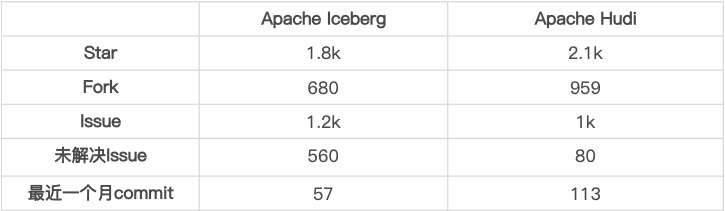
1.2 社区活跃度对比
统计截止至 2021-08-09
1.3 总结
大致可以分为以下几个主要纬度来进行对比:
- 对 Append 的支持
Iceberg 设计之初的主要支持方案,针对该场景做了很多优化。 Hudi 在 0.9 版本中对 Appned 模式进行了支持,目前在大部分场景下和 Iceberg 的差距不大, 目前的 0.10 版本中仍然在持续优化,与 Iceberg 的性能已经非常相近了。
- 对 Upsert 的支持
Hudi 设计之初的主要支持方案,相对于 Iceberg 的设计,性能和文件数量上有非常明显的优 势,并且 Compaction 流程和逻辑全部都是高度抽象的接口。 Iceberg 对于 Upsert 的支持启动较晚,社区方案在性能、小文件等地方与 Hudi 还有比较明显 的差距。
- 社区活跃度
Hudi 的社区相较于 Iceberg 社区明显更加活跃,得益于社区活跃,Hudi 对于功能的丰富程度与 Iceberg 拉开了一定的差距。
综合对比,我们选择了 Hudi 作为我们的数据湖组件,并在其上继续优化我们需要的功能 ( Flink 更好的集成、Clustering 支持等)
2. 选择 Flink + Hudi 作为写入方式
我们选择 Flink + Hudi 的方式集成 Hudi 的主要原因有三个:
- 我们部分自己维护了 Flink 引擎,支撑了全公司的实时计算,从成本上考虑不想同时维护两套计算引擎,尤其是在我们内部 Spark 版本也做了很多内部修改的情况下。
Spark + Hudi 的集成方案主要有两种 Index 方案可供选择,但是都有劣势:
- Bloom Index:使用 Bloom Index 的话,Spark 会在写入的时候,每个 task 都去 list 一遍所有的文件,读取 footer 内写入的 Bloom 过滤数据,这样会对我们内部压力已经非常大的 HDFS 造成非常恐怖的压力。
- Hbase Index:这种方式倒是可以做到 O(1) 的找到索引,但是需要引入外部依赖,这样会使整个方案变的比较重。
- 我们需要和 Flink 增量处理的框架进行对接。
3. Flink + Hudi 集成的优化
3.1 Hudi 0.8 版本集成 Flink 方案
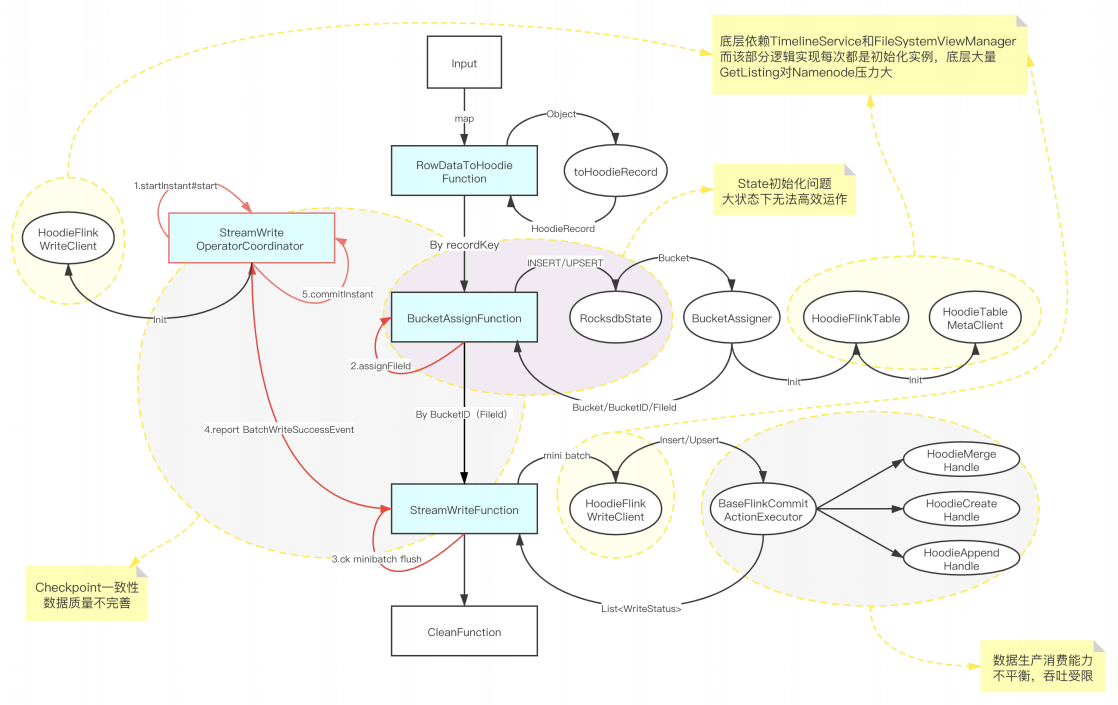
针对 Hudi 0.8 版本集成暴露出来的问题,B站和社区合作进行了优化与完善。
3.2 Bootstrap State 冷启动
背景:支持在已经存在 Hudi 表启动 Flink 任务写入,从而可以做到由 Spark on Hudi 到 Flink on Hudi 的方案切换
原方案:
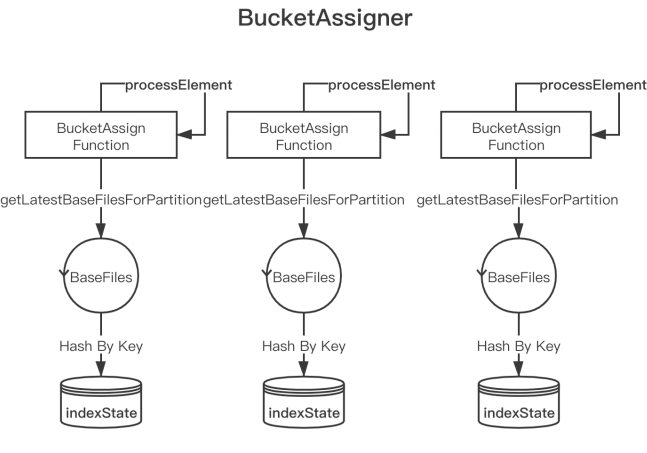
问题:每个 Task 处理全量数据,然后选择属于当前 Task 的 HoodieKey 存入 state 优化方案。
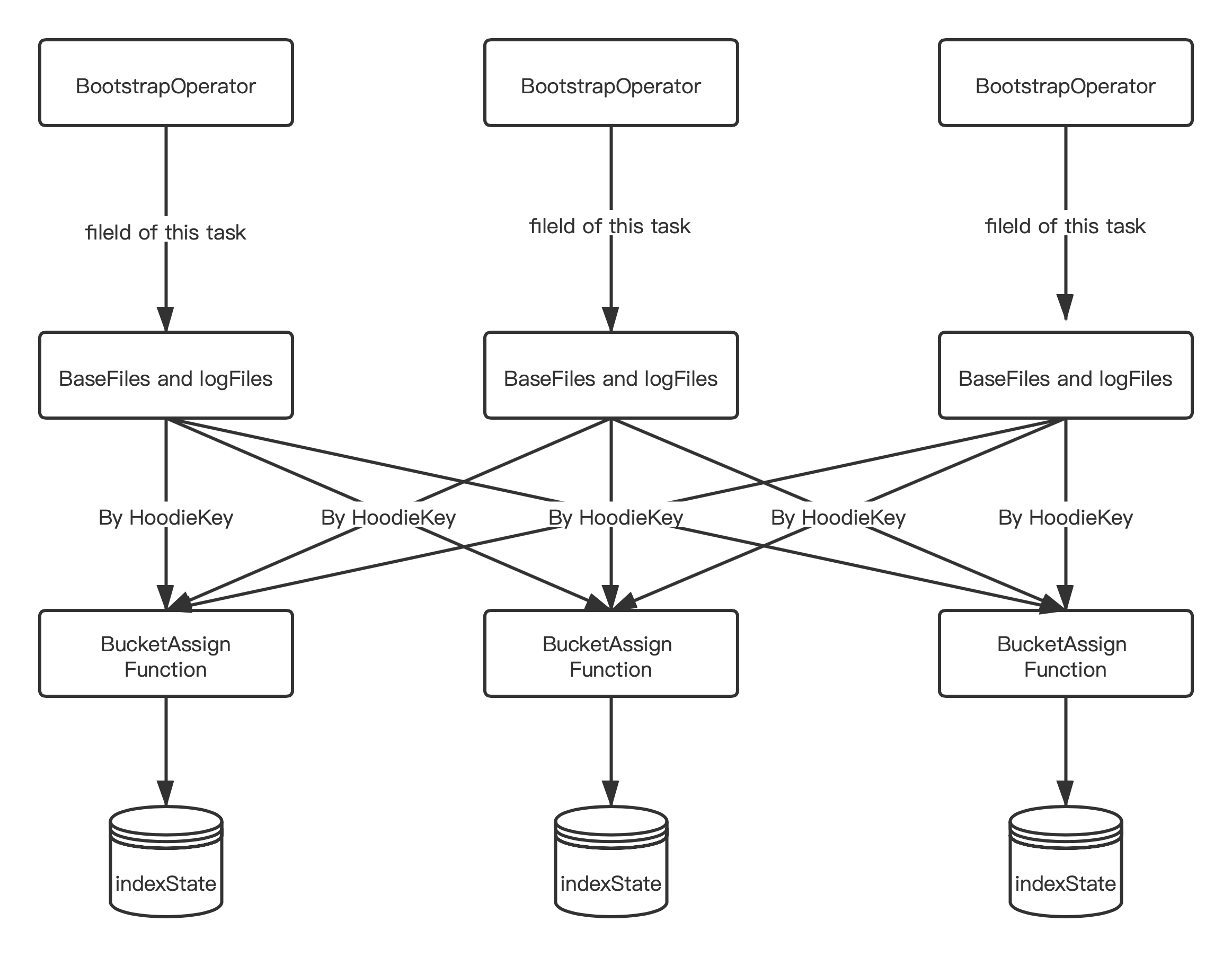
- 每个 Bootstrap Operator 在初始化时,加载属于当前 Task 的 fileId 相关的 BaseFile 和 logFile;
- 将 BaseFile 和 logFile 中的 recordKey 组装成 HoodieKey,通过 Key By 的形式发送给 BucketAssignFunction,然后将 HoodieKey 作为索引存储在 BucketAssignFunction 的 state 中。
效果:通过将 Bootstrap 功能单独抽出一个 Operator,做到了索引加载的可扩展性,加载速度提升 N (取决于并发度) 倍。
3.3 Checkpoint 一致性优化
背景:在 Hudi 0.8 版本的 StreamWriteFunction 中,存在极端情况下的数据一致性问题。
原方案:
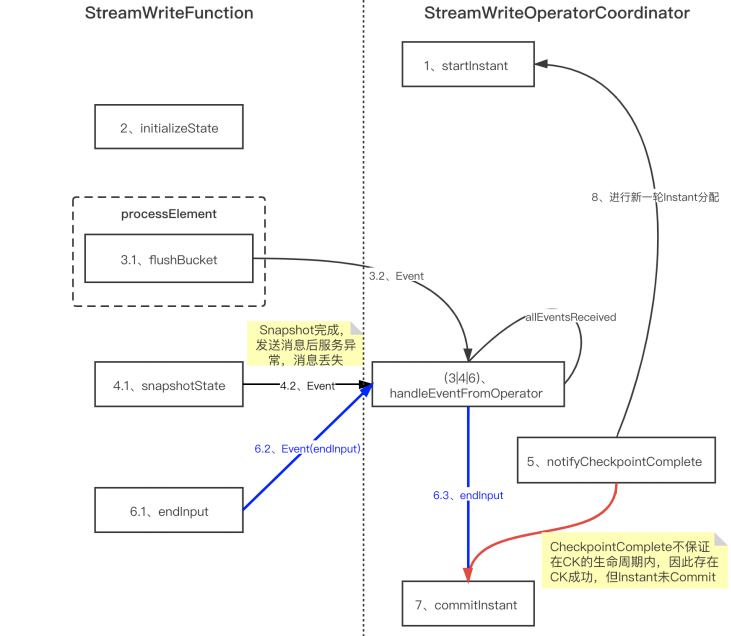
问题:CheckpointComplete不在CK生命周期内,存在CK成功但是instant没有commit的情 况,从而导致出现数据丢失。
优化方案:
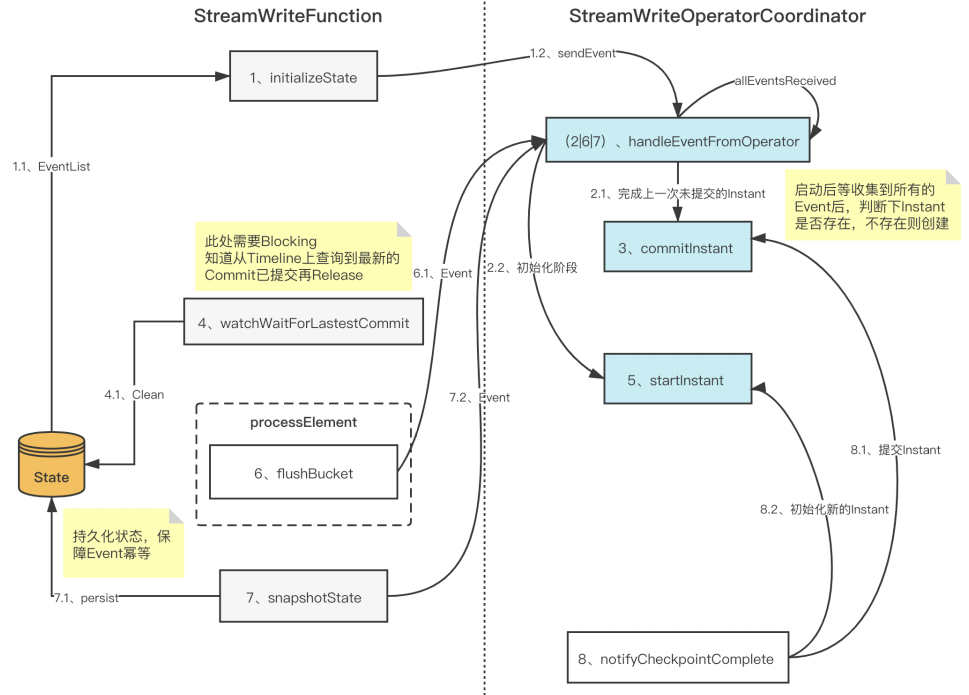
3.4 Append 模式支持及优化
背景:Append 模式是用于支持不需要 update 的数据集时使用的模式,可以在流程中省略索引、 合并等不必要的处理,从而大幅提高写入效率。
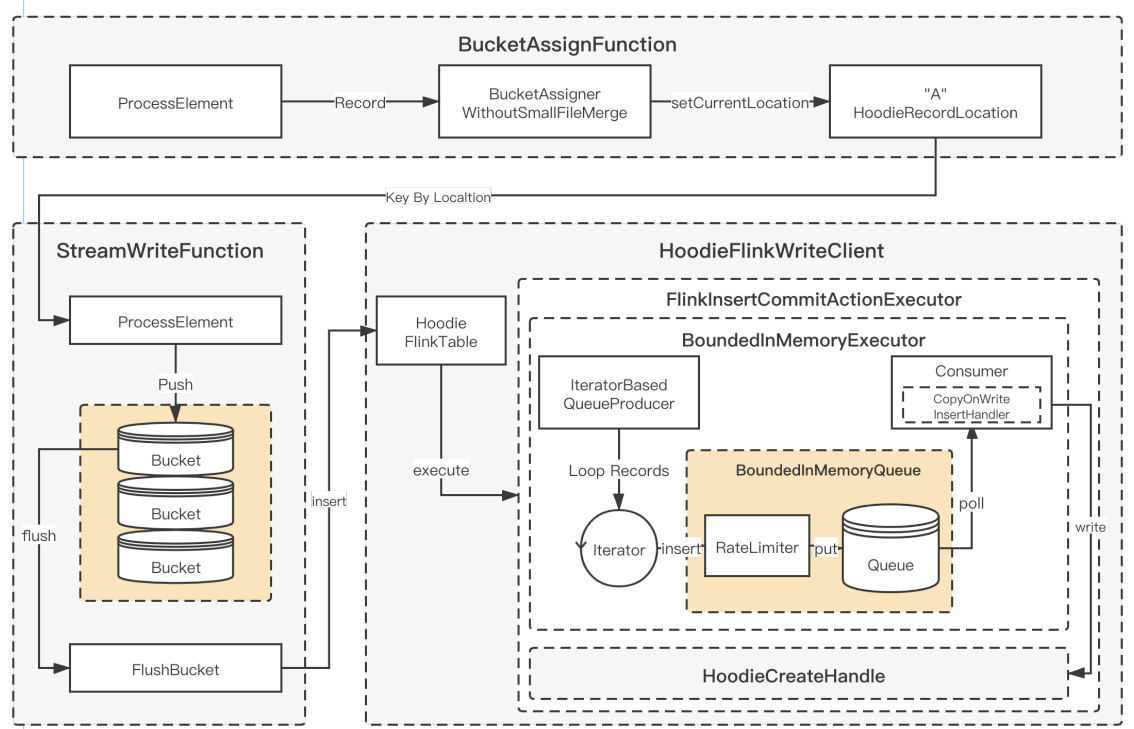

主要修改:
- 支持每次 FlushBucket 写入一个新的文件,避免出现读写的放大;
- 添加参数,支持关闭 BoundedInMemeoryQueue 内部的限速机制,在 Flink Append 模式下只需要将 Queue 的大小和 Bucket buffer 设置成同样的大小就可以了;
- 针对每个 CK 产生的小文件,制定自定义 Compaction 计划;
- 通过以上的开发和优化之后,在纯 Insert 场景下性能可达原先 COW 的 5 倍。
三、Hudi 任务稳定性保障
1. Hudi 集成 Flink Metrics
通过在关键节点上报 Metric,可以比较清晰的掌握整个任务的运行情况:
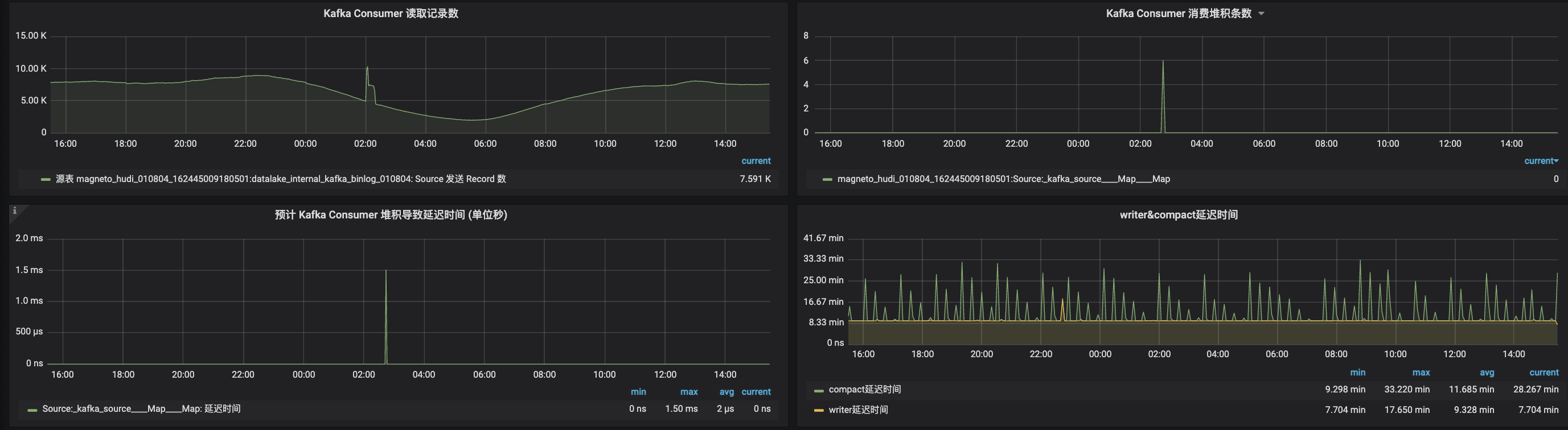
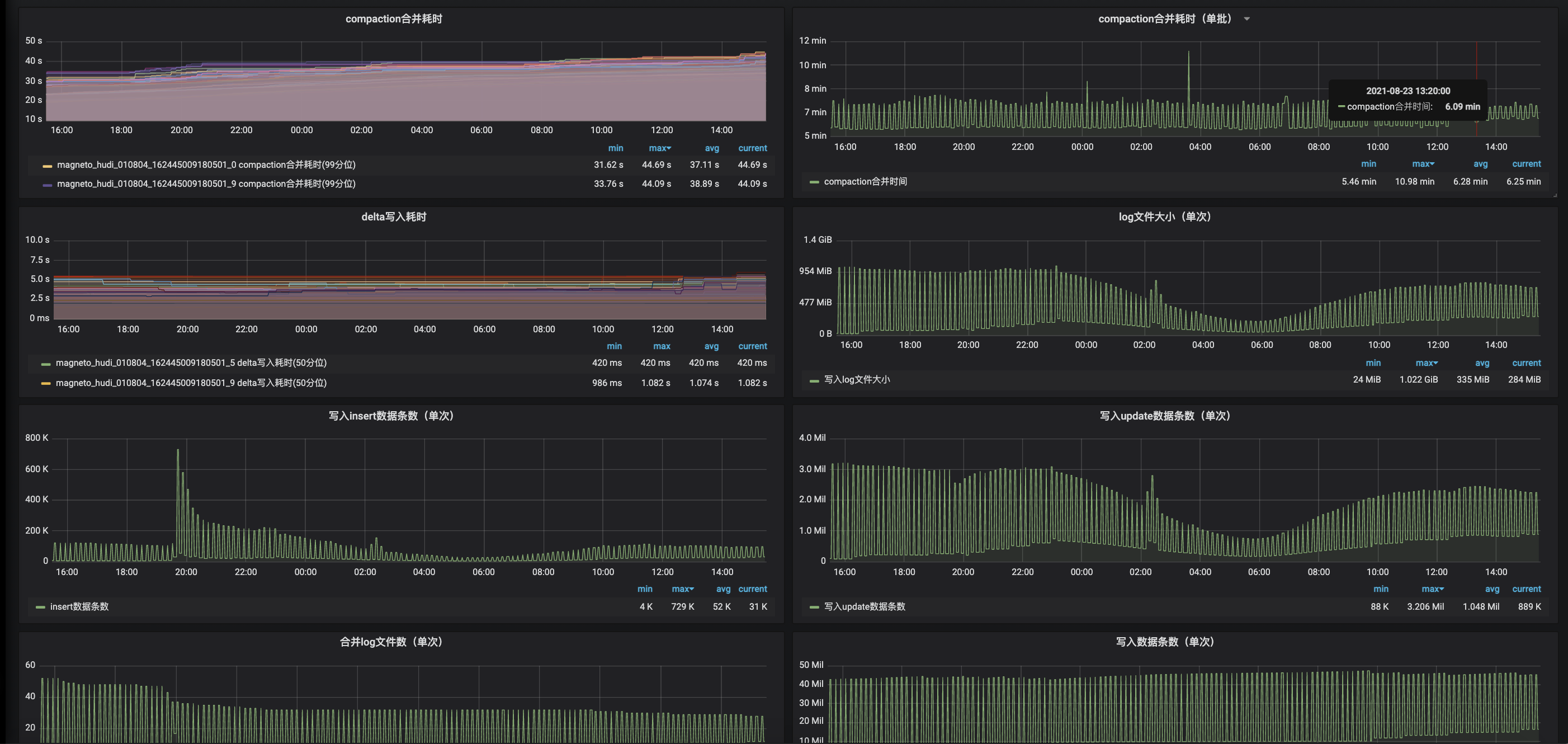
2. 系统内数据校验
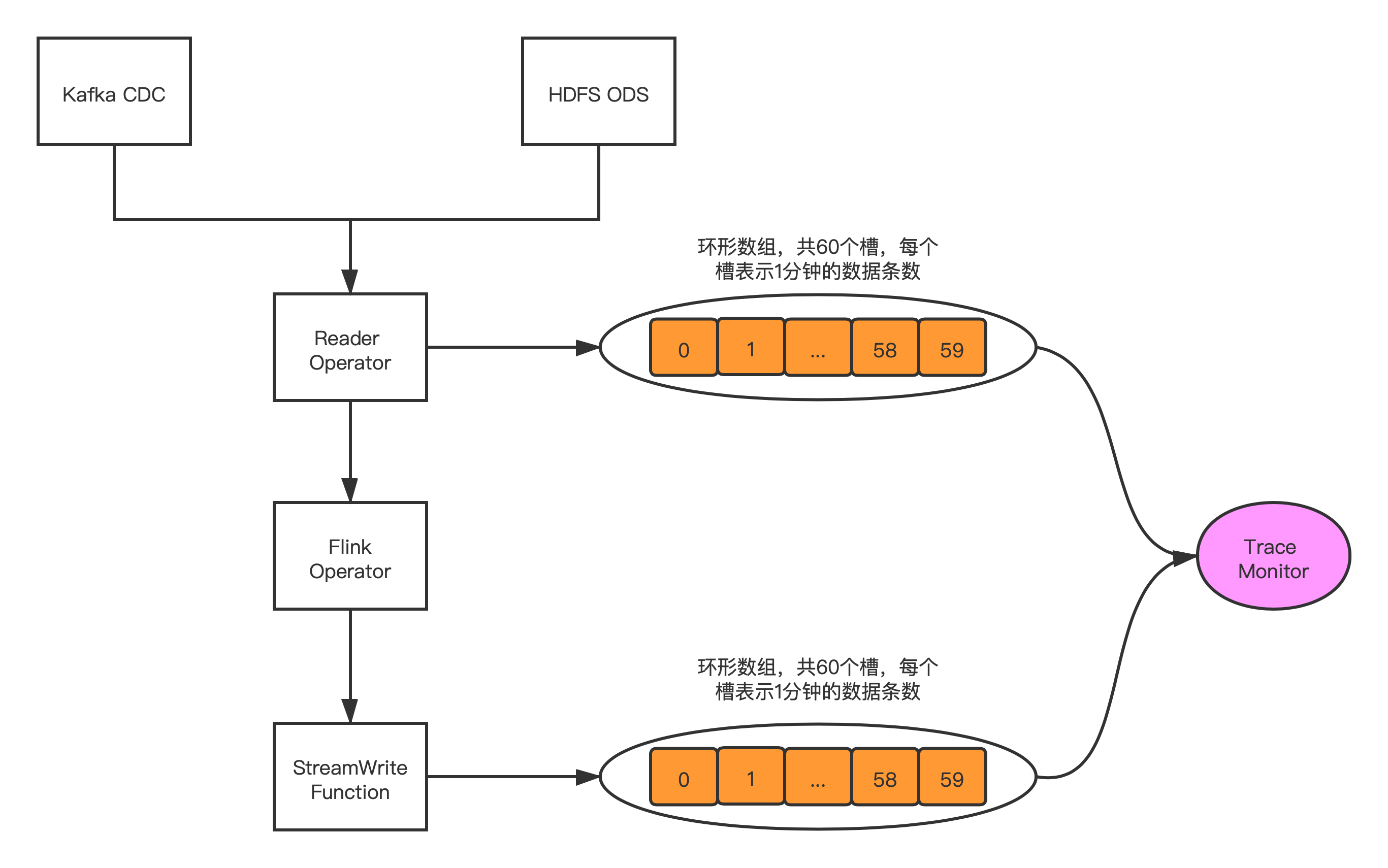
3. 系统外数据校验

四、数据入湖实践
1. CDC数据入湖
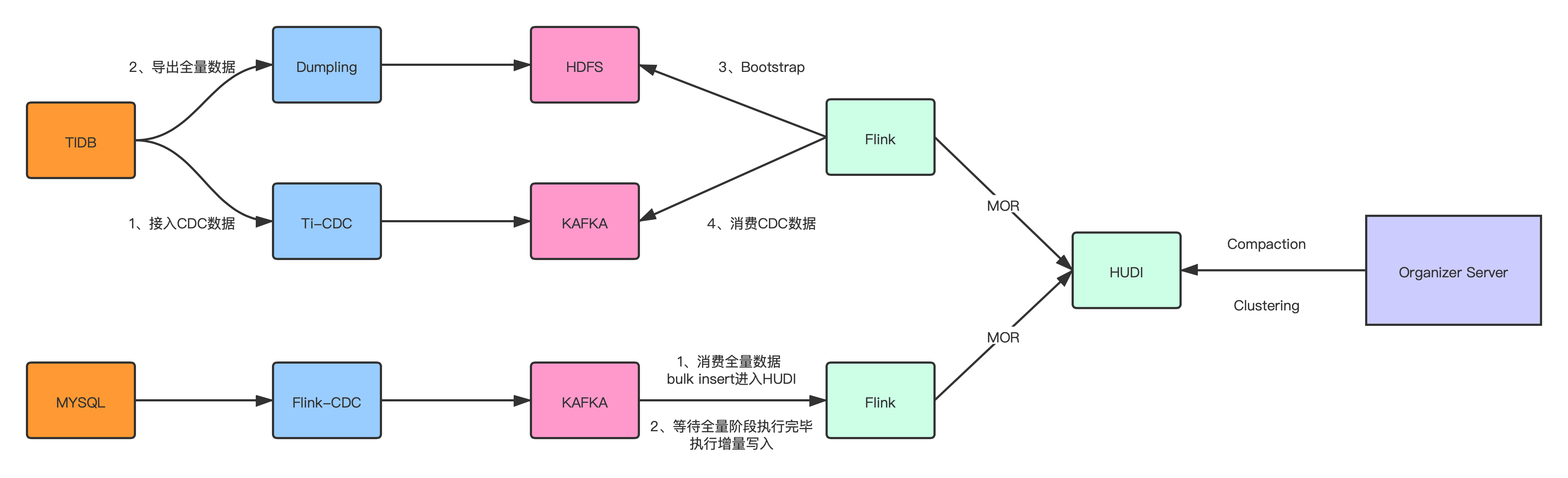
1.1 TiDB入湖方案
由于目前开源的各种方案都没办法直接支持 TiDB 的数据导出,直接使用 Select 的方式会影响数 据库的稳定性,所以拆成了全量 + 增量的方式:
- 启动 TI-CDC,将 TIDB 的 CDC 数据写入对应的 Kafka topic;
- 利用 TiDB 提供的 Dumpling 组件,修改部分源码,支持直接写入 HDFS;
- 启动 Flink 将全量数据通过 Bulk Insert 的方式写入 Hudi;
- 消费增量的 CDC 数据,通过 Flink MOR 的方式写入 Hudi。
1.2 MySQL 入湖方案
MySQL 的入湖方案是直接使用开源的 Flink-CDC,将全量和增量数据通过一个 Flink 任务写入 Kafka topic:
- 启动 Flink-CDC 任务将全量数据以及 CDC 数据导入 Kafka topic;
- 启动 Flink Batch 任务读取全量数据,通过 Bulk Insert 写入 Hudi;
- 切换为 Flink Streaming 任务将增量 CDC 数据通过 MOR 的方式写入 Hudi。
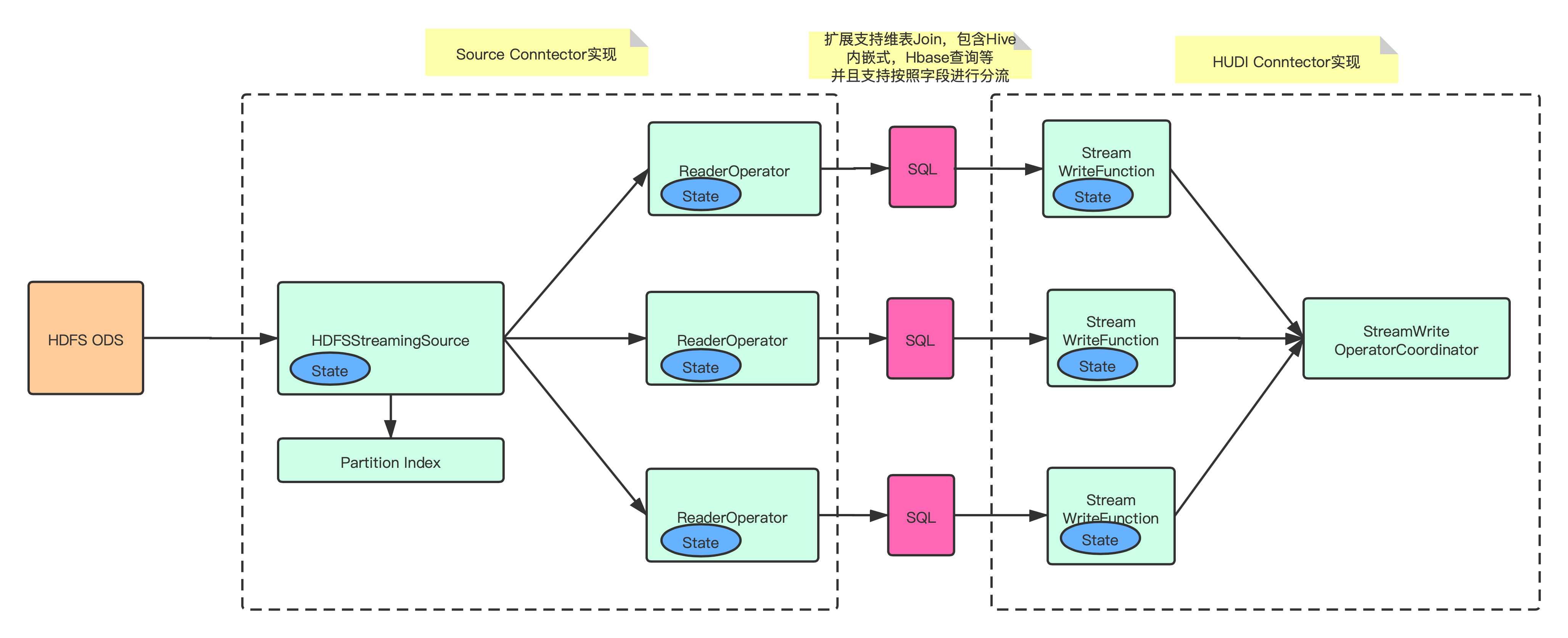
2. 日志数据增量入湖
- 实现 HDFSStreamingSource 和 ReaderOperator,增量同步 ODS 的数据文件,并且通过写入 ODS 的分区索引信息,减少对 HDFS 的 list 请求;
- 支持 transform SQL 配置化,允许用户进行自定义逻辑转化,包括但不限于维表 join、自定义 udf、按字段分流等;
- 实现 Flink on Hudi 的 Append 模式,大幅提升不需要合并的数据写入速率。
五、增量数据湖平台收益
- 通过 Flink 增量同步大幅度提升了数据同步的时效性,分区就绪时间从 2:00~5:00 提前到 00:30 分内;
- 存储引擎使用 Hudi,提供用户基于 COW、MOR 的多种查询方式,让不同用户可以根据自己 的应用场景选择合适的查询方式,而不是单纯的只能等待分区归档后查询;
- 相较于之前数仓的 T+1 Binlog 合并方式,基于 Hudi 的自动 Compaction 使得用户可以将 Hive 当成 MySQL 的快照进行查询;
- 大幅节约资源,原先需要重复查询的分流任务只需要执行一次,节约大约 18000 core。
六、社区贡献
上述优化都已经合并到 Hudi 社区,B站在未来会进一步加强 Hudi 的建设,与社区一起成⻓。
部分核心PR
七、未来的发展与思考
- 平台支持流批一体,统一实时与离线逻辑;
- 推进数仓增量化,达成 Hudi ODS -> Flink -> Hudi DW -> Flink -> Hudi ADS 的全流程;
- 在 Flink 上支持 Hudi 的 Clustering,体现出 Hudi 在数据组织上的优势,并探索 Z-Order 等加速多维查询的性能表现;
- 支持 inline clustering。
原文链接
本文为阿里云原创内容,未经允许不得转载。
Apache Hudi 在 B 站构建实时数据湖的实践的更多相关文章
- 使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入 大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的.遵循的基本原则之一是文件的"一次写入多次读取"访问模型.这对于处理 ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- DataPipeline丨构建实时数据集成平台时,在技术选型上的考量点
文 | 陈肃 DataPipeline CTO 随着企业应用复杂性的上升和微服务架构的流行,数据正变得越来越以应用为中心. 服务之间仅在必要时以接口或者消息队列方式进行数据交互,从而避免了构建单一数 ...
- Apache Hudi在华米科技的应用-湖仓一体化改造
徐昱 Apache Hudi Contributor:华米高级大数据开发工程师 巨东东 华米大数据开发工程师 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技 ...
- 基于Apache Hudi + Flink的亿级数据入湖实践
本次分享分为5个部分介绍Apache Hudi的应用与实践 实时数据落地需求演进 基于Spark+Hudi的实时数据落地应用实践 基于Flink自定义实时数据落地实践 基于Flink+Hudi的应用实 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(中)
引言 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 因此数据湖相关服务 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(下)
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- 深度对比Apache CarbonData、Hudi和Open Delta三大开源数据湖方案
摘要:今天我们就来解构数据湖的核心需求,同时深度对比Apache CarbonData.Hudi和Open Delta三大解决方案,帮助用户更好地针对自身场景来做数据湖方案选型. 背景 我们已经看到, ...
- 基于 Apache Hudi + Presto + AWS S3 构建开放Lakehouse
认识Lakehouse 数据仓库被认为是对结构化数据执行分析的标准,但它不能处理非结构化数据. 包括诸如文本.图像.音频.视频和其他格式的信息. 此外机器学习和人工智能在业务的各个方面变得越来越普遍, ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2不容错过(上)
背景 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 数据湖的核心功能, ...
随机推荐
- JS(运算符、流程控制)
一 运算符(操作符) 1 运算符的分类 运算符(operator)也被称为操作符,是用于实现赋值.比较和执行算数运算等功能的符号. JavaScript中常用的运算符有: 算数运算符 递增和递减运算符 ...
- window-命令行操作
window命令行操作 调起命令行-win+r输入cmd 网络探活 ping www.baidu.com 快捷启动应用 打开记事本 notepad 打开画图 mspaint 打开计算器 calc 命令 ...
- Python 合并Excel数据 (Excel文件单sheet)
一.Python批量合并Excel数据<方法1> import pandas as pd import glob import os # 使用glob.glob函数获取指定目录下所有以.x ...
- 跳转到制定Sheet页及提交指定sheet页内容
一.跳转到指定Sheet的实现 话不多说,先上效果图 两个按钮的事件分别如下: _g().loadSheetByName("sheet1") # 跳转至sheet1按钮事件 _g( ...
- 【已解决】wordpress 修改固定链接 伪静态URL出现nginx 404错误
一.站点设置 打开站点设置,选择伪静态,选择wordpress 二.wordpress设置 打开wordpress后台,选择设置 --->固定链接 选择一个你喜欢的格式点击保存 之后打开你的文章 ...
- 不到2000字,轻松带你搞懂STM32中GPIO的8种工作模式
大家好,我是知微! 学习过单片机的小伙伴对GPIO肯定不陌生,GPIO (general purpose input output)是通用输入输出端口的简称,通俗来讲就是单片机上的引脚. 在STM32 ...
- 3 JavaScript字符串操作
3 字符串操作 常用的字符串操作相关的方法: s.split() 字符串切割 s.substr(start, len) 字符串切割, 从start开始切, 切len个字符 s.substring(st ...
- #博弈论#Poj 2505 A multiplication game
题目 给你一个整数\(n\),你从1开始乘,乘2-9之间的任意一个数. 最先得到大于等于\(n\)的数的人胜利.Stan先手Ollie后手. 那么,请问给你一个数\(n\),Stan和Ollie都足够 ...
- #trie,动态规划#洛谷 2292 [HNOI2004]L语言
题目 分析 建一棵trie,然后匹配最长前缀可以用\(dp\)做, 如果这个位置可以被匹配到那么可以从这个位置继续匹配 代码 #include <cstdio> #include < ...
- Python删除文件、文件夹----os
使用 os 删除文件 import os '''删除文件 语法: os.unlink(path) 示例: 删除 b 文件夹中的 12.txt ''' os.unlink('b/12.txt') ...