如何使用 Kubernetes 监测定位慢调用
简介:本次课程主要分为三大部分,首先将介绍慢调用的危害以及常见的原因;其次介绍慢调用的分析方法以及最佳实践;最后将通过几个案例来去演示一下慢调用的分析过程。
作者:李煌东
大家好,我是阿里云的李煌东。今天我为大家分享 Kubernetes 监测公开课第四节,如何使用 Kubernetes 监测定位慢调用。今天的课程主要分为三大部分,首先我会介绍一下慢调用的危害以及常见的原因;其次我会介绍慢调用的分析方法以及最佳实践;最后通过几个案例来去演示一下慢调用的分析过程。
慢调用危害及常见原因
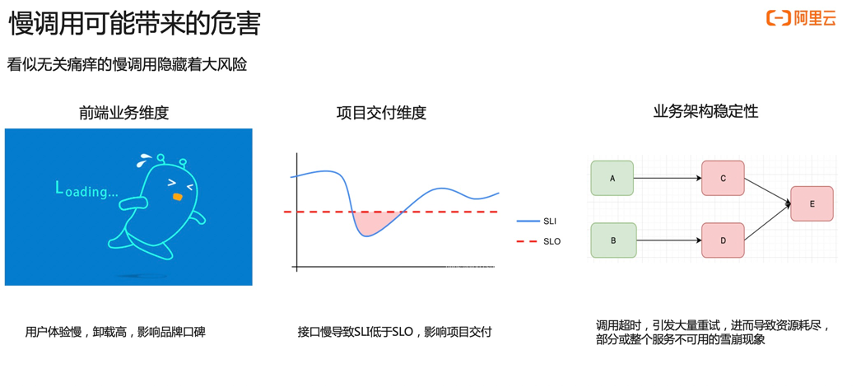
在开发软件过程中,慢调用是非常常见的异常。慢调用可能带来的危害包括:
- 前端业务维度:首先慢调用可能会引起前端加载慢的问题,前端加载慢可能会进一步导致应用卸载率高,进而影响品牌的口碑。
- 项目交付的维度:由于接口慢导致达不到 SLO,进而导致项目延期。
- 业务架构稳定性:当接口调用慢时,非常容易引起超时,当其他业务服务都依赖这个接口,那么就会引发大量重试,进而导致资源耗尽,最终导致部分服务或者整个服务不可用的雪崩的现象。
所以,看似一个无关痛痒的慢调用可能隐藏着巨大风险,我们应该引起警惕。对慢调用最好都不要去忽视它,应该尽可能去分析其背后的原因,从而进行风险控制。
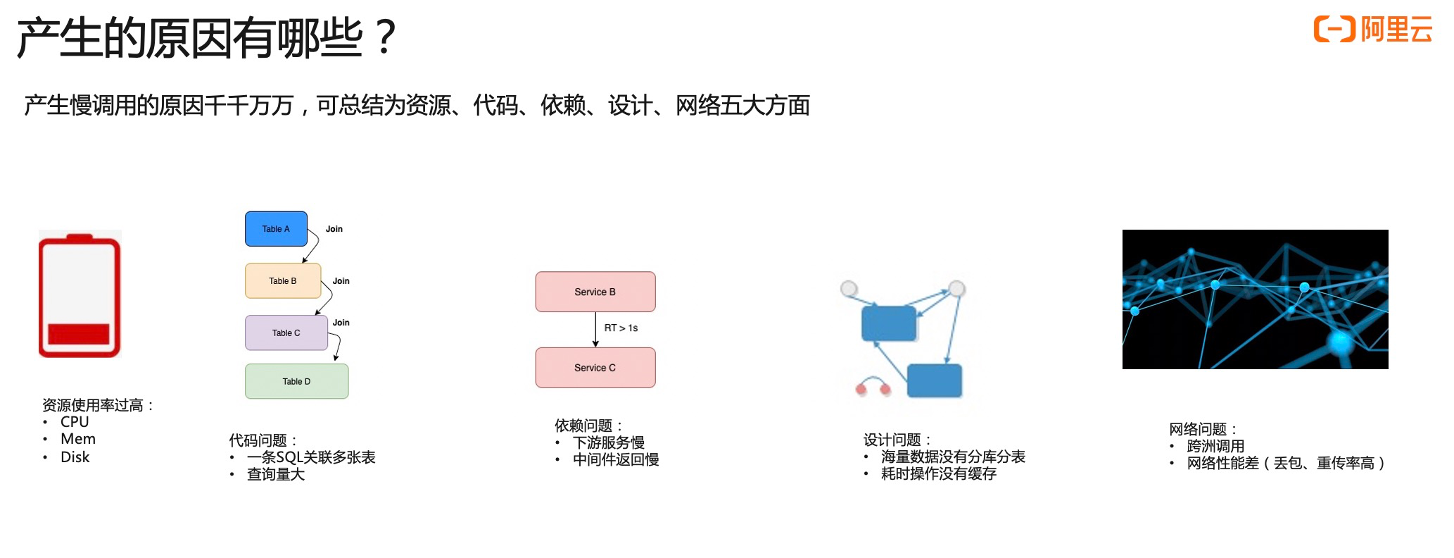
产生慢调用的原因有哪些?产生慢调用的原因是千千万万的,归结起来有五个常见原因。
- 第一个是资源使用率过高问题,比如说 CPU 内存、磁盘、网卡等等。当这些使用率过高的时候,非常容易引起服务慢。
- 第二个是代码设计的问题,通常来说如果 SQL 它关联了很多表,做了很多表,那么会非常影响 SQL 执行的性能。
- 第三个是依赖问题,服务自身没有问题,但调用下游服务时下游返回慢,自身服务处于等待状态,也会导致服务慢调用的情况。
- 第四个是设计问题,比如说海量数据的表非常大,亿级别数据查询没有分库分表,那么就会非常容易引起慢查询。类似的情况还有耗时的操作没有做缓存。
- 第五个是网络方面问题,比如说跨洲调用,跨洲调用是物理距离太大了,导致往返时间比较长,进而导致慢调用。或者两点之间的网络性能可能比较差。比如说有丢包重传率,重传率高的问题。
今天我们的例子围绕这五个方面,我们一起来看一下。
定位慢调用一般来说有什么样的步骤,或者说有什么样的最佳实践呢?我这里总结的为三个方面:黄金信号 + 资源指标 + 全局架构。

我们先来看一下黄金信号。首先,黄金信号是出自谷歌 SRE 圣经里面的 Site Reliability Engineering 一书。用来表征系统是否健康的最小指标的集合,这其中包括:
- 延时--用来描述系统执行请求花费的时间。常见指标包括平均响应时间,P90/P95/P99 这些分位数,这些指标能够很好的表征这个系统对外响应的快还是慢,是比较直观的。
- 流量--用来表征服务繁忙程度,典型的指标有 QPS、TPS。
- 错误--也就是我们常见的类似于协议里 HTTP 协议里面的 500、400 这些,通常如果错误很多的话,说明可能已经出现问题了。
- 饱和度--就是资源水位,通常来说接近饱和的服务比较容易出现问题,比如说磁盘满了,导致日志没办法写入,进而导致服务响应。典型的那些资源有 CPU、 内存、磁盘、队列长度、连接数等等。
除了黄金信号,我们还需要关注一个资源指标。著名的性能分析大神 Brandan Gregg ,在他的性能分析方法论文章中提到一个 USE 方法。USE 方法是从资源角度进行分析,它是对于每一个资源去检查 utilization(使用率),saturation (饱和度),error(错误) ,合起来就是 USE 了,检查这三项基本上能够解决 80% 的服务问题,而你只需要花费 5% 的时间。
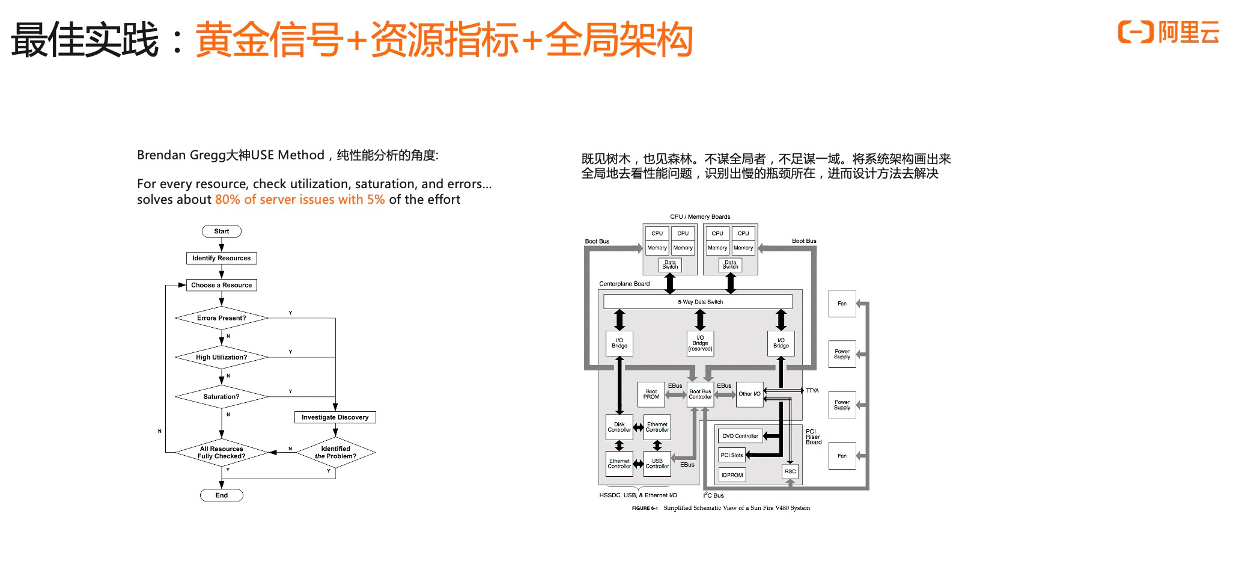
前面有了黄金信号、资源指标之后,我们还需要关注什么?正如 Branda 在方法论里面提到的“我们不能只见树木,不见森林”。诸葛亮也说过“不谋全局者,不足以谋一域”。我们应该把系统架构画出来,从全局去看性能问题,而不只是看某个资源、某个服务。把所有东西进行综合考虑,识别出瓶颈所在,通过设计方法系统性解决问题,这也是一种更优的方法。所以,我们需要黄金信号、资源指标以及全局架构这种组合。
慢调用最佳实践
接下来我会讲三个案例,第一个是节点 CPU 打满问题,这也是典型的资源问题导致的服务慢的问题,即服务自身的资源导致的问题。第二个是依赖的服务中间件慢调用的问题。第三个是网络性能差。第一个案例是判断服务自身有没有问题;第二个案例是判断下游服务的问题;第三个就是判断自身跟服务之间的网络性能问题。
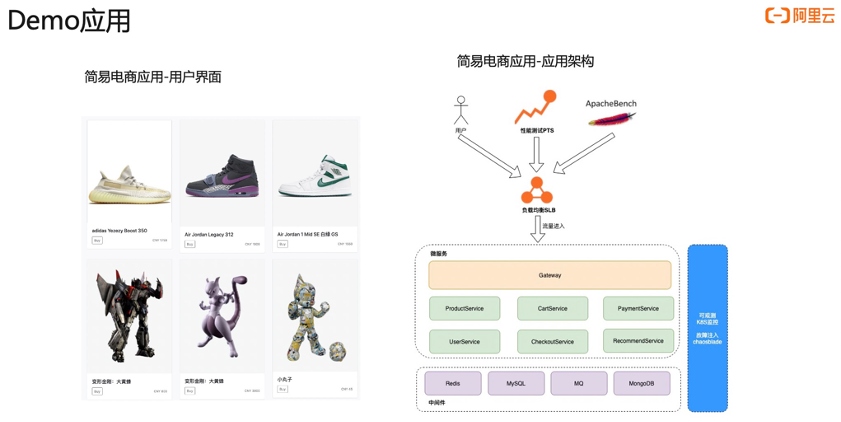
我们以一个电商应用举例。首先流量入口是阿里云 SLB,然后流量进入到微服务体系中,微服务里面我们通过网关去接收所有流量,然后网关会把流量打到对应的内部服务里面,比如说 ProductService、CartService、 PaymentService 这些。下面我们依赖了一些中间件,比如说 Redis 、MySQL 等等,这整个架构我们会使用阿里云的 ARMS 的 Kubernetes 监测产品来去监测整个架构。故障注入方面,我们会通过 chaosblade 去注入诸如 CPU 打满、网络异常等不同类型的异常。
案例一:节点 CPU 打满问题
节点 CPU 打满会带来什么样的问题呢?节点 CPU 打满之后,上面的 Pod 可能没办法申请到更多 CPU,导致里面的线程都处于等待调度的状态,进而导致慢调用。除了节点上面,我们这除了 CPU 之外,还有一些像磁盘、Memory 等等资源。
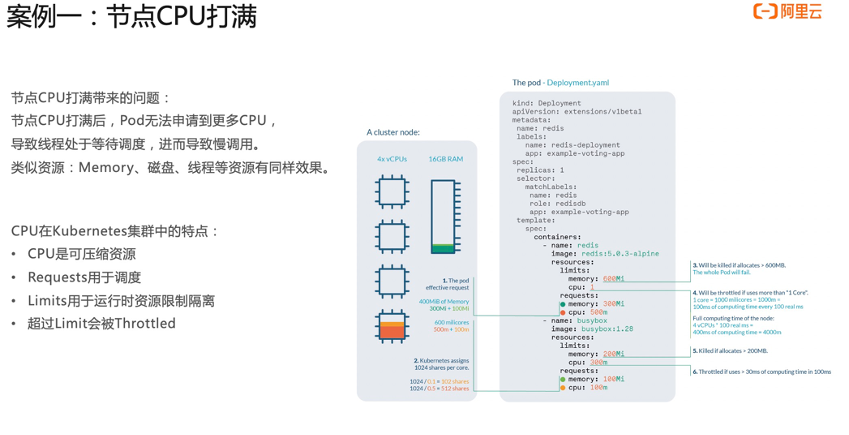
接下来我们看一下 CPU 在 Kubernetes 的集群里面的一些特点。首先,CPU 是可压缩的资源,在 Kubernetes 里面我们右边看这些配置,有几个常见配置,比如说 Requests,Requests 是主要是用来做调度的。Limits 是用来去做运行时的一个限制,超过这个 Limits,它就会被限流。所以,我们的实验原理是说对节点这个 CPU 进行打满注入,导致 Pod 没办法申请到更多的内存,进而导致服务变慢。
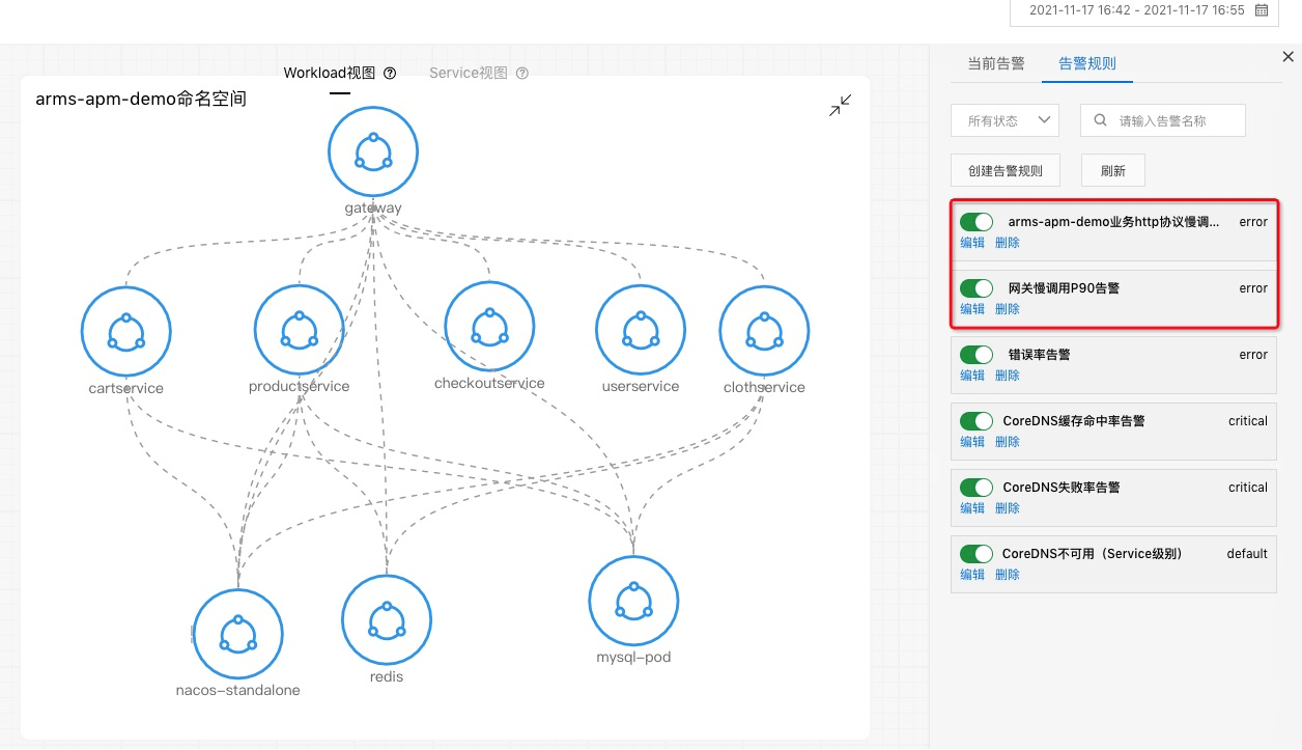
在正式开始前,我们通过拓扑图对关键链路进行识别,在上面配置一些告警。比如说网关及支付链路,我们会配置平均响应时间 P90 以及慢调用等告警。然后配置完之后,我这边会注入一个节点 CPU 打满这么一个故障。那这个节点选的是网关的节点,大概等待五分钟之后,我们就可以收到告警,就是第二步里面的那个验证告警的有效性。
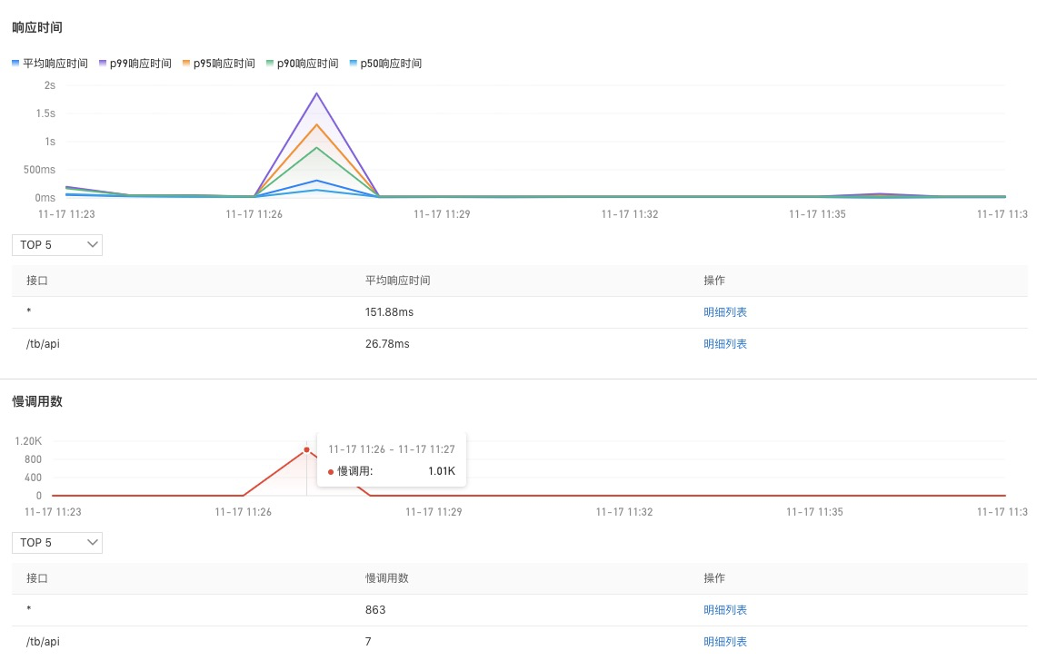
接下来我们进入根因定位。首先,我们进入到查看到网关的应用详情里面。第一步是查看相关黄金信号,黄金信号就是响应时间,我们看到响应时间非常直观显示了突增,下面是慢调用数,慢调用数是有一千多个,慢调用数突然增多了,P90/P95 出现了明显上升,并超过一秒,说明整个服务也变慢了。
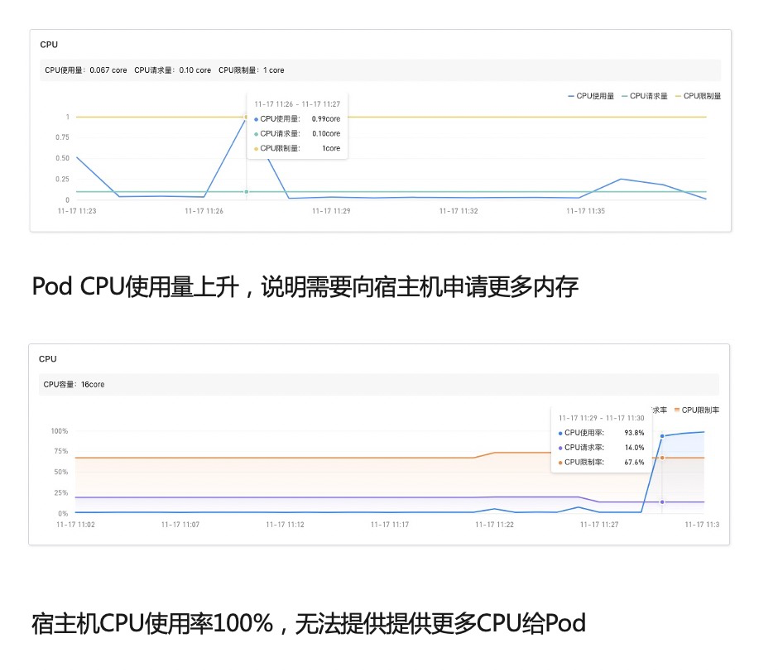
接下来,我们需要分析资源指标,在 Pod CPU 使用量图表中可以看到这段时间 Pod 使用量上升很快,这个过程说明需要向宿主机或者节点申请更多内存。我们进一步看一下节点或者宿主机的 CPU 使用率是怎么样的,我们看到这段时间使用率接近百分之百,Pod 申请不了更多 CPU,进一步导致服务慢了,进而导致平均响应时间大量增长。
定位到问题之后,我们可以想想具体解决方案。通过 CPU 使用率配置弹性伸缩。因为我们不知道相关流量或者资源,不知道什么时候突然就不够。那么应对这种场景最好的办法就是给资源配置弹性伸缩,为节点配置弹性伸缩,主要是为了确保在负载上升时,资源能够动态扩容。为了给应用配置弹性伸缩,我们可以给比如 CPU 指标,配置一个增加副本数的一个扩容动作来去分担流量,这里面我们可以配置成最大副本数为十,最小副本数为三等等。
效果如下:注入 CPU 慢故障时,慢调用会上升,上升完成之后会触发到弹性伸缩,那就是 CPU 的使用率超过阈值了,如 70%。那么,它就会自动扩出一些副本去分担这些流量,我们可以看到慢调用数逐步下降直到消失,说明我们的那个弹性伸缩起到作用了。

案例二:依赖的服务中间件慢调用的问题
接下来我们看第二个案例。首先介绍一下准备工作,左边这边图我们可以看到网关进来掉了两个下游服务,一个是 MySQL ,一个是 ProductService,所以在网关上直接配置一个大于一秒的告警,平均响应时间 P99 大于一秒的告警。第二步我们看这个 Product 也是在关键链路上面,我给它配一个 P99 大于一秒的告警,第三个是 MySQL ,也配一个大于一秒的告警,配完之后,我会在 Product 这个服务上面去注入一个 MySQL 慢查询的故障,大概等到两分钟之后,我们就可以看到陆续告警就触发出来了,网关跟 Product 上面都有一个红点跟一个灰色的点,这一点其实就是报出来的故障,报出的告警事件,Kubernetes 监测会把这个告警事件通过命名空间应用自动的 match 到这个节点上面,所以能够一眼的看出哪些服务、哪些应用是异常的,这样能够快速定位出问题所在。我们现在收到告警了之后,下一步去进行一个根因定位。
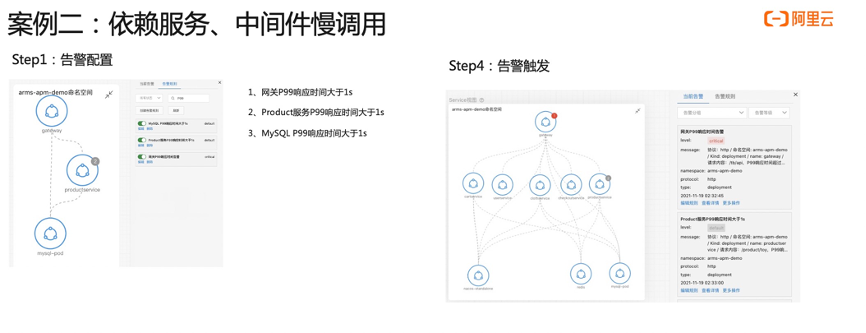
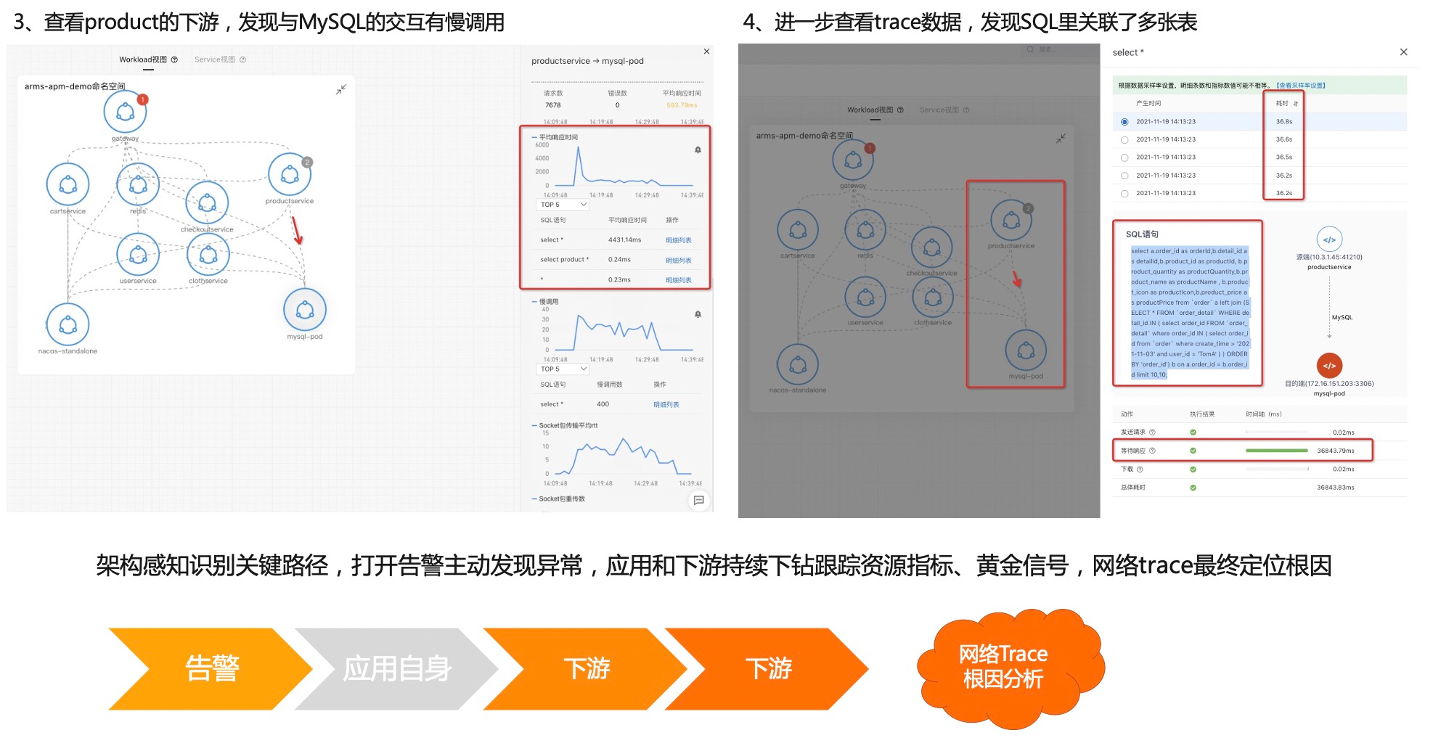
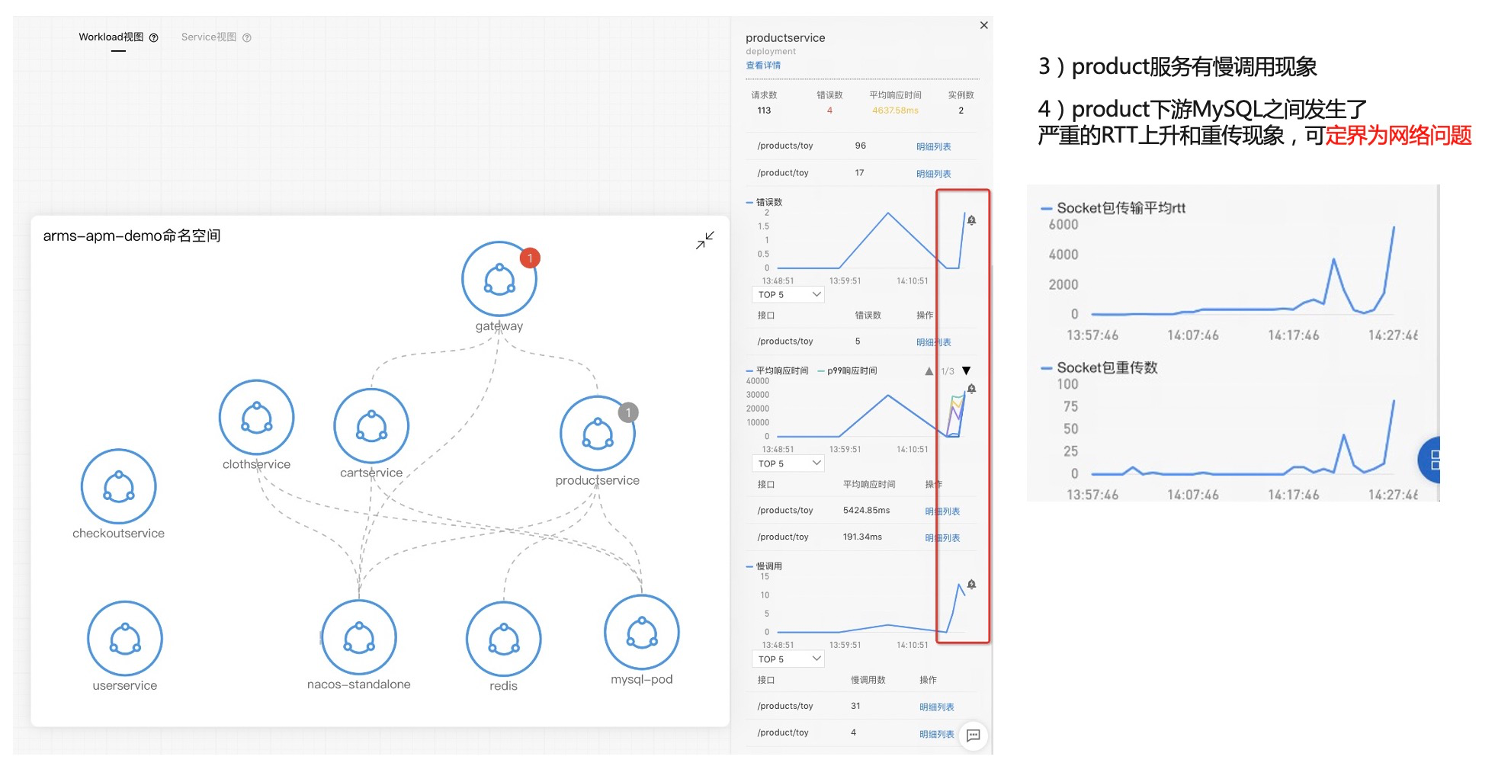
首先说一下这个更新定位的流程,告警驱动因为预防总比补救要好,所以我们是采用先配置告警,再去更新定位这么一个过程。然后我们会用拓扑来去进行一个可视化分析,因为拓扑是能够去进行架构感知、分析上下游,可以进行可视化分析。当收到告警后,可以针对告警看对应的一个应用发生了什么情况。第一个我们看那个网关,我们看到网关的那个 P99 上升到 1800 毫秒以上,所以触发了一个大于 1 秒阈值的这么一个告警。我们可以也可以看到几个分位数都是上涨的,然后我们进一步看另外一个发生告警的服务,也就是 Product,点开这个节点之后,我们可以从那个 panel 上面看到这个 Product 也发生了一个慢调用,P99、P95 都已经不同程度的发生慢调用大都是大于一秒的,然后这时候我们是可以去看一下 Product 的资源使用情况的,因为可能 Product 本身有问题。我们查看 Product 的下游,一个是 Nacos,一个是 MySQL,我们看 MySQL 的这个交互的时候就发现这里面有大量的一个慢调用,然后看到这些慢调用之后,点击这些明细,去下钻看一下它调用的时候发生了什么事情,我们进一步看这些数据之后,就会发现 SQL 里面 Product 调用 Mysql 的时候执行了一条很复杂,Join 了多张表的一个 SQL 的语句。从调用 Trace 看到耗时非常大,这样的话我们就能够定位到基本上是这条 SQL 产生的一个问题了。
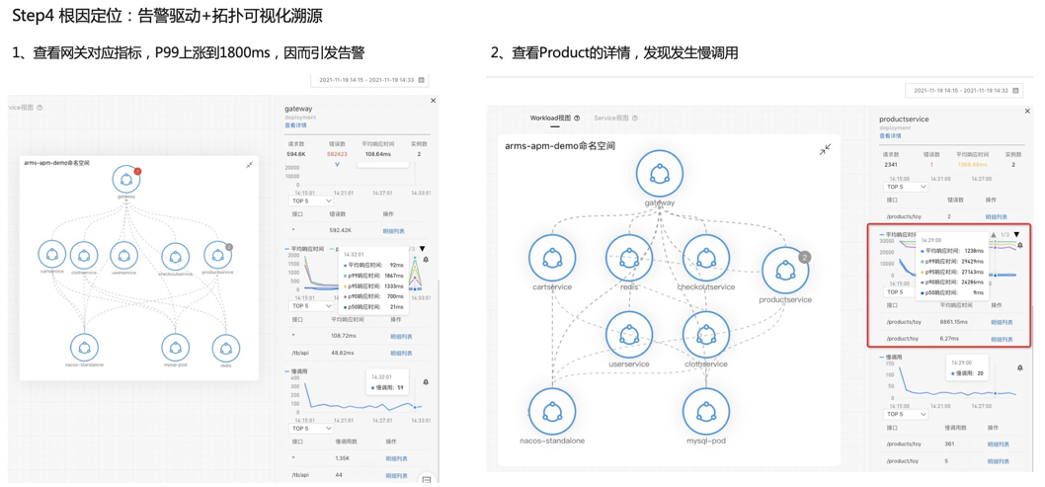
总结一下我们整个流程,首先我们会通过架构感知去识别关键的路径,然后在这个关键路径上去配置告警去主动发现异常。发现异常之后,我们通过应用自身的资源指标黄金信号等来去定位问题。如果自身没有问题,那我们就可往下追踪下游,我们去看下游的资源指标,用这么一种方法去定位慢调用的一个依赖的问题,中间件调用的问题。
案例三:网络性能差
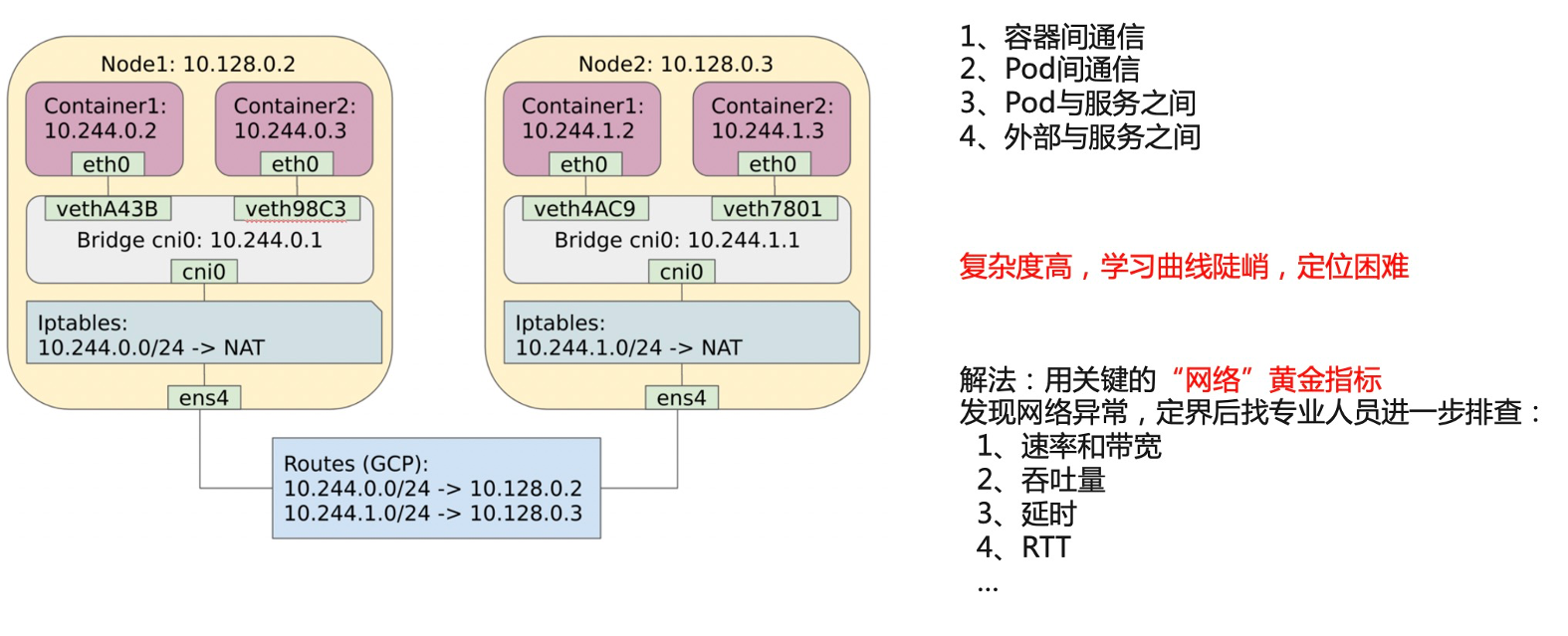
接下来我们讲最后一个例子就是网络性能差,Kubernetes 的网络架构是比较复杂的,容器之间的通信、Pod 之间的通信、Pod 与服务之间通信、外部与服务之间的通信等等。所以复杂度是比较高的,学习的曲线也比较陡峭,这给定位问题带来一定困难。那么,我们怎么去应对这种情况呢?如果采用关键网络环境指标去发现网络异常,有哪些关键环境指标呢?首先一个是速率跟带宽,第二个是吞吐量,第三个是延时,第四个是 RTT。
首先我会这边配置一个告警,注入 MySQL 所在节点丢包率高这个故障,等待几分钟之后,我们会收到慢调用告警,网关跟 Product 的响应时间都发生了大于一秒的告警。接下来我们看一下根因定位,我们看到网关,发生了慢调用 P99 的响应时间暴增,然后看 Product 也发生了平均响应时间突增的问题,那就是刚才的服务慢调用了,然后我们进一步看 Product 的下游,依赖了 Nacos、Redis 、MySQL 这三个服务,可以发现慢调用是比较明显的,然后我们查看它的下游时就发现了 Product 调 MySQL 的时候发生了比较严重的慢调用,同时它的 RTT 跟重传现象也很明显。

正常情况下 RTT 是很平稳的。它反映的是上下游之间的往返的时间,如果它都上涨非常快,基本上可以认定为它是网络问题,所以说可以看到就是这里面有三条,从网关、Product、MySQL,从这里我们可以总结到就是通过这种识别关键路径,然后在拓扑上面去配置告警的这种方法可以非常快的去定位问题,不需要去查证很多散落在各个地方的信息。我们只需要去在这条拓扑上面去树藤摸瓜的去查看对应的性能指标,网络指标等等,快速定位到问题所在。所以,这就是我们黄金信号 + 资源指标 + 资源拓扑定位像慢调用这种异常的最佳实践。
最后总结下本次最佳实践:
1、 通过默认告警主动发现异常,默认告警模板涵盖 RED,常见资源类型指标。除了默认下发的告警规则,用户还可以基于模板定制化配置。
2、 通过黄金信号和资源指标发现、定位异常,同时 Trace 配合下钻定位根因。
3、 通过拓扑图做上下游分析、依赖分析、架构感知,有利于从全局视角审视架构,从而得到最优解,做到持续改善,构建更稳定的系统。
原文链接
本文为阿里云原创内容,未经允许不得转载。
如何使用 Kubernetes 监测定位慢调用的更多相关文章
- php快速定位当前调用的类的位置
php快速定位当前调用的类的位置 $func = new ReflectionMethod('类名', '方法名'); $start = $func->getStartLine() - 1; $ ...
- Kubernetes 问题定位技巧:分析 ExitCode
使用 kubectl describe pod 查看异常的 pod 的状态,在容器列表里看 State 字段,其中 ExitCode 即程序退出时的状态码,正常退出时为0.如果不为0,表示异常退出,我 ...
- SQL Server如何定位自定义标量函数被那个SQL调用次数最多浅析
前阵子遇到一个很是棘手的问题,监控系统DPA发现某个自定义标量函数被调用的次数非常高,高到一个离谱的程度.然后在Troubleshooting这个问题的时候,确实遇到了一些问题让我很是纠结,下文是解决 ...
- Kubernetes调用vSphere vSAN做持久化存储
参考 1.vSphere Storage for Kubernetes 2.IBM vSphere Cloud Provider 3.GitHub vSphere Volume examples 一. ...
- 通过Kubernetes监控探索应用架构,发现预期外的流量
大家好,我是阿里云云原生应用平台的炎寻,很高兴能和大家一起在 Kubernetes 监控系列公开课上进行交流.本次公开课期望能够给大家在 Kubernetes 容器化环境中快速发现和定位问题带来新的解 ...
- Kubernetes HPA
简介 通过手工执行 kubectl scale 命令或者通过修改deployment的replicas数量,可以实现 Pod 扩容或缩容.但如果仅止于此,显然不符合 Google 对 Kubernet ...
- Kubernetes 实战 —— 01. Kubernetes 介绍
简介 P2 Kubernetes 能自动调度.配置.监管和故障处理,使开发者可以自主部署应用,并且控制部署的频率,完全脱离运维团队的帮助. Kubernetes 同时能让运维团队监控整个系统,并且在硬 ...
- 如何发现 Kubernetes 中服务和工作负载的异常
大家好,我是来自阿里云的李煌东,今天由我为大家分享 Kubernetes 监控公开课的第二节内容:如何发现 Kubernetes 中服务和工作负载的异常. 本次分享由三个部分组成: 一.Kuberne ...
- swift 定位
iOS 8 及以上需要在info.plist文件中添加下面两个属性 NSLocationWhenInUseUsageDescription 使用应用期间 NSLocationAlwaysUsageDe ...
- iOS开发——高级技术&调用地图功能的实现
调用地图功能的实现 一:苹果自带地图 学习如逆水行舟,不进则退.古人告诉我们要不断的反思和总结,日思则日精,月思则月精,年思则年精.只有不断的尝试和总结,才能让我们的工作和生活更加 轻松愉快和美好.连 ...
随机推荐
- MapStructPlus 1.2.5 发布,新增 Solon 支持
MapStructPlus 1.2.5 发布,更新内容如下: fix: 解决 MapConvertMapperAdapter 编译警告问题 feat: 增加 nullValueMappingStrat ...
- 自定义Key类型的字典无法序列化的N种解决方案
当我们使用System.Text.Json.JsonSerializer对一个字典对象进行序列化的时候,默认情况下字典的Key不能是一个自定义的类型,本文介绍几种解决方案. 一.问题重现 二.自定义J ...
- 摄像头网页预览,不需安装插件,支持Chrome
背景 实在是不想折腾ActiveX控件 1.麻烦(开发麻烦.使用时设置也麻烦) 2.非IE浏览器不兼容 解决方案 写一个摄像头服务,提供http服务,返回摄像头当前画面的Base64字符串,前端页面调 ...
- 2024 VEXIQ 赛季笔(游)记 Pt.1
2024/03/07 老师让我们做机器初步思考了. 搞搞戒指,只要一个小夹子加上赛季的抬升吸环改一下就可以了,方便的一批. 于是夹子 10 分钟不到搞完了,现在是缝合怪时间. 但是老师下课不让我搞了 ...
- 冲刺 NOIP2024 之动态规划专题
专题链接 B - Birds \(3.19\) . 混合背包 \(DP\) . 定义 \(f_{i,j}\) 表示取到鸟巢 \(i\) ,获得 \(j\) 只小鸟时所剩的魔力值. 显然有 \(f_{0 ...
- #位运算#CF959E Mahmoud and Ehab and the xor-MST
题目 \(n\)个点的完全图标号为\([0,n-1]\),\(i\)和\(j\)连边权值为\(i\: xor\:j\),求MST的值 分析 考虑MST有两种解法一种是Prim一种是Kruskal,Pr ...
- OpenHarmony嵌套类对象属性变化:@Observed装饰器和@ObjectLink装饰器
上文所述的装饰器仅能观察到第一层的变化,但是在实际应用开发中,应用会根据开发需要,封装自己的数据模型.对于多层嵌套的情况,比如二维数组,或者数组项class,或者class的属性是class,他们的第 ...
- OpenHarmony社区运营报告(2023年7月)
本月快讯 • 2023年7月28日-29日,全球软件质量&效能大会(简称"QECon")圆满举行,OpenAtom OpenHarmony(简称"OpenHar ...
- [一本通1681]统计方案 题解(Meet in mid与逆元的结合)
题目描述 小\(B\)写了一个程序,随机生成了\(n\)个正整数,分别是\(a[1]-a[n]\),他取出了其中一些数,并把它们乘起来之后模\(p\),得到了余数\(c\).但是没过多久,小\(B\) ...
- Go 语言数组基础教程 - 数组的声明、初始化和使用方法
数组用于在单个变量中存储相同类型的多个值,而不是为每个值声明单独的变量. 声明数组 在Go中,有两种声明数组的方式: 使用var关键字: 语法 var array_name = [length]dat ...