[转帖]可直接拿来用的kafka+prometheus+grafana监控告警配置
kafka配置jmx_exporter
点击:https://github.com/prometheus/jmx_exporter,选择下面的jar包下载:

将下载好的这个agent jar包上传到kafka的broker节点所在服务器上,每个broker都需要,比如上传到如下路径:
/opt/agent/jmx_prometheus_javaagent-0.16.1.jar
修改kafka启动脚本: bin/kafka-server-start.sh,增加java agent配置如下:
-
JMX_EXPORTER_OPTS="-javaagent:/opt/agent/jmx_prometheus_javaagent-0.16.1.jar=9095:/opt/agent/kafka_broker.yml"
-
export KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS $JMX_EXPORTER_OPTS"
这两行代码可以添加在脚本首部。
这里指定了9095作为端口,jmx_exporter用到的kafka_broker.yml 配置如下:https://github.com/xxd763795151/kafka-exporter/blob/main/kafka_broker.yml
将kafka每个broker都这样配置,重启kafka。
Prometheus配置
修改prometheus的配置prometheus.yml,增加如下配置:
-
- job_name: 'kafka'
-
metrics_path: /metrics
-
static_configs:
-
- targets: ['kafka1:9095', 'kafka2:9095', 'kafka3:9095']
-
labels:
-
env: "test"
p.s. 注意job_name不要修改,值就是"kafka",要不我下面的grafana不能直接用,还需要每个面板依次修改。
Grafana配置
下面的Grafana面板我已经配置好,可以直接拿来用,之后可以根据需要增加或删除相关面板:https://github.com/xxd763795151/kafka-exporter/blob/main/grafana.json
贴几个截图:
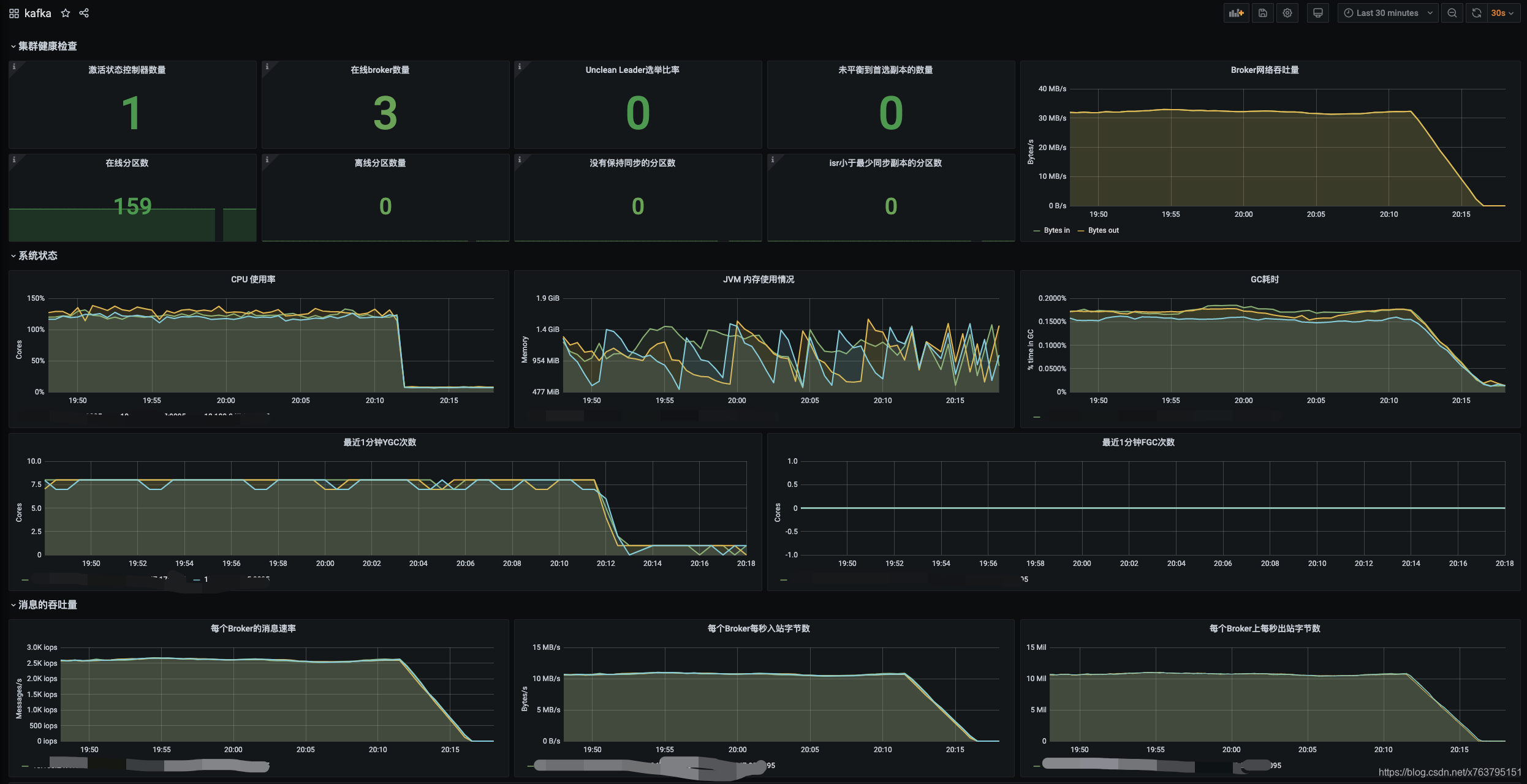
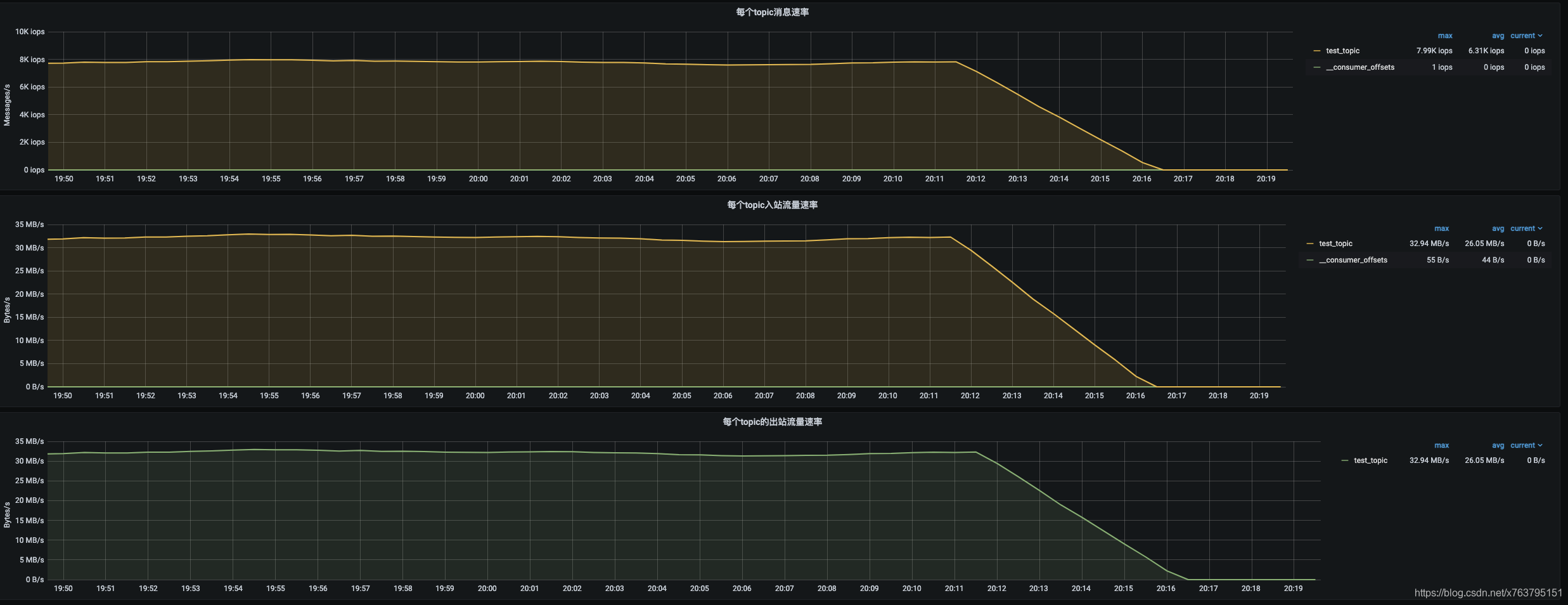

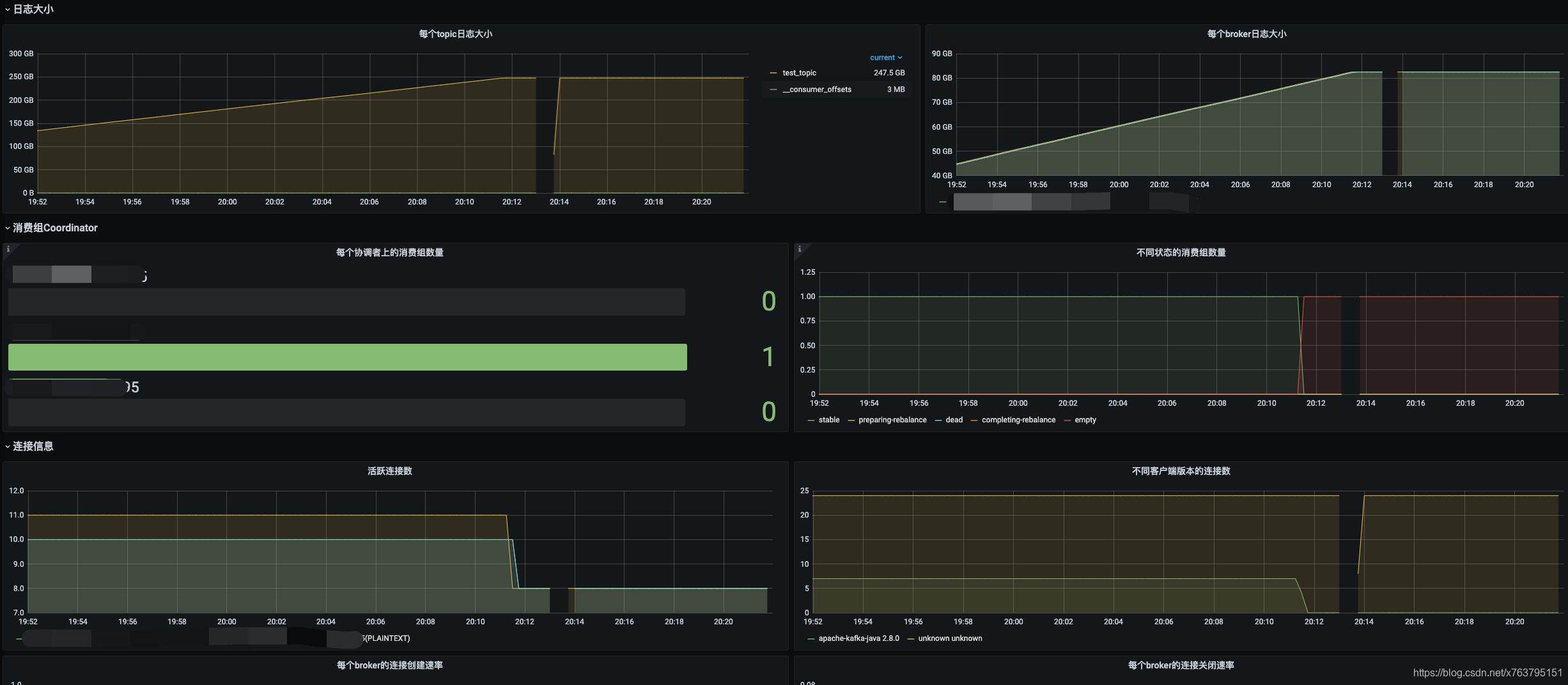
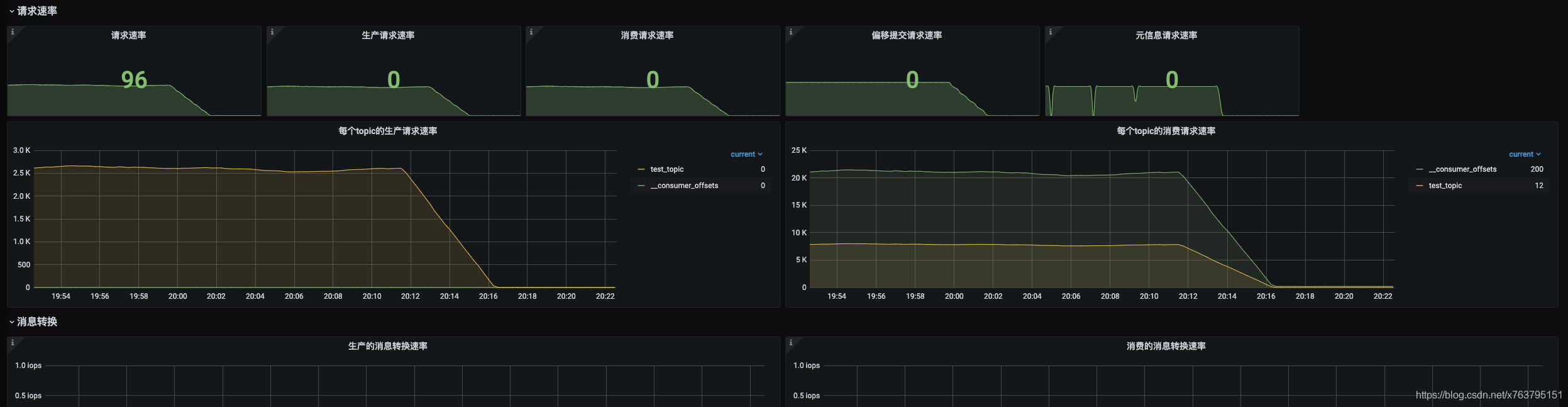
消息积压
在kafka的broker端无法直接获取消息积压等指标信息,这些数据在消费端上,我们也不太可能去连接所有的消费端获取监控信息。
所以,我单独写了一个kafka-exporter可以获取消息积压的监控指标:https://github.com/xxd763795151/kafka-exporter
点击这个链接进入github仓库后,根据说明进行部署并配置启动后,然后在prometheus.yml增加如下配置:
-
- job_name: 'kafka-exporter'
-
metrics_path: /prometheus
-
static_configs:
-
- targets: ['kafka-expoter-host:9097']
-
labels:
-
env: "test"
上面的grafana配置里已经包含了消息积压的面板:
 如果后续有其它指标在jmx里不提供,也可以继续补充kafka-exporter,刮取更多需要的metrics。
如果后续有其它指标在jmx里不提供,也可以继续补充kafka-exporter,刮取更多需要的metrics。
告警
最新的配置代码会提交在这里: https://github.com/xxd763795151/kafka-exporter/blob/main/kafka_alert.yml
示例如下:

末语
我从grafana 官方上搜索了几个dashboard,但指标实在太少。感谢从这篇博文里找到的grafana配置可以参考,提供了很多指标的面板,可以让我对着kafka官方监控jmx说明进行整理,让我在grafana面板的配置上,省了一半的功夫:
https://www.confluent.io/blog/monitor-kafka-clusters-with-prometheus-grafana-and-confluent/
[转帖]可直接拿来用的kafka+prometheus+grafana监控告警配置的更多相关文章
- [转帖]Prometheus+Grafana监控Kubernetes
原博客的位置: https://blog.csdn.net/shenhonglei1234/article/details/80503353 感谢原作者 这里记录一下自己试验过程中遇到的问题: . 自 ...
- [转帖]安装prometheus+grafana监控mysql redis kubernetes等
安装prometheus+grafana监控mysql redis kubernetes等 https://www.cnblogs.com/sfnz/p/6566951.html plug 的模式进行 ...
- [转帖]插曲:大白话带你认识Kafka
插曲:大白话带你认识Kafka 2019-11-18 21:58:27 从事Java 阅读数 2更多 分类专栏: java Kafaka 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA ...
- [转帖]基于docker 搭建Prometheus+Grafana
基于docker 搭建Prometheus+Grafana https://www.cnblogs.com/xiao987334176/p/9930517.html need good study 一 ...
- [转帖]Linux网络管理员不得不了解的系统目录/proc/sys/net/(网络配置)
Linux网络管理员不得不了解的系统目录/proc/sys/net/(网络配置) https://blog.csdn.net/u013485792/article/details/76416836 需 ...
- [ZZ] [精彩盘点] TesterHome 社区 2018年 度精华帖
原文地址: https://testerhome.com/topics/17646 相逢即是缘分,总有一篇适合您! 感觉好的请点赞收藏 ,感觉分类不严谨的,欢迎反馈给我! 测试方法&测试管理 ...
- 《转》Spring4 Freemarker框架搭建学习
这里原帖地址:http://www.cnblogs.com/porcoGT/p/4537064.html 完整配置springmvc4,最终视图选择的是html,非静态文件. 最近自己配置spring ...
- Windows 7 封装与定制不完全教程
Windows 7 封装与定制不完全教程 从定制Win7母盘到封装详细教程 手把手教你定制WIN7小母盘 Windows 7 封装与定制不完全教程 [教程] Windows 7 封装与定制不完全教程( ...
- Open Source
资源来源于http://www.cnblogs.com/Leo_wl/category/246424.html RabbitMQ 安装与使用 摘要: RabbitMQ 安装与使用 前言 吃多了拉就是队 ...
- 你都用python来做什么?
首页发现话题 提问 你都用 Python 来做什么? 关注问题写回答 编程语言 Python 编程 Python 入门 Python 开发 你都用 Python 来做什么? 发现很 ...
随机推荐
- vivo 海量微服务架构最新实践
作者:来自 vivo 互联网中间件团队 本文根据罗亮老师在"2023 vivo开发者大会"现场演讲内容整理而成.公众号回复[2023 VDC]获取互联网技术分会场议题相关资料. v ...
- POJ 3003 DP 寻路 记录路径
POJ 3003 DP 寻路 记录路径 我一开始把M看成是每个a_i的上限了,这是致命的,因为这个题dfs暴力搜索+剪枝是过不了的因为M<=40,全部状态有2的四十次幂. 正解是DP,设dp[i ...
- 云图说|一张图看懂一站式DevOps利器——华为云DevCloud
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要: 华为云DevCl ...
- 云图说|云上应用监控神器——应用性能监控APM2.0
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要: 应用性能管理服务 ...
- 华为云GaussDB(for Influx)揭秘第五期:最佳实践之子查询
摘要: GaussDB(for influx)提供灵活的子查询能力,满足海量数据场景下的高性能查询需求. 本文分享自华为云社区<华为云GaussDB(for Influx)揭秘第五期:最佳实践之 ...
- 一文带你从零认识什么是XLA
摘要:简要介绍XLA的工作原理以及它在 Pytorch下的使用. 本文分享自华为云社区<XLA优化原理简介>,作者: 拓荒者01. 初识XLA XLA的全称是Accelerated Lin ...
- 火山引擎 VeDI 零售行业解决方案 聚焦精准营销场景提升品牌转化
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 你知道,为了能让你买到合适的商品,品牌商们有多努力吗? 精准营销并不是一个新词,但近年来,随着营销渠道/平台的更加 ...
- Solon Aop 特色开发(2)注入或手动获取Bean
Solon,更小.更快.更自由!本系列专门介绍Solon Aop方面的特色: <Solon Aop 特色开发(1)注入或手动获取配置> <Solon Aop 特色开发(2)注入或手动 ...
- Mac 复制文件名目录路径
Mac快速复制文件路径 在Mac电脑上,我们经常需要复制文件的路径,其实,Mac系统提供了快速复制文件路径的方法.下面我们来详细介绍. 方法一:使用菜单栏 首先,打开Finder,然后选择你要复制路径 ...
- Mac下安装mysqlclient出错解决「mysql_config not found」
错误信息如下图 解决方法 安装mysql-client brew install mysql-client 设置环境变量 export PATH=$PATH:/usr/local/Cellar/mys ...