TF-VAEGAN:添加潜在嵌入(Latent Embedding)的VAEGAN处理零样本学习
前面介绍了将VAE+GAN解决零样本学习的方法:f-VAEGAN-D2,这里继续讨论引入生成模型处理零样本学习(Zero-shot Learning, ZSL)问题。论文“Latent Embedding Feedback and Discriminative Features for Zero-Shot Classification”提出TF-VAEGAN,以f-VAEGAN-D2为Baseline进行改进。
引言
动机
一些工作利用辅助模块(如Decoder)在训练期间对语义嵌入重建实现循环一致(cycle-consistency)约束,帮助生成器合成语义一致的特征。但这些辅助模块仅在训练中使用,在调整合成与分类预测阶段被丢弃。既然辅助模块在训练中帮助生成器,作者希望能在调整合成阶段帮助生成判别性的特征,减少不同类之间的歧义促进分类。因此作者在文中,增强了特征合成与零样本分类。
此外,为了保证生成的特征语义上尽可能与真实特征分布相近,训练时,对生成特征与原始特征使用循环一致(cycle-consistency)损失。对于语义嵌入也使用类似的一致损失,并在特征合成与分类期间进一步学习。
贡献
在VAEGAN架构的基础上增加一个语义嵌入解码器(Semantic Embedding Decoder, SED),并且:
- 增加了一个用于(广义)零样本学习的反馈模块(feedback module),该模块在训练和合成调整阶段均使用SED。反馈模块首先转换SED的潜在嵌入,然后生成潜在表征供生成器使用。作者表示自己是第一个提出反馈模块用于(广义)零样本学习,而之前的反馈模块用于图像超分辨率。
- 在分类阶段引入判别特征转换(discriminative feature transformation),转换会利用SED的潜在嵌入及相应的视觉特征来减少对象类别之间的歧义。
最后,作者在4个图像数据集、2个视频数据集进行了测试。
方法
设置
- \(x\in\mathcal{X}\)为图像(视频)特征实例;
- \(y\in\mathcal{Y}^s\)为相应的标签,标签集合含\(M\)个可见类,即\(\mathcal{Y}^s=\{y_1\dots,y_M\}\);
- \(\mathcal{Y}^u=\{u_1\dots,u_N\}\)表示\(N\)未见类,并且\(\mathcal{Y}^s\cap\mathcal{Y}^u=\varnothing\);
- 描述类的特定语义嵌入\(a(k)\in\mathcal{A},\forall k\in\mathcal{Y}^s\cup\mathcal{Y}^u\);
- 对于无标签的测试数据\(x_t\in\mathcal{X}\)不在归纳ZSL中使用,仅在转导ZSL中使用;
- ZSL和GZSL的任务目的是分别学习分类器\(f_{zsl}:\mathcal{X}\to\mathcal{Y}^u\ \text{and}\ f_{gzsl}:\mathcal{X}\to\mathcal{Y}^s\cup\mathcal{Y}^u\)。在此之前,首先使用可见类特征\(x_s\)和相应嵌入\(a(y)\)合成特征。然后使用后学习到的模型使用未见类嵌入\(a(u)\)合成特征\(\hat{x}_u\)。结果得到的\(\hat{x}_u\)与\(x_s\)将用来训练分类器\(f_{zsl}\)和\(f_{gzsl}\)。
Baseline:f-VAEGAN-D2
此处再复述一遍f-VAEGAN-D2的损失函数设置。对于VAE部分的Encoder设置为\(E(x,a)\) ,它将输入特征x计算为潜在表征z,使用解码器\(G(z,a)\)从z重构x(解码器与WGAN共享作为条件生成器)。对于E和G,以嵌入a作为条件,VAE优化函数为
\]
KL表示KL散度,\(p(z|a)\)表示先验分布假设为\(\mathcal{N}(0,1)\),\(\log G(z,a)\)为重构损失。对于WGAN部分,有着生成器\(G(z,a)\)和判别器\(D(x,a)\)。G从随机噪声z合成特征\(\hat{x}\in\mathcal{X}\),D对于输出的x输出实数,表示x是真实还是合成的概率,对于G和D,以嵌入a作为条件,优化函数为WGAN损失
\]
\(\begin{aligned}\hat{x}=G(z,a)\end{aligned}\)是合成特征,\(\lambda\)是惩罚系数,\(\tilde{x}\)为\(x\)和\(\hat{x}\)的随机插值。令\(\alpha\)为超参数,整体的优化函数为
\]
局限
公式(1)第2项训练时,保证生成的特征与原始视觉特征循环一致(cyclically-consistent)。但在语义嵌入上并没有这种循环一致(cycle-consistency)约束,而其他通过辅助模块(除了生成器)在嵌入上实现循环一致的方法,仅作用在了训练,而在合成特征与分类阶段丢弃了辅助模块。
因此,在该论文,作者引入SED在训练、合成特征和分类阶段对语义嵌入实现循环一致约束,让生成器与SED互补学习并减少ZSL分类过程的歧义。
整体框架
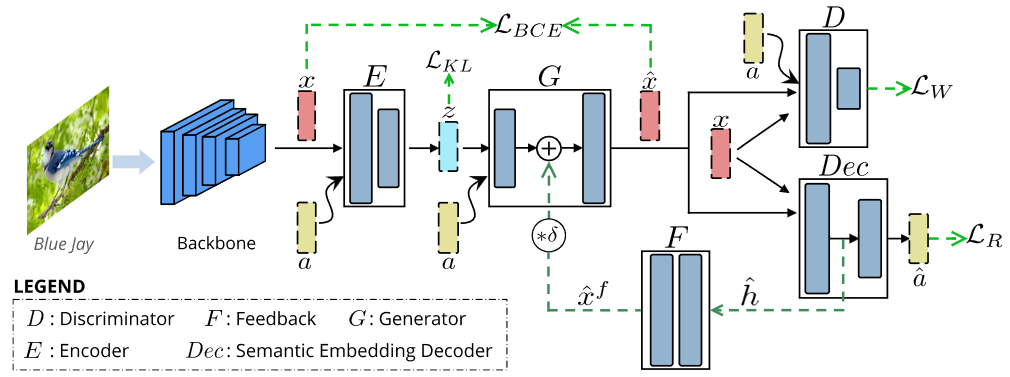
对于给出的图片,骨干网络提取特征x与相应的语义嵌入a输入编码器E。E输出潜在表征z,z与a输入生成器G合成特征\(\hat{x}\)。判别器D学习区分真实特征x与合成特征\(\hat{x}\)。
E与G构成VAE使用二元交叉熵损失(\(\mathcal{L}_{BCE}\))和KL散度优化(\(\mathcal{L}_{KL}\))。G与D构成WGAN,使用WGAN损失\(\mathcal{L}_{W}\)优化。此外,加入了反馈模块F转换Dec(也就是SED)输出的潜在嵌入\(\hat{h}\),并喂入G,让G迭代细化\(\hat{x}\)。
Dec和反馈模块F在分类过程中,共同增强特征合成、减少类别间的歧义。Dec接受x与\(\hat{x}\),重构生成嵌入\(\hat{a}\)。使用循环一致损失\(\mathcal{L}_R\)训练。学习后的Dec将被用在ZSL/GZSL分类中。F转换Dec的潜在嵌入,反馈给G以实现改进的特征合成。
语义嵌入解码器(SED)
语义嵌入解码器\(Dec:\mathcal{X}\to\mathcal{A}\),对于生成特征\(\hat{x}\)重构语义嵌入\(a\)。为了循环一致性,保证生成语义一致的特征,使用L1重构损失。
\]
令\(\beta\)为解码器重构误差的权重超参数,整个TF-VAEGAN的优化函数为
\]
接下来介绍SED在分类过程中的重要性以及它在特征合成的作用。
判别特征转换(Discriminative Feature Transformation)
生成器G仅使用可见类特征和嵌入来学习每个类的“单个语义嵌入到多个实例”映射。与G类似,SED也仅使用可见的类进行训练,但学习每个类的“多个实例到一个嵌入”逆映射,实现互补学习。如下图(a)所示,使用SED的潜在嵌入(\(x\oplus h\))作为分类阶段的重要信息源以减少特征间的歧义。
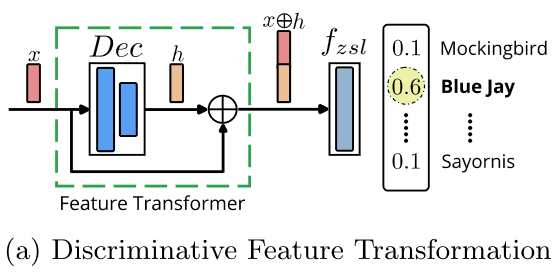
Dec在分类阶段,通过输入特征\(x\)与相应的潜在嵌入\(h\)进行连接操作\(\oplus\),即特征转换(Transformation),然后将转换后的特征用于ZSL/GZSL分类。
首先进行G和Dec的训练。然后使用Dec将(合成或真实)特征转换到嵌入空间\(\mathcal{A}\)(也就是框架图中Dec生成的\(\hat{a}\))。再然后将Dec中间的潜在嵌入与视觉特征连接。令\(h_s,\hat{h}_s\in\mathcal{H}\)表示Dec潜在嵌入,输入为\(x_s,\hat{x}_s\)分别实现转换:\(x_s\oplus h_s\)或\(\hat{x}_u\oplus \hat{x}_u\)。转换的特征用于学习分类器:
\]
接下来介绍Dec在特征合成阶段的使用。
反馈模块(Feedback Module)

\(\bigstar,\blacktriangle,\boldsymbol{\bullet}\)表示3种类。生成特征\(\hat{x}\)由类特定嵌入a通过生成器G合成.\(\hat{a}\)由SED重构得到,并用于进一步加强合成特征\(\hat{x}_e\)。
f-VAEGAN-D2使用生成器直接通过类嵌入a合成特征\(\hat{x}\)(如(a)所示),这会造成真实与合成特征间存在gap。为此引入了一个反馈循环,在训练与合成特征阶段迭代优化特征生成(如(b)所示)。反馈回路由Dec到G,经过反馈模块F。F能在训练和合成阶段有效利用Dec。
令\(g^l\)表示G的第\(l\)层输出;\(\hat{x}^f\)表示加入了\(g^l\)的反馈结果,反馈的输出可表示为
\]
其中\(\hat{x}^f=F(h)\),h为Dec的潜在表征,\(\delta\)为控制模块的参数。然而,对于未见类,合成的特征不太可靠,作者对反馈循环进行了改进。
反馈模块的输入
ZSL中,判别器D是需要条件的,目的是为了区分可见类的真假特征,而未见类图像没有相应的嵌入(也就是转导的图像没有标签、语义嵌入配对)。这时需要Dec,它通过将实例的图像转为类相关的语义嵌入,Dec比D更适合向G提供反馈,Dec的结果更适合作为反馈的输入。
训练策略
首先通过标准的GAN训练方式,对G和D经过全面训练。然后使用D和冻结的G对F进行训练。G的输出由于F的反馈得到改善,D和F得到进一步对抗训练。由于G被固定没对特征合成作出改进,这种训练不是最优的。为了进一步利用反馈改进合成,采用了迭代交替训练G和F。迭代中,G的训练不变,而F含两个子迭代(如下图所示)。
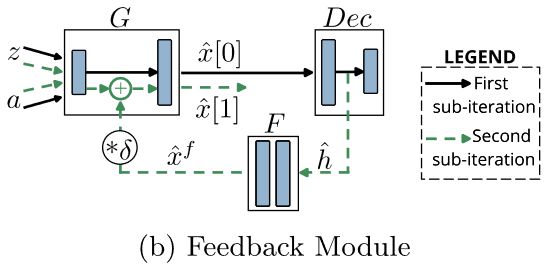
- 第一次子迭代:噪声z与语义嵌入a输入G,得初始合成特征\(\hat{x}[0]=G(z,a)\),并输入Dec。
- 第二次子迭代:Dec的结果\(\hat{h}\)输入F,得到\(\hat{x}^f[t]=F(\hat{h})\),并通过式(6)加入G的潜在表征,在第一次子迭代用过的z和a与\(\hat{x}^f[t]\)输入G合成\(\hat{x}^f[t+1]\)。
\]
\(\hat{x}[t+1]\)输入Dec与D,使用式(4)训练。实践中第二次子迭代仅发生一次(t=0)。F让G学习Dec的h,从而增强特征的生成。
(广义)零样本分类
以上还没涉及转导的未见类图像,在Tf-VAEGAN中,通过输入嵌入\(a(u)\)和z到G:\(\hat{x}_u=G(z,a(u),\hat{x}^f[0])\)。合成的未见类特征\(\hat{x}\)与真实特征\(x_s\)分别输入Dec得到潜在特征并连接,即\(x_s\oplus h_s\)或\(\hat{x}_u\oplus \hat{x}_u\),并分别用于训练分类器\(f_{zsl}\)或\(f_{gzsl}\)。对测试样本\(x_t\)也是同样处理方式:\(x_t\oplus h_t\),然后对它进行预测。
实验
实现细节
判别器D、编码器E和生成器G由4096个隐藏单元的两层全连接 (Fully-connected, FC)网络实现。加入无条件判别器D2(架构图中为画出,可参考f-vAEGAN-D2)。许多设置于f-VAEGAN-D2的论文一致,如z与a的维度相同(\(d_z=d_a\))这里不再赘述。
泛化能力
作者将SED加入到f-CLSWGAN并于原始f-CLSWGAN对比证明,该模块可以迁移到不同架构并提高性能。
特征可视化

参考文献
- Narayan, Sanath, et al. "Latent embedding feedback and discriminative features for zero-shot classification." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16. Springer International Publishing, 2020.
TF-VAEGAN:添加潜在嵌入(Latent Embedding)的VAEGAN处理零样本学习的更多相关文章
- 词向量 词嵌入 word embedding
词嵌入 word embedding embedding 嵌入 embedding: 嵌入, 在数学上表示一个映射f:x->y, 是将x所在的空间映射到y所在空间上去,并且在x空间中每一个x有y ...
- 潜在语义分析Latent semantic analysis note(LSA)原理及代码
文章引用:http://blog.sina.com.cn/s/blog_62a9902f0101cjl3.html Latent Semantic Analysis (LSA)也被称为Latent S ...
- [DeeplearningAI笔记]序列模型2.1-2.2词嵌入word embedding
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.1词汇表征 Word representation 原先都是使用词汇表来表示词汇,并且使用1-hot编码的方式来表示词汇 ...
- 零基础学习java------36---------xml,MyBatis,入门程序,CURD练习(#{}和${}区别,模糊查询,添加本地约束文件) 全局配置文件中常用属性 动态Sql(掌握)
一. xml 1. 文档的声明 2. 文档的约束,规定了当前文件中有的标签(属性),并且规定了标签层级关系 其叫html文档而言,语法要求更严格,标签成对出现(不是的话会报错) 3. 作用:数据格式 ...
- AI人工智能专业词汇集
作为最早关注人工智能技术的媒体,机器之心在编译国外技术博客.论文.专家观点等内容上已经积累了超过两年多的经验.期间,从无到有,机器之心的编译团队一直在积累专业词汇.虽然有很多的文章因为专业性我们没能尽 ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- 小样本学习Few-shot learning
One-shot learning Zero-shot learning Multi-shot learning Sparse Fine-grained Fine-tune 背景:CVPR 2018收 ...
- Bert文本分类实践(三):处理样本不均衡和提升模型鲁棒性trick
目录 写在前面 缓解样本不均衡 模型层面解决样本不均衡 Focal Loss pytorch代码实现 数据层面解决样本不均衡 提升模型鲁棒性 对抗训练 对抗训练pytorch代码实现 知识蒸馏 防止模 ...
- 知识图谱顶会论文(ACL-2022) PKGC:预训练模型是否有利于KGC?可靠的评估和合理的方法
PKGC:预训练模型是否有利于KGC?可靠的评估和合理的方法 论文地址:Do Pre-trained Models Benefit Knowledge Graph Completion? A Reli ...
- 国内“谁”能实现chatgpt,短期穷出的类ChatGPT简评(算法侧角度为主),以及对MOSS、ChatYuan给出简评,一文带你深入了解宏观技术路线。
1.ChatGPT简介[核心技术.技术局限] ChatGPT(全名:Chat Generative Pre-trained Transformer),美国OpenAI 研发的聊天机器人程序 ,于202 ...
随机推荐
- 【内核】深入分析内核panic(二)--内核中的少林扫地僧-NMI Watchdog Timer
没有完美的代码 没有完美的人,更没有完美的代码.虽然教科书上说deadlock(死锁)多么不好不好,但是在现实生活中,很难把它完全消灭.假设不小心内核出现了deadlock,可能你得干瞪眼.CPU就在 ...
- 封装http并挂载到全局
https://www.bilibili.com/video/BV1BJ411W7pX?p=32 具体使用:https://blog.csdn.net/weixin_44763569/article/ ...
- P1802-DP【橙】
1.又是一道因为写了异常剪枝而调了好久的题,以后再也不写异常剪枝了,异常情况压根不该出现,所以针对出现的异常情况进行补救的异常剪枝是一种很容易出错的行为,做为两手准备也就罢了,但第一次写成的代码必须能 ...
- Python数据可视化-动态柱状图可视化
Python数据可视化-动态柱状图可视化 一.基础柱状图 通过Bar构建基础柱状图 """ 演示基础柱状图的开发 """ from pyec ...
- 远程复制文件-scp
- Nginx的日志处理
Nginx的日志处理 背景 之前一直被各种咨询nginx的使用问题. 大部分都是性能, 加模块, 以及一些tcp端口等的问题. 其实这些都还好, 还有一个比较麻烦的问题时日志相关的. nginx的日志 ...
- [转帖]Oracle 19c 新特性|增加 VARCHAR2 数据类型的大小限制
JiekeXuAll China Database Union2022-10-13 795 经朋友介绍,我读完 Tim Hall 于 2022 年 9 月 27 日他的博客上发表的博文.10 月 11 ...
- [转帖]JVM随笔 --- 安全点(safe point)与 安全区域( safe region)
https://zhuanlan.zhihu.com/p/461298916 11 人赞同了该文章 最近回顾 JVM safe point 与 safe region 又有一些新的感悟与收获,特别写篇 ...
- 阿里云IPV6 创建虚拟机的过程
阿里云IPV6 创建虚拟机的过程 背景 IPV6 已经越来越广泛的应用. 想在外网开通一下IPV6,发现还有一些坑. 这里总结一下. 备忘. 开通方式 1. 登录阿里云的控制台, 打开云服务器ECS的 ...
- [转帖]Linux中查看各文件夹大小命令du -h --max-depth=1
https://www.cnblogs.com/the-tops/p/8798678.html 最近排查服务器异常的时候,常会遇到磁盘慢的情况,这个时候,查找那个文件夹占用的内存的时候常用到这个命令: ...