OpenTelemetry 深度定制:跨服务追踪的实战技巧
背景

在上一篇《从 Dapper 到 OpenTelemetry:分布式追踪的演进之旅》中在最后提到在做一些 Trace 的定制开发。
到现在差不多算是完成了,可以和大家分享一下。
我们的需求是这样的:
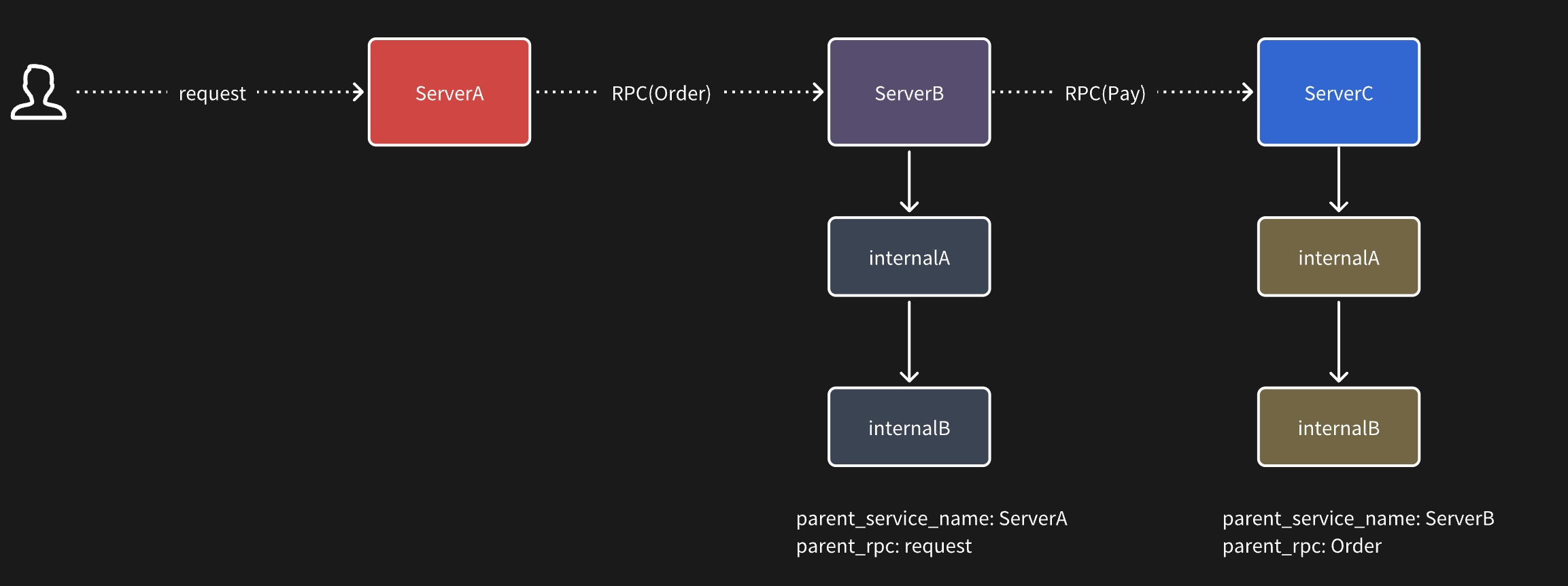
假设现在有三个服务:ServiceA、ServiceB、ServiceC
ServiceA 对外提供了一个 http 接口 request,在这个接口会调用 ServiceB 的 order 订单接口创建订单,同时 serviceB 调用 serviceC 的 pay 接口。
整个调用关系如上图所示。
默认情况下 span 中的 attribute 会记录当前 span 的一些信息,比如:
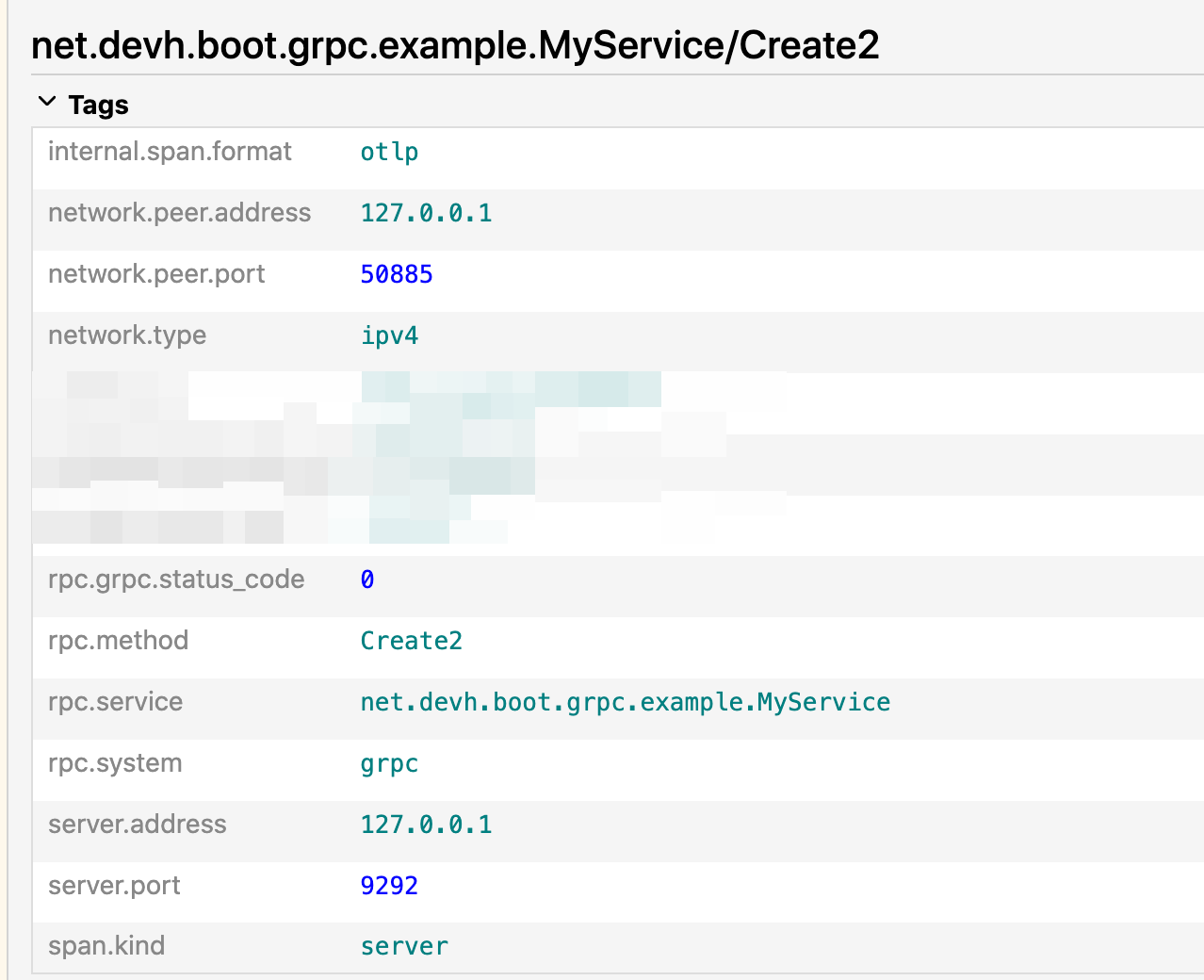
这些都是当前一些当前 span 内置的信息,比如当前 gRPC 接口的一些基本数据:服务名、ip、端口等信息。
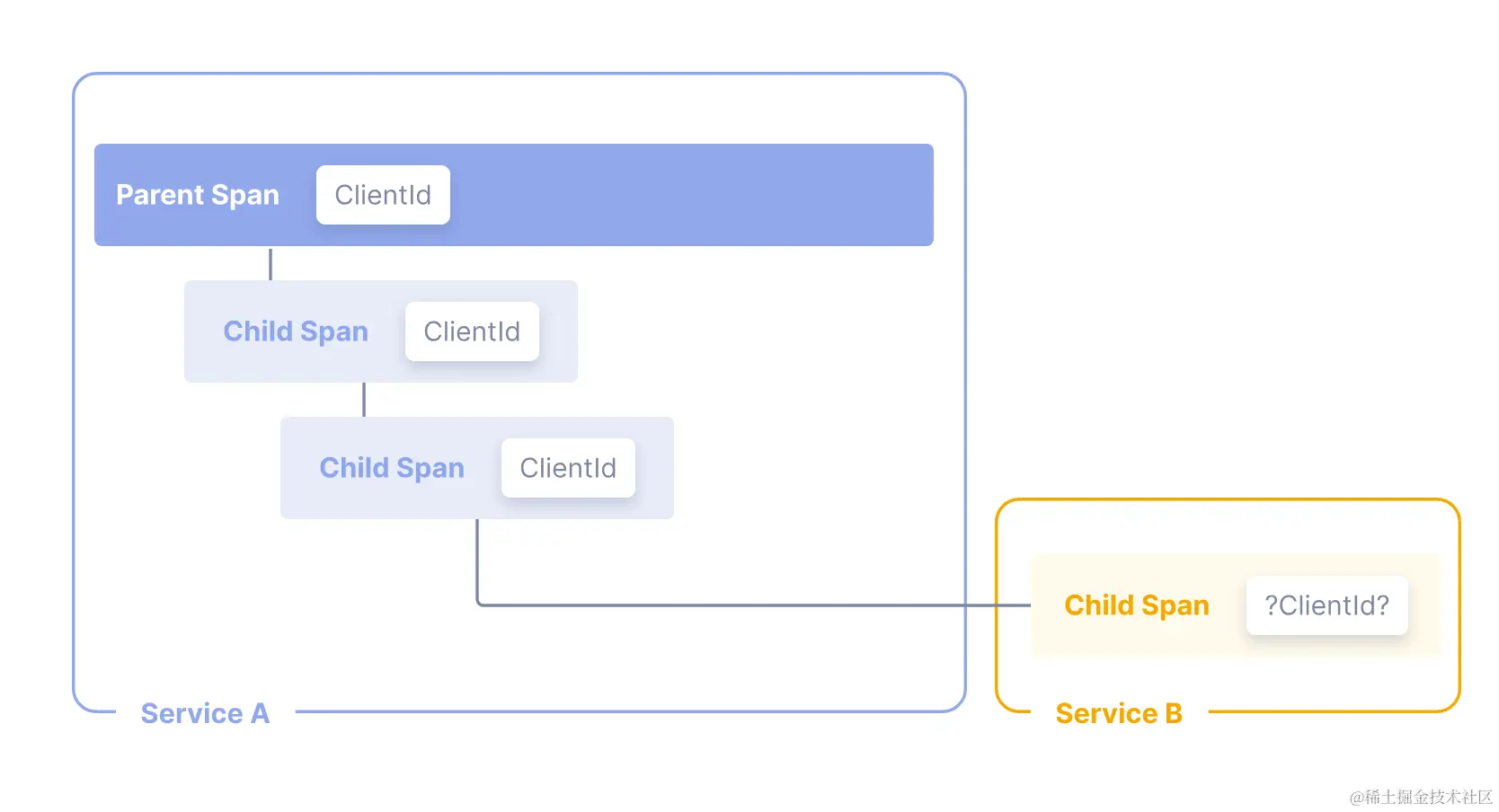
但这里并没有上游的一些信息,虽然我们可以通过 Jaeger 的树状图得知上游是哪个应用调用过来的,但是一旦某个 span 下有多个子 span 的调用,就没办法很直观知道这个子 span 的上游是由谁发起的调用。
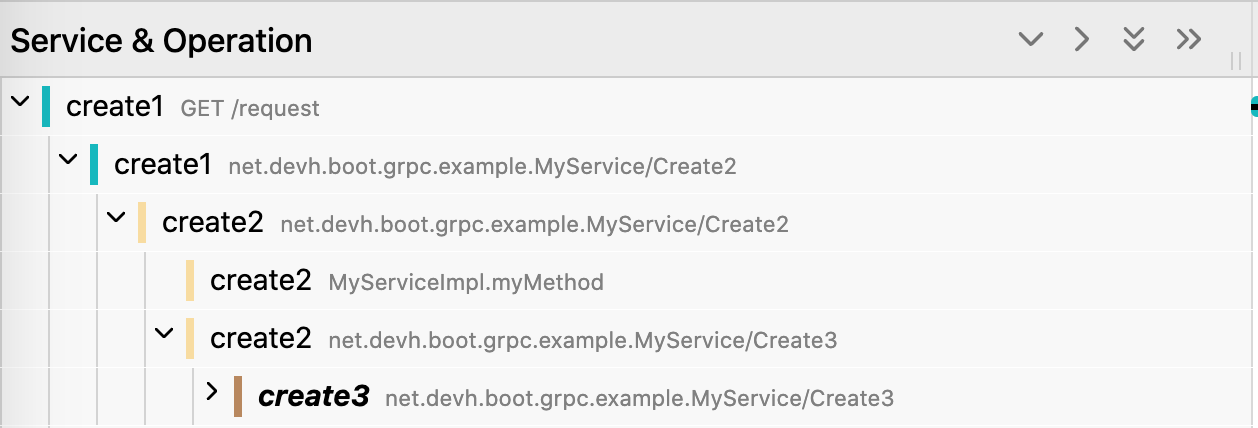
比如如下这个链路:
当一个调用链非常长,同时也非常复杂时,没办法第一时间知道某一个 span 的上游到底是谁发起的,需要手动一层层的去折叠,或者全靠眼睛去找。
预期效果
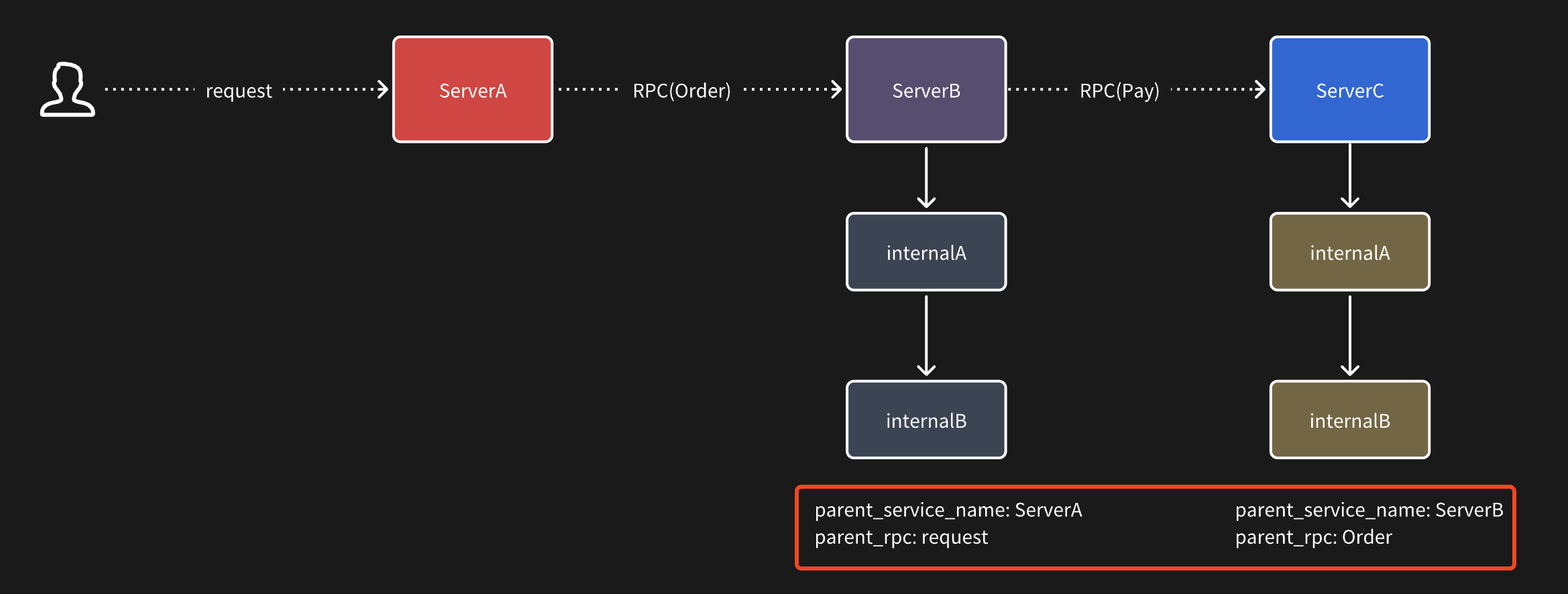
为此我们希望的效果是可以通过给每一个子 span 中加入两个 attribute,来标明它的父调用来源。
比如在 serviceB 中的所有 span 中都会加上两个标签:来源是 serviceA,同时是 serviceA 的 request 接口发起的请求。
而在 serviceC 中同样可以知道来源是 serviceB 的 Order 接口发起的调用。
我启动了三个 demo 应用,分别是 create1,create2,create3.
create1 中会提供一个 request 接口,在这里面调用 create2 的 create2 接口,create2 的接口里接着调用 create3 的 create3 接口。
create1:
@RequestMapping("/request")
public String request(@RequestParam String name) {
HelloRequest request = HelloRequest.newBuilder()
.setName(name)
.build();
log.info("request: {}", request);
String message = myServiceStub.create2(request).getMessage();
Executors.newFixedThreadPool(1).execute(() -> {
myServiceStub.create2(request).getMessage();
}); return message;
}
create2:
@Override
public void create2(HelloRequest request, StreamObserver<HelloReply> responseObserver) {
HelloReply reply = HelloReply.newBuilder()
.setMessage("Create2 ==> " + request.getName())
.build();
log.info("Create2: {}", reply.getMessage());
myMethod(request.getName());
myServiceStub.create3(request);
responseObserver.onNext(reply);
responseObserver.onCompleted();
}
create3:
@Override
public void create3(HelloRequest request, StreamObserver<HelloReply> responseObserver) {
HelloReply reply = HelloReply.newBuilder()
.setMessage("Create3 ==> " + request.getName())
.build();
log.info("Create3: {}", reply.getMessage());
myMethod(request.getName());
responseObserver.onNext(reply);
responseObserver.onCompleted();
}
java -javaagent:opentelemetry-javaagent-2.4.0-SNAPSHOT.jar \
-Dotel.javaagent.extensions=otel-extensions-custom-context-1.0-SNAPSHOT.jar \
-Dotel.traces.exporter=otlp \
-Dotel.logs.exporter=none \
-Dotel.service.name=create2 \
-Dotel.exporter.otlp.protocol=grpc \
-Dotel.propagators=tracecontext,baggage,demo \
-Dotel.exporter.otlp.endpoint=http://127.0.0.1:5317 \
-jar target/demo-0.0.1-SNAPSHOT.jar --spring.application.name=create2 --server.port=9191 --grpc.server.port=9292 --grpc.client.myService.address=static://127.0.0.1:9393
只是每个应用都需要使用我这边单独打的 agent 包以及一个 extension(tel-extensions-custom-context-1.0-SNAPSHOT.jar) 才能生效。
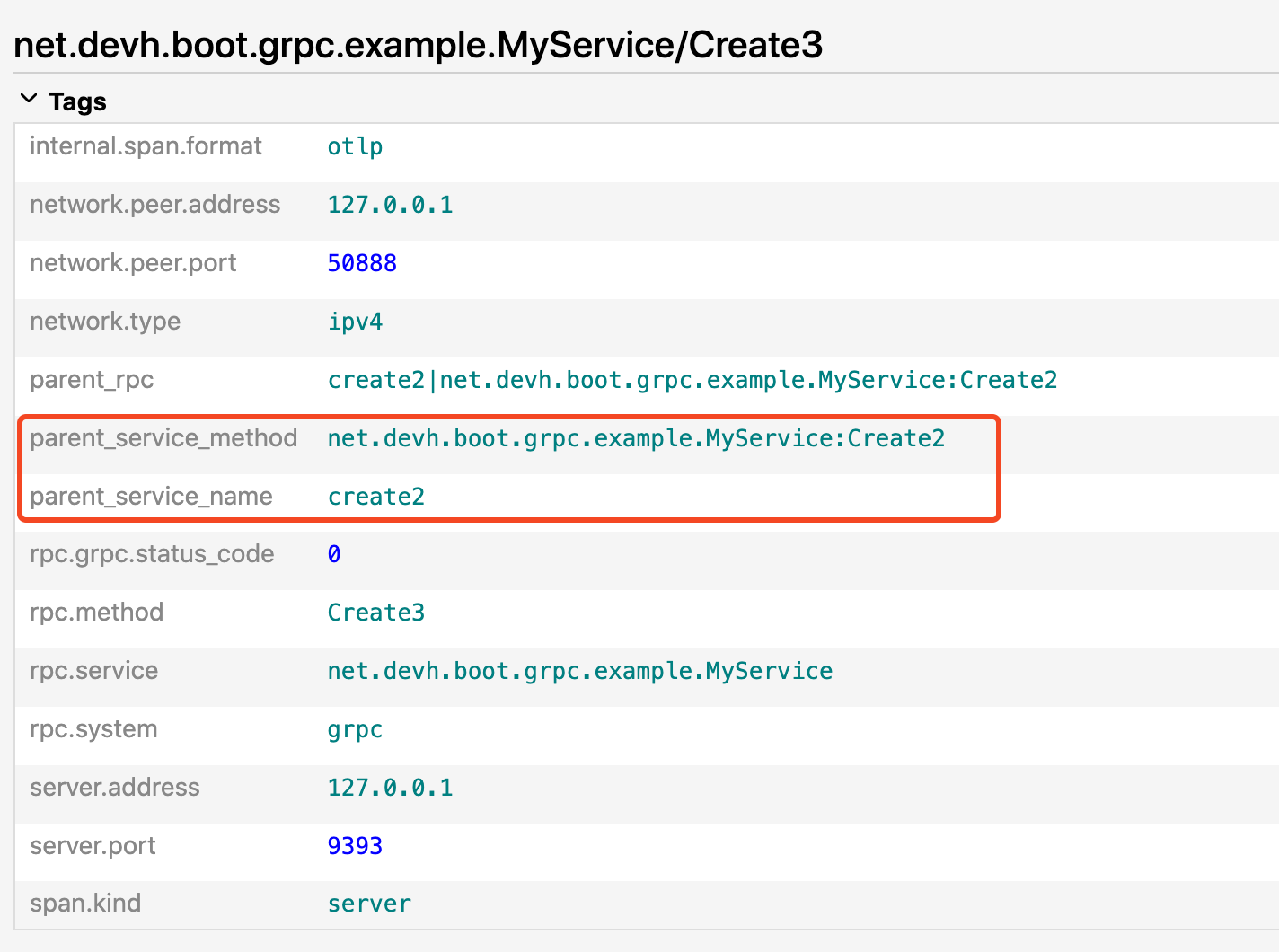
最终的效果如下:
Baggage
在讲具体的实现之前需要先了解几个 Trace 中的概念,在这里主要用到的是一个称为 Baggage 的对象。
在之前的文章中其实提到过它的原理以及使用场景:
从 Dapper 到 OpenTelemetry:分布式追踪的演进之旅
Baggage 的中文翻译是:包裹;简单来说就是我们可以通过自定义 baggage 可以将我们想要的数据存放在其中,这样再整个 Trace 的任意一个 Span 中都可以读取到。
@RequestMapping("/request")
public String request(@RequestParam String name) {
// 写入
Baggage.current().toBuilder().
put("request.name", name).build()
.storeInContext(Context.current()).makeCurrent();
}
// 获取
String value = Baggage.current().getEntryValue("request.name");
log.info("request.name: {}", value);
理解了这个之后,我们要实现的将上游的信息传递到下游就可以通过这个组件实现了。
只需要在上游创建 span 时将它自身数据写入到 Baggage 中,再到下游 span 取出来写入到 attribute 中即可。
ContextCustomizer
这里的关键就是在哪里写入这个 Baggage,因为对第三方组件的 Instrumentation 的实现都是在 opentelemetry-java-instrumentation项目中。
javaagent.jar 包也是通过该项目打包出来的。
所以在该项目的 io.opentelemetry.instrumentation.api.instrumenter.Instrumenter#doStart 这个函数中我们发现一段逻辑:
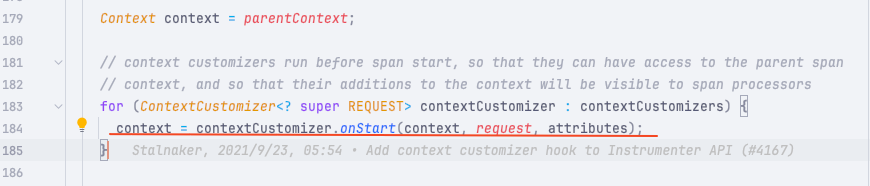
这个函数是在创建一个 span 的时候调用的,通常这个创建函数是在这些第三方库的拦截器中创建的。
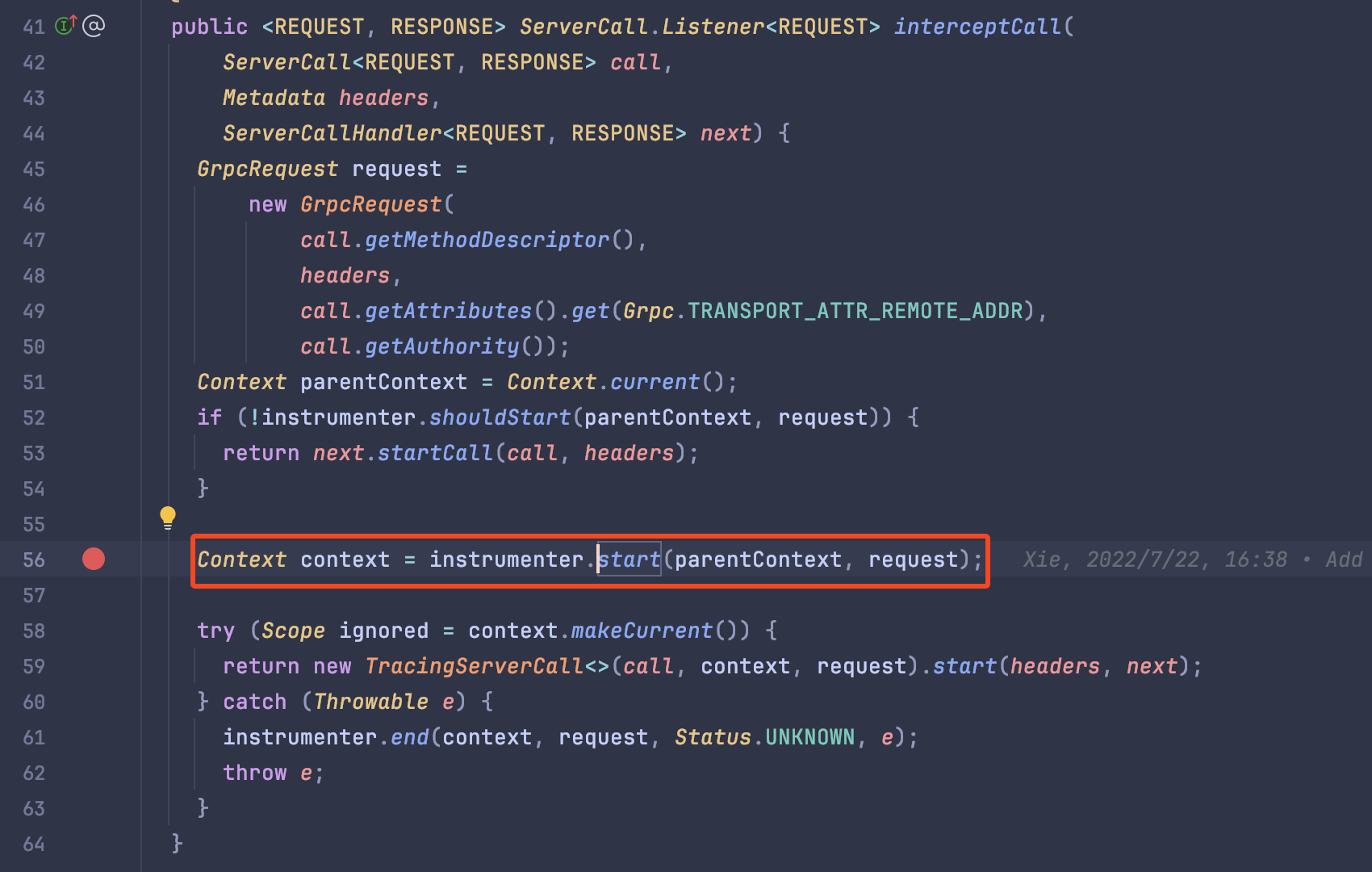
比如这是在 grpc 的拦截器中调用。
// context customizers run before span start, so that they can have access to the parent span
// context, and so that their additions to the context will be visible to span processors
for (ContextCustomizer<? super REQUEST> contextCustomizer : contextCustomizers) {
context = contextCustomizer.onStart(context, request, attributes);
}
ContextCustomizer 是一个接口只提供了一个函数:
public interface ContextCustomizer<REQUEST> {
/** Allows to customize the operation {@link Context}. */
Context onStart(Context parentContext, REQUEST request, Attributes startAttributes);
}
Context是上下文信息,可以在自定义的 ContextCustomizer 继续往上下文中追加信息。REQUEST是一个泛型:一般是当前第三方组件的请求信息:- 比如是
HTTP时,这个request就是 HTTP 的请求信息。 - 而如果是
gRPC,则是gRPC的请求信息。 - 其他的请求类型同理。
- 比如是
startAttributes则是预先写入的一些属性,比如在上图中看到的一些rpc.service/rpc.method等字段。
// context customizers run before span start, so that they can have access to the parent span
// context, and so that their additions to the context will be visible to span processors
从这个接口的调用注释可以看出:
这个自定义的 context 会在 span 开始之前调用,所以在这里是可以访问到当前创建的 span 的父 context,同时在这里的 context 中新增的数据可以在 SpanProcessor 访问到。
SpanProcessor
而 SpanProcessor 又是一个非常的重要的组件,我们接着刚才的 contextCustomizer 处往后跟踪代码。
context = contextCustomizer.onStart(context, request, attributes);
--->Span span = spanBuilder.setParent(context).startSpan();
--->io.opentelemetry.sdk.trace.SdkSpanBuilder#startSpan
--->io.opentelemetry.sdk.trace.SdkSpan#startSpan
--->spanProcessor.onStart(parentContext, span);
可以看到 spanProcessor.onStart 这个函数会在 contextCustomizer 之后调用。

/**
* SpanProcessor is the interface {@link SdkTracer} uses to allow synchronous hooks for when a
* {@code Span} is started or when a {@code Span} is ended.
*/
//==========================================================
/**
* Called when a {@link io.opentelemetry.api.trace.Span} is started, if the {@link
* Span#isRecording()} returns true.
* * <p>This method is called synchronously on the execution thread, should not throw or block the
* execution thread. * * @param parentContext the parent {@code Context} of the span that just started.
* @param span the {@code Span} that just started.
*/void onStart(Context parentContext, ReadWriteSpan span);
从注释中可以知道 SpanProcessor 是作为一个 span 的生命周期中的关键节点的 hook 函数。
在这些函数中我们可以自定义一些 span 的数据,比如在 onStart 还可以往 span 中写入一些自定义的 attribute。
这也是我们这次会用到的一个接口,我们的方案是:
在 gRPC 构建 Instrument 时自定义一个 GrpcServerContextCustomizer ,在这个自定义的 ContextCustomizer 中写入一个 Baggage。
然后在 io.opentelemetry.sdk.trace.SpanProcessor#onStart 接口中取出这个 Baggage 写入到当前 span 的 attribute 中。
这样我们就可以看到之前提到的那些数据上游信息了。
为 gRPC 添加上下文
先来看看如何为 gRPC 添加 Baggage:
我们先自定义一个 GrpcServerContextCustomizer 实现类:
public class GrpcServerContextCustomizer implements ContextCustomizer<GrpcRequest> {
private final String currentServiceName;
private static final String PARENT_RPC_KEY = "parent_rpc";
private static final String CURRENT_RPC_KEY = "current_rpc";
private static final String CURRENT_HTTP_URL_PATH = "current_http_url_path";
public GrpcServerContextCustomizer(String serviceName) {
this.currentServiceName = serviceName;
}
@Override
public Context onStart(Context parentContext, GrpcRequest grpcRequest,
Attributes startAttributeds) {
BaggageBuilder builder = Baggage.fromContext(parentContext).toBuilder();
String currentRpc = Baggage.fromContext(parentContext).getEntryValue(CURRENT_RPC_KEY);
String fullMethodName = startAttributeds.get(AttributeKey.stringKey("rpc.method"));
String rpcService = startAttributeds.get(AttributeKey.stringKey("rpc.service"));
// call from grpc
String method = rpcService + ":" + fullMethodName;
String baggageInfo = getBaggageInfo(currentServiceName, method);
String httpUrlPath = Baggage.fromContext(parentContext).getEntryValue(CURRENT_HTTP_URL_PATH);
if (!StringUtils.isNullOrEmpty(httpUrlPath)) {
// call from http
// currentRpc = currentRpc; currentRpc = create1|GET:/request // clear current_http_url_path builder.put(CURRENT_HTTP_URL_PATH, "");
}
Baggage baggage = builder
.put(PARENT_RPC_KEY, currentRpc)
.put(CURRENT_RPC_KEY, baggageInfo)
.build();
return parentContext.with(baggage);
}
private static String getBaggageInfo(String serviceName, String method) {
if (StringUtils.isNullOrEmpty(serviceName)) {
return "";
} return serviceName + "|" + method;
}
}
从这个代码中可以看出,我们需要先从上下文中获取 CURRENT_RPC_KEY ,从而得知当前的 span 是不是 root span。
所以我们其实是把当前的 span 信息作为一个 PARENT_RPC_KEY 写入到 Baggage 中。
这样在 SpanProcessor 中便可以直接取出 PARENT_RPC_KEY 作为上游的信息写入 span 的 attribute 中。
@Override
public void onStart(Context parentContext, ReadWriteSpan span) {
String parentRpc = Baggage.fromContext(parentContext).getEntryValue("parent_rpc");
if (!StringUtils.isNullOrEmpty(parentRpc)) {
String[] split = parentRpc.split("\\|");
span.setAttribute("parent_rpc", parentRpc);
span.setAttribute("parent_service_name", split[0]);
span.setAttribute("parent_service_method", split[1]);
}
}
需要注意的是,这里的 Baggage 需要使用
Baggage.fromContext(parentContext)才能拿到刚才写入 Baggage 信息。
之后我们找到构建 gRPCServerInstrumenterBuilder 的地方,写入我们刚才自定义的 GrpcServerContextCustomizer 即可。
.addContextCustomizer(new GrpcServerContextCustomizer(serviceName))
这里我们选择写入到是 serverInstrumenterBuilder 而不是clientInstrumenterBuilder,因为在服务端的入口就知道是从哪个接口进来的请求。
为 spring boot 的 http 接口添加上下文
如果只存在 gRPC 调用时只添加 gRPC 的上下文也够用了,但是我们也不排除由外部接口是通过 HTTP 访问进来的,然后再调用内部的 gRPC 接口;这也是非常常见的架构模式。
所以我们还需要在 HTTP 中增加 ContextCustomizer 将自身的数据写入到 Baggage 中。
好在 HttpServerRouteBuilder 自身是实现了 ContextCustomizer 接口的,我们只需要往里面写入 Baggage 数据即可。
public ContextCustomizer<REQUEST> build() {
Set<String> knownMethods = new HashSet<>(this.knownMethods);
return (context, request, startAttributes) -> {
if (HttpRouteState.fromContextOrNull(context) != null) {
return context;
} String method = getter.getHttpRequestMethod(request);
if (method == null || !knownMethods.contains(method)) {
method = "HTTP";
} String urlPath = getter.getUrlPath(request);
String methodPath = method + ":" + urlPath;
String currentRpc = Baggage.fromContext(context).getEntryValue(CURRENT_RPC_KEY);
String baggageInfo = getBaggageInfo(serviceName, methodPath);
Baggage baggage = Baggage.fromContext(context).toBuilder()
.put(PARENT_RPC_KEY, currentRpc)
.put(CURRENT_RPC_KEY, baggageInfo)
.put(CURRENT_HTTP_URL_PATH, methodPath)
.build();
return context.with(HttpRouteState.create(method, null, 0))
.with(baggage);
};}
这里新增了 CURRENT_HTTP_URL_PATH 用于标记当前的请求来源是 HTTP,在 grpc 的 ContextCustomizer 解析时会判断这个值是否为空。
String httpUrlPath = Baggage.fromContext(parentContext).getEntryValue(CURRENT_HTTP_URL_PATH);
if (!StringUtils.isNullOrEmpty(httpUrlPath)) {
// call from http
// currentRpc = currentRpc; currentRpc = create1|GET:/request // clear current_http_url_path builder.put(CURRENT_HTTP_URL_PATH, "");
}
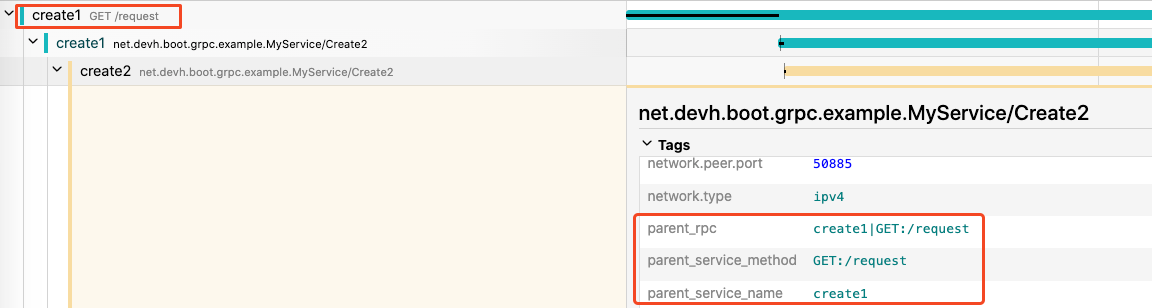
这样就可以在 grpc 的下游接口拿到入口的 HTTP 接口数据了。
当然也有可能是在 grpc 接口中调用 HTTP 的接口的场景,只是我们的业务中没有这种情况,所以就没有适配这类的场景。
总结
ContextCustomizer 接口没有提供对应的扩展,但是 SpanProcessor 是提供了扩展接口的。
原本是想尽量别维护自己的 javaagent,但也好在 OpenTelemetry 是提供的接口,所以也并不会去修改原本的代码。
所以我们还是需要创建一个 extensions 的项目在实现 SpanProcessor,这个在之前的 《实战:如何编写一个 OpenTelemetry Extensions》有详细讲到。
所以最后的应用启动方式如下:
java -javaagent:opentelemetry-javaagent-2.4.0-SNAPSHOT.jar \
-Dotel.javaagent.extensions=otel-extensions-custom-context-1.0-SNAPSHOT.jar \
需要使用我们手动打包的 javaagent 以及一个自定义扩展包。
打包方式:
./gradlew assemble
opentelemetry-java-instrumentation项目比较大,所以打包过程可能比较久。
因为这其实是一些定制需求,所以就没提交到上游,感兴趣的可以自行合并代码测试。
最后可以这个分支中查看到修改的部分:
https://github.com/crossoverJie/opentelemetry-java-instrumentation/compare/main...add-grpc-context
OpenTelemetry 深度定制:跨服务追踪的实战技巧的更多相关文章
- Go微服务框架go-kratos实战05:分布式链路追踪 OpenTelemetry 使用
一.分布式链路追踪发展简介 1.1 分布式链路追踪介绍 关于分布式链路追踪的介绍,可以查看我前面的文章 微服务架构学习与思考(09):分布式链路追踪系统-dapper论文学习(https://www. ...
- 网易云基于 Kubernetes 的深度定制化实践
本文由 网易云发布. 2017 年,Kubernetes 超越 Mesos 和 Docker Swarm成为最受欢迎的容器编排技术.网易云从 2015 下半年开始向 Kubernetes 社区贡献代 ...
- 阿里内部分享:我们是如何?深度定制高性能MySQL的
阿里云资深数据库工程师赵建伟在“云栖大会上海峰会”的分享.核心是阿里云的数据库服务和MySQL分支的深度定制实践分享. 阿里巴巴MySQL在全球都是有名的.不仅是因为其性能,还因为其是全世界少数拥有M ...
- 服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana
服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana https://www.cnblogs.com/xishuai/p/elk- ...
- 分布式服务追踪与调用链 Zikpin
分布式服务追踪与调用链系统产生的背景 在为服务中,如果服务与服务之间的依赖关系非常复杂,如果某个服务出现了一些问题,很难追查到原因,特别是服务与服务之间调用的时候. 在微服务系统中,随着业务的发展,系 ...
- 【.net core】电商平台升级之微服务架构应用实战
一.前言 这篇文章本来是继续分享IdentityServer4 的相关文章,由于之前有博友问我关于微服务相关的问题,我就先跳过IdentityServer4的分享,进行微服务相关的技术学习和分享.微服 ...
- 像MIUI一样做Zabbix二次开发(3)——Zabbix深度定制的意义
深度定制的意义 综合来讲,Zabbix是一个非常强大的监控平台,简单拿来完成监控一些Hosts,没有什么问题,而且,目前国内大部分客户都是这么做的,基本上是安装完后,网上找到一些相关模板,配置后把Ho ...
- SpringCloud微服务之跨服务调用后端接口
SpringCloud微服务系列博客: SpringCloud微服务之快速搭建EurekaServer:https://blog.csdn.net/egg1996911/article/details ...
- 微服务—分布式服务追踪sleuth和zipkin
随着业务的发展,系统规模也会越来越大,各微服务间的调用关系也越来越错综复杂. 通常一个客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果, 在复杂的微服务架构系统中,几乎每 ...
- C# 跨服务大文件复制
跨服务的大文件复制,肯定要和本地大文件复制一样,分多次传递,要不然内存也承受不了,下面就说下如何实现大文件的跨服务复制······ 首先肯定要建立一个WCF的服务以及对应的客户端来测试服务,此方法请参 ...
随机推荐
- C# - 自建 SDK 的 API 文档
在代码中添加 API 文档 用户在使用类库时,通常需要通过 VS 的 Intellisense 或 F12 反编译查看 API 的注释,借助这些注释来了解如何使用 API.在 C# 源文件中,可以通过 ...
- Unsortbin attack原理及分析
Unsortbin attack原理 ️条件:首先要实现Unsortbin attack前提是可以控制Unsortbin attack chunk的bk指针 ️目的:我们可以实现修改任意地址为一个比较 ...
- 小程序中使用 lottie 动画 | 踩坑经验分享
最近被拉去支援紧急需求(赶在五一节假日前上线的,双休需要加班),参与到项目中才知道,开发的项目是微信小程序技术栈的.由于是临时支援,笔者也很久没开发过微信小程序了,所以挑选了相对独立,业务属性相对轻薄 ...
- SAP HANA计算视图
Text. Text. Text. Text. Text. Text. Text. Text. Text. Text. 越来越多的SAP用户正在将SAP HANA实施为现有SAP BW的基础和数据库. ...
- 为什么需要学习ITSM/ITIL
假如你需要管理一个超过20人的IT服务组织,一般会面临以下问题: 人多事杂活重,每个人都很累,工作却还是一团糟糕, 用户方怨声载道,领导也颇有微词,同事间也经常互相甩锅埋坑, 工作只是救火或者混日子, ...
- ubuntu16下升级python3的版本--升级到3.8
ubuntu16下升级python3的版本,这里是升级到3.8. 1.首先添加安装源,在命令行输入如下命令: $ sudo add-apt-repository ppa:jonathonf/pytho ...
- centos 文件系统权限
模板:drwxrwxrwx r表是读 (Read) .w表示写 (Write) .x表示执行 (eXecute) 读.写.运行三项权限可以用数字表示,就是r=4,w=2,x=1, 777就是rwxrw ...
- Git命令拾掇
修改commit信息 git commit --amend -m 'The new message' 使用ssh替换https:// 设置某个仓库 git remote set-url origin ...
- 鸿蒙HarmonyOS实战-Stage模型(ExtensionAbility组件)
一.ExtensionAbility组件 1.概念 HarmonyOS中的ExtensionAbility组件是一种能够扩展系统功能的能力组件.它可以通过扩展系统能力接口,为应用程序提供一些特定的功能 ...
- golang select 和外层的 for 搭配
select语句通常与for循环搭配使用,但并不是必须的. 在某些情况下,select可能会直接放在一个独立的goroutine中,没有外层的for循环. 这通常发生在你知道只会有一次或有限次操作的情 ...