文件系统(九):一文看懂yaffs2文件系统原理
liwen01 2024.07.07
前言
yaffs 是专为nand flash 设计的一款文件系统,与jffs 类似,都是属于日志结构文件系统。与jffs 不同的是,yaffs 文件系统利用了nand flash 一些特有属性,所以在数据读写擦除和回收上都有较大的差异。
关于jffs2文件系统的介绍可以查看《文件系统(八):Linux JFFS2文件系统工作原理、优势与局限》
这里先介绍一下nand flash的一些基础知识,有助于后面理解yaffs的设计原理。
(一)flash 基础
flash分为nor flash和nand flash两类:
nor flash: 成本较高,容量较小,优点是读写数据不容易出错,比较适用于存储关键数据,比如程序固件、配置参数等。
nand flash :成本较低,相对便宜,容量较大,但是数据比较容易出错,所以一般都需要有对应的软件或者硬件的校验算法(ECC),比较适合用来储存大容量且数据安全要求不是非常严格的数据,比如照片、视频等。
(1)nand flash 数据存储单元
nand flash数据存储单元从概念上来说,由大到小有:
Nand Flash(Package) -> Chip(Die) -> Plane -> Block -> Page(Chunk) -> OOB(Spare data)
其中有些存储单元,在一些不同的资料上它们的叫法不太一样,比如page(页),、有些资料上介绍的是Chunk,在有些软件编程中,也有可能被介绍为扇区sector
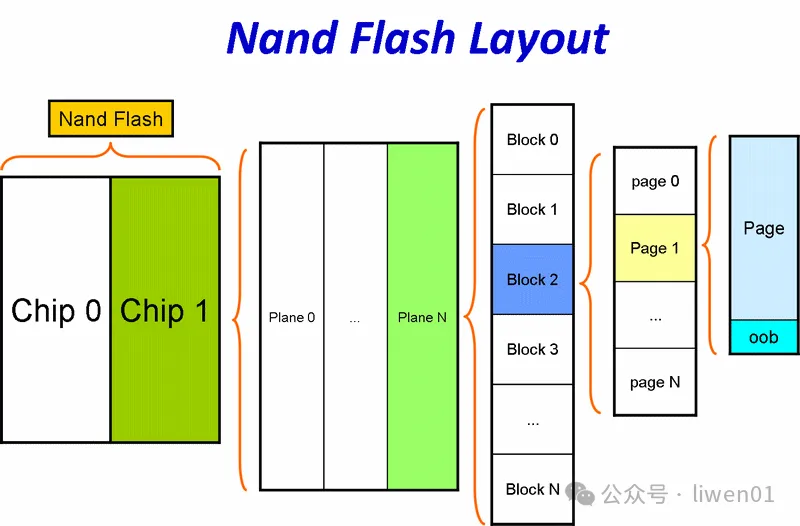
Nand Flash:也叫Package,这是我们在PCBA上看到的已经封装好的整科芯片,带有封装有IO引脚,可以直接焊接到PCB上使用。
Chip:也叫Die(裸片),这是独立的硅片,包含存储单元和控制电路,一个Package 中可以包含多个Die。
Plane : Plane是die内部的一个逻辑分区。每个die通常被划分为多个plane,以实现并行操作。每个plane有独立的寄存器和数据缓存,因此可以同时进行多个操作(如读取、写入、擦除),从而提高性能。
Block :NAND Flash存储的基本单位。
Page :也叫chunk,NAND Flash中最小的可编程单元。
OOB(Out-Of-Band) :也叫Spare data,OOB区域是每个page中额外的存储空间,用于存储元数据,例如错误校正码(ECC)、坏块标记和其他管理信息.
(2)nand flash 特性
nand flash 有一些特殊的属性,也是因为这些特殊的属性才有了yaffs文件系统的特殊设计
数据读写的最小单位是page(chunk) 数据写入之前,写入位置需要是被擦除过了的 数据擦除的最小单位是block block里面的page,只能按顺序写入,不能任意page写入 oob的数据是随着page(chunk)的数据一同被写入 nand flash有编程干扰、读取干扰、配对页面等问题,会引起自身或是配对页面的位翻转。
(3)数据存储
结合nand flash的特性,从应用软件编程的角度来看,整个nand flash空间是由各page(chunk)组成,每个page(chunk)后面跟随一个与之对应的oob.
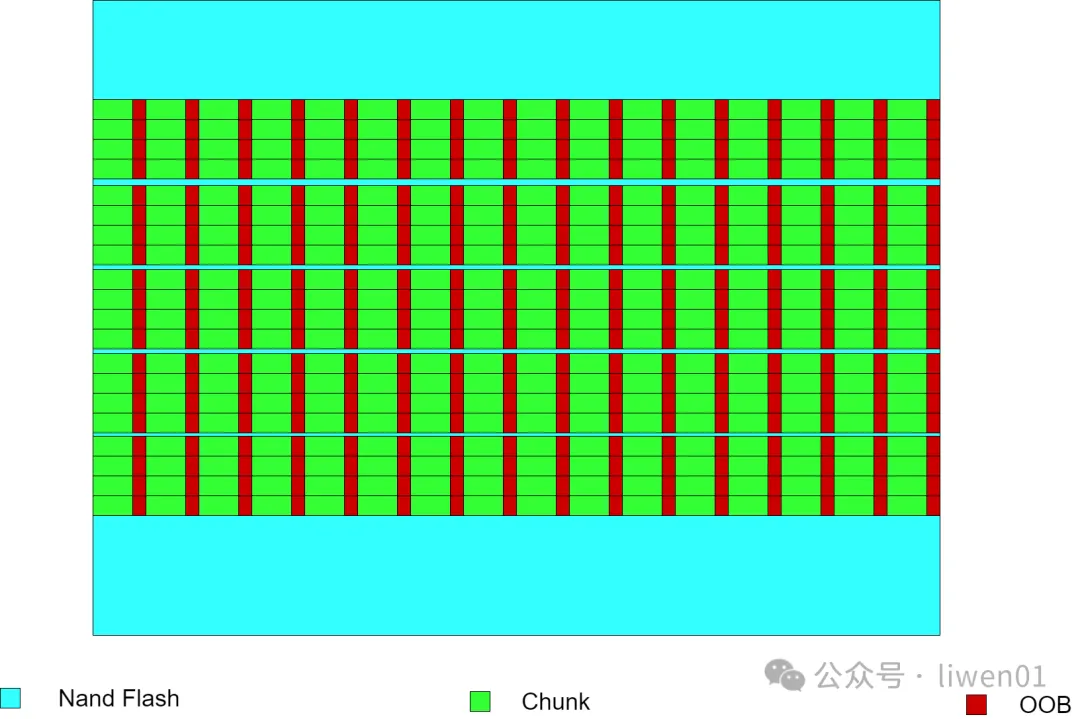
不同型号不同厂家生产的nand flash,它的block、page、oob等大小有可能不一样,在软件开发或是制作yaffs文件系统时,首先需要确认nand flash的参数。
(二)yaff2 数据格式
yaffs 有两个版本,yaffs1与yaffs2,主要区别是yaffs2可以支持比512Byte更大的chunk。它发布于2003年,比jffs2晚一两年被设计,但距今也二十多年了。
下面内容,yaffs 是代指yaffs1和yaffs2。关于yaffs文件系统的详细介绍,可以从官方网站下载到最新的代码和说明文档:https://www.aleph1.co.uk/gitweb/
(1)yaffs2 数据打包
创建4个测试目录,每个目录各创建一个测试文件,里面写有少量字符数据:
biao@ubuntu:~/test/yaffs/yaffs2_fs$ tree
.
├── test1
│ └── file1
├── test2
│ └── file2
├── test3
│ └── file3
└── test4
└── file4
4 directories, 4 files在制作成yaffs2镜像文件之前,4个目录和文件的大小如下:
biao@ubuntu:~/test/yaffs$ du yaffs2_fs
8 yaffs2_fs/test3
8 yaffs2_fs/test2
8 yaffs2_fs/test1
8 yaffs2_fs/test4
36 yaffs2_fs
biao@ubuntu:~/test/yaffs$下载最新yaffs源码,在yaffs2/utils 目录执行make,编译生成mkyaffs2image打包程序 使用默认参数对测试目录进行打包
biao@ubuntu:~/test/yaffs$ ./mkyaffs2image yaffs2_fs yaffs2_fs.img
mkyaffs2image: image building tool for YAFFS2 built Jul 7 2024
Processing directory yaffs2_fs into image file yaffs2_fs.img
Object 257, yaffs2_fs/test3 is a directory
Object 258, yaffs2_fs/test3/file3 is a file, 1 data chunks written
Object 259, yaffs2_fs/test2 is a directory
Object 260, yaffs2_fs/test2/file2 is a file, 1 data chunks written
Object 261, yaffs2_fs/test1 is a directory
Object 262, yaffs2_fs/test1/file1 is a file, 1 data chunks written
Object 263, yaffs2_fs/test4 is a directory
Object 264, yaffs2_fs/test4/file4 is a file, 1 data chunks written
Operation complete.
16 objects in 5 directories
12 NAND pages
biao@ubuntu:~/test/yaffs$查看yaffs2_fs.img镜像文件信息:
biao@ubuntu:~/test/yaffs$ stat yaffs2_fs.img
File: yaffs2_fs.img
Size: 135168 Blocks: 264 IO Block: 4096 regular file
Device: 801h/2049d Inode: 7874075 Links: 1
Access: (0600/-rw-------) Uid: ( 1000/ biao) Gid: ( 1000/ biao)
Access: 2024-07-07 23:12:18.195919283 +0800
Modify: 2024-07-07 23:10:19.798582920 +0800
Change: 2024-07-07 23:10:19.798582920 +0800
Birth: -
biao@ubuntu:~/test/yaffs$从yaffs2_fs.img镜像文件中我们看到,打包后的镜像文件比我们原来的目录文件要大很多,打包前是36KByte,打包后是132KByte,这是为什么呢?
(2)yaffs 数据分析
使用hexdunp命令直接查看yaffs2_fs.img镜像文件数据:
biao@ubuntu:~/test/yaffs$ hexdump -C yaffs2_fs.img
00000000 03 00 00 00 01 00 00 00 ff ff 74 65 73 74 33 00 |..........test3.|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
.........
.........
*
00000840 01 00 00 00 01 01 00 00 ff ff 66 69 6c 65 33 00 |..........file3.|
00000850 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000940 00 00 00 00 00 00 00 00 00 00 ff ff b4 81 00 00 |................|
00000950 e8 03 00 00 e8 03 00 00 f4 45 85 66 7e e5 70 66 |.........E.f~.pf|
00000960 43 45 85 66 1d 00 00 00 ff ff ff ff ff ff ff ff |CE.f............|
00000970 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
.........
.........
*
00001080 63 63 63 63 63 63 63 63 63 63 63 63 63 63 63 63 |cccccccccccccccc|
00001090 63 63 63 63 63 63 63 63 63 63 63 63 0a ff ff ff |cccccccccccc....|
000010a0 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
.........
.........从hex数据中我们可以直观的看到文件名信息和文件里面的数据,也就是说文件名和文件里面的数据都是未压缩的。
我们对mkyaffsimage.c的源码进行分析,在默认参数下mkyaffsimage打包的镜像文件,它的chunk、spare、block大小信息如下:
#define chunkSize 2048
#define spareSize 64
#define pagesPerBlock 64yaffs2的镜像文件是由object_header、data、yaffs_spare 三个部分组成,每个object_header、data 至少占用一个chunk,yaffs_spare 实际上也就是oob数据,是存储在spare空间。
(3)yaffs2 目录
我们对上面yaffs2_fs.img的镜像文件进行分析,先看最开始的数据,是test3目录obj
00000000 03 00 00 00 01 00 00 00 ff ff 74 65 73 74 33 00 |..........test3.|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000100 00 00 00 00 00 00 00 00 00 00 ff ff fd 41 00 00 |.............A..|
00000110 e8 03 00 00 e8 03 00 00 f4 45 85 66 7e e5 70 66 |.........E.f~.pf|
00000120 43 45 85 66 ff ff ff ff ff ff ff ff ff ff ff ff |CE.f............|
00000130 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
000001c0 ff ff ff ff ff ff ff ff ff ff ff ff 00 00 00 00 |................|
000001d0 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00000800 00 10 00 00 01 01 00 00 00 00 00 00 ff ff 00 00 |................|
00000810 25 00 00 00 00 00 00 00 ff ff ff ff ff ff ff ff |%...............|
00000820 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*0~0x800 地址的数据是object_header数据结构,后面是oob的数据结构,详细解析数据如下:
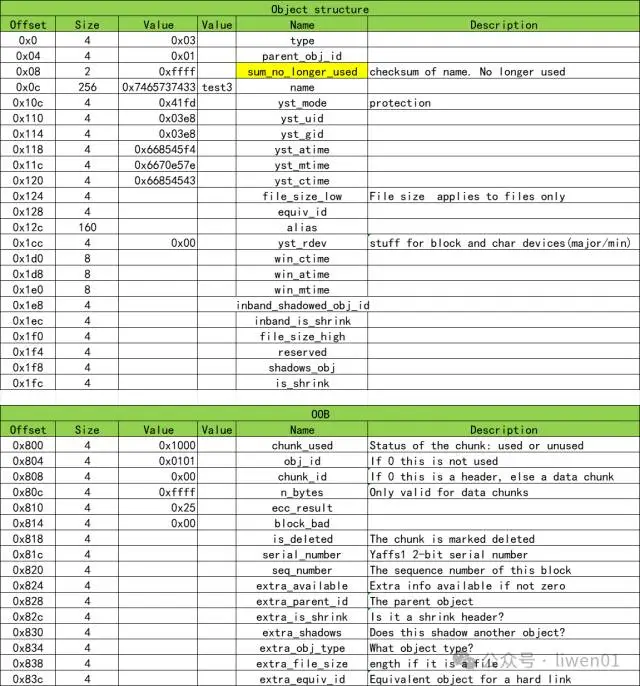
未填写区域是数据0xFF,也就是未写入数据 object_header大小为512Byte oob 大小为64Byte,与上面代码设置的相同 这里file_size_low为0xFF,表示不携带实际数据,实际也是没有data段 obj_id 是从0x100(256)开始,在整个文件系统中,obj_id是不重复的,chunk更新的时候,obj_id保持不变
(3)yaffs2 文件
下面数据是file3的数据结构
00000840 01 00 00 00 01 01 00 00 ff ff 66 69 6c 65 33 00 |..........file3.|
00000850 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000940 00 00 00 00 00 00 00 00 00 00 ff ff b4 81 00 00 |................|
00000950 e8 03 00 00 e8 03 00 00 f4 45 85 66 7e e5 70 66 |.........E.f~.pf|
00000960 43 45 85 66 1d 00 00 00 ff ff ff ff ff ff ff ff |CE.f............|
00000970 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00000a00 ff ff ff ff ff ff ff ff ff ff ff ff 00 00 00 00 |................|
00000a10 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00000a30 00 00 00 00 ff ff ff ff ff ff ff ff ff ff ff ff |................|
00000a40 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00001040 00 10 00 00 02 01 00 00 00 00 00 00 ff ff 00 00 |................|
00001050 26 00 00 00 00 00 00 00 ff ff ff ff ff ff ff ff |&...............|
00001060 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00001080 63 63 63 63 63 63 63 63 63 63 63 63 63 63 63 63 |cccccccccccccccc|
00001090 63 63 63 63 63 63 63 63 63 63 63 63 0a ff ff ff |cccccccccccc....|
000010a0 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*
00001880 00 10 00 00 02 01 00 00 01 00 00 00 1d 00 00 00 |................|
00001890 00 00 00 00 08 00 00 00 08 00 00 00 ff ff ff ff |................|
000018a0 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
*file3是一个文件,其中包括2个chunk:一个是Object,另外一个是data,其中每个chunk后面有一个与之对应的oob
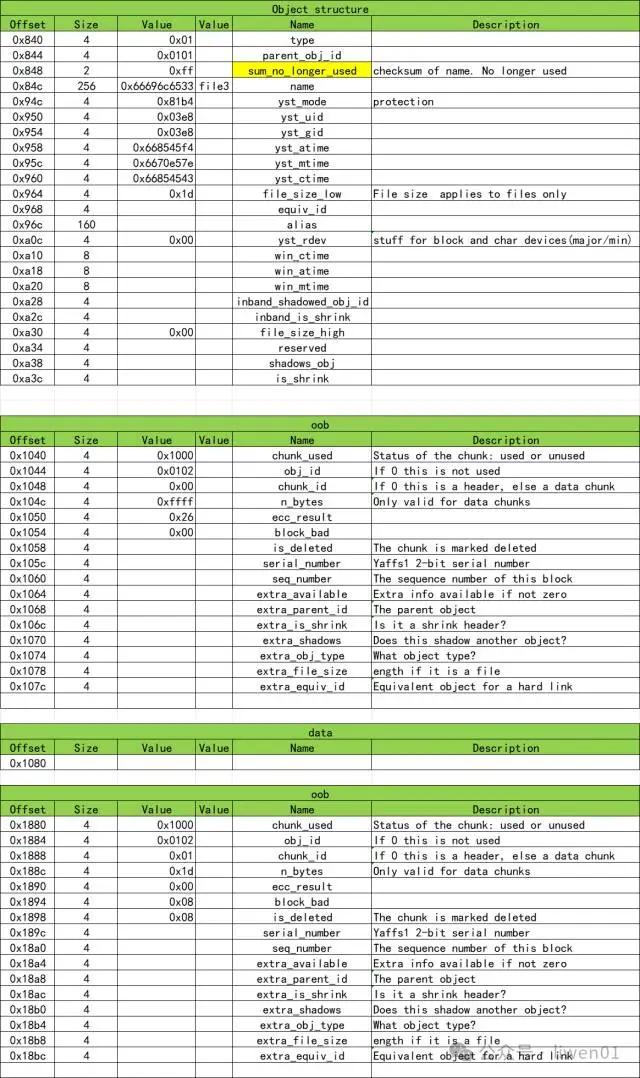
与目录相比,文件有file_size_low,chunk_id,还有data chunk。我们看file3实际数据:
biao@ubuntu:~/test/yaffs$ stat yaffs2_fs/test3/file3
File: yaffs2_fs/test3/file3
Size: 29 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 7874095 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ biao) Gid: ( 1000/ biao)
Access: 2024-07-07 23:57:37.355671911 +0800
Modify: 2024-07-07 23:40:14.962499985 +0800
Change: 2024-07-07 23:34:11.067767029 +0800
Birth: -
biao@ubuntu:~/test/yaffs$ cat yaffs2_fs/test3/file3
cccccccccccccccccccccccccccc
biao@ubuntu:~/test/yaffs$对比发现data chunk中存储的数据,就是file3文件里面的实际数据。
(三)工作原理
(1)yaffs2 挂载
上面我们分析了目录和文件obj的数据结构,实际yaffs还支持其它的文件类型:
enum yaffs_obj_type {
YAFFS_OBJECT_TYPE_UNKNOWN,
YAFFS_OBJECT_TYPE_FILE,
YAFFS_OBJECT_TYPE_SYMLINK,
YAFFS_OBJECT_TYPE_DIRECTORY,
YAFFS_OBJECT_TYPE_HARDLINK,
YAFFS_OBJECT_TYPE_SPECIAL
};从obj 类型结构体中我们可以看到,还支持软连接、硬连接和特殊文件类型。它们与常规的文件、目录一样,都有object_header 结构,关键的元数据信息都是存储在oob中。
实际yaffs文件系统在挂载的时候,并不需要像jffs2一样扫描整个flash空间。在yaffs文件系统中,只需要先扫描oob里面的数据就可以构建出文件、目录与chunk之间的关系,再结合object_header信息就可以构建出整个文件系统的信息。所以yaffs2在同等大小的文件系统中,挂载速度是会比jffs2快的。
(2)yaffs2数据更新
回顾我们前面介绍的nand flash特性:
数据读写的最小单位是page(chunk) 数据写入之前,写入位置需要是被擦除过了的 数据擦除的最小单位是block block里面的page,只能按顺序写入,不能任意page写入 oob的数据是随着page的数据一同被写入
对于我们上面介绍的file3文件,如果我们要对它进行修改或是删除,在flash中是需要怎么操作的呢?
首先找到要修改的chunk,将数据读取到内存中,再对其数据进行修改,最后将修改后的数据写入到一个新的chunk 新的数据写入新chunk的同时,与它对应的oob数据也会被一同写入新chunk对应的oob区域
oob的数据是随着chunk的数据写入flash中的,但是nand flash 的擦除又是按block进行擦除,如果不擦除,数据又不能重新被写入,那要怎么标记file3 存储原来数据的chunk为无效呢?
在yaffs2中,它是通过oob中的obj id来标记是否同一个数据chunk,通过seq_number来标记哪个chunk的数据是最新的,如果不是最新的,那就是无效的了。
比如在文件系统中,有多个chunk它们有相同的obj id,说明这些chunk都是这个obj id 的不同修改版本的同一组数据,seq_number值最大的是最新的数据,其它的则都是无效数据。每一次修改,seq_number就会增加1。
这里是通过软件方法来标记数据无效,实际物理数据是没有做无效标记的,数据也没有被清除。物理上的标记无效和数据擦除,是需要等到垃圾回收的时候再对整个block进行擦除操作,这个时候标记的其实不是数据无效,而是chunk未使用.
在数据更新的操作中,核心的参数是obj id 和seq_number。
(3)垃圾回收机制
从上面数据更新原理上我们知道,一个旧的数据,或是数据结构,在yaffs2文件系统中并不会标记它为无效,因为写入标志同样需要擦除再写入。在yaffs2文件系统中,是通过seq_number来标记数据版本的新旧,旧的则为无效数据。
在yaffs2的垃圾回收中,有两种方式:主动回收和被动回收:
主动回收:一个block中的绝大部分chunk数据都是无效的,文件系统会触发主动回收
被动回收:flash 已经没有干净的chunk可以继续使用,此时需要立即执行垃圾回收以释放空间。这里会把几个block中的有效数据合并到一块,腾出至少一个无效数据block以便进行整块擦除回收。
yaffs2文件系统中,为了平衡性能与回收功能,它的垃圾回收有两个特性:
尽可能地延迟进行垃圾回收 一次只处理一个块
(四)优缺点
(1)优点
启动较快:与jffs2相比,它不需要全盘扫描flash空间,所以挂载所花费的时间相对较短。 日志结构:采用日志结构的设计,在异常断电等情况下比较容易保持文件系统的一致性。 磨损均衡:block内的chunk是按序写入,加上日志结构设备使yaffs自带磨损平衡。但是在垃圾回收的时候,并没有提供专门的算法,所以不是严格的磨损平衡,带有一些随机性。
(2)缺点
无压缩功能:从上面我们对file3文件的分析可以看到,文件数据和元数据都未进行压缩,这个在对成本敏感的嵌入式设备中,是个劣势。 元数据开销大: 每个obj都至少需要一个chunk存储object_header,元数据的开销大,浪费存储空间。 扩展性差:不适合大容量的存储设备,管理大规模数据时性能可能下降。
(3)yaffs2与jffs2
yaffs2 文件系统与 jffs2 文件系统非常相似,都是基于裸flash设计的文件系统,jffs2 更常用于nor flash ,而yaffs2 是专为nand flash 而设计。它们都是日志结构文件系统,都有磨损平衡功能,但也都是随机磨损平衡。
它们都适合比较小容量的存储设备,因为jffs2挂载的时候需要全盘扫描flash查找元数据构建文件目录结构,所以jffs2在大容量存储设备中数据存储比较多时,挂载所需要的时间会比较长,耗用的内存也会比较多。
yaff2 是将关键元数据存储在oob中,nand flash的oob区域是固定的。挂载的时候只需要扫描oob区域数据就可以了,所以相比较jffs2,yaffs2的挂载启动速度会比较快一些。
jffs2的数据和元数据都是压缩的,并且支持多种压缩算法,这些yaffs2都没有,所以空间利用率yaffs2并没有jffs2高。
在产品功能没有明显优势的前提下,能把产品价格做低其实也是一个非常大的优势,所以nand flash的应用也越发的普及。但目前nand flash 使用比较多的是集成到FTL(Flash Translation Layer)设备中,比如TF卡,SD卡、SSD、U盘等。
jffs2和yaffs2文件系统,都是基于裸的flash来使用,它们并不适用于FTL设备,FTL设备使用比较多的文件系统是:FAT32,exFAT、NTFS、ext3、ext4等
关于存储介质和其它文件系统原理的介绍,可以查看前面文章:
结尾
yaffs2目前在嵌入式设备中使用率还是比较高,了解它的工作原理,有助于更好地使用它。另外从官方资料上看,yaffs 是需要授权收费的,如果有使用yaffs2文件系统的设备,需要考虑是否存在版权法律风险。
【如果你觉得文章内容对你有帮助,那就点个赞、关注一下吧】
------------------End------------------如需获取更多内容请关注 liwen01 公众号
文件系统(九):一文看懂yaffs2文件系统原理的更多相关文章
- 一文看懂Transformer内部原理(含PyTorch实现)
Transformer注解及PyTorch实现 原文:http://nlp.seas.harvard.edu/2018/04/03/attention.html 作者:Alexander Rush 转 ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- 【转帖】一文看懂docker容器技术架构及其中的各个模块
一文看懂docker容器技术架构及其中的各个模块 原创 波波说运维 2019-09-29 00:01:00 https://www.toutiao.com/a6740234030798602763/ ...
- 一文看懂web服务器、应用服务器、web容器、反向代理服务器区别与联系
我们知道,不同肤色的人外貌差别很大,而双胞胎的辨识很难.有意思的是Web服务器/Web容器/Web应用程序服务器/反向代理有点像四胞胎,在网络上经常一起出现.本文将带读者对这四个相似概念如何区分. 1 ...
- 一文看懂https如何保证数据传输的安全性的【转载、收藏】
一文看懂https如何保证数据传输的安全性的 一文看懂https如何保证数据传输的安全性的 大家都知道,在客户端与服务器数据传输的过程中,http协议的传输是不安全的,也就是一般情况下http是明 ...
- [转帖]一文看懂web服务器、应用服务器、web容器、反向代理服务器区别与联系
一文看懂web服务器.应用服务器.web容器.反向代理服务器区别与联系 https://www.cnblogs.com/vipyoumay/p/7455431.html 我们知道,不同肤色的人外貌差别 ...
- [转帖] 一文看懂:"边缘计算"究竟是什么?为何潜力无限?
一文看懂:"边缘计算"究竟是什么?为何潜力无限? 转载cnbeta 云计算 雾计算 边缘计算... 知名创投调研机构CB Insights撰文详述了边缘计算的发展和应用前景 ...
- 一文看懂Stacking!(含Python代码)
一文看懂Stacking!(含Python代码) https://mp.weixin.qq.com/s/faQNTGgBZdZyyZscdhjwUQ
- Nature 为引,一文看懂个体化肿瘤疫苗前世今生
进入2017年,当红辣子鸡PD-1疗法,一路横扫多个适应症.而CAR-T治疗的“小车”在获得FDA专委会推荐后也已经走上高速路,成为免疫治疗又一里程碑事件.PD-1.CAR-T之后,下一个免疫治疗产品 ...
- 转载来自朱小厮博客的 一文看懂Kafka消息格式的演变
转载来自朱小厮博客的 一文看懂Kafka消息格式的演变 ✎摘要 对于一个成熟的消息中间件而言,消息格式不仅关系到功能维度的扩展,还牵涉到性能维度的优化.随着Kafka的迅猛发展,其消息格式也在 ...
随机推荐
- 鸿蒙stage模型
app.json5全局的配置文件 icon和label是应用列表的 module.json5模块配置文件 中有一个abilities其中的icon和label才是桌面的图标和名称 日志的话就是hail ...
- C++ placement new学习
通常创建对象使用new操作,但这样无法指定在具体某一块内存开辟空间创建对象.而如果 可以指定开辟空间的内存位置,我们可以编写内存池高效的复用同一个内存位置,这样可以避免系统频繁申请可用内存 所占用的时 ...
- vue学习笔记之父组件子组件的传值
一 在前端开发过程中,很多情况下一个页面无法装载大部分的代码,所以需要子组件来完成父组件的任务,下面我来展示一下,组件之间如何进行传值以及常见的坑,首先上代码 1.1 父组件代码 <tem ...
- linux各个目录详细说明
在linux中一切皆文件,每个目录均有自己特定的作用,下面进行详细说明. 目录 说明 / 处于linux系统树形结构的最顶端,它是linux文件系统的入口,所有的目录.文件.设备都在 / 之下 /bi ...
- uni-app写微信小程序,data字段循环引用
在写程序过程中,需要使用到 globalData里的内容,而这个全局变量,在uni-app上需要通过: var app=getApp(); app.globalData.xxx=xxx来使用. 我觉得 ...
- mySql脚本转换成sqlserver脚本(主流数据库的脚本都能转换,需要使用powerdesigner)
我使用的powerdesginer版本是16.5,只需要脚本文件就可以了,不需要安装mysql和sqlserver. 文件->反向工程->Database... 选择原脚本文件的数据库类型 ...
- group_concat 和 case when 的坑
SELECT size,instrument_id, (CASE side WHEN "sell" THEN group_concat(id ORDER BY id) END )a ...
- SpringBoot使用@Value获取不到值的问题
背景 在一次SpringBoot项目改造为Cloud的过程中,使用Nacos作为配置中心获取属性,改造后程序启动报错,查看日志,定位到代码: 解决方案 如果了解Bean的生命周期的同学应该知道,Spr ...
- python 如何判断一组数呈上升还是下降趋势
1. python 判断一组数呈上升还是下降趋势的方法 要判断一组数(数列)是呈上升趋势.下降趋势还是无明显趋势,我们可以比较数列中相邻元素的差值.如果大部分差值都是正数,则数列呈上升趋势:如果大部分 ...
- 使用 INFINI Console 实现 Elasticsearch 的增量数据迁移
功能介绍 # 在 INFINI Console 1.3.0 版本里,数据迁移功能增加了对增量迁移的支持.这篇文章将会介绍增量迁移的具体使用方法和实现原理. 场景介绍 # 以常见的日志场景为例,假设 A ...