Llama2-Chinese项目:8-TRL资料整理
TRL(Transformer Reinforcement Learning)是一个使用强化学习来训练Transformer语言模型和Stable Diffusion模型的Python类库工具集,听上去很抽象,但如果说主要是做SFT(Supervised Fine-tuning)、RM(Reward Modeling)、RLHF(Reinforcement Learning from Human Feedback)和PPO(Proximal Policy Optimization)等的话,肯定就很熟悉了。最重要的是TRL构建于transformers库之上,两者均由Hugging Face公司开发。
一.TRL类库
1.TRL类库介绍
简单理解就是可以通过TRL库做RLHF训练,如下所示:
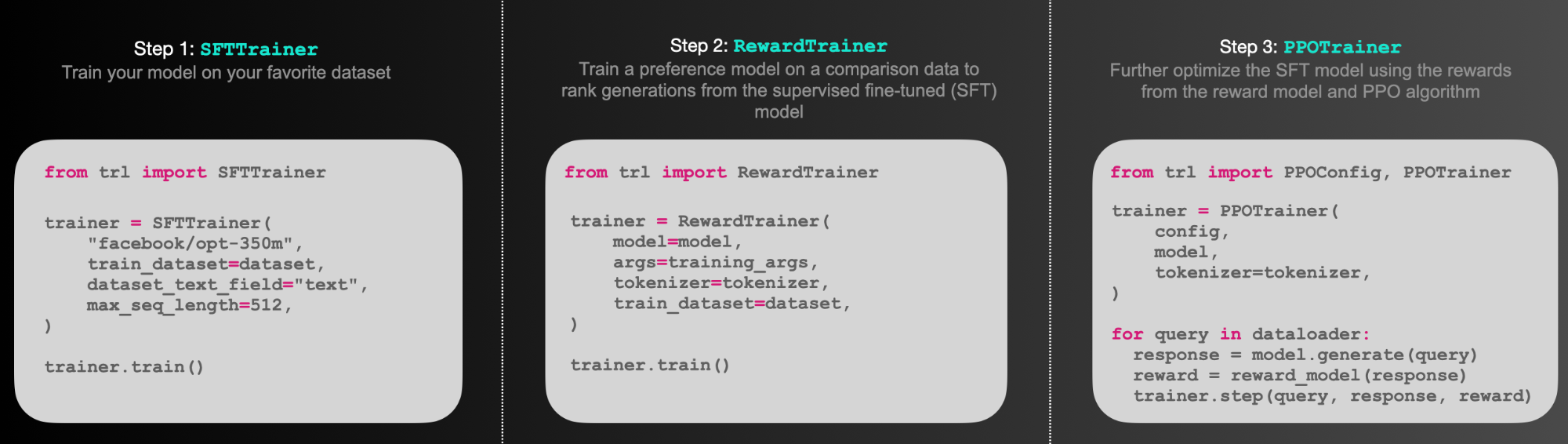
(1)SFTTrainer:是一个轻量级、友好的transformers Trainer包装器,可轻松在自定义数据集上微调语言模型或适配器。
(2)RewardTrainer:是一个轻量级的transformers Trainer包装器,可轻松为人类偏好(奖励建模)微调语言模型。
(3)PPOTrainer:一个PPO训练器,用于语言模型,只需要(query, response, reward)三元组来优化语言模型。
(4)AutoModelForCausalLMWithValueHead & AutoModelForSeq2SeqLMWithValueHead:一个带有额外标量输出的transformer模型,每个token都可以用作强化学习中的值函数。
(5)Examples:使用BERT情感分类器训练GPT2生成积极的电影评论,仅使用适配器的完整RLHF,训练GPT-j以减少毒性,Stack-Llama例子等。
2.PPO工作原理
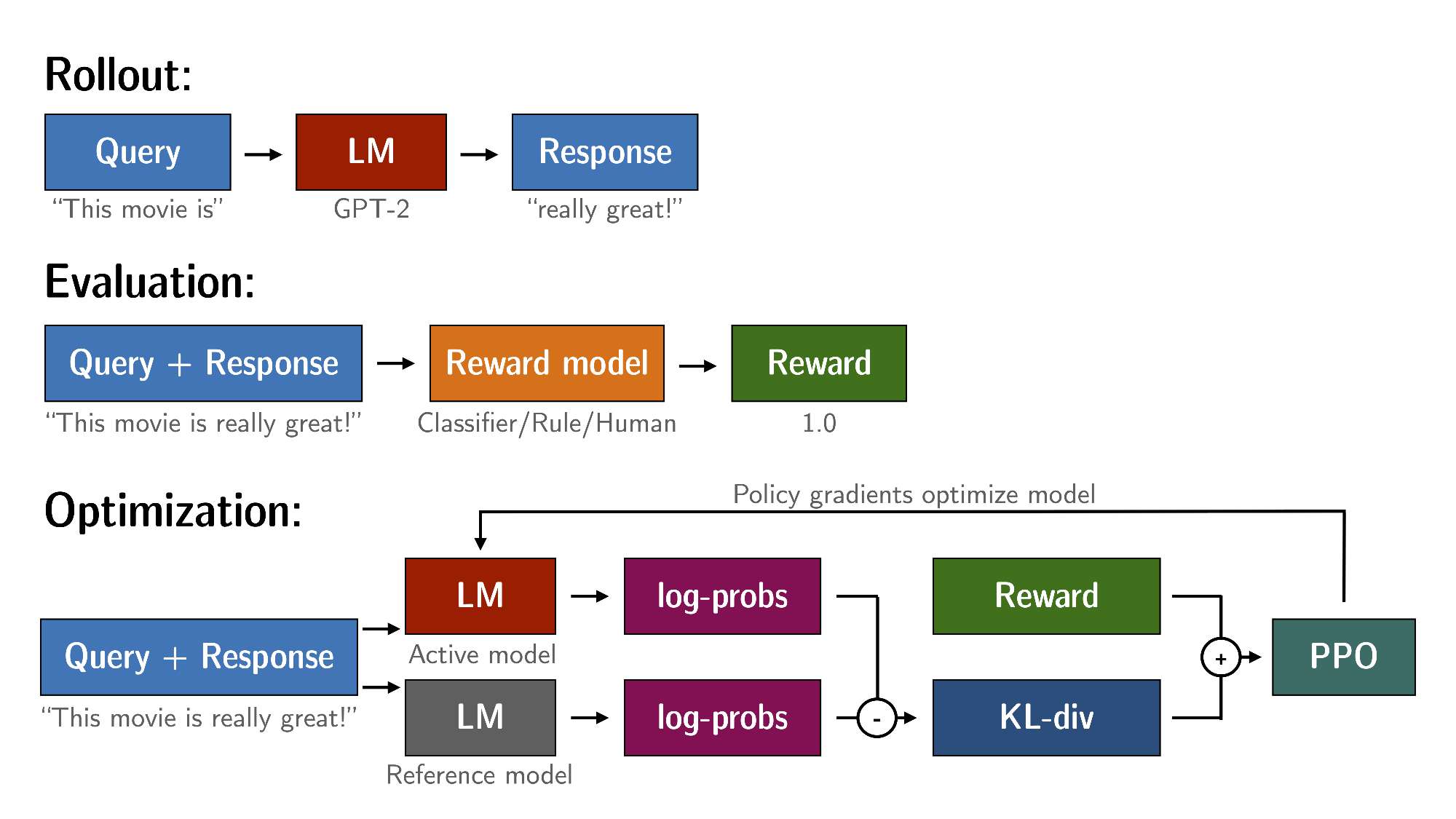
通过PPO对语言模型进行微调大致包括三个步骤:
(1)Rollout:语言模型根据query生成response或continuation,query可以是一个句子的开头。
(2)Evaluation:使用函数、模型、人类反馈或它们的某些组合对查询和响应进行评估。重要的是,此过程应为每个query/response对生成一个标量值。
(3)Optimization:这是最复杂的部分。在优化步骤中,query/response对用于计算序列中token的对数概率。这是使用经过训练的模型和Reference model完成的,Reference model通常是微调前的预训练模型。两个输出之间的KL散度用作额外的奖励信号,以确保生成的response不会偏离Reference model太远。然后使用PPO训练Active model。
二.TRL安装和使用方式
1.TRL安装
# 直接安装包
pip install trl
# 从源码安装
git clone https://github.com/huggingface/trl.git
cd trl/
pip install .
2.SFTTrainer使用方式
SFTTrainer是围绕transformer Trainer的轻量级封装,可以轻松微调自定义数据集上的语言模型或适配器。如下所示:
# 导入Python包
from datasets import load_dataset
from trl import SFTTrainer
# 加载imdb数据集
dataset = load_dataset("imdb", split="train")
# 得到trainer
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
# 开始训练
trainer.train()
3.RewardTrainer使用方式
RewardTrainer是围绕transformers Trainer的封装,可以轻松在自定义偏好数据集上微调奖励模型或适配器。如下所示:
# 导入Python包
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from trl import RewardTrainer
# 加载模型和数据集,数据集需要为指定格式
model = AutoModelForSequenceClassification.from_pretrained("gpt2", num_labels=1)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
...
# 得到trainer
trainer = RewardTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
)
# 开始训练
trainer.train()
4.PPOTrainer使用方式
query通过语言模型输出一个response,然后对其进行评估。评估可以人类反馈,也可以是另一个模型的输出。如下所示:
# 导入Python包
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch
# 首先加载模型,然后创建参考模型
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = create_reference_model(model)
tokenizer = AutoTokenizer.from_pretrained('gpt2')
# 初始化ppo配置对象
ppo_config = PPOConfig(
batch_size=1,
)
# 编码一个query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
# 得到模型response
response_tensor = respond_to_batch(model, query_tensor)
# 创建一个ppo trainer
ppo_trainer = PPOTrainer(ppo_config, model, model_ref, tokenizer)
# 为response定义一个reward(人类反馈或模型输出奖励)
reward = [torch.tensor(1.0)]
# 使用ppo训练一步模型
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
参考文献:
[1]https://github.com/huggingface/trl
[2]https://huggingface.co/docs/trl/v0.7.1/en/index
Llama2-Chinese项目:8-TRL资料整理的更多相关文章
- iOS 开发学习资料整理(持续更新)
“如果说我看得比别人远些,那是因为我站在巨人们的肩膀上.” ---牛顿 iOS及Mac开源项目和学习资料[超级全面] http://www.kancloud.cn/digest/ios-mac ...
- zz 圣诞丨太阁所有的免费算法视频资料整理
首发于 太阁实验室 关注专栏 写文章 圣诞丨太阁所有的免费算法视频资料整理 Ray Cao· 12 小时前 感谢大家一年以来对太阁实验室的支持,我们特地整理了在过去一年中我们所有的原创算法 ...
- 【转】iOS超全开源框架、项目和学习资料汇总
iOS超全开源框架.项目和学习资料汇总(1)UI篇iOS超全开源框架.项目和学习资料汇总(2)动画篇iOS超全开源框架.项目和学习资料汇总(3)网络和Model篇iOS超全开源框架.项目和学习资料汇总 ...
- H.264的一些资料整理
本文转载自 http://blog.csdn.net/ljzcom/article/details/7258978, 如有需要,请移步查看. Technorati 标签: H.264 资料整理 --- ...
- Java 学习资料整理
Java 学习资料整理 Java 精品学习视频教程下载汇总 Java视频教程 孙鑫Java无难事 (全12CD) Java视频教程 即学即会java 上海交大 Java初级编程基础 共25讲下载 av ...
- word2vec剖析,资料整理备存
声明:word2vec剖析,资料整理备存,以下资料均为转载,膜拜大神,仅作学术交流之用. word2vec是google最新发布的深度学习工具,它利用神经网络将单词映射到低维连续实数空间,又称为单词嵌 ...
- F4NNIU 的 Docker 学习资料整理
F4NNIU 的 Docker 学习资料整理 Docker 介绍 以下来自 Wikipedia Docker是一个开放源代码软件项目,让应用程序部署在软件货柜下的工作可以自动化进行,借此在Linux操 ...
- Burpsuite 资料整理
Burpsuite 资料整理, 整到一起比较方便.大家有更多关于Burpsuite的Tip请一起增量.谢谢! 插件 序号 名称 功能 参考文档 1 Turbo intruder 并发 https:// ...
- iOS 学习资料整理
iOS学习资料整理 https://github.com/NunchakusHuang/trip-to-iOS 很好的个人博客 http://www.cnblogs.com/ygm900/ 开发笔记 ...
- 转:基于IOS上MDM技术相关资料整理及汇总
一.MDM相关知识: MDM (Mobile Device Management ),即移动设备管理.在21世纪的今天,数据是企业宝贵的资产,安全问题更是重中之重,在移动互联网时代,员工个人的设备接入 ...
随机推荐
- Background Removal obs
Background Removal / Portrait Segmentation / Virtual Green-screen v0.5.16 Go to download Author roys ...
- js性能优化解决办法
1. 减少http请求次数:CSS Sprites, JS.CSS 源码压缩.图片大小控制合适:网页 Gzip,CDN 托管,data 缓存 ,图片服务器 2. 前端模板 JS + 数据,减少由于HT ...
- ELK日志企业案例:(5.3版本)
1.shell三剑客同居.分析nginx日志: 1)在企业生产环境中,日志内容主要用来做什么? 日志内容主要用于运维人员.开发人员.DBA排错软件服务故障的,因为通过日志内容能够第一时间找到软件服务的 ...
- 当我们输入 kubectl run 时都发生了什么?
为了确保整体的简单性和易上手,Kubernetes 通过一些简单的抽象隐去操作背后的复杂逻辑,但作为一名有梦想的工程师,掌握其背后的真正思路是十分有必要的.本文以 Kubectl 创建 Pod 为例, ...
- [Python]对称日!
def check(year): if (year%4 == 0 and year%100 != 0) or year%400 == 0: return True else: return False ...
- JavaScript 语法:变量、数据类型及数据类型转换
作者:WangMin 格言:努力做好自己喜欢的每一件事 变量 赋值变量用 var 关键字,情况如下: 1)先声明变量再赋值 var varName; varName="你好~"; ...
- 极致性能优化:前端SSR渲染利器Qwik.js
引言 前端性能已成为网站和应用成功的关键要素之一.用户期望快速加载的页面和流畅的交互,而前端框架的选择对于实现这些目标至关重要.然而,传统的前端框架在某些情况下可能面临性能挑战且存在技术壁垒. 在这个 ...
- C#/.NET/.NET Core推荐学习书籍(已分类)
前言 古人云:"书中自有黄金屋,书中自有颜如玉",说明了书籍的重要性.作为程序员,我们需要不断学习以提升自己的核心竞争力.以下是一些优秀的C#/.NET/.NET Core相关学习 ...
- VideoPipe可视化视频结构化框架更新总结(2023-12-5)
项目地址:https://github.com/sherlockchou86/video_pipe_c 往期文章:https://www.cnblogs.com/xiaozhi_5638/p/1696 ...
- C# 对象与JSON字符串互相转换
一.JSON字符串转对象(反序列化) 1.使用Newtonsoft.Json 反序列化字符串转换为指定类型 (T) JsonConvert.DeserializeObject<T>(jso ...