人工智能模型训练技术:随机失活,丢弃法,Dropout

前一篇:《探索训练人工智能模型的词汇大小与模型的维度》
序言:Dropout 是神经网络设计领域的一种技术,通常我们把它翻译成 随机失活 或者 丢弃法。如果训练神经网络的时候不用 Dropout,模型就很容易“读死书”,也就是过拟合,结果可能导致项目失败。
那 Dropout 到底在干什么呢?其实很简单,就是在训练模型的时候,随机关掉隐藏层中的一些神经元,不让它们输出结果。没什么玄乎的,就是这么直接。比如说,在每一轮(epoch)训练中,会随机挑一些神经元“闭麦”,让它们暂时休息,输出值设为 0。但需要注意的是,哪些神经元会被关掉是随机的,每次都不一样,而不是每次关掉一批固定的神经元。这样操作的好处是,模型必须依赖所有神经元协同工作,去学习更普遍的规律,而不是只死记硬背几个特定特征。所以 Dropout 能很好地解决模型的“读死书”问题,让它更灵活、更聪明,也更有能力去识别它从未见过的新知识。
使用 Dropout
在减少过拟合方面,一个常用的技巧是在全连接神经网络中加入 Dropout。我们在第 3 章中探讨了它在卷积神经网络中的应用。这时可能会很想直接使用 Dropout 来看看它对过拟合的效果,但在这里我选择先不急着用,而是等到词汇表大小、嵌入维度和架构复杂度都调整好之后再试。毕竟,这些调整往往比使用 Dropout 对模型效果的影响更大,而我们已经从这些调整中看到了不错的结果。
现在,我们的架构已经简化到中间的全连接层只有 8 个神经元了,因此 Dropout 的作用可能会被最小化,但我们还是来试一试吧。以下是更新后的模型代码,加入了 0.25 的 Dropout(这相当于我们 8 个神经元中丢弃了 2 个):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(8, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(1, activation='sigmoid')
])
图 6-14 显示了训练 100 个周期后的准确率结果。这次我们看到训练集的准确率开始超过之前的阈值,而验证集的准确率则在慢慢下降。这表明我们又进入了过拟合的区域。
这一点通过图 6-15 的损失曲线得到了验证。
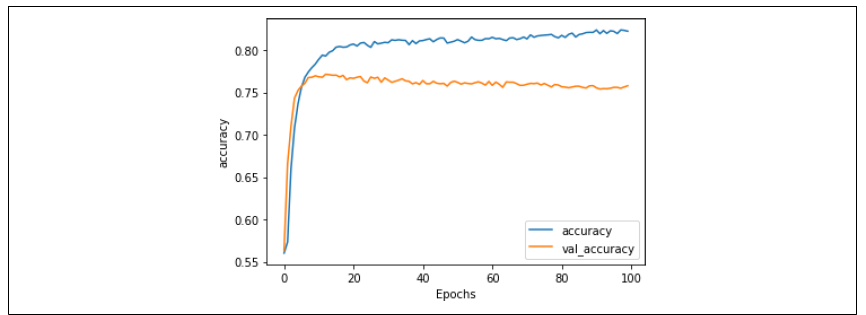
图 6-14:加入 Dropout 后的准确率

图 6-15:加入 Dropout 后的损失
从这里你可以看到,模型的验证损失又开始呈现出之前那种随着时间增加的趋势。虽然情况没有之前那么糟糕,但显然方向是不对的。
在这种情况下,由于神经元的数量非常少,加入 Dropout 可能并不是一个合适的选择。不过,Dropout 仍然是一个很好的工具,要记得把它放进你的工具箱,在比这个更复杂的架构中使用它。
总结:本节示例演示了在网络中引入 Dropout 的效果。从实验中我们可以看到,Dropout 是一个有效的工具,但它的作用依赖于模型架构和具体场景。对于像本例中这种简化的模型,Dropout 的影响较小。但在更复杂的模型中,它往往是防止过拟合的关键手段。接下来,我们还会介绍几种优化技术,帮助进一步解决模型过拟合的“读死书”问题
人工智能模型训练技术:随机失活,丢弃法,Dropout的更多相关文章
- 理解dropout——本质是通过阻止特征检测器的共同作用来防止过拟合 Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了
理解dropout from:http://blog.csdn.net/stdcoutzyx/article/details/49022443 http://www.cnblogs.com/torna ...
- 小白学习之pytorch框架(6)-模型选择(K折交叉验证)、欠拟合、过拟合(权重衰减法(=L2范数正则化)、丢弃法)、正向传播、反向传播
下面要说的基本都是<动手学深度学习>这本花书上的内容,图也采用的书上的 首先说的是训练误差(模型在训练数据集上表现出的误差)和泛化误差(模型在任意一个测试数据集样本上表现出的误差的期望) ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- MXNET:丢弃法
除了前面介绍的权重衰减以外,深度学习模型常常使用丢弃法(dropout)来应对过拟合问题. 方法与原理 为了确保测试模型的确定性,丢弃法的使用只发生在训练模型时,并非测试模型时.当神经网络中的某一层使 ...
- 谷歌大规模机器学习:模型训练、特征工程和算法选择 (32PPT下载)
本文转自:http://mp.weixin.qq.com/s/Xe3g2OSkE3BpIC2wdt5J-A 谷歌大规模机器学习:模型训练.特征工程和算法选择 (32PPT下载) 2017-01-26 ...
- 【神经网络】丢弃法(dropout)
丢弃法是一种降低过拟合的方法,具体过程是在神经网络传播的过程中,随机"沉默"一些节点.这个行为让模型过度贴合训练集的难度更高. 添加丢弃层后,训练速度明显上升,在同样的轮数下测试集 ...
- 零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程. 1.通用文本分类技术UTC介绍 本项目提供基于通用文本分类 UTC(Universal Text C ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- 深度学习面试题14:Dropout(随机失活)
目录 卷积层的dropout 全连接层的dropout Dropout的反向传播 Dropout的反向传播举例 参考资料 在训练过程中,Dropout会让输出中的每个值以概率keep_prob变为原来 ...
随机推荐
- 22.11.20 ICPC合肥站 打星记录
A,B,H签到. B题:注意区分相对误差与绝对误差!!小数相对误差小于1e-6,至少要输出十二位! G题优先队列.场上十几分钟就想出来了,表扬自己一波,留个坑位写题解. M题情况不多直接暴搜, 最后一 ...
- Go 互斥锁 Mutex 源码分析(二)
原创文章,欢迎转载,转载请注明出处,谢谢. 0. 前言 在 Go 互斥锁 Mutex 源码分析(一) 一文中分析了互斥锁的结构和基本的抢占互斥锁的场景.在学习锁的过程中,看的不少文章是基于锁的状态解释 ...
- cdh6.3.2 hue集成hbase
参考地址:https://blog.csdn.net/u010886217/article/details/98606976
- 在 Windows 中启用 Administrator 帐户
打开管理员终端. 启用: net user administrator /active:yes 关闭: net user administrator /active:no
- 自制 ShareLaTeX 镜像
Overleaf 官方的 sharelatex 镜像的 TeX Live 版本可能较旧,无法安装最新的宏包,并且往往只包含了少量的基础宏包.为了方便使用,我们可以自己构建一个使用最新 TeX Live ...
- DB\redis\zookeeper分布式锁设计
redis 参考目录: 生产级Redis 高并发分布式锁实战1:高并发分布式锁如何实现 https://www.cnblogs.com/yizhiamumu/p/16556153.html 生产级Re ...
- KernelWarehouse:英特尔开源轻量级涨点神器,动态卷积核突破100+ | ICML 2024
动态卷积学习n个静态卷积核的线性混合,加权使用它们输入相关的注意力,表现出比普通卷积更优越的性能.然而,它将卷积参数的数量增加了n倍,因此并不是参数高效的.这导致不能探索n>100的设置(比典型 ...
- 给vue+element-ui动态设置主题色(包括外链样式、内联样式、行内样式)
基本思路 实现思路:实现一个mixins混入的主题js即theme.js,注册到全局下.使用el-color-picker组件切换颜色的时候,把颜色值传递到根root下,在根实例下监听主题色的变化来更 ...
- Unity中的光源类型(向前渲染路径进行光照计算)
Unity中的光源类型 Unity中共支持4种光源类型: 平行光 点光源 聚光灯 面光源(在光照烘焙时才可以发挥作用) 光源的属性: 位置 方向(到某个点的方向) 颜色 强度 衰减(到某个点的衰减) ...
- 暑假集训CSP提高模拟8
一看见题目列表就吓晕了,还好我是体育生,后面忘了 唉这场比赛没啥好写的,要不就是太难要不就是太简单要不就是拉出去写在专题里了 A. 基础的生成函数练习题 考虑到只有奇偶性相同才能尝试加二,因此先用加一 ...