【Python】【爬虫】【爬狼】003_获取搜索结果的页数
# 获取搜索内容的页数
需要的包
import urllib.request # 获取网页源码
import re # 正则表达式,进行文字匹配
from bs4 import BeautifulSoup # 解析网页
解析网页
第一步,解析网页为网页源码(【Python】【爬虫系列】【爬狼】002_自定义获取网页源码的函数 - 萌狼蓝天 - 博客园 (cnblogs.com/mllt))
# 获取网页源码
response_html = xrilang_UrlToDocument(Url)
# xrilang_UrlToDocument是我自定义函数,如果你没写这个函数,直接使用,会报错的。
# 如果你想了解这个函数的具体内容,请看【爬狼系列】笔记第002篇
获取搜索内容的页数
分析网页

切换页数,观察地址栏变化。
根据观察第二页、第三页链接如下
# 第二页
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=1
# 第三页
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=2
由此可以推测出,第一页的地址为
https://www.yhdmp.cc/s_all?kw=love&pagesize=24&pageindex=0
s_all:Search All 搜索全部
kw:Key Word
pagesize:页面大小(一页有多少个视频)
pageindex:页面索引(索引从0开始,代表页数。索引0是第一页,索引1是第二页,以此类推)
获取视频数量

此处会显示视频数量,我们只需取出这个“数字”就可以了。
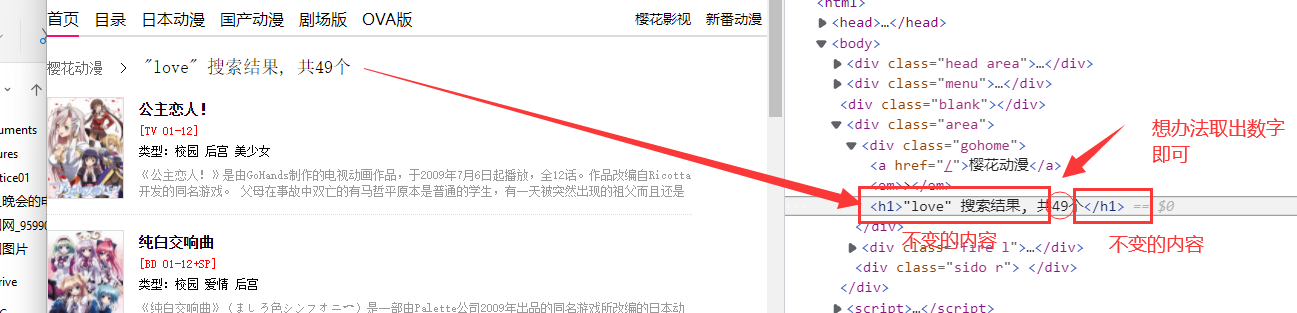
方法1
# 1.获取所搜结果视频数量
reStr1 = r'''搜索结果, 共(.*?)个''' # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
方法2(推荐使用)
# 1.获取所搜结果视频数量
reStr1 = re.compile(r'''搜索结果, 共(.*?)个''') # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
通过视频数量获取页数
通过分析,我们知道,一页有24个视频,视频总数在上面已经求出来了,那么会有多少页呢,这就是一个小学的题了。
视频总数/每页展示视频数=总页数
即:视频总数/24=总页数
注意,如果有余数,则直接+1,结果为整数
# 通过视频数量判断有多少页
# pageNumber = int(mvNumber) / 24
# 运行结果为:2.0416666666666665
# 求出页数
if (int(mvNumber) % 24) == 0:
pageNumber = int(mvNumber) / 24
else:
pageNumber = int(int(mvNumber) / 24) + 1
# 最终得到页数结果 pageNumber
# mvNumber是视频总数
将此功能编写为函数
为了方便求页数,我们需要将次功能编写为函数方便我们使用
def xrilag_SearchAll(keyword):
"""
'获取搜索内容的总页数'
:param keyword:搜索的关键字
:return:int 搜索结果的总页数
"""
# 基础链接
baseUrl = "https://www.yhdmp.cc/s_all?ex=1&kw="
Url = baseUrl + keyword
# 获取网页源码
response_html = xrilang_UrlToDocument(Url)
# 1.获取所搜结果视频数量
reStr1 = re.compile(r'''搜索结果, 共(.*?)个''') # 正则规则
# temp = re.findall(reStr1, response_html) # 在 response_html 中查找符合上述正则规则(reStr1)的内容
# 运行结果为:['49']
mvNumber = re.findall(reStr1, response_html)[0] # 取出列表的第一项(索引为0) 设置变量mvNumber(搜索得到的视频数量)
# 运行结果为:49
# 通过视频数量判断有多少页
# pageNumber = int(mvNumber) / 24
# 运行结果为:2.0416666666666665
# 求出页数
if (int(mvNumber) % 24) == 0:
pageNumber = int(mvNumber) / 24
else:
pageNumber = int(int(mvNumber) / 24) + 1
# 最终得到页数结果 pageNumber
return pageNumber
学习本文,最重要的是学习思维和处理方式
【Python】【爬虫】【爬狼】003_获取搜索结果的页数的更多相关文章
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 使用python爬虫爬取链家潍坊市二手房项目
使用python爬虫爬取链家潍坊市二手房项目 需求分析 需要将潍坊市各县市区页面所展示的二手房信息按要求爬取下来,同时保存到本地. 流程设计 明确目标网站URL( https://wf.lianjia ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
随机推荐
- iOS本地化NSLocalizedString的使用小结
在iOS设备,包括iPhone和iPad是全球可用.显然,iOS用户都来自不同国家,说着不同的语言.为了提供出色的用户体验,你可能希望以多种语言提供您的应用程序.适应应用程序以支持特定语言的过程通常被 ...
- 什么是 DOM
百度: DOM 定义:文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口.它是一种与平台和语言无关的应用程序接口(API),它可 ...
- 谈一谈 vuex 的运行机制
Vuex提供数据(state)来驱动视图(vue components),通过dispath派发actions,在其中可以做一些异步的操作,然后通过commit来提交mutations,最后mutat ...
- 0608-nn和autograd的区别
0608-nn和autograd的区别 目录 一.nn 和 autograd 的区别 二.Function 和 Module 在实际中使用的情况 pytorch完整教程目录:https://www.c ...
- Android复习(二)应用资源
1. res下的资源类型 目录 资源类型 animator/ 用于定义属性动画的 XML 文件. anim/ 用于定义渐变动画的 XML 文件.(属性动画也可保存在此目录中,但为了区分这两种类型,属性 ...
- KubeSphere 部署 Kafka 集群实战指南
本文档将详细阐述如何利用 Helm 这一强大的工具,快速而高效地在 K8s 集群上安装并配置一个 Kafka 集群. 实战服务器配置(架构 1:1 复刻小规模生产环境,配置略有不同) 主机名 IP C ...
- KubeSphere 社区双周报 | KubeKey v3.0.7 发布 | 2023-02-03
KubeSphere 从诞生的第一天起便秉持着开源.开放的理念,并且以社区的方式成长,如今 KubeSphere 已经成为全球最受欢迎的开源容器平台之一.这些都离不开社区小伙伴的共同努力,你们为 Ku ...
- 如何使用 VuePress 搭建博客网站并 Vercel 部署
先来看一下网站截图: 快速上手 1.创建并进入一个新目录 mkdir vuepress-starter && cd vuepress-starter 2.使用你喜欢的包管理器进行初始化 ...
- Java 面向对象高级
文章目录 1.静态 1.1 static修饰成员变量 1.2 static修饰成员变量的应用场景 1.3 static修饰成员方法 1.4 工具类 1.5 static的注意事项 1.6 static ...
- PLSQL安装配置与汉化
一.下载安装 1.官方安装包下载链接:https://www.allroundautomations.com/plsqldev.html 如下图所示,可自行选择32位或者64位 2.下载后双击安装至指 ...