seq2seq(1)- EncoderDecoder架构
零
seq2seq是从序列到序列的学习过程,最重要的是输入序列和输出序列是可变长的,这种方式就非常灵活了,典型的机器翻译就是这样一个过程。
一
最基本的seq2seq网络架构如下所示:
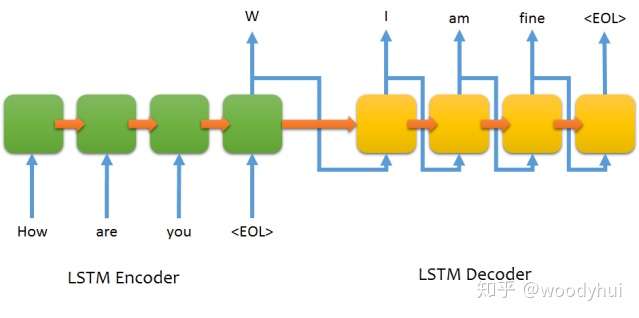
可以看到,encoder构成一个RNN的网络,decoder也是一个RNN的网络。训练过程和推断过程有一些不太一样的地方,介绍如下。
训练过程:
- encoder构成一个RNN网络,输入为源语言的文本,输出最后一个timestep的hidden state,同时不需要output,将最后一个hidden state作为decoder的初始化state;
- decoder也构成一个RNN网络,输入为目标语言的文本,这个地方要注意的是输入需要往后lag一个位置,输出就是正常的目标语言文本即可,选用categorical cross entropy进行多分类训练。
# input sentence
How are you
# output sentence
I am fine
# encoder input
["How", "are", "you"]
# decoder input
["<start tag>", "I", "am", "fine"]
# decoder target
["I", "am", "fine", "<end tag>"]推断过程:
推断过程只有encoder input了,所以有个greedy/sampling/beam-search等decoding的方法,下面讨论最简单的greedy方法。
- 将源语言的输入经过encoder编码成最后timestep的hidden state;
- 目标语言的输入设定成一个单词<start tag>,喂给decoder,产出一个目标单词;
- 将上一步的目标的单词作为目标语言新的输入,继续2的步骤,直到遇到<end tag>,或者产生的预测sequence长度超过阈值。
二
以上就是最基本的seq2seq架构,优点就是简单,缺点也很明显,我们人类一般翻译文本的时候,目标语言单词往往只和源语言文本其中有限一两个单词有关,而上面的做法,将源语言文本编码成一个固定长度的hidden state,导致decoder过程中每个单词都是受固定state的影响,而没有差异化和重点,由此下一篇会介绍seq2seq优化的比较重要的一个机制 - Attention Mechanism。
seq2seq(1)- EncoderDecoder架构的更多相关文章
- 6. 从Encoder-Decoder(Seq2Seq)理解Attention的本质
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- 深度学习的seq2seq模型——本质是LSTM,训练过程是使得所有样本的p(y1,...,yT‘|x1,...,xT)概率之和最大
from:https://baijiahao.baidu.com/s?id=1584177164196579663&wfr=spider&for=pc seq2seq模型是以编码(En ...
- RNN/LSTM/GRU/seq2seq公式推导
概括:RNN 适用于处理序列数据用于预测,但却受到短时记忆的制约.LSTM 和 GRU 采用门结构来克服短时记忆的影响.门结构可以调节流经序列链的信息流.LSTM 和 GRU 被广泛地应用到语音识别. ...
- seq2seq和attention应用到文档自动摘要
一.摘要种类 抽取式摘要 直接从原文中抽取一些句子组成摘要.本质上就是个排序问题,给每个句子打分,将高分句子摘出来,再做一些去冗余(方法是MMR)等.这种方式应用最广泛,因为比较简单.经典方法有Lex ...
- seq2seq模型以及其tensorflow的简化代码实现
本文内容: 什么是seq2seq模型 Encoder-Decoder结构 常用的四种结构 带attention的seq2seq 模型的输出 seq2seq简单序列生成实现代码 一.什么是seq2seq ...
- NMT 机器翻译
本文近期学习NMT相关知识,学习大佬资料,汇总便于后期复习用,有问题,欢迎斧正. 目录 RNN Seq2Seq Attention Seq2Seq + Attention Transformer Tr ...
- TACOTRON:端到端的语音合成
tacotron主要是将文本转化为语音,采用的结构为基于encoder-decoder的Seq2Seq的结构.其中还引入了注意机制(attention mechanism).在对模型的结构进行介绍之前 ...
- CNN卷积神经网络的改进(15年最新paper)
回归正题,今天要跟大家分享的是一些 Convolutional Neural Networks(CNN)的工作. 大家都知道,CNN 最早提出时,是以一定的人眼生理结构为基础,然后逐渐定下来了一些经典 ...
- Google工程师亲授 Tensorflow2.0-入门到进阶
第1章 Tensorfow简介与环境搭建 本门课程的入门章节,简要介绍了tensorflow是什么,详细介绍了Tensorflow历史版本变迁以及tensorflow的架构和强大特性.并在Tensor ...
随机推荐
- list:[::5]
0-99的数列 L = [0, 1, 2, 3, ..., 99] 所有数,每5个取一个 >>> L[::5] [0, 5, 10, 15, 20, 25, 30, 35, 40, ...
- idea清除缓存和索引
转自:https://blog.csdn.net/mzy755423868/article/details/80559381
- Asp.net Mvc 数据库上下文初始化器
在Asp.net Mvc 和Entity FrameWork程序中,如果数据库不存在,EF默认的行为是新建一个数据库.如果模型类与已有的数据库不匹配的时候,会抛出一个异常. 通过指定数据库上下文对象初 ...
- The Power of Android Action Bars(转载)
转自:http://www.informit.com/articles/article.aspx?p=1743642
- 利用爬虫将Yuan先生的博客文章爬取下来
由于一次巧遇,我阅读了Yuan先生的一篇博客文章,感觉从Yuan先生得博客学到很多东西,很喜欢他得文章.于是我就关注了他,并且想阅读更多出自他手笔得博客文章,无奈,可能Yuan先生不想公开自己得博客吧 ...
- 题解报告:hdu 1230 火星A+B(字符串)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1230 Problem Description 读入两个不超过25位的火星正整数A和B,计算A+B.需要 ...
- C# 基础知识和VS2010的小技巧总汇
看了一些基础视频,才发现自己的基础比较薄弱,有很多基础知识都不知道.这里总汇一些基础知识. 1: foreach不仅可以作用于list类的索引集合,还可以遍历dictionary类,这一点比for更简 ...
- 图形化unix/linux 工具 mobarxterm
1.使用 mobarxterm 图形化登录工具 2. 如果服务器是图形化界面启动的,xhost +命令可以不用执行 [root@test ~]# xhost +xhost: unable to o ...
- JMeter(十一)内存溢出解决方法
使用jmeter进行压力测试时遇到一段时间后报内存溢出outfmenmory错误,导致jmeter卡死了,先尝试在jmeter.bat中增加了JVM_ARGS="-Xmx2048m -Xms ...
- 鼠标适配器Adapter
先来看看概念: 现在我们要写一个这样的东西,就是一个窗口,然后鼠标点一下就有一个小圆点,like this: 来我们来看代码: import java.awt.*; import java.util. ...