DeepMind:所谓SACX学习范式
机器人是否能应用于服务最终还是那两条腿值多少钱,而与人交互,能真正地做“服务”工作,还是看那两条胳膊怎么工作。大脑的智能化还是非常遥远的,还是先把感受器和效应器做好才是王道。
关于强化学习,根据Agent对策略的主动性不同划分为主动强化学习(学习策略:必须自己决定采取什么行动)和被动强化学习(固定的策略决定其行为,为评价学习,即Agent如何从成功与失败中、回报与惩罚中进行学习,学习效用函数)。
被动强化学习:EnforceLearning-被动强化学习
主动强化学习:EnforceLearning-主动强化学习
文章:SACX新范式,训练用于机器人抓取任务
DeepMind提出调度辅助控制(Scheduled Auxiliary Control,SACX),这是强化学习(RL)上下文中一种新型的学习范式。SAC-X能够在存在多个稀疏奖励信号的情况下,从头开始(from scratch)学习复杂行为。为此,智能体配备了一套通用的辅助任务,它试图通过off-policy强化学习同时从中进行学习。
这个长向量的形式化以及优化为论文的亮点。
由四个基本准则组成:状态配备多个稀疏奖惩向量-一个稀疏的长向量;每个奖惩被分配策略-称为意图,通过最大化累计奖惩向量反馈;建立一个高层的选择执行特定意图的机制用以提高Agent的表现;学习是基于off-policy(新策略,Q值更新使用新策略),且意图之间的经验共享增加效率。总体方法可以应用于通用领域,在此我们以典型的机器人任务进行演示。
基于Off-Play的好处:https://www.zhihu.com/question/57159315
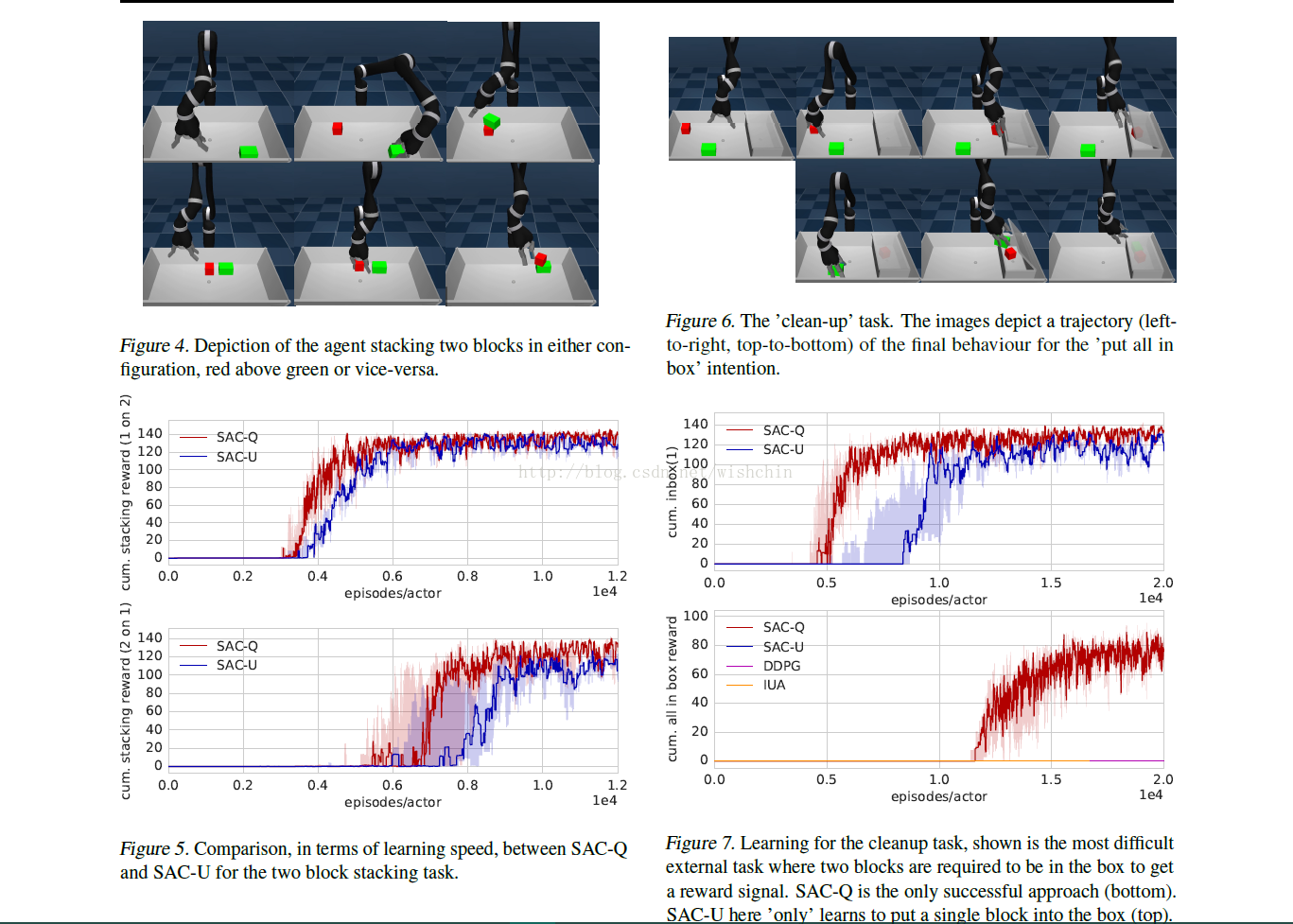
论文:Learning by Playing – Solving Sparse Reward Tasks from Scratch
DeepMind:所谓SACX学习范式的更多相关文章
- 学习世界模型,通向AI的下一步:Yann LeCun在IJCAI 2018上的演讲
https://baijiahao.baidu.com/s?id=1606296521706399213&wfr=spider&for=pc 机器之心整理,机器之心编辑部. 人工智能顶 ...
- 学习笔记TF037:实现强化学习策略网络
强化学习(Reinforcement Learing),机器学习重要分支,解决连续决策问题.强化学习问题三概念,环境状态(Environment State).行动(Action).奖励(Reward ...
- 深度学习在CTR预估中的应用
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由鹅厂优文发表于云+社区专栏 一.前言 二.深度学习模型 1. Factorization-machine(FM) FM = LR+ e ...
- 学界| UC Berkeley提出新型分布式框架Ray:实时动态学习的开端—— AI 应用的系统需求:支持(a)异质、并行计算,(b)动态任务图,(c)高吞吐量和低延迟的调度,以及(d)透明的容错性。
学界| UC Berkeley提出新型分布式框架Ray:实时动态学习的开端 from:https://baijia.baidu.com/s?id=1587367874517247282&wfr ...
- AI面试必备/深度学习100问1-50题答案解析
AI面试必备/深度学习100问1-50题答案解析 2018年09月04日 15:42:07 刀客123 阅读数 2020更多 分类专栏: 机器学习 转载:https://blog.csdn.net ...
- Generalizing from a Few Examples: A Survey on Few-Shot Learning(从几个例子总结经验:少样本学习综述)
摘要:人工智能在数据密集型应用中取得了成功,但它缺乏从有限的示例中学习的能力.为了解决这一问题,提出了少镜头学习(FSL).利用先验知识,可以快速地从有限监督经验的新任务中归纳出来.为了全面了解FSL ...
- 13.深度学习(词嵌入)与自然语言处理--HanLP实现
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 13. 深度学习与自然语言处理 13.1 传统方法的局限 前面已经讲过了隐马尔可夫 ...
- Flink + 强化学习 搭建实时推荐系统
如今的推荐系统,对于实时性的要求越来越高,实时推荐的流程大致可以概括为这样: 推荐系统对于用户的请求产生推荐,用户对推荐结果作出反馈 (购买/点击/离开等等),推荐系统再根据用户反馈作出新的推荐.这个 ...
- MySQL数据库基础-2范式
数据库结构设计 范式 设计数据库的规范 第12345范式,凡是之间有依赖关系. 关系模型的发明者埃德加·科德最早提出这一概念,并于1970 年代初定义了第一范式.第二范式和第三范式的概念 设计关系数据 ...
随机推荐
- Android应用程序安装过程浅析
我们知道在android中.安装应用是由PackageManager来管理的,可是我们发现PackageManager是一个抽象类.他的installPackage方法也没有详细的实现. 那在安装过程 ...
- LinQ开篇介绍
语言集成查询(LINQ)是 Visual Studio2008中引入的一组功能. 可为 C# 和 Visual Basic 语言语法提供强大的查询功能. LINQ引入了标准易学的数据查询和更新模式,能 ...
- Linux操作系统改动PATH的方法
1. 暂时改动: 使用export.比如#export PATH=$PATH:/etc/apache/bin 2. 针对用户的改动: vi ~/.bash_profile 增加:export PATH ...
- C Language Study - gets , getchar & scanf
慢慢的发现C语言功底是如此的薄弱,被这几个字符输入函数搞糊涂了又~~ 来,再来忧伤一次吧~ 那么.我们从scanf開始: 假如说你要将一串字符输入到一字符数组里,例如以下面程序, char a[2]; ...
- 鸟哥的Linux私房菜-----1、Linux是什么与怎样学习Linux
- Wget下载多个链接
需要wget下载多个文件链接时,可以采用如下方法: 1. 将链接存入文件url.list中: 2. wget -bc -i url.list -o [log_file] -P [target_dir] ...
- 关于ExecuteNonQuery执行存储过程的返回值 、、实例讲解存储过程的返回值与传出参数、、、C#获取存储过程的 Return返回值和Output输出参数值
关于ExecuteNonQuery执行存储过程的返回值 用到过ExecuteNonQuery()函数的朋友们在开发的时候肯定这么用过. if(cmd.ExecuteNonQuery("xxx ...
- ADT20 混淆编译
注意:一定要 android代码混淆,整了两天怎么也弄不去来,百度翻遍了也都是怎么配置cfg文件,怎么混淆成功的喜悦,我就气死了,怎么都不成功.真是气死了,不过功夫不负有心人,终究还是弄出来了. 不能 ...
- luogu 1121 环状最大两段子段和
题目大意: 一个序列看做一个环 选两段数使它们和最大 思路: 定义一个dp数组i j 0/1 表示前i个取了连续的j段 0/1表示取不取第i个 但是因为看做一个环 首尾相接的情况可以看做是选三段,其中 ...
- tyvj 1013 找啊找啊找GF
题目大意: 有一个背包,里面的东西需要满足两个条件,不只是体积 求最多能装多少东西,这些东西的东西最小价值 思路: 双重背包 开两个数组,记录装的东西数量和价值 #include<iostrea ...