hadoop-2.4.1集群搭建及zookeeper管理
准备
1.1修改主机名,设置IP与主机名的映射
[root@xuegod74 ~]# vim /etc/hosts
192.168.1.73 xuegod73
192.168.1.74 xuegod74
192.168.1.75 xuegod75
192.168.1.76 xuegod76
192.168.1.77 xuegod77
192.168.1.78 xuegod78
192.168.1.79 xuegod79
192.168.1.80 xuegod80
192.168.1.81 xuegod81
1.2清空防火墙规则,设置防火墙开机自动关闭
[root@xuegod74 ~]# iptables -F
[root@xuegod74 ~]# service iptables stop
[root@xuegod74 ~]# chkconfig iptables off
[root@xuegod74 ~]# chkconfig iptables --list
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
1.3添加用户及用户组(这步是给普通用户执行的,本实验是root 用户下运行的,普通用户类似,只要用root赋予权限即可,没什么给什么···)
[root@xuegod74 ~]# groupadd hadoop
[root@xuegod74 ~]# useradd hadoop -g hadoop
[root@xuegod74 ~]# echo 123456 | passwd --stdin hadoop
1.4配置节点之间的ssh互信机制
1.4.1生成密钥(前提是已经安装了openssh,如果没有安装的话要配置下yum源,执行yum install openssh openssh-* -y进行安装)
[root@xuegod74 ~]# ssh-keygen #生成密钥
[root@xuegod74 ~]# ssh-copy-id xuegod74 #依次执行(xuegod75,xuegod76,xuegod77,xuegod78,xuegod79,xuegod80)注意这步要包括本机。
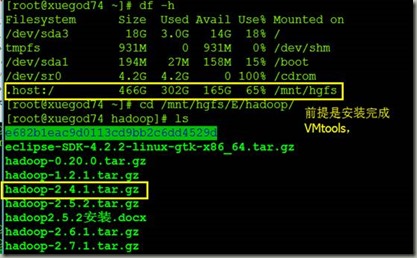
2.1上传软件包
[root@xuegod74 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 18G 3.0G 14G 18% /
tmpfs 931M 0 931M 0% /dev/shm
/dev/sda1 194M 27M 158M 15% /boot
/dev/sr0 4.2G 4.2G 0 100% /cdrom
.host:/ 466G 302G 165G 65% /mnt/hgfs
[root@xuegod74 ~]# cd /mnt/hgfs/E/hadoop/
[root@xuegod74 hadoop]# ls
e682b1eac9d0113cd9bb2c6dd4529d
eclipse-SDK-4.2.2-linux-gtk-x86_64.tar.gz
hadoop-0.20.0.tar.gz
hadoop-1.2.1.tar.gz
hadoop-2.4.1.tar.gz
hadoop-2.5.2.tar.gz
hadoop2.5.2安装.docx
hadoop-2.6.1.tar.gz
hadoop-2.7.1.tar.gz
hadoop-2.7.1.txt
hadoop2.7.1安装.docx
hadoop安装.docx
pig-0.7.0.tar.gz
zookeeper-3.3.2.tar.gz
(也可以用ssh远程连接工具直接用rz上传)
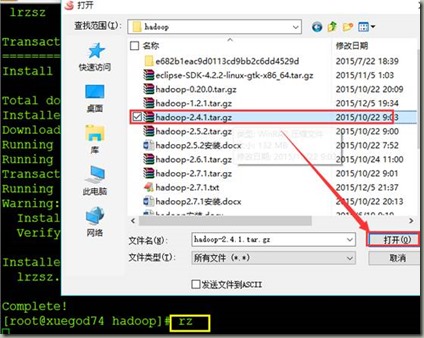
[root@xuegod74 hadoop]# tar -xvf hadoop-2.4.1.tar.gz -C /usr/src/
[root@xuegod74 Java]# cp jdk-8u66-linux-x64.rpm /usr/src/

[root@xuegod74 src]# rpm -ivh jdk-8u66-linux-x64.rpm
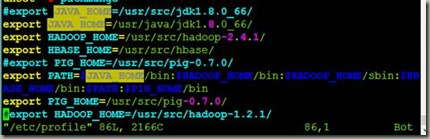
2.2配置环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_66/
export HADOOP_HOME=/usr/src/hadoop-2.4.1/
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HB
ASE_HOME/bin:$PATH:$PIG_HOME/bin
2.3hadoop安装配置配置
总共需要配置
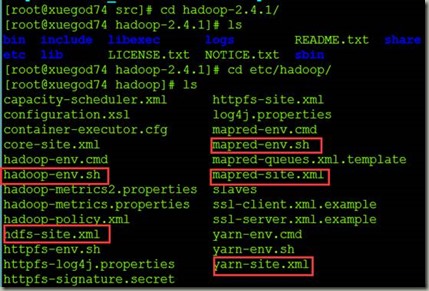
2.3.1 hadoop-env.sh配置
[root@xuegod74 hadoop]# vim hadoop-env.sh

2.3.2 hdfs-site.xml配置
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<value>xuegod74:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>xuegod74:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>xuegod75:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.4.1/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.Configur
edFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
2.3.3 core-site.xml
[root@xuegod74 hadoop]# vim core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.4.1/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>xuegod78:2181,xuegod79:2181,xuegod80:2181</value>
</property>
</configuration>
2.3.4 mapred-site.xml
[root@xuegod74 hadoop]# vim mapred-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.3.5 yarn-site.xm
[root@xuegod74 hadoop]# vim yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>xuegod76</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>xuegod77</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>xuegod78:2181,xuegod79:2181,xuegod80:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.4在xuegod77、xuegod79、xuegod80上面配置zookeeper
上传zookeeper软件包方法同上

[root@xuegod78 src]# cd zookeeper-3.4.7/conf/
[root@xuegod78 conf]# cdcp zoo_sample.cfg zoo.cfg
[root@xuegod78 conf]# ls

2.4.1 配置zookeeper
[root@xuegod78 conf]# vim zoo.cfg

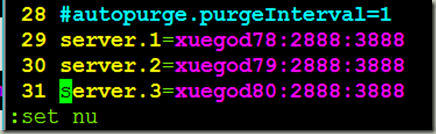
[root@xuegod78 ~]# mkdir -p /home/zookeeper-3.4.7/tmp
[root@xuegod78 ~]# echo 1 > !$/myid
[root@xuegod74 ~]# start-dfs.sh
[root@xuegod78 ~]# cat !$

2.4.2 配置环境变量
[root@xuegod78 ~]# vim /etc/profile
export JAVA_HOME=/usr/src/jdk1.8.0_66/
export JAVA_HOME=/usr/java/jdk1.8.0_66/
export HADOOP_HOME=/usr/src/hadoop-2.4.1/
export ZOOKEEPER_HOME=/usr/src/zookeeper-3.4.7/
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PA
TH:$ZOOKEEPER_HOME/bin
是配置文件生效
[root@xuegod78 ~]# source !$
2.4.3验证配置是否成功
[root@xuegod78 ~]# zkServer.sh status #这里已经启动所以会有以下信息,如果是配置成功的话直接zkS键入之后按下Tab键就可以自动补全,证明zookeeper安装配置成功。
ZooKeeper JMX enabled by default
Using config: /usr/src/zookeeper-3.4.7/bin/../conf/zoo.cfg
Mode: follower
2.4.4 将配置好的zookeeper拷贝到xuegod79和xuegod80上面
[root@xuegod78 ~]# scp -r /usr/src/zookeeper-3.4.7/ xuegod79:/usr/src/
[root@xuegod78 ~]# scp -r /usr/src/zookeeper-3.4.7/ xuegod80:/usr/src/
同样分别在xuegod79和xuegod80上面创建mkdir /home/zookeeper-3.4.7/tmp/
echo 2 > /home/zookeeper-3.4.7/tmp/myid #xuegod79上面
echo 3 > /home/zookeeper-3.4.7/tmp/myid #xuegod80上面
3.1在xuegod74上面讲配置好的文件拷贝到其他节点
[root@xuegod74 hadoop]# scp -r /usr/src/hadoop-2.4.1/ xuegod75:/usr/src/
[root@xuegod74 hadoop]# scp /etc/profile xuegod75:/etc/
以上操作要一次拷贝到xuegod76 xuegod77 xuegod78 xuegod79 xuegod80上面。
4.启动集群
4.1首先分别在xuegod78,xuegod79和xuegod80上面启动zookeeper
4.1.1启动zookeeper
[root@xuegod78 ~]# zkServer.sh start #要分别在xuegod79 xuegod80上面执行
ZooKeeper JMX enabled by default
Using config: /usr/src/zookeeper-3.4.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
4.1.2启动journalnode(分别在在xuegod78 xuegod79 xuegod80上执行)
[root@xuegod78 ~]# hadoop-daemon.sh start journalnode
4.1.3格式化HDFS,在xuegod74上面
[root@xuegod74 hadoop]# hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置
的是/home/hadoop/app/hadoop-2.4.1/tmp,然后将/home/hadoop/app/hadoop-2.4.1/tmp拷贝到xuegod75的/home/hadoop/app/hadoop-2.4.1/tmp下.
[root@xuegod74 ~]#scp -r /home/hadoop/app/hadoop-2.4.1/tmp/ xuegod75:/home/hadoop/app/hadoop-2.4.1/

建议是使用hdfs namenode -bootstrapStandby来格式化
4.1.4格式化ZKFC(在xuegod74上)
[root@xuegod74 ~]# hdfs zkfc -format
4.2 启动HDFS(在xuegod74上)
[root@xuegod74 ~]# start-dfs.sh
4.3 启动启动YARN(在xuegod75上)
[root@xuegod75 ~]# start-yarn.sh
5查看
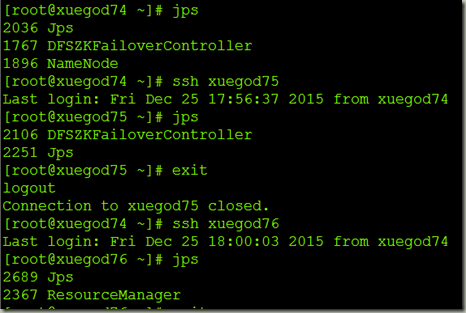
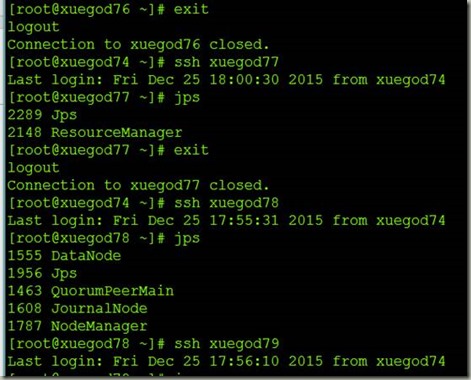
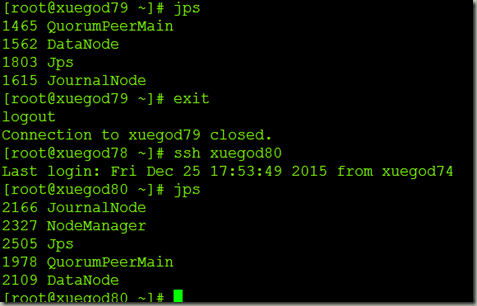
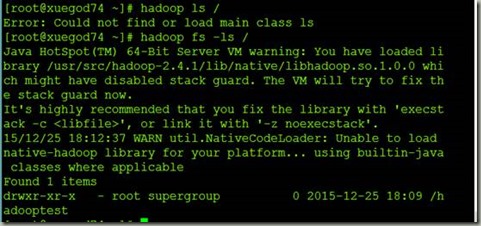
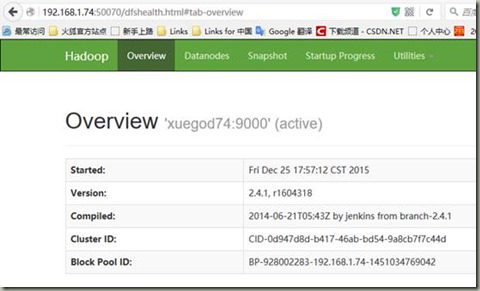
6关闭集群
[root@xuegod74 ~]# stop-all.sh
[root@xuegod74 ~]# ssh xuegod78 #手动关闭xuegod79 xuegod80上的zookeeper
[root@xuegod78 ~]# zkServer.sh stop
注:若有错误请诸君指正,谢谢~
hadoop-2.4.1集群搭建及zookeeper管理的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机 ...
- 高可用Hadoop平台-HBase集群搭建
1.概述 今天补充一篇HBase集群的搭建,这个是高可用系列遗漏的一篇博客,今天抽时间补上,今天给大家介绍的主要内容目录如下所示: 基础软件的准备 HBase介绍 HBase集群搭建 单点问题验证 截 ...
- Hadoop初期学习和集群搭建
留给我学习hadoop的时间不多了,要提高效率,用上以前学的东西.hadoop要注重实战,把概念和原理弄清楚,之前看过一些spark,感觉都是一些小细节,对于理解hadoop没什么帮助.多看看资料,把 ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- hadoop HA+kerberos HA集群搭建
IP.主机名规划 hadoop集群规划: hostname IP hadoop 备注 hadoop1 110.185.225.158 NameNode,ResourceManager,DFSZKFai ...
- 第3章 Hadoop 2.x分布式集群搭建
目录 3.1 配置各节点SSH无密钥登录 1.将各节点的秘钥加入到同一个授权文件中 2.拷贝授权文件到各个节点 3.测试无秘钥登录 3.2 搭建Hadoop集群 1.上传Hadoop并解压 2.配置H ...
- 3.环境搭建-Hadoop(CDH)集群搭建
目录 目录 实验环境 安装 Hadoop 配置文件 在另外两台虚拟机上搭建hadoop 启动hdfs集群 启动yarn集群 本文主要是在上节CentOS集群基础上搭建Hadoop集群. 实验环境 Ha ...
随机推荐
- USACO castle
<pre name="code" class="cpp"><pre>USER: Kevin Samuel [kevin_s1] TASK ...
- 鸟哥的Linux私房菜-----13、账号管理
- E. Dreamoon and Strings(Codeforces Round #272)
E. Dreamoon and Strings time limit per test 1 second memory limit per test 256 megabytes input stand ...
- 【手记】小心在where中使用NEWID()的大坑 【手记】解决启动SQL Server Management Studio 17时报Cannot find one of more components...的问题 【C#】组件分享:FormDragger窗体拖拽器 【手记】注意BinaryWriter写string的小坑——会在string前加上长度前缀length-prefixed
[手记]小心在where中使用NEWID()的大坑 这个表达式: ABS(CHECKSUM(NEWID())) % 3 --把GUID弄成正整数,然后取模 是随机返回0.1.2这三个数,不可能返回其它 ...
- 正向代理tinyproxy使用总结
使用tinyproxy的问题背景: 其实以前代理一直用的是apache,后来,那次有个任务要给ios的推送设置代理,任务很紧急,可是apache报错. 原因如下:APNS发送通知的端口2195,但是A ...
- java8--IO(java疯狂讲义3复习笔记)
产生文件 File file = new File("abc.txt"); if(!file.exists()){ System.out.println(file.exists() ...
- Tomcat 安装错误
安装tomcat时,遇到"failed to install tomcat6 service check your settings and permissions"的问题 安装时 ...
- 网络驱动移植之例解netdev_priv函数
版权声明:本文为博主原创文章,未经博主允许不得转载. 开发平台:Ubuntu 11.04 编译器:gcc version 4.5.2 (Ubuntu/Linaro 4.5.2-8ubuntu4) 内核 ...
- Get started with Sourcetree
Understand the interface Bookmarks window From that window, select the Local or Remote buttons to vi ...
- centos7下比特币源码编译安装
今天我们介绍比特币的源码安装过程,是利用编译安装的 首先安装依赖 1 yum install -y boost-devel qt-devel protobuf-devel qrencode-devel ...