Python网络爬虫与信息提取
1.Requests库入门
Requests安装
用管理员身份打开命令提示符:
pip install requests
测试:打开IDLE:
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code
200
>>> r.encoding = 'utf-8' #修改默认编码
>>> r.text #打印网页内容
HTTP协议
超文本传输协议,Hypertext Transfer Protocol.
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。
HTTP协议采用URL作为定位网络资源的标识。
URL格式
http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省端口为80
path:请求资源的路径
操作
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URl位置资源的响应消息报告,即获得该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |
Requests主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
主要方法为request方法,其他方法都是在此方法基础上封装而来以便使用。
request()方法
requests.request(method,url,**kwargs)
#method:请求方式,对应get/put/post等7种
#url:拟获取页面的url链接
#**kwargs:控制访问的参数,共13个
**kwargs:控制访问的参数,均为可选项
get()方法
r = requests.get(url)
完整方法:
requests.get(url,params=None,**kwargs)
url:拟获取页面的url链接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问的参数,可选
get()方法:
构造一个向服务器请求资源的Request对象
返回一个包含服务器资源的Response对象
Response对象
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即:url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
head()方法
r = requests.head('http://httpbin.org/get')
r.headers
获取网络资源的概要信息
post()方法
向服务器提交新增数据
payload = {'key1':'value1','key2':'value2'} #新建一个字典
#向URL POST一个字典,自动编码为form(表单)
r = requests.post('http://httpbin.org/post',data = payload)
#向URL POST一个字符串,自动编码为data
r = requests.post('http://httpbin.org/post',data = 'ABC')
print(r.text)
put()方法
同post,只不过会把原来的内容覆盖掉。
patch()方法
delete()方法
Requests库的异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大 重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
| 异常方法 | 说明 |
|---|---|
| r.raise_for_status | 如果不是200产生异常requests.HTTPError |
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status() #如果不是200,引发HTTPError异常
r.recoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
实例
向百度提交关键词
import requests
# 向搜索引擎进行关键词提交
url = "http://www.baidu.com"
try:
kv = {'wd':'python'}
r = requests.get(url,params =kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("产生异常")
获取网络图片及存储
import requests
import os
url = "http://image.ngchina.com.cn/2019/0423/20190423024928618.jpg"
root = "D://2345//Temp//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path,'wb') as f:
f.write(r.content) #r.content返回二进制内容
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
2.信息提取之Beautiful Soup库入门
Beautiful Soup库安装
pip install beautifulsoup4
测试:
import requests
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
form bs4 import BeautifulSoup #从bs4中引入BeautifulSoup类
soup = BeautifulSoup(demo, "html.parser")
Beautiful Soup库是解析、遍历、维护“标签树”的功能库
Beautiful Soup库的基本元素
Beautiful Soup库的引用
Beautiful Soup库,也叫beautifulsoup4或bs4.
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
Beautiful Soup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,
... 的名字是'p',格式:.name |
| Attributes | 标签的属性,字典形式组织,格式:.attrs |
| NavigableString | 标签内非属性字符串,<>...</>中字符串,格式:.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
基于bs4库的HTML内容遍历方法
下行遍历
| 属性 | 说明 |
|---|---|
| .contents(列表类型) | 子节点的列表,将所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
#遍历儿子节点
for child in soup.body.children
print(child)
#遍历子孙节点
for child in soup.body.descendants
print(child)
上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
soup = BeautifulSoup(demo,"html.parser")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
#输出结果
#p
#body
#html
#[document]
平行遍历
平行遍历发生在同一个父节点下的各节点间。
下一个获取的可能是字符串类型,不一定是下一个节点。
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
#遍历后续节点
for sibling in soup.a.next_siblings
print(sibling)
#遍历前续节点
for sibling in soup.a.previous_siblings
print(sibling)
基于bs4库的HTML格式化和编码
格式化方法:.prettify()
soup = BeautifulSoup(demo,"html.parser")
print(soup.a.prettify())
编码:默认utf-8
soup = BeautifulSoup("<p>中文</p>","html.parser")
soup.p.string
#'中文'
print(soup.p.prettify())
#<p>
# 中文
#</p>
3.信息组织与提取
信息标记的三种形式
标记后的信息可形成信息组织结构,增加了信息的维度;
标记后的信息可用于通信、存储和展示;
标记的结构和信息一样具有重要价值;
标记后的信息有利于程序的理解和运用。
XML: eXtensible Matkup Language
最早的通用信息标记语言,可扩展性好,但繁琐。
用于Internet上的信息交互和传递。
<name>...</name>
<name/>
<!-- -->
JSON: JavaScript Object Notation
信息有类型,适合程序处理(js),较XML简洁。
用于移动应用云端和节点的信息通信,无注释。
#有类型的键值对表示信息的标记形式
"key":"value"
"key":["value1","value2"]
"key":{"subkey":"subvalue"}
YAMl: YAML Ain't Markup Language
信息无类型,文本信息比例最高,可读性好。
用于各类系统的配置文件,有注释易读。
#无类型的键值对表示信息的标记形式
key : "value"
key : #comment
-value1
-value2
key :
subkey : subvalue
信息提取的一般方法
方法一:完整解析信息的标记形式,再提取关键信息。
XML JSON YAML
需要标记解析器,例如bs4库的标签树遍历。
优点:信息解析准确
缺点:提取过程繁琐,过程慢
方法二:无视标记形式,直接搜索关键信息
搜索
对信息的文本查找函数即可。
优点:提取过程简洁,速度较快
缺点:提取过程准确性与信息内容相关
融合方法:结合形式解析与搜索方法,提取关键信息
XML JSON YAML 搜索
需要标记解析器及文本查找函数。
实例:提取HTML中所有URL链接
思路: 1. 搜索到所有标签
2.解析标签格式,提取href后的链接内容
form bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
基于bs4库的HTML内容查找方法
| 方法 | 说明 |
|---|---|
| <>.find_all(name,attrs,recursive,string,**kwargs) | 返回一个列表类型,存储查找的结果 |
简写形式:(..) 等价于 .find_all(..)
#name:对标签名称的检索字符串
soup.find_all('a')
soup.find_all(['a', 'b'])
soup.find_all(True) #返回soup的所有标签信息
for tag in soup.find_all(True):
print(tag.name) #html head title body p b p a a
#输出所有b开头的标签,包括b和body
#引入正则表达式库
import re
for tag in soup.find_all(re.compile('b')):
print(tag.name) #body b
#attrs:对标签属性值的检索字符串,可标注属性检索
soup.find_all('p', 'course')
soup.find_all(id='link1')
import re
soup.find_all(id=re.compile('link'))
#recursive:是否对子孙全部检索,默认为True
soup.find_all('p', recursive = False)
#string:<>...</>字符串区域的检索字符串
soup.find_all(string = "Basic Python")
import re
soup.find_all(string = re.compile('Python'))
#简写形式:soup(..) = soup.find_all(..)
拓展方法:参数同.find_all()
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,字符串类型 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型 |
| <>.find_parent() | 在先辈节点中返回一个结果,字符串类型 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,字符串类型 |
| <>.find_previous_siblings() | 在前续平行节点中搜索,返回列表类型 |
| <>.find_previous_sibling() | 在前续平行节点中返回一个结果,字符串类型 |
4.信息提取实例
中国大学排名定向爬虫
功能描述:
输入:大学排名URL链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:requests-bs4
定向爬虫:仅对输入URL进行爬取,不拓展爬取
程序的结构设计:
步骤1:从网络上获取大学排名网页内容
getHTMLText()
步骤2:提取网页内容中信息到合适的数据结构
fillUnivList()
步骤3:利用数据结构展示并输出结果
printUnivList()
初步代码编写
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout= 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "分数"))
for i in range(num):
u = ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0], u[1], u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) #20 univs
main()
中文输出对齐问题
当输出中文的宽度不够时,系统会采用西文字符填充,导致对齐出现问题。
可以使用中文空格chr(12288)填充解决。
<填充>:用于填充的单个字符
<对齐>:<左对齐 >右对齐 ^居中对齐
<宽度>:槽的设定输出宽度
,:数字的千位分隔符适用于整数和浮点数
<精度>:浮点数小数部分的精度或字符串的最大输出长度
<类型>:整数类型b,c,d,o,x,X浮点数类型e,E,f,%
代码优化
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout= 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名", "学校名称", "分数",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2],chr(12288)))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) #20 univs
main()
5.实战之Re库入门
正则表达式
- 通用的字符串表达框架
- 简介表达一组字符串的表达式
- 针对字符串表达“简洁”和“特征”思想的工具
- 判断某字符串的特征归属
正则表达式的语法
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [ ] | 字符集,对单个字符给出取值范围 | [abc]表达式a、b、c,[a-z]表示a到z单个字符 |
| [^ ] | 非字符集,对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc* 表示 ab、abc、abcc、abccc等 |
| + | 前一个字符1次或无限次扩展 | abc+ 表示 abc、abcc、abccc等 |
| ? | 前一个字符0次或1次扩展 | abc?表示 ab、abc |
| | | 左右表达式任意一个 | abc|def 表示 abc 、def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(含n) | ab{1,2}c表示abc、abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| ( ) | 分组标记,内部只能使用|操作符 | (abc)表示abc,{abc|def}表示abc、def |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9_] |
经典正则表达式实例
| 正则表达式 | 说明 |
|---|---|
^[A-Za-z]+$ |
由26个字母组成的字符串 |
^[A-Za-z0-9]+$ |
由26个字母和数字组成的字符串 |
^-?\d+$ |
整数形式的字符串 |
^[0-9]*[1-9][0-9]*$ |
正整数形式的字符串 |
[1-9]\d{5} |
中国境内邮政编码,6位 |
[\u4e00-\u9fa5] |
匹配中文字符 |
\d{3}-\d{8}|\d{4}-\d{7} |
国内电话号码 |
Re库的基本使用
Re库是Python的标准库,主要用于字符串匹配。
正则表达式的表示类型
raw string类型(原生字符串类型),是不包含转义符\的字符串
re库采用raw string类型表示正则表达式,表示为:r'text'
例如:r'[1-9]\d{5}'
r'\d{3}-\d{8}|\d{4}-\d{7}'
Re库主要功能函数
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
re.search(pattern,string,flags=0)
re.search(pattern,string,flags=0)
在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象;
pattern:正则表达式的字符串或原生字符串表示;
string:待匹配字符串;
flags:正则表达式使用时的控制标记;
常用标记 说明 re.I|re.IGNORECASE 忽略正则表达式的大小写,[A-Z]能匹配小写字符 re.M|re.MUTILINE 正则表达式中的^操作符能够将给定字符串的每行当做匹配开始 re.S|re.DOTILL 正则表达式中的.操作符能够匹配所有字符,默认匹配除换行符外的所有字符
例子:
import re
match = re.search(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0)) #'100081'
re.match(pattern,string,flags=0)
re.match(pattern,string,flags=0)
- 从一个字符串的开始位置起匹配正则表达式,返回match对象
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- flags:正则表达式使用时的控制标记;
例子:
import re
match = re.match(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0)) #NULL
match = re.match(r'[1-9]\d{5}','100081 BIT')
if match:
print(match.group(0)) #'100081'
re.findall(pattern,string,flags=0)
re.findall(pattern,string,flags=0)
- 搜索字符串,以列表类型返回全部能匹配的子串
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- flags:正则表达式使用时的控制标记;
例子:
import re
ls = re.findall(r'[1-9]\d{5}', 'BIT100081 TSU100084')
print(ls) #['100081', '100084']
re.split(pattern,string,maxsplit=0,flags=0)
re.split(pattern,string,flags=0)
- 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- maxsplit:最大分割数,剩余部分作为最后一个元素输出;
- flags:正则表达式使用时的控制标记;
例子:
import re
ls = re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084')
print(ls) #['BIT', ' TSU', '']
ls2 = re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084', maxsplit=1)
print(ls2) #['BIT', ' TSU10084']
re.finditer(pattern,string,flags=0)
re.finditer(pattern,string,flags=0)
- 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素都是match对象
- pattern:正则表达式的字符串或原生字符串表示;
- string:待匹配字符串;
- flags:正则表达式使用时的控制标记;
例子:
import re
for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'):
if m:
print(m.group(0)) #100081 100084
re.sub(pattern,repl,string,count=0,flags=0)
re.sub(pattern,repl,string,count=0,flags=0)
- 在一个字符串中替换所有匹配正则表达式的子串,并返回替换后的字符串
- pattern:正则表达式的字符串或原生字符串表示;
- repl:替换匹配字符串的字符串;
- string:待匹配字符串;
- count:匹配的最大替换次数
- flags:正则表达式使用时的控制标记;
例子:
import re
rst = re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT 100081,TSU 100084')
print(rst) # 'BIT :zipcode TSU :zipcode'
Re库的另一种用法
编译后的对象拥有的方法和re库主要功能函数相同
#函数式用法:一次性操作
rst = re.search(r'[1-9]\d{5}', 'BIT 100081')
#面向对象用法:编译后的多次操作
pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 100081')
re.compile(pattern,flags=0)
- 将正则表达式的字符串形式编译成正则表达式对象
- pattern:正则表达式的字符串或原生字符串表示;
- flags:正则表达式使用时的控制标记;
regex = re.compile(r'[1-9]\d{5}')
Re库的match对象
import re
match = re.search(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0)) # '100081'
print(type(match)) # <class 're.Match'>
Match对象的属性
| 属性 | 说明 |
|---|---|
| .string | 待匹配的文本 |
| .re | 匹配时使用的pattern对象(正则表达式) |
| .pos | 正则表达式搜索文本的开始位置 |
| .endpos | 正则表达式搜索文本的结束位置 |
Match对象的方法
| 方法 | 说明 |
|---|---|
| .group(0) | 获得匹配后的字符串 |
| .start() | 匹配字符串在原始字符串的开始位置 |
| .end() | 匹配字符串在原始字符串的结束位置 |
| .span() | 返回(.start(),.end()) |
import re
m = re.search(r'[1-9]\d{5}', 'BIT100081 TSU100084')
print(m.string) # BIT100081 TSU100084
print(m.re) # re.compile('[1-9]\\d{5}')
print(m.pos) # 0
print(m.endpos) # 19
print(m.group(0)) # '100081' 返回的是第一次匹配的结果,获取所有使用re.finditer()方法
print(m.start()) # 3
print(m.end()) # 9
print(m.span()) # (3, 9)
Re库的贪婪匹配和最小匹配
Re库默认采用贪婪匹配,即输出匹配最长的子串。
import re
match = re.search(r'PY.*N', 'PYANBNCNDN')
print(match.group(0)) # PYANBNCNDN
最小匹配方法:
import re
match = re.search(r'PY.*?N', 'PYANBNCNDN')
print(match.group(0)) # PYAN
最小匹配操作符
| 操作符 | 说明 |
|---|---|
| *? | 前一个字符0次或无限次扩展,最小匹配 |
| +? | 前一个字符1次或无限次扩展,最小匹配 |
| ?? | 前一个字符0次或1次扩展,最小匹配 |
| {m,n}? | 扩展前一个字符m至n次(含n),最小匹配 |
Re库实例之淘宝商品比价定向爬虫
功能描述:
- 目标:获取淘宝搜索页面的信息,提取其中的商品名称和价格
- 理解:
- 淘宝的搜索接口
- 翻页的处理
- 技术路线:requests-re
程序的结构设计:
- 步骤1:提交商品搜索请求,循环获取页面
- 步骤2:对于每个页面,提取商品的名称和价格信息
- 步骤3:将信息输出到屏幕上
import requests
import re
def getHTMLText(url):
#浏览器请求头中的User-Agent,代表当前请求的用户代理信息(下方有获取方式)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
try:
#浏览器请求头中的cookie,包含自己账号的登录信息(下方有获取方式)
coo = ''
cookies = {}
for line in coo.split(';'): #浏览器伪装
name, value = line.strip().split('=', 1)
cookies[name] = value
r = requests.get(url, cookies = cookies, headers=headers, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#解析请求到的页面,提取出相关商品的价格和名称
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 2 #爬取深度,2表示爬取两页数据
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
需要注意的是,淘宝网站本身有反爬虫机制,所以在使用requests库的get()方法爬取网页信息时,需要加入本地的cookie信息,否则淘宝返回的是一个错误页面,无法获取数据。
代码中的coo变量中需要自己添加浏览器中的cookie信息,具体做法是在浏览器中按F12,在出现的窗口中进入network(网络)内,搜索“书包”,然后找到请求的url(一般是第一个),点击请求在右侧header(消息头)中找到Request Header(请求头),在请求头中找到User-Agent和cookie字段,放到代码相应位置即可。
Re库实例之股票数据定向爬虫
功能描述:
- 目标:获取上交所和深交所所有股票的名称和交易信息
- 输出:保存到文件中
- 技术路线:requests-bs4-re
候选数据网站的选择:
- 新浪股票:https://finance.sina.com.cn/stock/
- 百度股票:https://gupiao.baidu.com/stock/
- 选取原则:股票信息静态存在于HTML页面中,非js代码生成,没有Robots协议限制。
程序的结构设计
- 步骤1:从东方财富网获取股票列表
- 步骤2:根据股票列表逐个到百度股票获取个股信息
- 步骤3:将结果存储到文件
初步代码编写(error)
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html=="":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
except:
traceback.print_exc()
continue
def main():
stock_list_url = 'https://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
代码优化(error)
速度提高:编码识别的优化
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html=="":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
continue
def main():
stock_list_url = 'https://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
测试成功代码
由于东方财富网链接访问时出现错误,所以更换了一个新的网站去获取股票列表,具体代码如下:
import requests
import re
import traceback
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return""
def getStockList(lst, stockListURL):
html = getHTMLText(stockListURL)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
lst = []
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[S][HZ]\d{6}", href)[0])
except:
continue
lst = [item.lower() for item in lst] # 将爬取信息转换小写
return lst
def getStockInfo(lst, stockInfoURL, fpath):
count = 0
for stock in lst:
url = stockInfoURL + stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div', attrs={'class': 'stock-bets'})
if isinstance(stockInfo, bs4.element.Tag): # 判断类型
name = stockInfo.find_all(attrs={'class': 'bets-name'})[0]
infoDict.update({'股票名称': name.text.split('\n')[1].replace(' ','')})
keylist = stockInfo.find_all('dt')
valuelist = stockInfo.find_all('dd')
for i in range(len(keylist)):
key = keylist[i].text
val = valuelist[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
count = count + 1
print("\r当前速度:{:.2f}%".format(count*100/len(lst)), end="")
except:
count = count + 1
print("\r当前速度:{:.2f}%".format(count*100/len(lst)), end="")
traceback.print_exc()
continue
def main():
fpath = 'D://gupiao.txt'
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
slist = []
list = getStockList(slist, stock_list_url)
getStockInfo(list, stock_info_url, fpath)
main()
6.爬虫框架-Scrapy
爬虫框架:是实现爬虫功能的一个软件结构和功能组件集合。
爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
安装Scrapy
pip install scrapy
#验证
scrapy -h
遇到错误
building 'twisted.test.raiser' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": https://visualstudio.microsoft.com/downloads/
解决方案
查看python版本及位数
C:\Users\ASUS>python
Python 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 23:09:28) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.可知,python版本为3.7.2, 64位
下载Twisted
到 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载twisted对应版本的whl文件;
根据版本应下载Twisted‑17.9.0‑cp37‑cp37m‑win_amd64.whl注意:cp后面是python版本,amd64代表64位,32位的下载32位对应的文件。
安装Twisted
python -m pip install D:\download\Twisted‑19.2.0‑cp37‑cp37m‑win_amd64.whl安装Scrapy
python -m pip install scrapy
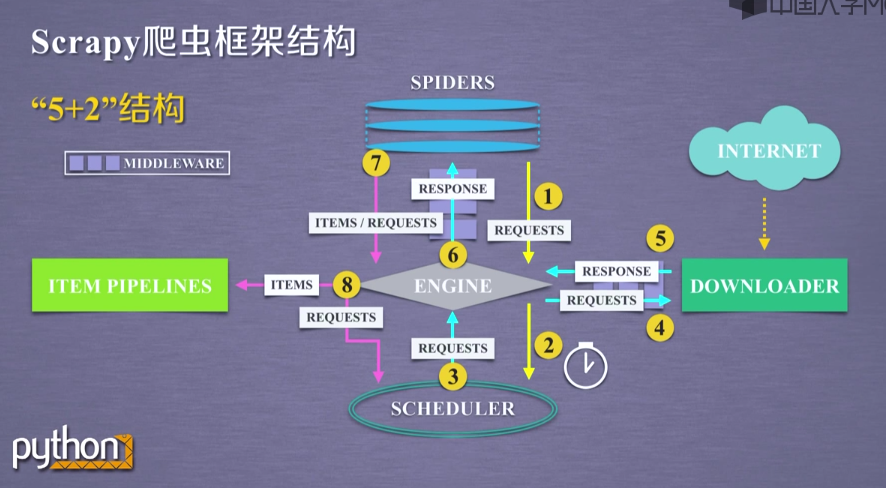
Scrapy爬虫框架解析
- Engine:不需要用户修改
- 控制所有模块之间的数据流
- 根据条件触发事件
- Downloader:不需要用户修改
- 根据请求下载网页
- Scheduler:不需要用户修改
- 对所有爬取请求进行调度管理
- Downloader Middleware:用户可编写配置代码
- 目的:实施Engine、Scheduler和Downloader之间进行用户可配置的控制
- 功能:修改、丢弃、新增请求或响应
- Spider:需要用户编写配置代码
- 解析Downloader返回的响应(Response)
- 产生爬取项(scraped item)
- 产生额外的爬取请求(Request)
- Item Pipelines:需要用户编写配置代码
- 以流水线方式处理Spider产生的爬取项
- 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
- 可能操作包括:清理、检验、和查重爬取项中的HTML数据、将数据存储到数据库
- Spider Middleware:用户可以编写配置代码
- 目的:对请求和爬取项的再处理
- 功能:修改、丢弃、新增请求或爬取项
requests vs. Scrapy
相同点
- 两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
- 两者可用性都好,文档丰富,入门简单
- 两者都没有处理js、提交表单、应对验证码等功能(可扩展)
不同点
requests Scrapy 页面级爬虫 网站级爬虫 功能库 框架 并发性考虑不足,性能较差 并发性好,性能较高 重点在于页面下载 重点在于爬虫结构 定制灵活 一般定制灵活,深度定制困难 上手十分简单 入门稍难 Scrapy爬虫的常用命令
Scrapy命令行
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject [dir] |
| genspider | 创建一个爬虫 | scrapy genspider [options] |
| settings | 获得爬虫配置信息 | scrapy setting [options] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调试命令行 | scrapy shell [url] |
Scrapy框架的基本使用
步骤1:建立一个Scrapy爬虫工程
#打开命令提示符-win+r 输入cmd
#进入存放工程的目录
D:\>cd demo
D:\demo>
#建立一个工程,工程名python123demo
D:\demo>scrapy startproject python123demo
New Scrapy project 'python123demo', using template directory 'd:\program files\python\lib\site-packages\scrapy\templates\project', created in:
D:\demo\python123demo
You can start your first spider with:
cd python123demo
scrapy genspider example example.com
D:\demo>
生成的目录工程介绍:
python123demo/ ----------------> 外层目录
scrapy.cfg ---------> 部署Scrapy爬虫的配置文件
python123demo/ ---------> Scrapy框架的用户自定义Python代码
__init__.py----> 初始化脚本 items.py ----> Items代码模板(继承类)
middlewares.py ----> Middlewares代码模板(继承类)
pipelines.py ----> Pipelines代码模板(继承类)
settings.py ----> Scrapy爬虫的配置文件
spiders/ ----> Spiders代码模板目录(继承类)
spiders/ ----------------> Spiders代码模板目录(继承类)
__init__.py--------> 初始文件,无需修改
__pycache__/--------> 缓存目录,无需修改
步骤2:在工程中产生一个Scrapy爬虫
#切换到工程目录
D:\demo>cd python123demo
#产生一个scrapy爬虫
D:\demo\python123demo>scrapy genspider demo python123.io
Created spider 'demo' using template 'basic' in module:
python123demo.spiders.demo
D:\demo\python123demo>
步骤3:配置产生的spider爬虫
修改D:\demo\python123demo\python123demo\spiders\demo.py
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname, 'wb') as f:
f.write(response.body)
self.log('Save file %s.' % name)
完整版代码编写方式
import scrapy
class DemoSpider(scrapy.Spider):
name = "demo"
def start_requests(self):
urls = [
'http://python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Requests(url=url, callback=self.parse)
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname, 'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % fname)
步骤4:运行爬虫,获取网页
#输入运行命令 scrapy crawl
D:\demo\python123demo>scrapy crawl demo
可能出现的错误
ModuleNotFoundError: No module named 'win32api'
解决方法
到 https://pypi.org/project/pypiwin32/#files 下载py3版本的pypiwin32-223-py3-none-any.whl文件;
安装pypiwin32-223-py3-none-any.whl
pip install D:\download\pypiwin32-223-py3-none-any.whl再次在工程目录下运行爬虫
scrapy crawl demo
yield关键字的使用
- yield<----------------------->生成器
- 生成器是一个不断产生值的函数;
- 包含yield语句的函数是一个生成器;
- 生成器每次产生一个值(yield语句),函数会被冻结,被唤醒后再产生一个值;
实例:
def gen(n):
for i in range(n):
yield i**2
#产生小于n的所有2的平方值
for i in gen(5):
print(i, " ", end="")
#0 1 4 9 16
#普通写法
def square(n):
ls = [i**2 for i in range(n)]
return ls
for i in square(5):
print(i, " ", end="")
#0 1 4 9 16
为何要有生成器?
- 生成器比一次列出所有内容的优势
- 更节省存储空间
- 响应更迅速
- 使用更灵活
Scrapy爬虫的使用步骤
- 步骤1:创建一个工程和Spider模板;
- 步骤2:编写Spider;
- 步骤3:编写Item Pipeline
- 步骤4:优化配置策略
Scrapy爬虫的数据类型
Request类
class scrapy.http.Request()
- Request对象表示一个HTTP请求
- 由Spider生成,由Downloader执行
| 属性或方法 | 说明 |
|---|---|
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法,’GET‘ ’POST‘等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 |
| .copy() | 复制该请求 |
Response类
class scrapy.http.Response()
- Response对象表示一个HTTP响应
- 由Downloader生成,由Spider处理
| 属性或方法 | 说明 |
|---|---|
| .url | Response对应的URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Request对象 |
| .copy() | 复制该响应 |
Item类
class scrapy.item.Item()
- Item对象表示一个从HTML页面中提取的信息内容
- 由Spider生成,由Item Pipeline处理
- Item类似字典类型,可以按照字典类型操作
CSS Selector的基本使用
.css('a::attr(href)').extract()
CSS Selector由W3C组织维护并规范。
股票数据Scrapy爬虫实例
功能描述:
- 技术路线:scrapy
- 目标:获取上交所和深交所所有股票的名称和交易信息
- 输出:保存到文件中
实例编写
- 步骤1:首先进入命令提示符建立工程和Spider模板
scrapy startproject BaiduStocks
cd BaiduStocks
scrapy genspider stocks baidu.com
#进一步修改spiders/stocks.py文件
- 步骤2:编写Spider
- 配置stock.py文件
- 修改对返回页面的处理
- 修改对新增URL爬取请求的处理
打开spider.stocks.py文件
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['https://quote.eastmoney.com/stocklist.html']
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}", href)[0]
url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
def parse_stock(self, response):
infoDict = {}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*</dt>', keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*</dd>', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key]=val
infoDict.update(
{'股票名称': re.findall('\s.*\(',name)[0].split()[0] + \
re.findall('\>.*\<', name)[0][1:-1]})
yield infoDict
- 步骤3:编写Pipelines
- 配置pipelines.py文件
- 定义对爬取项(Scrapy Item)的处理类
- 配置ITEM_PIPELINES选项
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
def open_spider(self, spider):
self.f = open('BaiduStockInfo.txt', 'w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
setting.py
# Configure item pipelines
# See https://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}
配置并发连接选项
settings.py
| 选项 | 说明 |
|---|---|
| CONCURRENT_REQUESTS | Downloader最大并发请求下载数量,默认为32 |
| CONCURRENT_ITEMS | Item Pipeline最大并发ITEM处理数量,默认为100 |
| CONCURRENT_REQUESTS_PRE_DOMAIN | 每个目标域名最大的并发请求数量,默认为8 |
| CONCURRENT_REQUESTS_PRE_IP | 每个目标IP最大的并发请求数量,默认为0,非0有效 |
来源:中国大学MOOC-北京理工大学-嵩天-Python网络爬虫与信息提取
Python网络爬虫与信息提取的更多相关文章
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- Python网络爬虫与信息提取(一)
学习 北京理工大学 嵩天 课程笔记 课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解 ...
- Python网络爬虫与信息提取(二)—— BeautifulSoup
BeautifulSoup官方介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. 官方 ...
- python网络爬虫与信息提取 学习笔记day2
Day2: 查看robots协议: 查看京东的robots协议 查看百度的robots协议,可以看到百度拒绝了搜狗的爬虫233 爬取京东商品页面相关信息: import requests url = ...
- PYTHON网络爬虫与信息提取[信息的组织与提取](单元五)
1 三种信息类型的简介 xml : extensible markup language 与html非常相似 现有html后有xml xml是html发展来的 扩展 通用 json 类型 javas ...
随机推荐
- 【webstorm 系列之一】快捷键很好用啊
书签 bookmarks , 在多文件中调试很方便 断点只能在js文件中用,而bookmark可以在所有文件中使用 书签开关 F11 (给光标所在行加书签) 显示书签 Shift + F11 书签号 ...
- FIREDAC连MYSQL中文乱码的解决办法
FIREDAC连MYSQL中文会乱码,因为字符集的原因,字符集设为gb2312以后,不再乱码. if SameText(DatabaseParams.driveId, 'MySQL') then fd ...
- java数据库连接池技术简单使用
JDBCDemo.java: package com.itheima.jdbc; import java.sql.Connection; import java.sql.PreparedStateme ...
- Microduino-W5500
2014-06-13, Microduino 公布了全新的以太网模块Microduino-W5500 ,模块基于WIZnet以太网芯片,拥有独特的全硬件TCP/IP协议栈. attachment_id ...
- hive计算网页停留时长
hive表结构例如以下: create table pv_user_info( session_id string, user_id string, url string, starttime big ...
- OC基础:Date
NSDate 日期类,继承自NSObject,代表一个时间点 NSDate *date=[NSDate date]; NSLog(@"%@",date); //格林尼治时间, ...
- [转] logback 常用配置详解(序)logback 简介
转载文章:原文出处:http://aub.iteye.com/blog/1101222 logback 简介 Ceki Gülcü在Java日志领域世界知名.他创造了Log4J ,这个最早的Java日 ...
- Codeforces Round #310 (Div. 1) C. Case of Chocolate (线段树)
题目地址:传送门 这题尽管是DIV1的C. . 可是挺简单的. .仅仅要用线段树分别维护一下横着和竖着的值就能够了,先离散化再维护. 每次查找最大的最小值<=tmp的点,能够直接在线段树里搜,也 ...
- 65*24=1560<2175 对数据的统计支撑决策假设 历史数据正确的情况下,去安排今后的任务
没有达到目标,原因不是时间投入不够,而是不用数据决策,不用数据调度定时脚本 [数据源情况统计]----># 近30天,日生效coin数目SELECT COUNT(DISTINCT coin) A ...
- cgi fastcgi wsgi nginx python Dispatching TurboGears Python via FCGI
https://www.nginx.com/resources/wiki/start/topics/examples/simplepythonfcgi/ 117 2018-06-28 19:56:42 ...