Hadoop-01 搭建hadoop伪分布式运行环境
Linux中配置Hadoop运行环境
程序清单
- VMware Workstation 11.0.0 build-2305329
- centos6.5 64bit
- jdk-7u80-linux-x64.rpm
- hadoop-2.6.0.tar.gz
- hbase-1.0.2-bin.tar.gz
- SSH(centos6.5 默认已安装)
创建Linux系统用户(伪分布式可直接使用root用户试验)
root用户登录linux,密码同初始安装用户密码。
1.创建hadoop用户组
[root@localhost /]# groupadd hadoop
2.创建hadoop用户hduser
[root@localhost /]# useradd -g hadoop hduser
3.设置hduser密码
[root@localhost /]# passwd hduser
4.为hduser用户添加权限
[root@localhost /]# chmod 777 /etc/sudoers #修改权限 [root@localhost /]# gedit /etc/sudoers #编辑sudoers
查找以下内容 ## Allow root to run any commands anywhere root ALL=(ALL) ALL hduser ALL=(ALL) ALL #添加hduser到sudoers [root@localhost /]# chmod 440 /etc/sudoers #还原默认权限
5.重启虚拟机
[root@localhost /]# sudo reboot
6.重启后切换到hduser登录
7.进入CentOS系统后,Terminal的设定:字体大小调整、ScrollBack设置为Unlimited。
8.查看ip
IP地址设定
[root@localhost ~]# ip a 或者 [root@localhost ~]# ifconfig
测试这个自动获取的ip是否可以连接外网,本机windows系统能够ping通此ip。如果正常ping通,进入下一步。
1.固化ip:避免虚拟机每次重启ip地址发生变化
拷贝自动获取的ip可视化修改ip地址和网关。
查看网关命令:
[root@localhost ~]# netstat –rn
DNS设定:
谷歌公共DNS:8.8.8.8,8.8.4.4
中国电信公共DNS:114.114.114.114,114.114.115.115
阿里公共DNS:223.5.5.5,223.6.6.6
百度公共DNS:180.76.76.76
OpenDNS:208.67.220.220,208.67.222.222
2.启用ip地址
重启网络服务:
[root@localhost ~]# service network restart
验证:
ping公网,从windows系统ping通centos,确认修改ip成功。
为了便于后期虚拟机的迁移。
记住网络连接适配器中VMNET1和VMNET8的网络配置。
或者从VMWare菜单>>>编辑>>>虚拟网络编辑器进入,查看虚拟机网络适配器网络设置情况。
3.修改hosts文件,设定本机DNS解析
[root@localhost ~]# gedit /etc/hosts
打开hosts文件,添加一行
192.168.153.131 centos
4.修改主机名
[root@localhost ~]# gedit /etc/sysconfig/network
在配置文件中修改: HOSTNAME=centos
输入[root@localhost ~]# hostname查看主机名
准备安装软件
1.软件安装在/usr/local
如果是专用用户,建议安装在用户当前目录。
2.所需软件拷贝到/usr/local目录(生产环境使用FTP)
jdk-7u80-linux-x64.tar.gz
hbase-1.0.2-bin.tar.gz
hadoop-2.6.0.tar.gz
安装JDK
1.解压JDK
[root@localhost local]# tar -zxvf jdk-7u80-linux-x64.tar.gz
2.修改目录名称【可选】
[root@localhost local]# mv jdk1.7.0_80 jdk
3.配置环境变量
查看jdk安装路径
[root@localhost local]# cd jdk [root@localhost jdk]# pwd /usr/local/jdk
修改Linux全局变量
[root@localhost jdk]# gedit /etc/profile
打开profile文件,在文件最后输入以下内容:
#JDK config export JAVA_HOME=/usr/local/jdk export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$PATH
保存并关闭文件,让后输入以下命令使环境变量生效:
[root@localhost ~]# source /etc/profile
4.验证JDK,输入命令
[root@localhost ~]# java –version
出现版本号则安装正确
配置本机SSH免密码登录
1.禁用防火墙
[root@localhost ~]# service iptables stop [root@localhost ~]# chkconfig iptables off [root@localhost ~]# reboot
2.确认防火墙关闭:
[root@centos ~]# service iptables status iptables: Firewall is not running.
3.关闭Linux安全加强工具selinux
[root@ centos ~]# gedit /etc/selinux/config
修改以下内容:
SELINUX=disabled
4.SSH说明
SSH免密码登录的实质是使用非对称加密公钥和私钥实现的。公钥类似一把打开的锁,私钥类似钥匙。他们是一对被加密的字符串。
5.使用ssh-keygen生成私钥与公钥文件
输入命令
[root@ centos ~]# ssh-keygen -t rsa
黄色提示输入部分直接回车【主机名改为centos】。

在/root/.ssh/目录下分别生成私钥(id_rsa)和公钥(id_rsa.pub)文件。
6.私钥保留在本机,公钥分发给其他主机(当前是localhost),输入命令
[root@ centos ~]# ssh-copy-id localhost
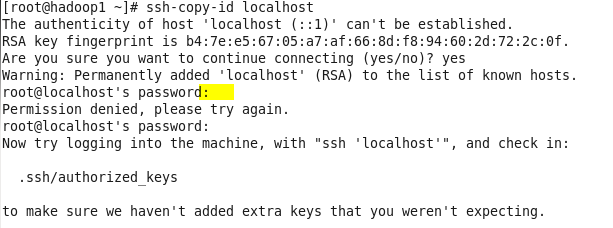
确认连接输入yes。首次连接要求输入密码(上图未输入密码报错),之后会在root/.ssh下生成授权文件:authorized_keys。authorized_key记录了收到的所有来自其他主机的公钥。
7.验证免密登录
[root@centos ~]# ssh centos

[root@centos ~]# ssh centos
Last login: Mon Jul 17 05:16:13 2017 from centos
[root@centos ~]# exit
hadoop伪分布式安装
hadoop的三种运行方式
- 单机模式:无须配置,hadoop被视作一个非分布式模式运行的独立java进程。
- 伪分布式:只有一个节点的集群,这个节点既是Master也是Slave,可以在此节点上以不同的java进程模拟分布式中的各类节点。
- 完全分布式:hadoop对于不同的系统会有不同节点划分方式。HDFS节点分为NameNode(管理者)和DataNode(工作者),其中NameNode只有一个,DataNode可以有多个;MapReduce节点划分为JobTracker(作业调度者)和TaskTracker(任务执行者),其中JobTracker只有一个,TaskTracker可以有多个。NameNode和JobTracker可以部署在不同的机器上,也可以部署在同一台机器上,部署NameNode和JobTracker的机器为Master,其余为Slave。
主机列表
|
主机名 |
IP地址 |
所分配角色 |
|
centos |
192.168.153.131 |
Master,NameNode,JobTracker slave,DataNode,TaskTracker |
安装hadoop
1.安装hadoop-2.6.0.tar.gz
把hadoop压缩包拷贝到/usr/local目录下
#解压hadoop
[root@centos local]# tar -zxvf hadoop-2.6.0.tar.gz
2.重命名hadoop
[root@centos local]# mv hadoop-2.6.0 hadoop
hadoop的目录结构说明
|
目录 |
说明 |
|
bin |
执行文件目录 |
|
etc |
Hadoop配置文件都在此目录 |
|
include |
包含C语言接口开发所需头文件 |
|
lib |
包含C语言接口开发所需链接库文件 |
|
libexec |
运行sbin目录中的脚本会调用该目录下的脚本 |
|
logs |
日志目录,在运行过Hadoop后会生成该目录 |
|
sbin |
仅超级用户能够执行的脚本,包括启动和停止dfs、yarn等 |
|
share |
包括doc和hadoop两个目录。doc目录包含大量的Hadoop帮助文档。hadoop目录包含了运行Hadoop所需的所有jar文件,在开发中用到的jar文件也可在该目录找到。 |
3.配置hadoop环境变量
获得hadoop安装路径
[root@centos hadoop]# pwd /usr/local/hadoop
打开系统配置文件
[hduser@node1 hadoop]$ sudo gedit /etc/profile
在文件末尾添加以下脚本(红色部分)
#JDK config export JAVA_HOME=/usr/local/jdk export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH #hadoop config export HADOOP_HOME=/usr/local/hadoop export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存并关闭,输入以下命令使之生效
[root@centos hadoop]# source /etc/profile
配置hadoop
配置hadoop主要涉及的文件有七个,在hadoop/etc/hadoop目录下,分别是:
1.配置文件一:hadoop-env.sh
[root@centos ~]$ cd /usr/local/hadoop/etc/hadoop [root@centos hadoop]# gedit hadoop-env.sh
指定JDK路径:
# The java implementation to use. export JAVA_HOME=/usr/local/jdk
2.配置文件二(hadoop全局配置文件): core-site.xml
[root@centos hadoop]# gedit core-site.xml
在<configuration>元素中增加配置属性:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos:9000</value>
</property>
</configuration>
配置属性说明:
fs.defaultFS:客户端连接HDFS时,默认的路径前缀,9000是HDFS工作的端口。hadoop v1版本默认端口是8020。
3.配置文件三:hdfs-site.xml
Hadoop分布式文件系统HDFS的配置。
[root@centos hadoop]# gedit hdfs-site.xml
在<configuration>元素中增加配置属性:
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>centos:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>centos:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> file:/// usr/local/hadoop/data/datanode </value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
参数说明:
|
属性 |
描述 |
|
dfs.namenode.secondary.http-address |
Secondary NameNode服务器HTTP地址和端口 |
|
dfs.namenode.name.dir |
NameNode存储名字空间及汇报日志的位置 |
|
dfs.datanode.data.dir |
DataNode存放数据块的目录列表 |
|
dfs.replication |
冗余备份数量,一份数据可设置多个拷贝 |
|
dfs.webhdfs.enabled |
在NameNode和DataNode中启用WebHDFS |
4.配置文件四:mapred-site.xml
[hduser@node1 hadoop]$ gedit mapred-site.xml.template [hduser@node1 hadoop]$ gedit mapred-site.xml
拷贝mapred-site.xml.template内容到mapred-site.xml
注意:可视化操作原目录中没有mapred-site.xml文件,需要创建mapred-site.xml文件。
<configuration>节点添加如下配置:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>centos:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value> centos:19888</value> </property>
配置说明:mapreduce.framework.name属性指定了使用YARN框架运行MapReduce程序。
5.配置文件五:yarn-site.xml
如果在mapred-site.xml 配置了使用YARN框架,那么YARN框架使用此文件中的配置。在<configuration>节点添加如下配置:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>centos:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>centos:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>centos:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>centos:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>centos:8088</value>
</property>
</configuration>
配置如下基本属性以指定相关服务地址
yarn.resourcemanager.address yarn.resourcemanager.scheduler.address yarn.resourcemanager.resource-tracker.address yarn.resourcemanager.admin.address yarn.resourcemanager.webapp.address
6.配置文件六:yarn-env.sh
配置YARN(hadoop资源管理器)框架以执行MapReduce程序
[root@centos hadoop]# gedit yarn-env.sh
指定JDK路径:
export JAVA_HOME=/usr/local/jdk
验证配置
1.格式化NameNode,输入命令
[root@centos hadoop]# hadoop namenode –format
2.启动hadoop
[root@centos hadoop]# start-all.sh
3.输入jps命令查看java进程,如图所示(五个进程hadoop进程已启动)
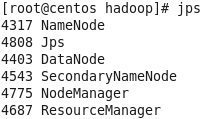
4.查看集群状态,输入命令
[root@centos hadoop]# hdfs dfsadmin –report
如果出现以下信息表示hadoop已经成功运行:
17/07/17 19:48:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Configured Capacity: 18779398144 (17.49 GB) Present Capacity: 13899386880 (12.94 GB) DFS Remaining: 13899362304 (12.94 GB) DFS Used: 24576 (24 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Live datanodes (1): Name: 192.168.153.131:50010 (centos) Hostname: centos Decommission Status : Normal Configured Capacity: 18779398144 (17.49 GB) DFS Used: 24576 (24 KB) Non DFS Used: 4880011264 (4.54 GB) DFS Remaining: 13899362304 (12.94 GB) DFS Used%: 0.00% DFS Remaining%: 74.01% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Mon Jul 17 19:48:05 PDT 2017
5.在浏览器中(Linux浏览器)查看HDFS运行状态,网址:
windows浏览器:http://192.168.153.131:50070
7.停止Hadoop,输入命令
[root@centos hadoop]$ stop-all.sh
hbase伪分布式安装
安装hbase
1.把hbase压缩包拷贝到/usr/local目录下
hbase-1.0.2-bin.tar.gz
2.解压hbase
[root@centos local]# tar -zxvf hbase-1.0.2-bin.tar.gz
3.重命名hbase
[root@centos local]# mv hbase-1.0.2 hbase
配置hbase
1.添加系统全局变量
[root@centos local]# gedit /etc/profile
修改文件:
#JDK config export JAVA_HOME=/usr/local/jdk export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH #hadoop config export HADOOP_HOME=/usr/local/hadoop #hbase config export HBASE_HOME=/usr/local/hbase #path config export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/sbin
启用文件:
[root@centos local]# source /etc/profile
2.配置hbase-site.xml文件
hbase-site.xml文件的完整配置如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://centos:9000/hbase</value>
<description>配置HRegionServer的数据库存储目录</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>配置HBase为分布式</description>
</property>
<property>
<name>hbase.master</name>
<value>node1:60000</value>
<description>配置HMaster的地址</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>centos</value>
<description>配置ZooKeeper集群服务器的位置 </description>
</property>
</configuration>
3.配置hbase-env.sh
export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/usr/local/hadoop export HBASE_HOME=/usr/local/hbase export HBASE_MANAGES_ZK=true #使用内置zookeeper实例
验证安装
[root@centos ~]# jps
3811 HRegionServer
3615 HQuorumPeer
2657 DataNode
3068 NodeManager
3897 Jps
2569 NameNode
2804 SecondaryNameNode
3700 HMaster
2978 ResourceManager
Hadoop-01 搭建hadoop伪分布式运行环境的更多相关文章
- centos中-hadoop单机安装及伪分布式运行实例
创建用户并加入授权 1,创建hadoop用户 sudo useradd -m hadoop -s /bin/bash 2,修改sudo的配置文件,位于/etc/sudoers,需要root权限才可以读 ...
- hadoop 2.7.3伪分布式环境运行官方wordcount
hadoop 2.7.3伪分布式模式运行wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次以伪分布式模式来运行w ...
- Hadoop 在windows 上伪分布式的安装过程
第一部分:Hadoop 在windows 上伪分布式的安装过程 安装JDK 1.下载JDK http://www.oracle.com/technetwork/java/javaee/d ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- hadoop 2.7.3伪分布式安装
hadoop 2.7.3伪分布式安装 hadoop集群的伪分布式部署由于只需要一台服务器,在测试,开发过程中还是很方便实用的,有必要将搭建伪分布式的过程记录下来,好记性不如烂笔头. hadoop 2. ...
- centos 7下Hadoop 2.7.2 伪分布式安装
centos 7 下Hadoop 2.7.2 伪分布式安装,安装jdk,免密匙登录,配置mapreduce,配置YARN.详细步骤如下: 1.0 安装JDK 1.1 查看是否安装了openjdk [l ...
- Win7下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper【转】
Win7下单机版的伪分布式solrCloud环境搭建Tomcat+solr+zookeeper 1.软件工具箱 在本文的实践中,需要用到以下的软件: Tomcat-7.0.62+solr-5.0.0+ ...
- Redis集群搭建,伪分布式集群,即一台服务器6个redis节点
Redis集群搭建,伪分布式集群,即一台服务器6个redis节点 一.Redis Cluster(Redis集群)简介 集群搭建需要的环境 二.搭建集群 2.1Redis的安装 2.2搭建6台redi ...
随机推荐
- git中文件的三种状态
用xcode的时候,左侧栏文件的邮右边时不时会看到M,A这一类的字母.当然,这些以后再写上.先说一下git里文件的三种状态 已提交(committed) 已经提交的本地仓库(repository), ...
- Untiy检测各类设备输入
轴需要单独设置 using UnityEngine; using System.Collections; using UnityEngine.UI; public class OutputKey : ...
- bzoj 3613: [Heoi2014]南园满地堆轻絮【二分+贪心】
二分答案w,然后判断的时候维护一个mx,扫描序列,先更新mx=max(mx,a[i]-w),然后如果a[i]+w<mx的话就是说这个位置即使升到极限并且前面降到极限也不能符合条件了 #inclu ...
- c#删除指定文件夹中今天之前的文件
1.说明 使用Directory类对指定文件夹下的今天或者更早日期之前的文件进行删除.原文链接:http://www.cnblogs.com/lengzhan/p/6423943.html 2.代码 ...
- 黑客攻防技术宝典web实战篇:核心防御机制习题
猫宁!!! 参考链接:http://www.ituring.com.cn/book/885 黑客攻防技术宝典web实战篇是一本非常不错的书,它的著作人之一是burpsuite的作者,课后的习题值得关注 ...
- PJzhang:微信公众号短连接与微信好友验证
猫宁!!! 参考链接:https://mp.weixin.qq.com/s/LPuYrDEyEXHyhcK3_HokSg 之前看到他们有人把微信公众号文章的长链接转为短链接,很受用,百度搜索一下方法, ...
- mycat启动报错UnknownHostException(Temporary failure in name resolution)解决方法
重启命令 ./mycat restart 查看日志 cd logs tail -f wrapper.log 报错信息 INFO | jvm 2 | 2018/05/09 11:28:28 | Erro ...
- AtCoder Grand Contest 015 E - Mr.Aoki Incubator
题目传送门:https://agc015.contest.atcoder.jp/tasks/agc015_e 题目大意: 数轴上有\(N\)个点,每个点初始时在位置\(X_i\),以\(V_i\)的速 ...
- fzu Problem 2198 快来快来数一数 (快速幂+优化)
题目链接: Problem 2198 快来快来数一数 题目描述: 给出n个六边形排成一排,a[i]代表i个六边形能组成的生成树个数,设定s[i]等于a[1]+a[2]+a[3]+....+a[i- ...
- LIS(变形) HDOJ 5489 Removed Interval
题目传送门 题意:求删掉连续L长度后的LIS 分析:记rdp[i]表示以a[i]为开始的LIS长度,用nlogn的办法,二分查找-a[i].dp[i]表示以a[i]为结尾并且删去[i-L-1, i-1 ...