HBase原理–所有Region切分的细节都在这里了

- ConstantSizeRegionSplitPolicy:0.94版本前默认切分策略。这是最容易理解但也最容易产生误解的切分策略,从字面意思来看,当region大小大于某个阈值(hbase.hregion.max.filesize)之后就会触发切分,实际上并不是这样,真正实现中这个阈值是对于某个store来说的,即一个region中最大store的大小大于设置阈值之后才会触发切分。另外一个大家比较关心的问题是这里所说的store大小是压缩后的文件总大小还是未压缩文件总大小,实际实现中store大小为压缩后的文件大小(采用压缩的场景)。ConstantSizeRegionSplitPolicy相对来来说最容易想到,但是在生产线上这种切分策略却有相当大的弊 端:切分策略对于大表和小表没有明显的区分。阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,这对业务来说并不是什么好事。如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
- IncreasingToUpperBoundRegionSplitPolicy: 0.94版本~2.0版本默认切分策略。这种切分策略微微有些复杂,总体来看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大store大小大于设置阈值就会触发切分。但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系 :(#regions) * (#regions) * (#regions) * flush size * 2,当然阈值并不会无限增大, 最大值为用户设置的MaxRegionFileSize。这种切分策略很好的弥补了ConstantSizeRegionSplitPolicy的短板,能够自适应大表和小表。而且在大集群条件下对于很多大表来说表现很优秀,但并不完美,这种策略下很多小表会在大集群中产生大量小region,分散在整个集群中。而且在发生region迁移时也可能会触发region分裂。
- SteppingSplitPolicy: 2.0版本默认切分策略。这种切分策略的切分阈值又发生了变化,相比IncreasingToUpperBoundRegionSplitPolicy简单了一些,依然和待分裂region所属表在当前regionserver上的region个 数有关系,如果region个数等于1,切分阈值为flush size * 2,否则为MaxRegionFileSize。这种切分策略对于大集群中的大表、小表会比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小region,而是适可而止。

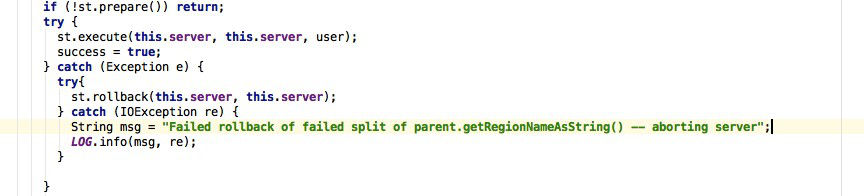
- prepare阶段:在内存中初始化两个子region,具体是生成两个HRegionInfo对象,包含tableName、regionName、startkey、endkey等。同时会生成一个transaction journal,这个对象用来记录切分的进展,具体见rollback阶段。
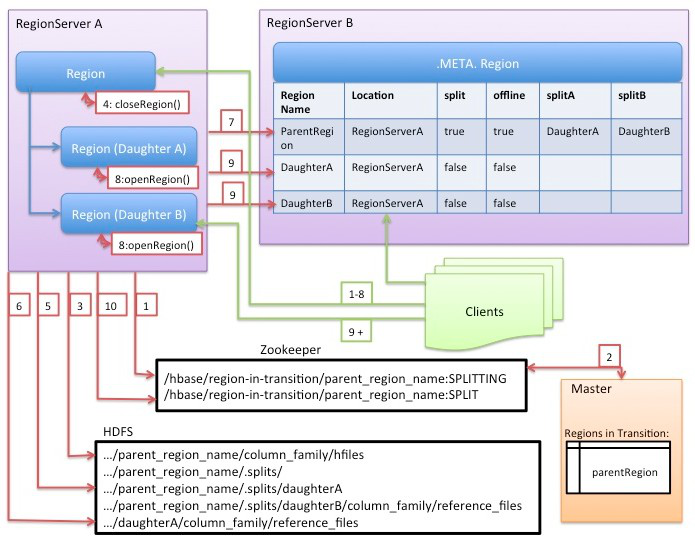
- execute阶段:切分的核心操作。见下图(来自Hortonworks):




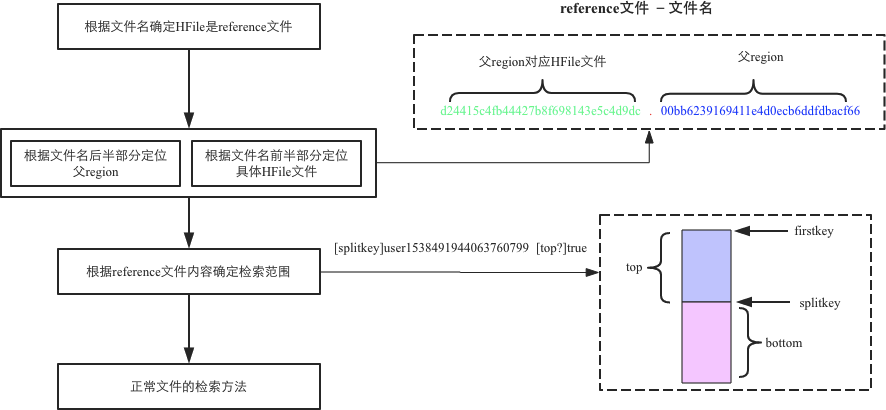
- rollback阶段:如果execute阶段出现异常,则执行rollback操作。为了实现回滚,整个切分过程被分为很多子阶段,回滚程序会根据当前进展到哪个子阶段清理对应的垃圾数据。代码中使用 JournalEntryType 来表征各个子阶段,具体见下图:


了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/
HBase原理–所有Region切分的细节都在这里了的更多相关文章
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
- 你想要的 HBase 原理都在这了
目录 一. 集群架构 集群角色 工作机制 二.存储机制 A. 存储模型 B. LSM 与 Compaction C. Region 分裂 D. 自动均衡 三.访问机制 四. 鉴权 五. 高可靠 1.集 ...
- HBase 架构与工作原理5 - Region 的部分特性
本文系转载,如有侵权,请联系我:likui0913@gmail.com Region Region 是表格可用性和分布的基本元素,由列族(Column Family)构成的 Store 组成.对象的层 ...
- 【转】HBase原理和设计
简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠的方 ...
- Hbase原理
Hbase原理 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop ...
- HBase原理和设计
转载 2016年1月10日:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ 简介 架构 数据组织 原理 RS定位 region写入 ...
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
- HBase原理解析(转)
本文属于转载,原文链接:http://www.aboutyun.com/thread-7199-1-1.html 前提是大家至少了解HBase的基本需求和组件. 从大家最熟悉的客户端发起请求开始讲 ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
随机推荐
- 学习记录:CONCAT()
连接多个字符串 SELECT * from t_info where phone = CONCAT('12345','678900')
- 跟我学算法-match-LSTM(向唐老师看齐)
对于match-lstm,将hi文本与输出的match-lstm(由si,hi,qi)组合重新输入到LSTM网络中,以端对端的操作理念. 参考的博客:https://blog.csdn.net/lad ...
- http post Content-type: application/json; charset=utf-8
The header just denotes what the content is encoded in. It is not necessarily possible to deduce t ...
- 温(Xue)习排序算法
最近忙着找工作,虽然排序算法用得到的情况不多,但不熟悉的话心里始终还是感觉没底. 于是今天给温习了其中的四个排序算法(与其说是温习,不如说是学习...因为感觉自己好像从来木有掌握过它们...) 一.选 ...
- Rigidbody中 Angular Drag (角阻力):
Rigidbody中 Angular Drag (角阻力):同样指的是空气阻力,只不过是用来阻碍物体旋转的.如果设置成无限的话,物体会立即停止旋转.如果设置成0,物体在上升过程中,会发生侧翻旋转. ...
- 系统批量运维管理器paramiko详解
一.paramiko介绍 paramiko是基于Python实现的SSH2远程安全连接,支持认证及密钥方式.可以实现远程命令执行.文件传输.中间SSH代理等功能,相对于Pexpect,封装的层次更高, ...
- Docker使用link建立容器之间的连接
我们在使用Docker的时候,经常可能需要连接到其他的容器,比如:web服务需要连接数据库.按照往常的做法,需要先启动数据库的容器,映射出端口来,然后配置好客户端的容器,再去访问.其实针对这种场景,D ...
- Vue.js基础知识
<!DOCTYPE html> <html lang="en" xmlns:v-bind="http://www.w3.org/1999/xhtml&q ...
- ubuntu账户密码正确但是登录不进去系统
ubuntu12.04管理员账户登录不了桌面,只能客人会话登录 求助!!ubuntu12.04管理员账户登录不了桌面,只能客人会话登录. ctrl+alt+f1 ,切换到tty1,输入管理员帐号和密码 ...
- 使用delphi 开发多层应用(二十一)使用XE5 RESTClient 直接访问kbmmw 数据库
delphi XE5 出来了,增加了android 的开发支持,另外增加了一个RESTClient 来支持访问REST 服务器. 这个功能非常强大,可以直接使用非常多的REST 服务器.同时也可以支持 ...