入坑-DM导论-第一章绪论笔记
//本学习笔记只是记录,并未有深入思考。
1.什么是数据挖掘?
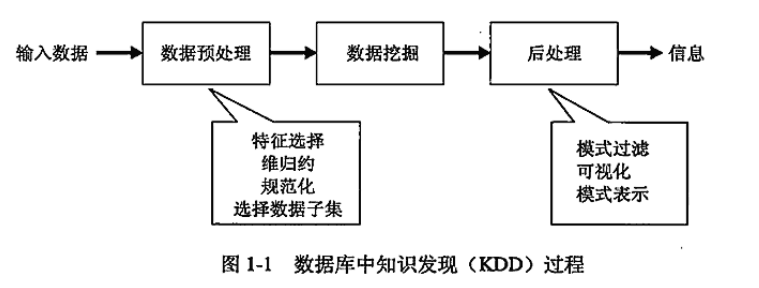
数据挖掘是数据库中发现必不可少的一部分。
数据预处理主要包括(可能是最耗时的步骤):
1.融合来自多个数据源的数据
2.清洗数据以消除噪声和重复的观测值
3.选择与当前数据挖掘任务相关的记录和特征。
2.数据挖掘要解决的问题
1.可伸缩性:面对海量数据,算法必须是可伸缩的。例如:当药不能处理的数据放入内存的时候,需要非内存算法;使用抽样技术或者开发并行和分布算法也可提高伸缩性。
2.高维性:具有成百上千的属性的数据集也很常见,比如基因特征;并且由于维度的增加,算法计算复杂度将会迅速升高。
3.异种数据和复杂数据:即非传统的数据类型:如包含半结构化的文本和超链接的Web页面,
4.数据所有权与分布:数据在地理上分属于多个站点和机构,需要开发分布式数据挖掘技术,
5.非传统分析:传统的统计方法基于假设-检验模式,但目前的数据分析需要的假设量太大,那么需要自动地产生假设和评估。
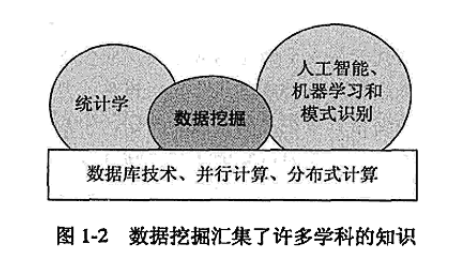
图中给出了数据挖掘和其他学科的关系。
1.3数据挖掘任务
预测任务:根据其他属性的值,预测特定属性的值。
描述任务:导出数据中潜在能够描述关系的模式(相关、趋势、聚类、轨迹和异常),这通常是探查性的,需要进行验证和解释。
根据数据类型可以分为:
分类:对离散型数据
回归:对连续型数据
2.分析方式概括
预测任务:比如对鸢尾花进行分类。
关联分析:用于发现数据中强关联的特征;比如找出功能相关的基因组,发现购物者同时购买的商品等。
聚类分析:发现紧密相关的观测值组群,对顾客进行分组。
异常检测:识别特征显著不同于其他特征的观测值;检测欺诈软件、网络攻击等;
入坑-DM导论-第一章绪论笔记的更多相关文章
- Day1 《机器学习》第一章学习笔记
<机器学习>这本书算是很好的一本了解机器学习知识的一本入门书籍吧,是南京大学周志华老师所著的鸿篇大作,很早就听闻周老师大名了,算是国内机器学习领域少数的大牛了吧,刚好研究生做这个方向相关的 ...
- 算法导论 第一章and第二章(python)
算法导论 第一章 算法 输入--(算法)-->输出 解决的问题 识别DNA(排序,最长公共子序列,) # 确定一部分用法 互联网快速访问索引 电子商务(数值算 ...
- 翻译学python---《Learn Python the hard Way》---第一章 绪论
打算学习python,但是又不想单纯地看书或是写个小项目,干脆引入很流行的翻译学习法来学习吧- 在论坛上看到了国外的一本<Learn Python the hard Way> ...
- Spring实战第一章学习笔记
Spring实战第一章学习笔记 Java开发的简化 为了降低Java开发的复杂性,Spring采取了以下四种策略: 基于POJO的轻量级和最小侵入性编程: 通过依赖注入和面向接口实现松耦合: 基于切面 ...
- Java程序设计(2021春)——第一章续笔记与思考
Java程序设计(2021春)--第一章续笔记与思考 目录 Java程序设计(2021春)--第一章续笔记与思考 Java数据类型 基本数据类型 引用类型 基本数据类型--整数类型的细节 基本数据类型 ...
- [蛙蛙推荐]SICP第一章学习笔记-编程入门
本书简介 <计算机程序的构造与解释>这本书是MIT计算机科学学科的入门课程, 大部分学生在学这门课程前都没有接触过程序设计,也就是说这本书是针对编程新手写的. 虽然是入门课程,但起点比较高 ...
- 《从Paxos到Zookeeper:分布式一致性原理与实践》第一章读书笔记
第一章主要介绍了计算机系统从集中式向分布式系统演变过程中面临的挑战,并简要介绍了ACID.CAP和BASE等经典分布式理论,主要包含以下内容: 集中式的特点 分布式的特点 分布式环境的各种问题 ACI ...
- 20135320赵瀚青LINUX第一章读书笔记
第一章-Linux内核简介 Unix的历史 依旧被认为是最强大和最优秀的系统 由一个失败的操作系统Multics中产生 被移植到PDP-11型机中 由其他组织进一步开发 重写了虚拟内存系统,最终官方版 ...
- 《Ansible自动化运维:技术与佳实践》第一章读书笔记
Ansible 架构及特点 第一章主要讲的是 Ansible 架构及特点,主要包含以下内容: Ansible 软件 Ansible 架构模式 Ansible 特性 Ansible 软件 Ansible ...
随机推荐
- go语言的time.Sleep
首先:time.sleep单位为:1ns (纳秒) 转换单位: 1纳秒 =1000皮秒 1纳秒 =0.001 微秒 1纳秒 =0.000 001毫秒 1纳秒 =0.0 ...
- 使用CXF为webservice添加拦截器
拦截器分为Service端和Client端 拦截器是在发送soap消息包的某一个时机拦截soap消息包,对soap消息包的数据进行分析或处理.分为CXF自带的拦截器和自定义的拦截器 1.Servi ...
- ubuntu网络配置命令
Ubuntu网络配置例如: (1) 配置eth0的IP地址, 同时激活该设备. #ifconfig eth0 192.168.1.10 netmask 255.255.255.0 up (2) 配置e ...
- [转]ASP.NET MVC 5 - 给数据模型添加校验器
在本节中将会给Movie模型添加验证逻辑.并且确保这些验证规则在用户创建或编辑电影时被执行. 拒绝重复 DRY ASP.NET MVC 的核心设计信条之一是DRY: "不要重复自己(DRY ...
- 连接oracle服务器超慢--原因分析
连接oracle服务器超慢:有如下原因可能会影响. 网络不好:oracle服务器跟本地网络不好. oracle服务器内存不足:导致反应超慢 监听日志listener.log太大:导致响应超慢. 所以对 ...
- ch5-处理数据,抽取-整理-推导
场景:教练kelly有4个选手James\Sarah\Julie\Mikey,他们每跑600米,教练就会计时并把时间记录在计算机的一个文件中,总共4个文件:James.txt\Sarah.txt\Ju ...
- /var/log/spooler
/var/log/spooler 用来记录 Linux 新闻群组方面的日志,内容一般是空的,没什么用,了解即可
- shell、cmd、dos和脚本语言杂谈(转)
问题一:DOS与windows中cmd区别 在windows系统中,“开始-运行-cmd”可以打开“cmd.exe”,进行命令行操作. 操作系统可以分成核心(kernel)和Shell(外壳)两部 ...
- UART简介
经常遇到初学者,对单片机串行通讯出了问题不知道如何办的情况.其实最有效的调试方法是用示波器观察收发数据的波形.通过观察波形可以确定以下情况: 1.数据是否接收或发送: 2.数据是否正确: 3.波特率是 ...
- Effective C++ —— 构造/析构/赋值运算(二)
条款05 : 了解C++默默编写并调用哪些函数 编译器可以暗自为class创建default构造函数.copy构造函数.copy assignment操作符,以及析构函数. 1. default构造函 ...