第2章 RDD编程(2.1-2.2)
第2章 RDD编程
2.1 编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
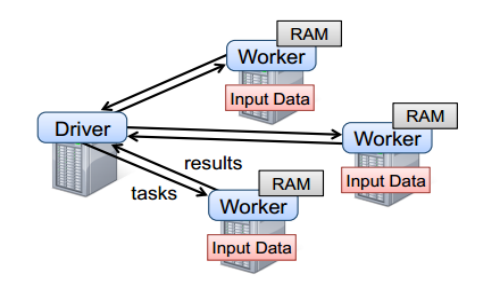
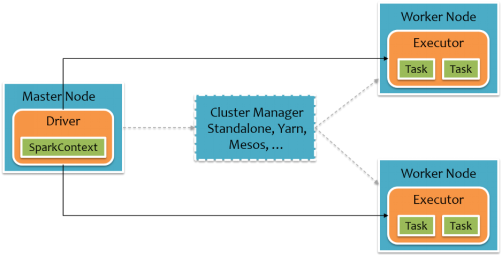
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
2.2 RDD创建
在Spark中创建RDD的创建方式大概可以分为三种:从集合中创建RDD;从外部存储创建RDD;从其他RDD创建。
由一个已经存在的Scala集合创建,集合并行化。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
而从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD。我们可以先看看这两个函数的声明:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
我们可以从上面看出makeRDD有两种实现,而且第一个makeRDD函数接收的参数和parallelize完全一致。其实第一种makeRDD函数实现是依赖了parallelize函数的实现,来看看Spark中是怎么实现这个makeRDD函数的:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
我们可以看出,这个makeRDD函数完全和parallelize函数一致。但是我们得看看第二种makeRDD函数函数实现了,它接收的参数类型是Seq[(T, Seq[String])],Spark文档的说明是:
Distribute a local Scala collection to form an RDD, with one or more location preferences (hostnames of Spark nodes) for each object. Create a new partition for each collection item.
原来,这个函数还为数据提供了位置信息,来看看我们怎么使用:
scala> val guigu1= sc.parallelize(List(1,2,3))
guigu1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:21
scala> val guigu2 = sc.makeRDD(List(1,2,3))
guigu2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at <console>:21
scala> val seq = List((1, List("slave01")),| (2, List("slave02")))
seq: List[(Int, List[String])] = List((1,List(slave01)),
(2,List(slave02)))
scala> val guigu3 = sc.makeRDD(seq)
guigu3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at makeRDD at <console>:23
scala> guigu3.preferredLocations(guigu3.partitions(1))
res26: Seq[String] = List(slave02)
scala> guigu3.preferredLocations(guigu3.partitions(0))
res27: Seq[String] = List(slave01)
scala> guigu1.preferredLocations(guigu1.partitions(0))
res28: Seq[String] = List()
我们可以看到,makeRDD函数有两种实现,第一种实现其实完全和parallelize一致;而第二种实现可以为数据提供位置信息,而除此之外的实现和parallelize函数也是一致的,如下:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
}
都是返回ParallelCollectionRDD,而且这个makeRDD的实现不可以自己指定分区的数量,而是固定为seq参数的size大小。
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val atguigu = sc.textFile("hdfs://hadoop102:9000/RELEASE")
atguigu: org.apache.spark.rdd.RDD[String] = hdfs:// hadoop102:9000/RELEASE MapPartitionsRDD[4] at textFile at <console>:24
第2章 RDD编程(2.1-2.2)的更多相关文章
- 第2章 RDD编程(2.3)
第2章 RDD编程(2.3) 2.3 TransFormation 基本RDD Pair类型RDD (伪集合操作 交.并.补.笛卡尔积都支持) 2.3.1 map(func) 返回一个新的RDD,该 ...
- Learning Spark中文版--第三章--RDD编程(2)
Common Transformations and Actions 本章中,我们浏览了Spark中大多数常见的transformation(转换)和action(开工).在包含特定数据类型的RD ...
- Learning Spark中文版--第三章--RDD编程(1)
本章介绍了Spark用于数据处理的核心抽象概念,具有弹性的分布式数据集(RDD).一个RDD仅仅是一个分布式的元素集合.在Spark中,所有工作都表示为创建新的RDDs.转换现有的RDD,或者调 ...
- 《Spark快速大数据分析》—— 第三章 RDD编程
- Spark学习笔记2:RDD编程
通过一个简单的单词计数的例子来开始介绍RDD编程. import org.apache.spark.{SparkConf, SparkContext} object word { def main(a ...
- 2. RDD编程
2.1 编程模型 在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换.经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,act ...
- 《深入浅出Node.js》第7章 网络编程
@by Ruth92(转载请注明出处) 第7章 网络编程 Node 只需要几行代码即可构建服务器,无需额外的容器. Node 提供了以下4个模块(适用于服务器端和客户端): net -> TCP ...
- 《深入浅出Node.js》第4章 异步编程
@by Ruth92(转载请注明出处) 第4章 异步编程 Node 能够迅速成功并流行起来的原因: V8 和 异步 I/O 在性能上带来的提升: 前后端 JavaScript 编程风格一致 一.函数式 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
随机推荐
- Centos 7 下安装PHP7.2(与Apache搭配的安装方式)
(1)源码包下载 百度云下载地址:https://pan.baidu.com/s/1xH7aiGYaX62wij4ul5P-ZQ 提取码:m9zc (2)安装php依赖组件: yum -y insta ...
- Java Script 数组
数组:有许多变量的集合,它们的名称和数据类型都是一致的. 定义 操作(添加修改) Var arr=new Array(): Var arr=[ ]; //定义 Var arr1=[ 1,2,3, ...
- c语言大小写转化函数(包括字母和字符串)
本憨憨忘了好几次了,这次一定记住他们! 首先大小写相差32.转换的话自己写函数也是可以写出来的. 1.字母 如果是字母转的话,用toupper(),tolower() 头文件是<ctype.h& ...
- 第七章 vuex专题
一.Vuex安装 一般在创建项目是会选择 Vuex,如果没有选择: cnpm install vuex --save 使用: import Vuex from "vuex"; V ...
- Python os.remove() 方法
概述 os.remove() 方法用于删除指定路径的文件.如果指定的路径是一个目录,将抛出OSError.高佣联盟 www.cgewang.com 在Unix, Windows中有效 语法 remov ...
- PHP date_isodate_set() 函数
------------恢复内容开始------------ 实例 设置 2013 年第 5 周的 ISO 日期: <?php$date=date_create();date_isodate_s ...
- PHP lcfirst() 函数
实例 把 "Hello" 的首字符转换为小写.: <?php高佣联盟 www.cgewang.comecho lcfirst("Hello world!" ...
- 5.15 省选模拟赛 T1 点分治 FFT
LINK:5.15 T1 对于60分的暴力 都很水 就不一一赘述了. 由于是询问所有点的这种信息 确实不太会. 想了一下 如果只是询问子树内的话 dsu on tree还是可以做的. 可以自己思考一下 ...
- 《分享》Koa2源码分析
曾经在公司内部做的一起关于koa源码的分享,希望对你有帮助: koa2 源码分析整理 koa2(2.4.1版本)源码主要包含四个js,包括application.js, context.js, req ...
- MyBatis-Plus使用(1)-概述+代码生成器
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发.提高效率而生. 官网:https://mp.baomidou.com ...