Spring Data Solr
1.什么是spring data solr?
Solr是一个开源搜索平台,用于构建搜索应用程序。简单的来说就是作为一个搜索引擎使用。
2.solr的安装(本地安装,远程安装同)
1)解压一个tomcat,用于运行solr项目
2)下载一个solr,然后解压
3)把 solr 下的dist目录中solr的war文件部署到tomcat\webapps下,把war的名字改为solr
4)启动tomcat,把war解压
5)把solr下example/lib/ext 目录下的所有的 jar 包复制到 solr 的工程WEB-INF/lib中
6)创建一个 solrhome。把solr 下的/example/solr 目录到D盘改名为solrhome
7)需要修改 solr 工程的 web.xml
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>d:\solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
8)启动 Tomcat,在浏览器输入http://localhost:8080/solr,看到如下页面说明solr已安装成功

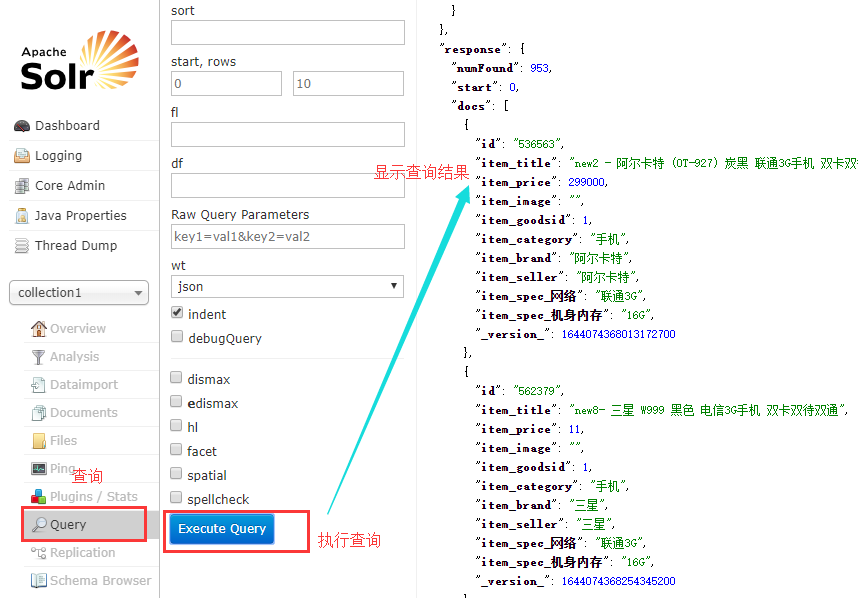
9)选择仓库,进行查询
3.中文分析器IK Analyzer
IK Analyzer 是一个开源的,基于java 语言开发的轻量级的中文分词工具。
IK Analyzer配置:
1)把IKAnalyzer2012FF_u1.jar 添加到 solr 工程的 lib 目录下
2)创建WEB-INF/classes文件夹,把扩展词典mydict.dic、停用词词典ext_stopword.dic、配置文件IKAnalyzer.cfg.xml放到 solr 工程的WEB-INF/classes 目录下。
3)修改 solrhome\collection1\conf\schema.xml 文件,在文件的尾部配置一个 FieldType。
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
4.域
域相当于数据库的表字段。
域的常用属性:
name:指定域的名称
type:指定域的类型
indexed:是否索引,当需要根据此字段查询时为true
stored:是否存储,设置存储后才能查询此字段
required:是否必须
multiValued:是否多值
1)字段域
将实体类中要保存到solr索引库的属性进行映射配置,与索引库的字段进行一一对应
<field name="item_id" type="int" indexed="true" stored="true"/>
2)复制域
复制域的作用在于将某一个Field中的数据复制到另一个域中,进行匹配查询
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_name" dest="item_keywords"/>
3)动态域
需要动态扩充字段时,要使用动态域
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" />
5.spring data solr入门
1)创建maven工程,名为springdata-solr,在pom.xml中引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
<version>1.5.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
</dependency>
</dependencies>
2)在src/main/resources下创建spring目录,目录下新建applicationContext-solr.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:solr="http://www.springframework.org/schema/data/solr"
xsi:schemaLocation="http://www.springframework.org/schema/data/solr
http://www.springframework.org/schema/data/solr/spring-solr-1.0.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<!-- solr服务器地址 -->
<solr:solr-server id="solrServer" url="http://127.0.0.1:8080/solr" />
<!-- solr模板,使用solr模板可对索引库进行CRUD的操作 -->
<bean id="solrTemplate" class="org.springframework.data.solr.core.SolrTemplate">
<constructor-arg ref="solrServer" />
</bean>
</beans>
3)创建类User并创建对应的数据库,填充一些信息
package com.entity;
public class MyUser {
private int id;
private String name;
private String password;
private String phone;
private String url;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
User类
4)配置@Field 注解
如果实体属性与配置文件定义的域名称不一致,需要在注解中指定域名称
//@Field()里面的字段需要和solrhome的schema.xml 中域的name相同
@Fieldprivate int id;
@Field("item_name")
private String name;
@Field("item_password")
private String password;
@Field("item_phone")
private String phone;
@Field("item_url")
private String url;
5)在solrhome\collection1\conf\schema.xm配置文件中添加字段,添加后重启tomcat服务器
<field name="item_name" type="text_ik" indexed="true" stored="true"/>
<field name="item_password" type="string" indexed="true" stored="true"/>
<field name="item_phone" type="string" indexed="false" stored="true" />
<field name="item_url" type="string" indexed="false" stored="true" /> <field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_name" dest="item_keywords"/>
<copyField source="item_password" dest="item_keywords"/>
<copyField source="item_phone" dest="item_keywords"/>
<copyField source="item_url" dest="item_keywords"/>
6)创建测试类SolrTest
package com.test; import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.solr.core.SolrTemplate;
import org.springframework.data.solr.core.query.Criteria;
import org.springframework.data.solr.core.query.Query;
import org.springframework.data.solr.core.query.SimpleQuery;
import org.springframework.data.solr.core.query.result.ScoredPage;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner; import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List; @RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:spring/applicationContext-solr.xml")
public class SolrTest { @Autowired
private SolrTemplate solrTemplate;
//在此写操作,这些操作只是对solr的仓库的
}
7)添加操作(在测试类中编写,下同)
@Test
public void add(){
//把数据添加到solr中
MyUser myUser=new MyUser();
myUser.setId(1);
myUser.setName("测试名");
myUser.setPassword("1234");
myUser.setUrl("baidu.com");
solrTemplate.saveBean(myUser);
solrTemplate.commit();
}
当执行后,在页面进行查询,会看到数据已经添加到solr仓库中了
8)按主键查询
@Test
public void findById(){
//按主键查询
MyUser id = solrTemplate.getById(1, MyUser.class);
System.out.println(id);//会把对应id的信息查询出来
}
9)按主键删除
@Test
public void deleteById(){
//按主键删除
solrTemplate.deleteById("1");
solrTemplate.commit();
}
10)删除全部
@Test
public void deleteAll(){
//删除全部
Query query=new SimpleQuery("*:*");
solrTemplate.delete(query);
solrTemplate.commit();
}
11)批量导入数据
//批量导入数据
@Test
public void addList(){
List<MyUser> list=new ArrayList<MyUser>();
for (int i = 0; i < 100; i++) {
MyUser myUser=new MyUser();
myUser.setId(1+i);
myUser.setName("测试名"+i);
myUser.setPassword("1234"+i);
myUser.setUrl("baidu.com"+i);
list.add(myUser);
}
//saveBeans添加list集合
solrTemplate.saveBeans(list);
solrTemplate.commit();
}
12)分页查询
@Test
public void findPage(){
//分页查询
Query query=new SimpleQuery("*:*");
//设置起始索引
query.setOffset(10);
//设置每页显示的条数
query.setRows(20);
ScoredPage<MyUser> pages = solrTemplate.queryForPage(query, MyUser.class);
//获取总记录数
System.out.println("总记录数:"+pages.getTotalElements());
//获取总页数
System.out.println("总页数:"+pages.getTotalPages());
//获取分页数据
List<MyUser> list = pages.getContent();
for (MyUser item : list) {
System.out.println(item.getName()+" "+item.getUrl());
}
}
13)有条件分页查询
@Test
public void findPageMutil(){
//有条件分页查询
Query query=new SimpleQuery("*:*");
Criteria criteria=new Criteria("item_keywords");
//contains包含(参数不可拆分),is是相等(参数可拆分)
criteria.is("试名");
query.addCriteria(criteria);
//设置起始索引
query.setOffset(10);
//设置每页显示的条数
query.setRows(20);
ScoredPage<MyUser> pages = solrTemplate.queryForPage(query, MyUser.class);
//获取总记录数
System.out.println("总记录数:"+pages.getTotalElements());
//获取总页数
System.out.println("总页数:"+pages.getTotalPages());
//获取分页数据
List<MyUser> list = pages.getContent();
for (MyUser item : list) {
System.out.println(item.getName()+" "+item.getUrl());
}
}
Spring Data Solr的更多相关文章
- Spring Data Solr教程(翻译) 开源的搜索服务器
Solr是一个使用开源的搜索服务器,它采用Lucene Core的索引和搜索功能构建,它可以用于几乎所有的编程语言实现可扩展的搜索引擎. Solr的虽然有很多优点,建立开发环境是不是其中之一.此博客条 ...
- Spring Data Solr教程(翻译)
大多数应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗并且它们由于沉重的数据库加载而拖垮你的应用的性能 这就是为什么转移负载到一个外部的搜索服务器是一个不错的主意,Apache Solr ...
- Spring Data Solr相关配置
1.增加Maven POM文件的存储库:pom配置如下: <repositories> <repository> <id>spring-milestone</ ...
- Spring Data Solr —— 快速入门
Solr是基于Lucene(全文检索引擎)开发,它是一个独立系统,运行在Tomcat或Jetty(solr6以上集成了jetty,无需再部署到servlet容器上),但其原生中文的分词词功能不行,需要 ...
- Solr学习笔记(5)—— Spring Data Solr入门
一.Spring Data Solr简介 前面已经介绍了通过solrJ来操作solr,那么我们如何将Solr的应用集成到Spring中?Spring Data Solr就是为了方便Solr的开发所研制 ...
- Spring Data Solr操作solr的简单案例
Spring Data Solr简介 虽然支持任何编程语言的能力具有很大的市场价值,你可能感兴趣的问题是:我如何将Solr的应用集成到Spring中?可以,Spring Data Solr就是为了方便 ...
- 记录一次Spring Data Solr相关的错误解决
记录一次Spring Data Solr相关的错误解决 生活本不易,流人遂自安 相信大家也使用过SpringDataSolr,但是在最新版的SpringDataSolr 4.0.5 RELEASE中有 ...
- SpringBoot整合Spring Data Solr
此文不讲solr相关,只讲整合,内容清单如下 1. maven依赖坐标 2. application.properties配置 3. Java Config配置 1. maven坐标 <depe ...
- Solr和Spring Data Solr
一.Solr概述与安装 1.Solr简介 Solr是一个开源搜索平台,用于构建搜索应用程序. 它建立在Lucene(全文搜索引擎)之上. Solr是企业级的,快速的和高度可扩展的.Solr可以和Had ...
- Spring Data Solr创建动态域报错:org.springframework.data.solr.UncategorizedSolrException
今天在项目中使用Spring Data Solr导入动态域数据报错, 控制台打印错误信息如下 Exception in thread "main" org.springframew ...
随机推荐
- PHP-文件、目录相关操作
PHP-文件.目录相关操作 一 目录操作(Directory 函数允许获得关于目录及其内容的信息) 相关函数: 函数 描述 chdir() 改变当前的目录. chroot() 改变根目录. clos ...
- Java开发中POJO和JSON互转时如何忽略隐藏字段
1. 前言 在Java开发中有时候某些敏感信息我们需要屏蔽掉,不能被消费这些数据的客户端知道.通常情况下我们会将其设置为null或者空字符 "",其实还有其它办法,如果你使用了Ja ...
- 记angular和asp.net使用grpc进行通信
AspNetCore配置grpc服务端 新建一个Demo项目: GrpcStartup, 目录结构如下图: GrpcStartup.GrpcServices需要安装下面的依赖 <PackageR ...
- 2019 沈阳网络赛 D Fish eating fruit ( 树形DP)
题目传送门 题意:求一颗树中所有点对(a,b)的路径长度,路径长度按照模3之后的值进行分类,最后分别求每一类的和 分析:树形DP \(dp[i][j]\) 表示以 i 为根的子树中,所有子节点到 i ...
- 2019牛客暑期多校训练营(第一场)I Points Division(dp+线段树优化)
给你n个点,第i个点在的位置为(xi,yi),有两个属性值(ai,bi).现在让你把这n个点划分为A和B两个部分,使得最后不存在i∈A和j∈B,使得xi>=xj且yi<=yj.然后对于所有 ...
- Codeforces Global Round 11 A. Avoiding Zero(前缀和)
题目链接:https://codeforces.com/contest/1427/problem/A 题意 将 \(n\) 个数重新排列使得不存在为 \(0\) 的前缀和. 题解 计算正.负前缀和,如 ...
- net core启动报错Unable to configure HTTPS endpoint. No server certificate was specified
这是因为net core2.1默认使用的https,如果使用Kestrel web服务器的话没有安装证书就会报这个错 其实仔细看他的错误提示,其中有一句叫你执行一个命令安装证书的语句: dotnet ...
- SpringBoot简单整合redis
Jedis和Lettuce Lettuce 和 Jedis 的定位都是Redis的client,所以他们当然可以直接连接redis server. Jedis在实现上是直接连接的redis serve ...
- Go中的Socket编程
在很多底层网络应用开发者的眼里一切编程都是Socket,话虽然有点夸张,但却也几乎如此了,现在的网络编程几乎都是用Socket来编程.你想过这些情景么?我们每天打开浏览器浏览网页时,浏览器进程怎么和W ...
- DQL 数据查询语言
查询数据(SELECT) # 查询所有数据 - 很危险,数据量过大,容易导致内存溢出而宕机 mysql> select * from student; # 先查询数据总量,然后决定是否可以查询所 ...