Attention & Transformer
Attention & Transformer
seq2seq; attention; self-attention; transformer;
1 注意力机制在NLP上的发展
Seq2Seq,Encoder,Decoder
引入Attention,Decoder上对输入的各个词施加不同的注意力 https://wx1.sbimg.cn/2020/09/15/9FZGo.png
Self-attention,Transformer,完全基于自注意力机制

Bert,双向Transformer,mask
XLNet,自回归语言模型,自动编码语言模型,摒弃遮盖
{kind=link}
2 注意力机制
以机器翻译为例;Seq2Seq架构;
2.1 RNN + RNN
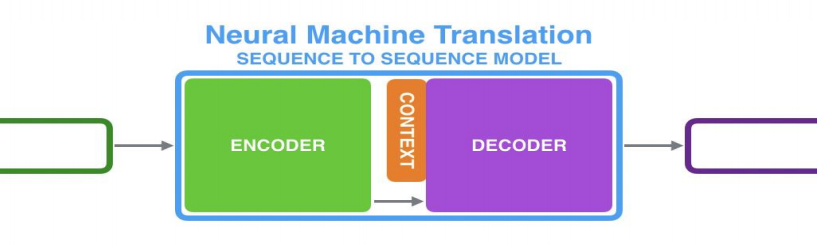
Encoder处理输入序列,得到上下文CONTEXT(一个向量,代表源文信息);Decoder处理CONTEXT逐项生成输出序列。
RNN在每个时间步接收两个输入
- 隐状态:上一个时间步传递来的;Decoder的初始隐状态为编码阶段的最后一个隐状态
- 词向量输入:Encoder为输入序列的对应位置的词向量;Decoder为上一个时间步的输出(第一个时间步的输入为Start)
上下文向量定长,模型难处理长句
2.2 RNN+RNN+Attention
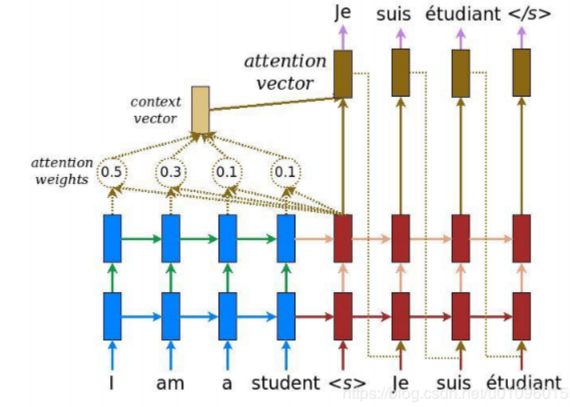
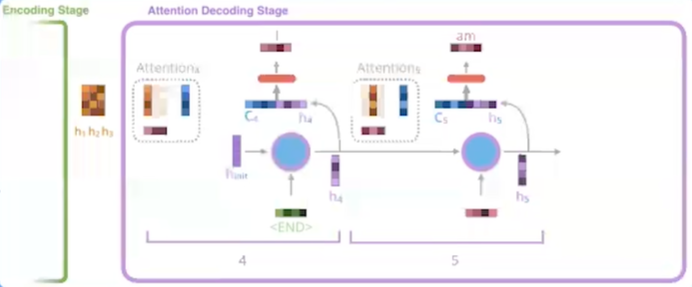
Encoder 向 Decoder 传递更多的数据,不止传递编码阶段的最后一个隐藏状态,而是传递所有隐藏状态。
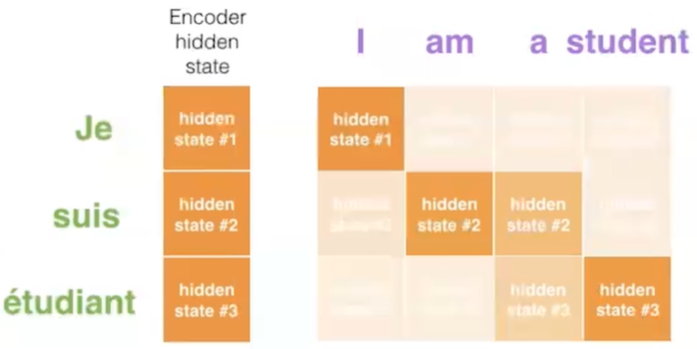
Decoder增加额外步骤,根据隐状态之间的相关性对不同的隐藏状态打分
为每个编码器隐状态打分;softmax加权;求和

打分后的Encoder隐状态加权后与当前Decoder隐状态结合,作为当前时间步的隐状态输入
Decode 过程中不同的步骤回关注于不同 Encoder 的隐状态
3 Transformer
Attention Is All You Need; self-attention;
3.1 概述
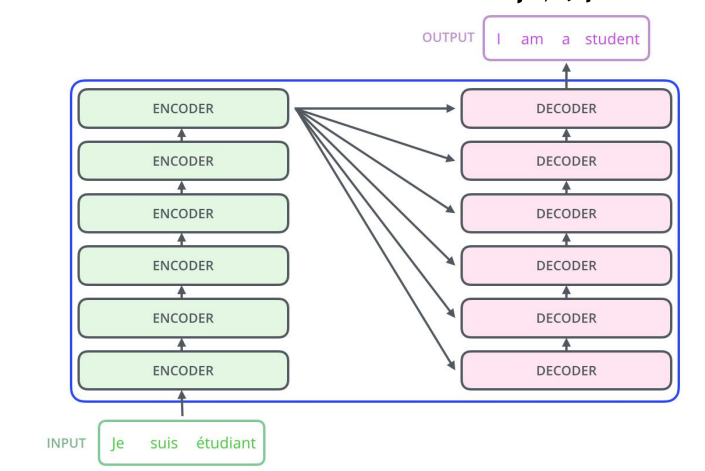
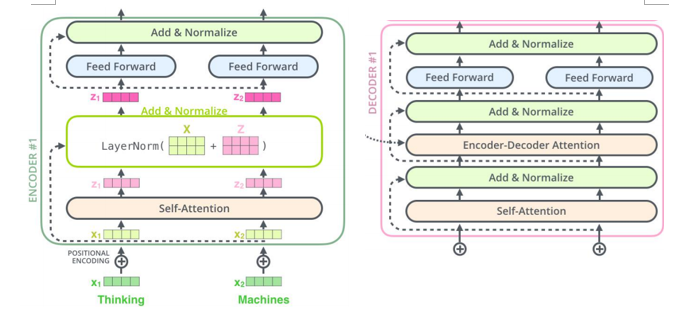
- 仍然由encoder和Decoder组成,完全基于自注意力机制,不使用RNN。
- 编码器和解码器都是一组编码/解码组件组成,原论文使用了6个
3.2 Encoder 解码器
- 编码器由两个子层:自注意力层(见3.3节)、全连接神经网络
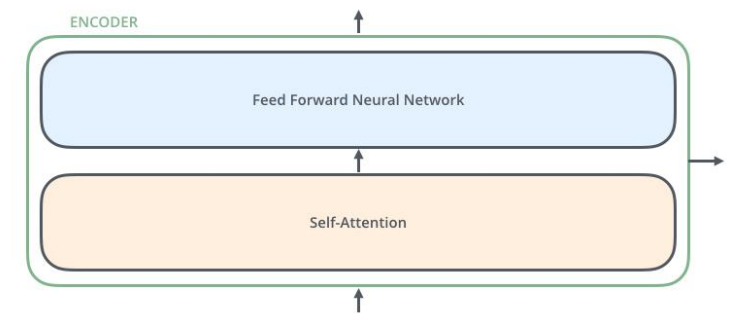
- 每个编码器组件结构相同,但不共享权重。
3.3 自注意力机制
自注意力机制全景图
词嵌入 word embedding
- 发生在最底部的编码器;输入数据[batch_size, word_embedding_size, seq_len];完成嵌入后作为输入经过编码器;每个位置的词并行经过编码器,速度比RNN快。
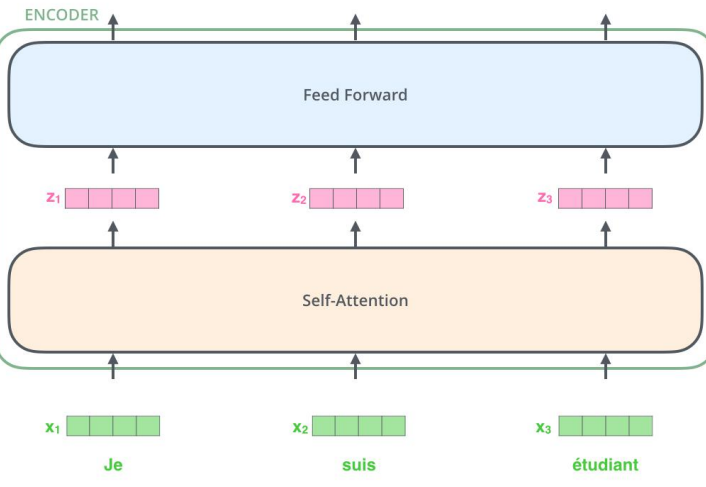
并行运算未考虑到顺序关系,通过位置编码(positional encoding)使词嵌入包含位置信息。
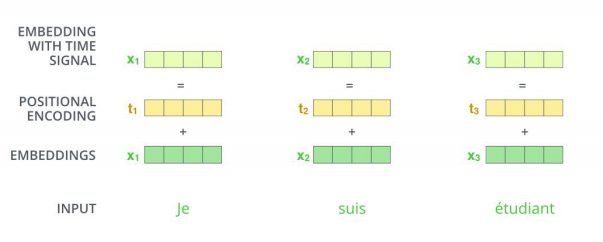
位置编码方式:sin、cos
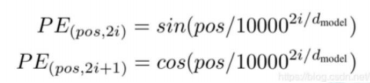
自注意力计算
三个参数W(\(W^Q\), \(W^K\),\(W^V\))与输入的向量相乘得到:查询向量q,键向量k,值向量v;新向量维度小于嵌入向量的维数
对于一个输入向量,将其q向量与其他词的k向量相乘计算分数;分数高则关系密切
将分数缩放(避免梯度弥散);通过softmax操作转化为概率。
将每个词的v向量用上一步的softmax概率加权求和;得到该输入向量的 z值
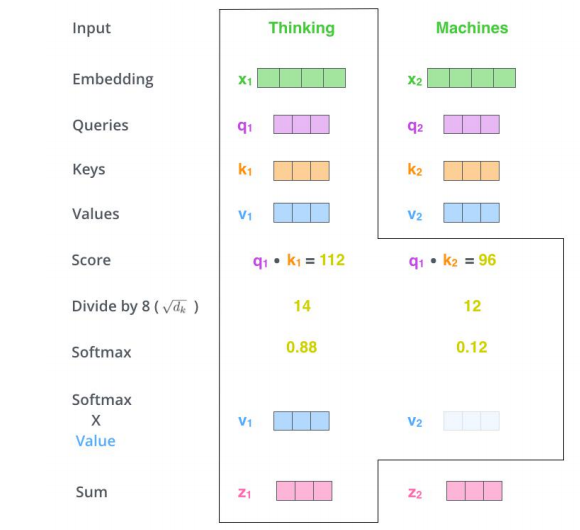
234步骤 以矩阵的形式,对多个输入向量并行求z,得到Z矩阵
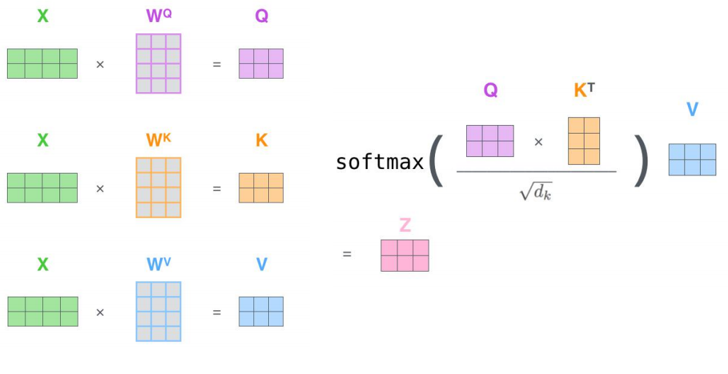
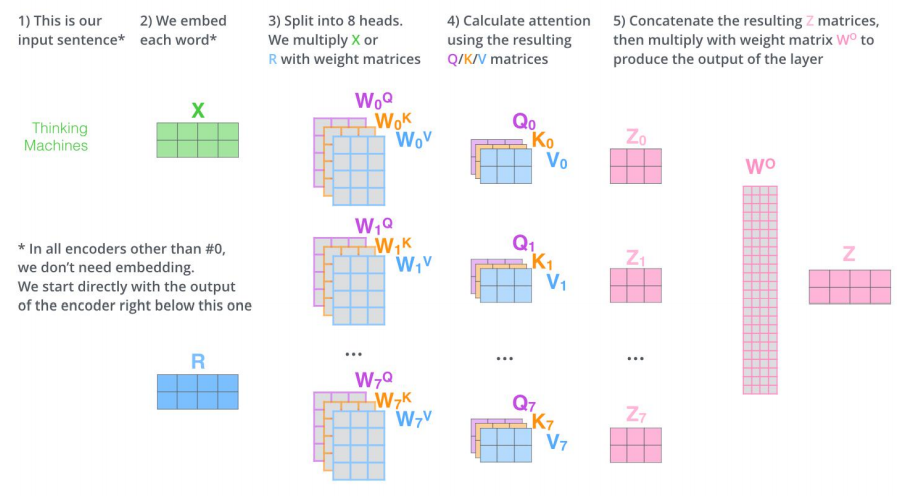
多头机制
为关注曾提供了多个表示子空间;拓展了模型专注于不同层面的能力
有多组qkv的权重矩阵;e.g. 使用8个关注头则每个编码器解码器会得到8组Z
将所有的Z连接起来和一个权重矩阵\(W^O\)相乘,得到捕捉了所有注意力头的Z矩阵,再将其输入到接下来的全连接层。
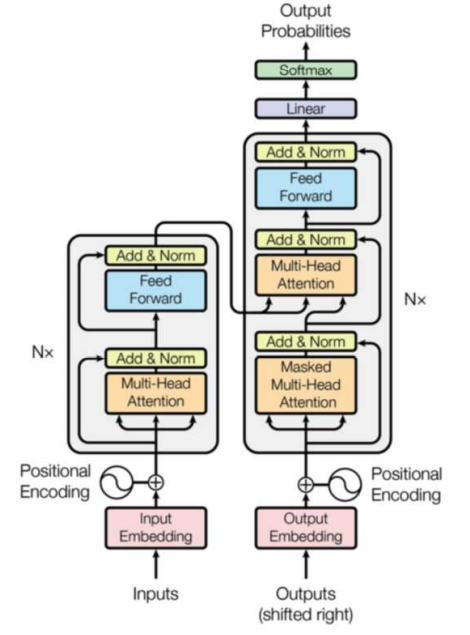
3.4 Decoder 解码器
结构:自注意力,encoder-decoder attention,全连接层
自注意力层:仅对输出序列中之前的位置;在softmax之前,把将来生成的位置设置为-inf
encoder-decoder attention
在自注意力层、全连接神经网络之间加入了一个encoder和decoder之间的注意力层,类似seq2seqRNN模型中的注意力。
最后一个Encoder的输出,转换为K和V的集合,每个decoder在其encoder-decoder attention层中使用这些KV。
工作方式与多头注意力类似,区别在于是从Encoder Stack的输出中获取KV。
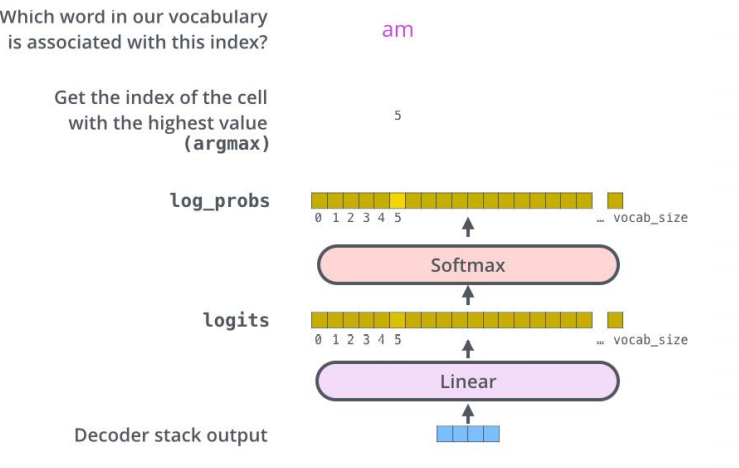
经过N层decoder,最终的输出通过线性层和softmax层得到输出的词
3.5 细节补充
残差和归一化 解码器编码器都有
Attention & Transformer的更多相关文章
- 2. Attention Is All You Need(Transformer)算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- 深入浅出Transformer
Transformer Transformer是NLP的颠覆者,它创造性地用非序列模型来处理序列化的数据,而且还获得了大成功.更重要的是,NLP真的可以"深度"学习了,各种基于tr ...
- [NLP] REFORMER: THE EFFICIENT TRANSFORMER
1.现状 (1) 模型层数加深 (2) 模型参数量变大 (3) 难以训练 (4) 难以fine-tune 2. 单层参数量和占用内存分析 层 参数设置 参数量与占用内存 1 layer 0.5Bill ...
- 文本建模、文本分类相关开源项目推荐(Pytorch实现)
Awesome-Repositories-for-Text-Modeling repo paper miracleyoo/DPCNN-TextCNN-Pytorch-Inception Deep Py ...
- 关于NLP和深度学习,准备好好看看这个github,还有这篇介绍
这个github感觉很不错,把一些比较新的实现都尝试了: https://github.com/brightmart/text_classification fastText TextCNN Text ...
- BERT解析及文本分类应用
目录 前言 BERT模型概览 Seq2Seq Attention Transformer encoder部分 Decoder部分 BERT Embedding 预训练 文本分类试验 参考文献 前言 在 ...
- ACNet: 特别的想法,腾讯提出结合注意力卷积的二叉神经树进行细粒度分类 | CVPR 2020
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的 ...
- 从RNN到BERT
一.文本特征编码 1. 标量编码 美国:1 中国:2 印度:3 … 朝鲜:197 标量编码问题:美国 + 中国 = 3 = 印度 2. One-hot编码 美国:[1,0,0,0,…,0]中国:[0, ...
- Transformer【Attention is all you need】
前言 Transfomer是一种encoder-decoder模型,在机器翻译领域主要就是通过encoder-decoder即seq2seq,将源语言(x1, x2 ... xn) 通过编码,再解码的 ...
随机推荐
- FL studio系列教程(十八):FL Studio输出监视面板讲解
在FL Studio编曲制作软件中输出监视器面板主要的功能是监视输出电平和波形以及频谱.下面大家就跟小编一起来认识下什么是FL Studio监视面板以及它的一些特征吧! 1.首先,我们来看一下输出监视 ...
- php bypass disable_function 命令执行 方法汇总简述
1.使用未被禁用的其他函数 exec,shell_exec,system,popen,proc_open,passthru (python_eval?perl_system ? weevely3 wi ...
- acm 易错警示
1:建图注意是有向图还是无向图,无向开两倍数组 2:看题注意是否为多组输入,多组输入注意初始化. 3:减法取模一定要注意 4:stl中.size()为unsigned如果要计算注意强制类型转换(int ...
- redis new
redis cluster 数据结构 geo,heperloglog 3个非核心dict:阻塞dict,非阻塞dict,watch dict 3个bio线程,生产者消费者模式,主线程生产者: 1.la ...
- Beta冲刺随笔——Day_Six
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 这个作业要求在哪里 Beta 冲刺 这个作业的目标 团队进行Beta冲刺 作业正文 正文 其他参考文献 无 今日事今日毕 林涛: ...
- Verilog单周期CPU(未完待续)
单周期CPU:指令周期=CPU周期 Top模块作为数据通路 运算器中有ALU,通路寄存器(R1.R2.R3.R4),数据缓冲寄存器(鉴于书上的运算器只有R0)........... 此为ALU和通用寄 ...
- 在 CentOS 7 安装 RabbitMQ
一.安装 Erlang RabbitMQ 是使用 Erlang 开发的,所以需要首先安装 Erlang,本文安装其最新版本 添加 repo 文件: sudo vim /etc/yum.repos.d/ ...
- 第3章 Python的数据类型 第3.1节 功能强大的 Python序列概述
一.概述 序列是Python中最基本的数据结构,C语言中没有这样的数据类型,只有数组有点类似,但序列跟数组差异比较大. 序列的典型特征如下: 序列使用索引来获取元素,这种索引方式适用于所有序列: 序列 ...
- 转:使用DOS命令chcp查看windows操作系统的默认编码以及编码和语言的对应关系
代码页是字符集编码的别名,也有人称"内码表".早期,代码页是IBM称呼电脑BIOS本身支持的字符集编码的名称.当时通用的操作系统都是命令行界面系统,这些操作系统直接使用BIOS供应 ...
- vue之keep-alive组件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...