redis缓存穿透穿透解决方案-布隆过滤器
redis缓存穿透穿透解决方案-布隆过滤器
我们先来看一段代码
cache_key = "id:1"
cache_value = GetValueFromRedis(cache_key); //判断缓存是否有数据
if cache_value != nil{ //如果有 直接返回数据
return cache_value
}
db_value = GetValueFromDb(cache_key) // 从数据库中查询数据
if db_value == nil{
return db_value
}
expire_time = 300
SetRedisValue(cache_key, db_value, expire_time) //将数据库的结果更新到缓存中,并直接返回结果
return db_value
相信绝大多数同学都是这么处理请求的,这样用redis能够给mysql抵挡住大部分的请求。其实这样是存在一定的问题的
问题1
我在请求的时候,用id=-1来请求
id=-1这条记录在数据库中是不存在的,当然对应的redis中也是没有的。那么就需要去请求数据库然后把数据写入到redis中,这样就会造成没有必要的数据库请求,一两个请求无所谓,但是如果从-∞到-1 无限的高频率的请求,就会给线上造成很大的压力。
针对问题1的解决方案
我们可以通过程序来限制id的合法性,判断id<1的情况都直接在接口层面拦截,这个方式的确可以解决上面说的那种情况,但是咱们接下来往下看
问题2
比如现在数据库id的最大值为1000,我们用比1000大的数字去请求
这种情况原理和问题1是一样的,这次我们就没法通过参数判断来拦截住请求了,所以我们就得用接下来一种经典的方式,布隆过滤器
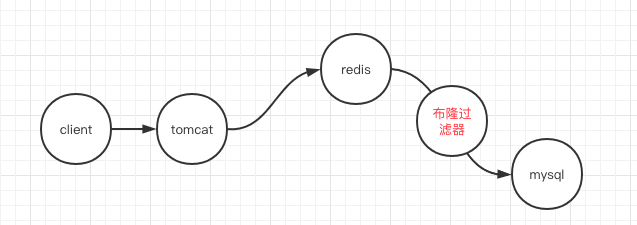
布隆过滤器其实就是一种比较巧妙的概率型数据结构,它可以告诉你某种东西一定不存在或者可能存在。从而达到对脏数据过滤的效果。他存在的位置如图
其实对布隆过滤器比较陌生的同学可以先想想,作为一个过滤器需要满足什么条件?
- 速度得快,得从内存查,如果从硬盘查的话还不如直接查数据库
- 因为过滤器里面得存入数据库所有的数据,所以内存势必是比较紧张的,所以内存要做到绝对的节省,说到节省内存,大家应该很容易能想到 redis里面的setbit操作
布隆过滤器的实现
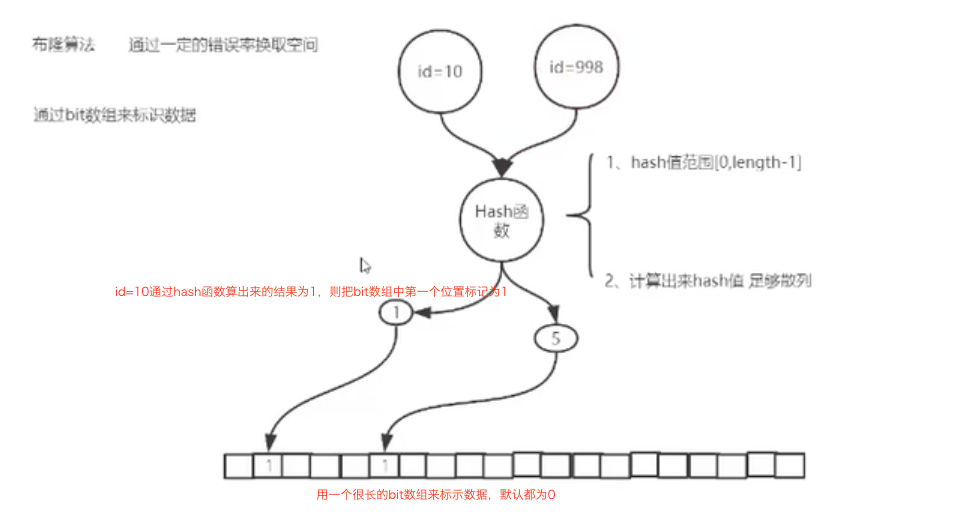
写入过程
- 通过bit数组来标识数据
- 比如id=10的数据,通过hash算法算出来结果为1
- 把bit数组下表为1的位置的值标记为1
查询过程
- 将id=10做hash运算,得到结果1
- 看bit数组下表为1的数据标识为1,则说明数据存在
其实我们看上面的算法是存在一定的问题的
1:只要是hash运算,就会存在hash碰撞问题,比如id=10 和id=100可能经过hash运算之后结果都为1,那么id=10写入之后查询id=100是否存在会误判为id=100也存在
2:当bit数组满了之后,查询的错误率肯定是百分之百,因为每个数据都存在
这些其实都是导致错误率的原因,错误率是不可能避免的,但是咱们可以减少错误率,减少错误率的方法有两个
1:加大bit数组的长度,对于bit数组的长度的增加是不用担心的,因为是bit操作,所以可以加到很大的值
2:增加hash函数的个数,hash函数的个数增加了,说明标识一个数组需要的位置就会变多。这样会降低发生hash碰撞的概率。但是hash的函数也不是越多越好,需要参照数组的长度来定
hash错误率:
布隆算法说数据存在,那么实际有可能不存在
如果数据不存在。那么一定不存在
布隆过滤器redis中的使用方法
1.下载redisbloom插件(redis官网下载即可)
wget https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz
2:解压并安装,生成.so文件
[root@redis]# tar -zxvf v1.1.1.tar.gz
[root@redis]# cd Redisbloom-1.1.1/
[root@redisbloom-1.1.1]# make
[root@redisbloom-1.1.1]# ls
contrib Dockerfile docs LICENSE Makefile mkdocs.yml ramp.yml README.md rebloom.so src tests
3:在redis配置文件(redis.conf)中加入该模块即可
[root@redis]# vim redis.conf
#####################MODULES################# # Load modules at startup. If the server is not able to load modules
# it will abort. It is possible to use multiple loadmodule directives.
loadmodule /usr/local/redis/redisbloom-1.1.1/rebloom.so
4:重新启动redis
redis-server ./redis.conf
5:测试安装是否成功
127.0.0.1:6379> bf.add users user2 //写入数据user2
(integer) 1
127.0.0.1:6379> bf.add users user1 //写入数据user1
(integer) 1
127.0.0.1:6379> bf.exists users user1 //查询user1存在
(integer) 1
127.0.0.1:6379> bf.exists users user3 //查询user3不存在
(integer) 0
上面说过布隆过滤器存在误判的情况,在 redis 中有两个值决定布隆过滤器的准确率:
- error_rate :允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
- initial_size :布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:
bf.reserve users 0.01 100
三个参数的含义:
第一个值是过滤器的名字。
第二个值为 error_rate 的值。
第三个值为 initial_size 的值。
关注我的技术公众号,每周都有优质技术文章推送。
微信扫一扫下方二维码即可关注:

redis缓存穿透穿透解决方案-布隆过滤器的更多相关文章
- REDIS 缓存的穿透,雪崩和热点key
穿透 穿透:频繁查询一个不存在的数据,由于缓存不命中,每次都要查询持久层.从而失去缓存的意义. 解决办法:①用一个bitmap和n个hash函数做布隆过滤器过滤没有在缓存的键. ②持久层查询不到就 ...
- Redis 缓存问题及解决方案
[相关概念] 缓存击穿:指的是一些热点数据过期,由于热点数据存在并发量大的特性,所以短时间内对数据库的造成很大的冲击,导致系统瘫痪.常见于例如微博系统中明星结婚或出轨时微博瘫痪的情况. 缓存雪崩:指的 ...
- Redis: 缓存过期、缓存雪崩、缓存穿透、缓存击穿(热点)、缓存并发(热点)、多级缓存、布隆过滤器
Redis: 缓存过期.缓存雪崩.缓存穿透.缓存击穿(热点).缓存并发(热点).多级缓存.布隆过滤器 2019年08月18日 16:34:24 hanchao5272 阅读数 1026更多 分类专栏: ...
- Redis缓存穿透和缓存雪崩以及解决方案
Redis缓存穿透和缓存雪崩以及解决方案 Redis缓存穿透和缓存雪崩以及解决方案缓存穿透解决方案布隆过滤缓存空对象比较缓存雪崩解决方案保证缓存层服务高可用性依赖隔离组件为后端限流并降级数据预热缓存并 ...
- Redis缓存穿透问题及解决方案
上周在工作中遇到了一个问题场景,即查询商品的配件信息时(商品:配件为1:N的关系),如若商品并未配置配件信息,则查数据库为空,且不会加入缓存,这就会导致,下次在查询同样商品的配件时,由于缓存未命中,则 ...
- Redis缓存穿透和缓存雪崩的面试题解析
前段时间去摩拜面试,然后,做笔试的时候,遇到了几道Redis面试题目,今天来做个总结.捋一下思路,顺便温习一下之前的知识,如果对您有帮助,左上角点下关注 ! 谢谢 文章目录 缓存穿透 缓存雪崩 大家都 ...
- Redis缓存穿透、缓存雪崩、缓存击穿好好说说
前言 Redis是目前非常流行的缓存数据库啦,其中一个主要作用就是为了避免大量请求直接打到数据库,以此来缓解数据库服务器压力:用上缓存难道就高枕无忧了吗?no,no,no,没有这么完美的技术, 缓存穿 ...
- Redis缓存雪崩、击穿、穿透
参考大佬 前言 Redis在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在Redis的使用和原理方面对小伙伴们进行360°的刁难.作为一个在互联网公司面一次拿一次offer的面霸(请允 ...
- Redis 缓存雪崩、穿透、击穿
缓存雪崩 定义: 同一时间所有 key 大面积失效,比如网站首页的数据基本上都是同一批次去缓存的. 解决方法: ① 存的时候设定随机的失效时间. ② 服务做熔断处理(异常或着慢查询 Hystrix 限 ...
随机推荐
- requestAnimationFrame小结
背景 在Web应用中,实现动画效果的方法比较多,Javascript 中可以通过定时器 setTimeout或者setInterval 来实现,css3 可以使用 transition 和 anima ...
- 关于ckfinder上传文件添加自定义处理方案
上篇博客中介绍了如何使用ckfinder中自定义按钮的功能,实现自定义上传的功能,但是却无法解决用户使用拖拽文件上传方式中添加自定义事件,今天我们来用另一种更简洁的方式来实现上传文件重名时做一些自定义 ...
- HTML5 初学者一步一步攀爬 努力加油学习
Html 5 Html:Hyper Text MarKup Language超文本标签语言 Html:网页的源码 浏览器:"解释和执行"HTMl源码的工具 Head 标签内的信息用 ...
- Sqoop export参数updatemode两种模式updateonly和allowinsert区别
1.更新导出(updateonly模式)1.1参数说明-- update-key,更新标识,即根据某个字段进行更新,例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔. -- updatem ...
- jQuery插件Validate
一.导入js库 <script type="text/javascript" src="<%=path %>/validate/jquery-1.6.2 ...
- Codeforces Round #622 (Div. 2) C2. Skyscrapers (hard version)(单调栈,递推)
Codeforces Round #622 (Div. 2) C2. Skyscrapers (hard version) 题意: 你是一名建筑工程师,现给出 n 幢建筑的预计建设高度,你想建成峰状, ...
- hdu1517 A Multiplication Game
Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submission ...
- FZU1894 志愿者选拔
Problem Description 世博会马上就要开幕了,福州大学组织了一次志愿者选拔活动.参加志愿者选拔的同学们排队接受面试官们的面试.参加面试的同学们按照先来先面试并且先结束的原则接受面试官们 ...
- Kibana 地标图可视化
ElasticSearch 可以使用 ingest-geoip 插件可以在 Kibana 上对 IP 进行地理位置分析, 这个插件需要 Maxmind 的 GeoLite2 City,GeoLite2 ...
- POJ - 3280 Cheapest Palindrome 【区间dp】【非原创】
Keeping track of all the cows can be a tricky task so Farmer John has installed a system to automate ...