有必要了解的大数据知识(一) Hadoop
前言
之前工作中,有接触到大数据的需求,虽然当时我们体系有专门的大数据部门,但是由于当时我们中台重构,整个体系的开发量巨大,共用一个大数据部门,人手已经忙不过来,没法办,为了赶时间,我自己负责的系统的大数据相关操作,由我们自己承担了。此前对大数据的知识了解的很少,于是晚上回去花时间突击大数据知识,白天就开始上手干,一边学一边做,总算在部门规定的时间,跟系统一起上线了。后来的维护迭代就交给大数据去了,虽然接触大数据的时间不长,但是对我来说,确是很有意思的一段经历,觉得把当时匆匆学的知识点,再仔细回顾回顾,整理下。
大数据概述
大数据: 就是对海量数据进行分析处理,得到一些有价值的信息,然后帮助企业做出判断和决策.
处理流程:
1:获取数据
2:处理数据
3:展示结果
Hadoop介绍
Hadoop是一个分布式系基础框架,它允许使用简单的编程模型跨大型计算机的大型数据集进行分布式处理.它主要解决两个问题
大数据存储问题: HDFS
大数据计算问题:MapReduce
问题一: 大文件怎么存储?
假设一个文件非常非常大,大小为1PB/a.txt, 大到世界上所有的高级计算机都存储不下, 怎么办?
- 为了保存大文件, 需要把文件放在多个机器上
- 文件要分块 block(128M)
- 不同的块放在不同的
HDFS节点
- 同时为了对外提供统一的访问, 让外部可以像是访问本机一样访问分布式文件系统
- 有一个统一的
HDFS Master - 它保存整个系统的文件信息
- 所有的文件元数据的修改都从
Master开始
- 有一个统一的
问题二: 大数据怎么计算?
从一个网络日志文件中计算独立 IP, 以及其出现的次数
如果数据量特别大,我们可以将,整个任务拆开, 划分为比较小的任务, 从而进行计算呢。
问题三: 如何将这些计算任务跑在集群中?
如果能够在不同的节点上并行执行, 更有更大的提升, 如何把这些任务跑在集群中?
- 可以设置一个集群的管理者, 这个地方叫做
Yarn- 这个集群管理者有一个
Master, 用于接收和分配任务 - 这个集群管理者有多个
Slave, 用于运行任务
- 这个集群管理者有一个
Hadoop 的组成
- Hadoop分布式文件系统(HDFS) 提供对应用程序数据的高吞吐量访问的分布式文件系统
- Hadoop Common 其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的必要Java文件和脚本
- Hadoop MapReduce 基于YARN的大型数据集并行处理系统
- Hadoop YARN 作业调度和集群资源管理的框架
Hadoop前生今世
- Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目.
狭义上来说,hadoop就是单独指代hadoop这个软件,
HDFS :分布式文件系统
MapReduce : 分布式计算系统
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
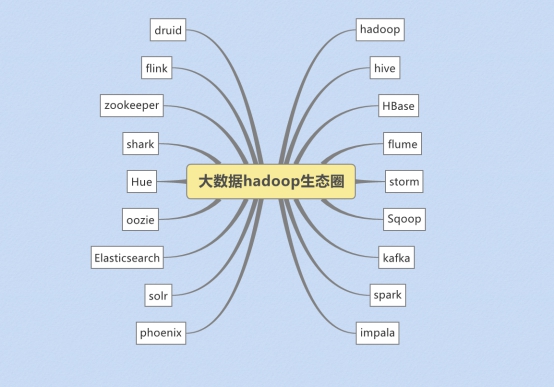
hadoop的架构模型
1.x的版本架构模型介绍
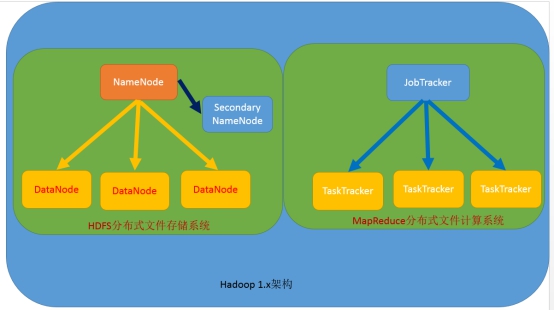
文件系统核心模块:
NameNode:集群当中的主节点,管理元数据(文件的大小,文件的位置,文件的权限),主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
JobTracker:接收用户的计算请求任务,并分配任务给从节点
TaskTracker:负责执行主节点JobTracker分配的任务
2.x的版本架构模型介绍
第一种:NameNode与ResourceManager单节点架构模型
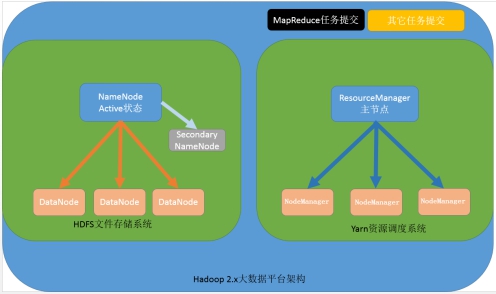
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager:负责执行主节点APPmaster分配的任务
第二种:NameNode单节点与ResourceManager高可用架构模型
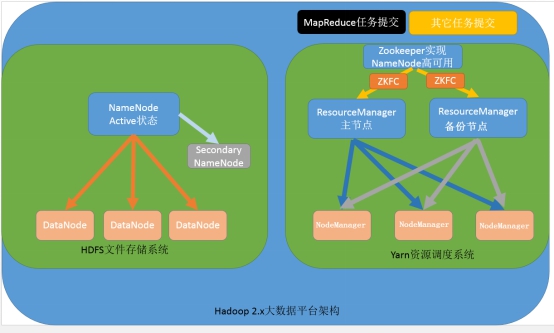
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分,通过zookeeper实现ResourceManager的高可用
NodeManager:负责执行主节点ResourceManager分配的任务
第三种:NameNode高可用与ResourceManager单节点架构模型
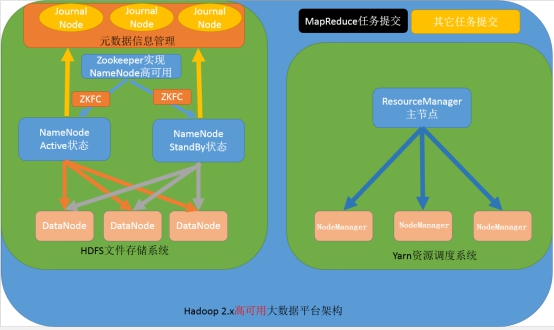
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,其中nameNode可以有两个,形成高可用状态
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
JournalNode:文件系统元数据信息管理
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分
NodeManager:负责执行主节点ResourceManager分配的任务
第四种:NameNode与ResourceManager高可用架构模型

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用
JournalNode:元数据信息管理进程,一般都是奇数个
DataNode:从节点,用于数据的存储
数据计算核心模块:
ResourceManager:Yarn平台的主节点,主要用于接收各种任务,通过两个,构建成高可用
NodeManager:Yarn平台的从节点,主要用于处理ResourceManager分配的任务
Hadoop 核心介绍
1. HDFS
HDFS(Hadoop Distributed File System) 是一个 Apache Software Foundation 项目, 是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统. HDFS 对数据文件的访问通过流的方式进行处理, 这意味着通过命令和 MapReduce 程序的方式可以直接使用 HDFS. HDFS 是容错的, 且提供对大数据集的高吞吐量访问.
HDFS 的一个非常重要的特点就是一次写入、多次读取, 该模型降低了对并发控制的要求, 简化了数据聚合性, 支持高吞吐量访问. 而吞吐量是大数据系统的一个非常重要的指标, 吞吐量高意味着能处理的数据量就大.
1.1. 设计目标
- 通过跨多个廉价计算机集群分布数据和处理来节约成本
- 通过自动维护多个数据副本和在故障发生时来实现可靠性
- 它们为存储和处理超大规模数据提供所需的扩展能力。
1.2. HDFS 的历史
- Doug Cutting 在做 Lucene 的时候, 需要编写一个爬虫服务, 这个爬虫写的并不顺利, 遇到了一些问题, 诸如: 如何存储大规模的数据, 如何保证集群的可伸缩性, 如何动态容错等
- 2013年的时候, Google 发布了三篇论文, 被称作为三驾马车, 其中有一篇叫做 GFS, 是描述了 Google 内部的一个叫做 GFS 的分布式大规模文件系统, 具有强大的可伸缩性和容错性
- Doug Cutting 后来根据 GFS 的论文, 创造了一个新的文件系统, 叫做 HDFS
1.3. HDFS 的架构
- NameNode 是一个中心服务器, 单一节点(简化系统的设计和实现), 负责管理文件系统的名字空间(NameSpace)以及客户端对文件的访问
- 文件操作, NameNode 是负责文件元数据的操作, DataNode 负责处理文件内容的读写请求, 跟文件内容相关的数据流不经过 NameNode, 只询问它跟哪个 DataNode联系, 否则 NameNode 会成为系统的瓶颈
- 副本存放在哪些 DataNode 上由 NameNode 来控制, 根据全局情况作出块放置决定, 读取文件时 NameNode 尽量让用户先读取最近的副本, 降低读取网络开销和读取延时
- NameNode 全权管理数据库的复制, 它周期性的从集群中的每个DataNode 接收心跳信合和状态报告, 接收到心跳信号意味着 DataNode 节点工作正常, 块状态报告包含了一个该 DataNode 上所有的数据列表
| NameNode | DataNode |
|---|---|
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘 |
| 保存文件, block, DataNode 之间的关系 | 维护了 block id 到 DataNode 文件之间的关系 |
1.4. HDFS 文件副本和 Block 块存储
所有的文件都是以 block 块的方式存放在 HDFS 文件系统当中, 在 Hadoop1 当中, 文件的 block 块默认大小是64M, hadoop2 当中, 文件的 block 块大小默认是 128M, block 块的大小可以通过 hdfs-site.xml 当中的配置文件进行指定
<property>
<name>dfs.block.size</name>
<value>块大小 以字节为单位</value>
</property>
1.4.1. 引入块机制的好处
- 一个文件有可能大于集群中任意一个磁盘
- 使用块抽象而不是文件可以简化存储子系统
- 块非常适合用于数据备份进而提供数据容错能力和可用性
1.4.2. 块缓存
通常 DataNode 从磁盘中读取块, 但对于访问频繁的文件, 其对应的块可能被显式的缓存在 DataNode 的内存中, 以堆外块缓存的形式存在. 默认情况下,一个块仅缓存在一个 DataNode 的内存中,当然可以针对每个文件配置 DataNode 的数量. 作业调度器通过在缓存块的 DataNode 上运行任务, 可以利用块缓存的优势提高读操作的性能.
例如:
连接(join) 操作中使用的一个小的查询表就是块缓存的一个很好的候选
用户或应用通过在缓存池中增加一个 Cache Directive 来告诉 NameNode 需要缓存哪些文件及存多久. 缓存池(Cache Pool) 是一个拥有管理缓存权限和资源使用的管理性分组.
例如一个文件 130M, 会被切分成 2 个 block 块, 保存在两个 block 块里面, 实际占用磁盘 130M 空间, 而不是占用256M的磁盘空间
1.4.3. HDFS 文件权限验证
HDFS 的文件权限机制与 Linux 系统的文件权限机制类似
r:read w:write x:execute
权限 x 对于文件表示忽略, 对于文件夹表示是否有权限访问其内容 如果 Linux 系统用户 zhangsan 使用 Hadoop 命令创建一个文件, 那么这个文件在 HDFS 当中的 Owner 就是 zhangsan HDFS 文件权限的目的, 防止好人做错事, 而不是阻止坏人做坏事. HDFS相信你告诉我你是谁, 你就是谁
1.5. HDFS 的元信息和 SecondaryNameNode
当 Hadoop 的集群当中, 只有一个 NameNode 的时候, 所有的元数据信息都保存在了 FsImage 与 Eidts 文件当中, 这两个文件就记录了所有的数据的元数据信息, 元数据信息的保存目录配置在了 hdfs-site.xml 当中
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-3.1.1/datas/namenode/namenodedatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-3.1.1/datas/dfs/nn/edits</value>
</property>
1.5.1. FsImage 和 Edits 详解
editsedits存放了客户端最近一段时间的操作日志- 客户端对 HDFS 进行写文件时会首先被记录在
edits文件中 edits修改时元数据也会更新- 每次 HDFS 更新时
edits先更新后客户端才会看到最新信息
fsimage- NameNode 中关于元数据的镜像, 一般称为检查点,
fsimage存放了一份比较完整的元数据信息 - 因为
fsimage是 NameNode 的完整的镜像, 如果每次都加载到内存生成树状拓扑结构,这是非常耗内存和CPU, 所以一般开始时对 NameNode 的操作都放在 edits 中 fsimage内容包含了 NameNode 管理下的所有 DataNode 文件及文件 block 及 block 所在的 DataNode 的元数据信息.- 随着
edits内容增大, 就需要在一定时间点和fsimage合并
- NameNode 中关于元数据的镜像, 一般称为检查点,
1.5.2. fsimage 中的文件信息查看
使用命令 hdfs oiv
cd /export/servers/hadoop-3.1.1/datas/namenode/namenodedatas
hdfs oiv -i fsimage_0000000000000000864 -p XML -o hello.xml
1.5.3. edits 中的文件信息查看
使用命令 hdfs oev
cd /export/servers/hadoop-3.1.1/datas/dfs/nn/edits
hdfs oev -i edits_0000000000000000865-0000000000000000866 -o myedit.xml -p XML
1.5.4. SecondaryNameNode 如何辅助管理 fsimage 与 edits 文件?
SecondaryNameNode 定期合并 fsimage 和 edits, 把 edits 控制在一个范围内
配置 SecondaryNameNode
SecondaryNameNode 在
conf/masters中指定在 masters 指定的机器上, 修改
hdfs-site.xml<property>
<name>dfs.http.address</name>
<value>host:50070</value>
</property>
修改
core-site.xml, 这一步不做配置保持默认也可以<!-- 多久记录一次 HDFS 镜像, 默认 1小时 -->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
<!-- 一次记录多大, 默认 64M -->
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
- SecondaryNameNode 通知 NameNode 切换 editlog
- SecondaryNameNode 从 NameNode 中获得 fsimage 和 editlog(通过http方式)
- SecondaryNameNode 将 fsimage 载入内存, 然后开始合并 editlog, 合并之后成为新的 fsimage
- SecondaryNameNode 将新的 fsimage 发回给 NameNode
- NameNode 用新的 fsimage 替换旧的 fsimage
特点
- 完成合并的是 SecondaryNameNode, 会请求 NameNode 停止使用 edits, 暂时将新写操作放入一个新的文件中
edits.new - SecondaryNameNode 从 NameNode 中通过 Http GET 获得 edits, 因为要和 fsimage 合并, 所以也是通过 Http Get 的方式把 fsimage 加载到内存, 然后逐一执行具体对文件系统的操作, 与 fsimage 合并, 生成新的 fsimage, 然后通过 Http POST 的方式把 fsimage 发送给 NameNode. NameNode 从 SecondaryNameNode 获得了 fsimage 后会把原有的 fsimage 替换为新的 fsimage, 把 edits.new 变成 edits. 同时会更新 fstime
- Hadoop 进入安全模式时需要管理员使用 dfsadmin 的 save namespace 来创建新的检查点
- SecondaryNameNode 在合并 edits 和 fsimage 时需要消耗的内存和 NameNode 差不多, 所以一般把 NameNode 和 SecondaryNameNode 放在不同的机器上
1.6 HDFS 文件写入过程
- Client 发起文件上传请求, 通过 RPC 与 NameNode 建立通讯, NameNode 检查目标文件是否已存在, 父目录是否存在, 返回是否可以上传
- Client 请求第一个 block 该传输到哪些 DataNode 服务器上
- NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分配, 返回可用的 DataNode 的地址如: A, B, C
- Hadoop 在设计时考虑到数据的安全与高效, 数据文件默认在 HDFS 上存放三份, 存储策略为本地一份, 同机架内其它某一节点上一份, 不同机架的某一节点上一份。
- Client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调用,建立 pipeline ), A 收到请求会继续调用 B, 然后 B 调用 C, 将整个 pipeline 建立完成, 后逐级返回 client
- Client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存), 以 packet 为单位(默认64K), A 收到一个 packet 就会传给 B, B 传给 C. A 每传一个 packet 会放入一个应答队列等待应答
- 数据被分割成一个个 packet 数据包在 pipeline 上依次传输, 在 pipeline 反方向上, 逐个发送 ack(命令正确应答), 最终由 pipeline 中第一个 DataNode 节点 A 将 pipelineack 发送给 Client
- 当一个 block 传输完成之后, Client 再次请求 NameNode 上传第二个 block 到服务 1
1.7. HDFS 文件读取过程
- Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
- NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址; 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
- Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性);
- 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
- 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
- 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
- read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
- 最终读取来所有的 block 会合并成一个完整的最终文件。
1.9. HDFS 的 API 操作
1.9.1. 导入 Maven 依赖
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>3.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
1.9.2. 概述
在 Java 中操作 HDFS, 主要涉及以下 Class:
Configuration- 该类的对象封转了客户端或者服务器的配置
FileSystem该类的对象是一个文件系统对象, 可以用该对象的一些方法来对文件进行操作, 通过 FileSystem 的静态方法 get 获得该对象
FileSystem fs = FileSystem.get(conf)
get方法从conf中的一个参数fs.defaultFS的配置值判断具体是什么类型的文件系统- 如果我们的代码中没有指定
fs.defaultFS, 并且工程 ClassPath 下也没有给定相应的配置,conf中的默认值就来自于 Hadoop 的 Jar 包中的core-default.xml - 默认值为
file:///, 则获取的不是一个 DistributedFileSystem 的实例, 而是一个本地文件系统的客户端对象
1.9.3. 获取 FileSystem 的几种方式
- 第一种方式
@Test
public void getFileSystem() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.250:8020"), configuration);
System.out.println(fileSystem.toString());
}
- 第二种方式
@Test
public void getFileSystem2() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.52.250:8020");
FileSystem fileSystem = FileSystem.get(new URI("/"), configuration);
System.out.println(fileSystem.toString());
}
- 第三种方式
@Test
public void getFileSystem3() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.52.250:8020"), configuration);
System.out.println(fileSystem.toString());
}
- 第四种方式
@Test
public void getFileSystem4() throws Exception{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.52.250:8020");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem.toString());
}
1.9.4. 遍历 HDFS 中所有文件
- 递归遍历
@Test
public void listFile() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
if(fileStatus.isDirectory()){
Path path = fileStatus.getPath();
listAllFiles(fileSystem,path);
}else{
System.out.println("文件路径为"+fileStatus.getPath().toString());
}
}
}
public void listAllFiles(FileSystem fileSystem,Path path) throws Exception{
FileStatus[] fileStatuses = fileSystem.listStatus(path);
for (FileStatus fileStatus : fileStatuses) {
if(fileStatus.isDirectory()){
listAllFiles(fileSystem,fileStatus.getPath());
}else{
Path path1 = fileStatus.getPath();
System.out.println("文件路径为"+path1);
}
}
}
- 使用 API 遍历
@Test
public void listMyFiles()throws Exception{
//获取fileSystem类
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.250:8020"), new Configuration());
//获取RemoteIterator 得到所有的文件或者文件夹,第一个参数指定遍历的路径,第二个参数表示是否要递归遍历
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fileSystem.listFiles(new Path("/"), true);
while (locatedFileStatusRemoteIterator.hasNext()){
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
System.out.println(next.getPath().toString());
}
fileSystem.close();
}
1.9.5. 下载文件到本地
@Test
public void getFileToLocal()throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.250:8020"), new Configuration());
FSDataInputStream open = fileSystem.open(new Path("/test/input/install.log"));
FileOutputStream fileOutputStream = new FileOutputStream(new File("c:\\install.log"));
IOUtils.copy(open,fileOutputStream );
IOUtils.closeQuietly(open);
IOUtils.closeQuietly(fileOutputStream);
fileSystem.close();
}
1.9.6. HDFS 上创建文件夹
@Test
public void mkdirs() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.250:8020"), new Configuration());
boolean mkdirs = fileSystem.mkdirs(new Path("/hello/mydir/test"));
fileSystem.close();
}
1.9.7. HDFS 文件上传
@Test
public void putData() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.250:8020"), new Configuration());
fileSystem.copyFromLocalFile(new Path("file:///c:\\install.log"),new Path("/hello/mydir/test"));
fileSystem.close();
}
1.9.8. 伪造用户
- 停止hdfs集群,在node01机器上执行以下命令
cd /export/servers/hadoop-3.1.1
sbin/stop-dfs.sh
- 修改node01机器上的hdfs-site.xml当中的配置文件
cd /export/servers/hadoop-3.1.1/etc/hadoop
vim hdfs-site.xml
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
- 修改完成之后配置文件发送到其他机器上面去
scp hdfs-site.xml node02:$PWD
scp hdfs-site.xml node03:$PWD
- 重启hdfs集群
cd /export/servers/hadoop-3.1.1
sbin/start-dfs.sh
- 随意上传一些文件到我们hadoop集群当中准备测试使用
cd /export/servers/hadoop-3.1.1/etc/hadoop
hdfs dfs -mkdir /config
hdfs dfs -put *.xml /config
hdfs dfs -chmod 600 /config/core-site.xml
- 使用代码准备下载文件
@Test
public void getConfig()throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.250:8020"), new Configuration(),"hadoop");
fileSystem.copyToLocalFile(new Path("/config/core-site.xml"),new Path("file:///c:/core-site.xml"));
fileSystem.close();
}
1.9.9. 小文件合并
由于 Hadoop 擅长存储大文件,因为大文件的元数据信息比较少,如果 Hadoop 集群当中有大量的小文件,那么每个小文件都需要维护一份元数据信息,会大大的增加集群管理元数据的内存压力,所以在实际工作当中,如果有必要一定要将小文件合并成大文件进行一起处理
在我们的 HDFS 的 Shell 命令模式下,可以通过命令行将很多的 hdfs 文件合并成一个大文件下载到本地
cd /export/servers
hdfs dfs -getmerge /config/*.xml ./hello.xml
既然可以在下载的时候将这些小文件合并成一个大文件一起下载,那么肯定就可以在上传的时候将小文件合并到一个大文件里面去

@Test
public void mergeFile() throws Exception{
//获取分布式文件系统
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.250:8020"), new Configuration(),"hadoop");
FSDataOutputStream outputStream = fileSystem.create(new Path("/bigfile.xml"));
//获取本地文件系统
LocalFileSystem local = FileSystem.getLocal(new Configuration());
//通过本地文件系统获取文件列表,为一个集合
FileStatus[] fileStatuses = local.listStatus(new Path("file:///F:\\传智播客大数据离线阶段课程资料\\3、大数据离线第三天\\上传小文件合并"));
for (FileStatus fileStatus : fileStatuses) {
FSDataInputStream inputStream = local.open(fileStatus.getPath());
IOUtils.copy(inputStream,outputStream);
IOUtils.closeQuietly(inputStream);
}
IOUtils.closeQuietly(outputStream);
local.close();
fileSystem.close();
}
有必要了解的大数据知识(一) Hadoop的更多相关文章
- 有必要了解的大数据知识(二) Hadoop
前言 接上文,复习整理大数据相关知识点,这章节从MapReduce开始... MapReduce介绍 MapReduce思想在生活中处处可见.或多或少都曾接触过这种思想.MapReduce的思想核心是 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 大数据测试之初识Hadoop
大数据测试之初识Hadoop POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的cas ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 孙荣辛|大数据穿针引线进阶必看——Google经典大数据知识
大数据技术的发展是一个非常典型的技术工程的发展过程,荣辛通过对于谷歌经典论文的盘点,希望可以帮助工程师们看到技术的探索.选择过程,以及最终历史告诉我们什么是正确的选择. 何为大数据 "大 ...
- 【大数据】了解Hadoop框架的基础知识
介绍 此Refcard提供了Apache Hadoop,这是最流行的软件框架,可使用简单的高级编程模型实现大型数据集的分布式存储和处理.我们将介绍Hadoop最重要的概念,描述其架构,指导您如何开始使 ...
- 从Hadoop Summit 2016看大数据行业与Hadoop的发展
前言: 好吧我承认已经有四年多没有更新博客了.... 在这四年中发生了很多事情,换了工作,换了工作的方向.在工作的第一年的时候接触机器学习,从那之后的一年非常狂热的学习机器学习的相关技术,也写了一些自 ...
- ASP.NET + SqlSever 大数据解决方案 PK HADOOP
半个月前看到博客园有人说.NET不行那篇文章,我只想说你们有时间去抱怨不如多写些实在的东西. 1.SQLSERVER优点和缺点? 优点:支持索引.事务.安全性以及容错性高 缺点:数据量达到100万以 ...
- 大数据 --> Spark与Hadoop对比
Spark与Hadoop对比 什么是Spark Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法 ...
随机推荐
- Leetcode(206)-反转链表
反转一个单链表. 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL 思路:反转链表很简 ...
- 关于FFT的一些理解,以及如何手工计算FFT加深理解和验证正确性
总结缺少逻辑性和系统性,主要便于自己理解和记忆 关于一维FFT的 于是复系数Cn是图像傅里叶变换的yn列向量 于是我们看到最后引入,Cn这个复系数的模来表征频率波的振幅记为Sn(即简谐波叠加的数量 然 ...
- 微服务架构Day05-SpringBoot之Servlet
旧版 配置嵌入式Servlet容器 SpringBoot默认使用Tomcat作为嵌入式Servlet容器 如何定制和修改Servlet容器相关配置 1.在配置文件中定制和修改Servlet容器有关的配 ...
- macOS & Catalina vs Big Sur
macOS & Catalina vs Big Sur 乍一看,macOS的色彩更加丰富,最大的变化就是明亮,略带卡通风格的iOS形状的图标. 一切都变得更加圆润,感觉一切都变得更大了. 这可 ...
- github & markdown & image layout
github & markdown & image layout css & right https://github.com/sindresorhus/log-symbols ...
- navigator.geolocation.getCurrentPosition
navigator.geolocation.getCurrentPosition Geolocation API Specification 2nd Edition W3C Recommendatio ...
- Flutter & QRCode App
Flutter & QRCode App https://github.com/xgqfrms/qrcode-reader-app how to open android emulator o ...
- js IdleDetector 检测用户是否处于活动状态API
btn.addEventListener("click", async () => { try { const state = await Notification.requ ...
- Flutter: random color
import 'dart:math' as math; import 'package:flutter/material.dart'; void main() => runApp(App()); ...
- ECMAScript 等性运算符
判断两个变量是否相等是程序设计中非常重要的运算.在处理原始值时,这种运算相当简单,但涉及对象,任务就稍有点复杂. ECMAScript 提供了两套等性运算符:等号和非等号用于处理原始值,全等号和非全等 ...