R语言学习笔记-单一决策树
决策树比较简单明晰,但存在不稳定的风险,数据的微小变化会导致最佳决策树结构的巨大变化,且决策树可能会变得比较复杂。
其算法原理参见https://zhuanlan.zhihu.com/p/148010749。笔记中主要以R语言中iris数据集描述实现步骤。
- data("iris") #导入iris数据集
set.seed(1926) #设置种子,便于复现操作结果 +1S
之后需要将数据分为两部分,训练集与测试集,可以用多种写法实现。这些写法的本质上都是sample函数
方法一:
- train.data <-sample(nrow(iris),0.7*nrow(iris),replace = F)
- train <-iris[train.data,]
- test <-iris[-train.data,]
写法二:
- formula <- sample(2, nrow(iris),
- replace=TRUE,
- prob=c(0.7, 0.3)
- )
- train <- iris[formula==1,]
- test <- iris[formula==2,]
写法三:
- smple.size <- floor(0.7*nrow(data)) )
- train.ind <- sample(seq_len(nrow(data)), smple.size)
- train <- data[train.ind, ]
- test <- data[-train.ind, ]
写法四:
- rank_num <- sample(1:150,105)
- train <- iris[rank_num,]
- test <- iris[-rank_num,]
接下来进行单一决策树分析,常用的包有tree,rpart,party等。
package "party"
- library(party)
- mdna.tree <- ctree(Species ~ Sepal.Length+Sepal.Width+Petal.Length+Petal.Width, data = train)
- mdna.tree
- #可以看看具体的分析
- plot(mdna.tree, type = "simple",main = "mdna的简单决策树")
- #也可以自己画图,上面的是简单树装图
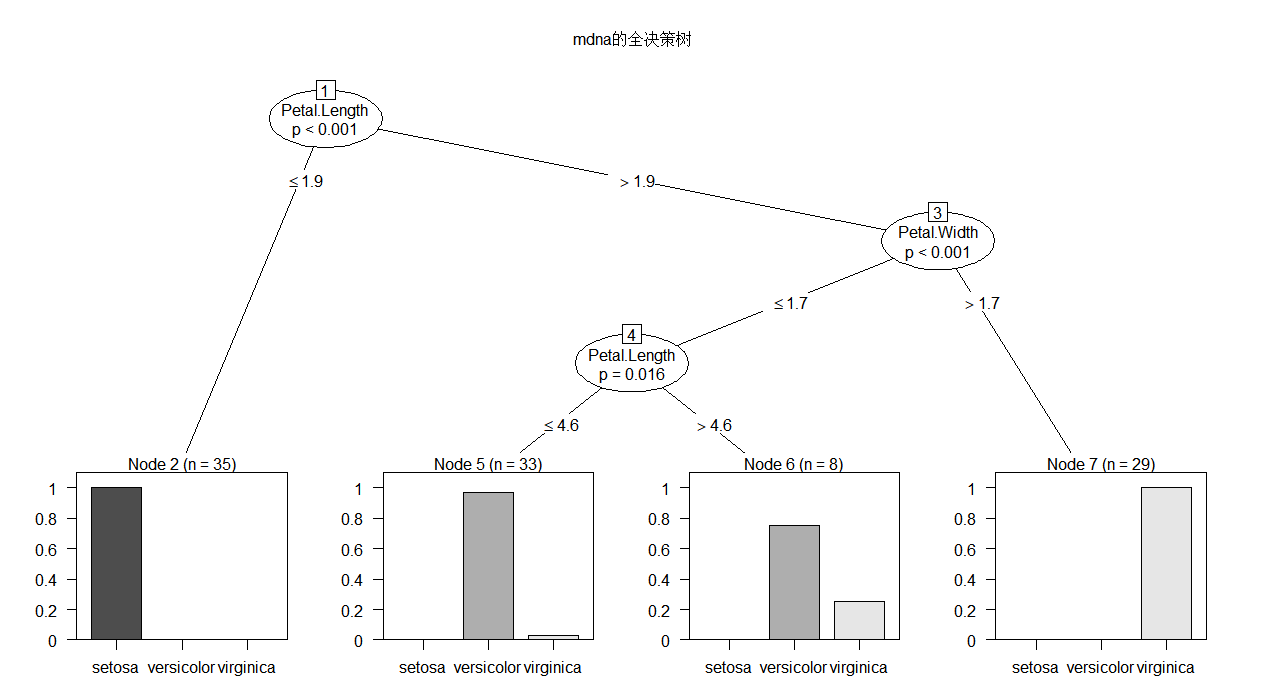
- plot(mdna.tree,main = "mdna的全决策树")
- #全面树状图
- Conditional inference tree with 4 terminal nodes
- Response: Species
- Inputs: Sepal.Length, Sepal.Width, Petal.Length, Petal.Width
- Number of observations: 105
- 1) Petal.Length <= 1.9; criterion = 1, statistic = 98.207
- 2)* weights = 35
- 1) Petal.Length > 1.9
- 3) Petal.Width <= 1.7; criterion = 1, statistic = 50.335
- 4) Petal.Length <= 4.6; criterion = 0.984, statistic = 8.319
- 5)* weights = 33
- 4) Petal.Length > 4.6
- 6)* weights = 8
- 3) Petal.Width > 1.7
- 7)* weights = 29

package "rpart"
- library('rpart')
- library('rpart.plot')
- model.2<- rpart(formula =Species~.,data=train ,method='class')
- model.2
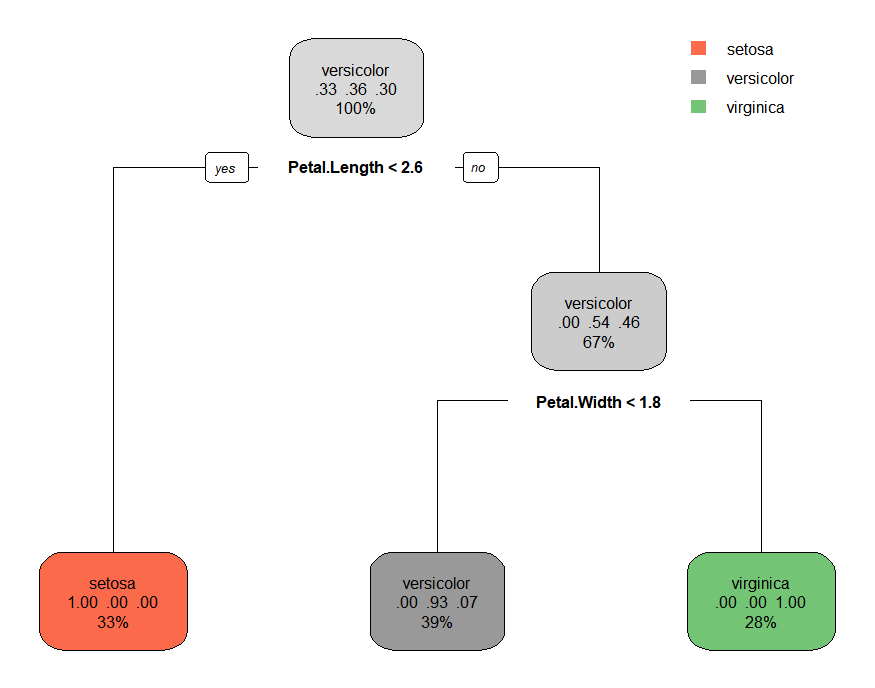
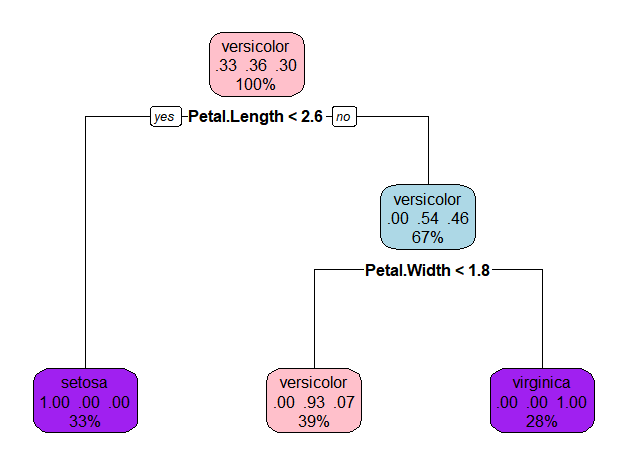
- rpart.plot(model.2)
- n= 105
- node), split, n, loss, yval, (yprob)
- * denotes terminal node
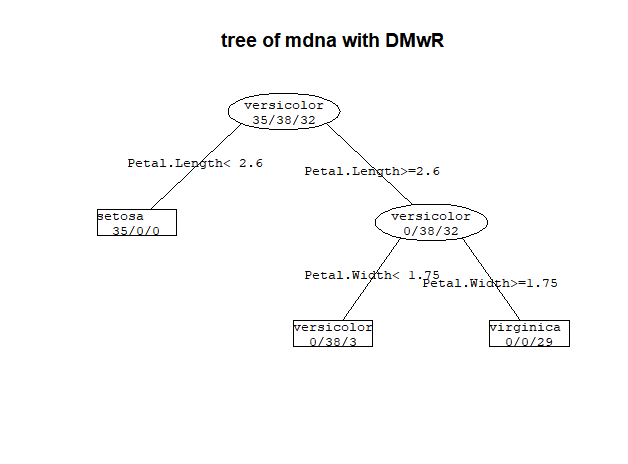
- 1) root 105 67 versicolor (0.33333333 0.36190476 0.30476190)
- 2) Petal.Length< 2.6 35 0 setosa (1.00000000 0.00000000 0.00000000) *
- 3) Petal.Length>=2.6 70 32 versicolor (0.00000000 0.54285714 0.45714286)
- 6) Petal.Width< 1.75 41 3 versicolor (0.00000000 0.92682927 0.07317073) *
- 7) Petal.Width>=1.75 29 0 virginica (0.00000000 0.00000000 1.00000000) *
rpart包提供了复杂度损失修剪的修剪方法,printcp会告诉分裂到每一层,cp是多少,平均相对误差是多少
- printcp(model.2)
- Classification tree:
- rpart(formula = Species ~ ., data = train, method = "class")
- Variables actually used in tree construction:
- [1] Petal.Length Petal.Width
- Root node error: 67/105 = 0.6381
- n= 105
- CP nsplit rel error xerror xstd
- 1 0.52239 0 1.000000 1.268657 0.060056
- 2 0.43284 1 0.477612 0.582090 0.073898
- 3 0.01000 2 0.044776 0.074627 0.032570
#一般使用1-SE法则选出最优cp值:找到xerror最小的行,得到误差阈值为该行的xerror+xstd##找到所有xerror小于这个阈值的行,取其中最大值的上限为prune的阈值
###根据我们的结果,来看最小的交叉验证误差为0.074,刚好是最后一个节点,不需要剪枝
####需要剪枝的案例https://danzhuibing.github.io/r_decision_tree.html
剪枝的代码
- # model.prune <- prune(cfit, cp=0.03)
#cp值为示例
换个颜色
- rpart.plot(model.2, box.col=c("pink", "purple","lightblue"))
这个图也可以用DMwR绘制
- library(DMwR)
- prettyTree(model.2,main='tree of mdna with DMwR')
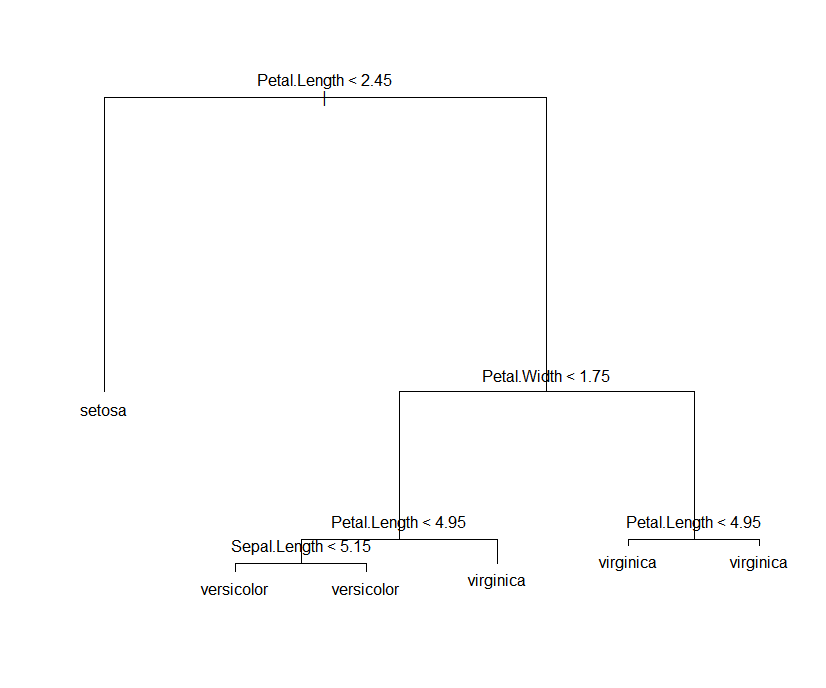
package 'tree'
- library(tree)
- model.3<- tree(Species ~ Sepal.Width +
- Sepal.Length +
- Petal.Length +
- Petal.Width,
- data = iris
- )
- summary(model.3)
- plot(model.3)
- text(model.3)
结果:
- Classification tree:
- tree(formula = Species ~ Sepal.Width + Sepal.Length + Petal.Length +
- Petal.Width, data = iris)
- Variables actually used in tree construction:
- [1] "Petal.Length" "Petal.Width" "Sepal.Length"
- Number of terminal nodes: 6
- Residual mean deviance: 0.1253 = 18.05 / 144
- Misclassification error rate: 0.02667 = 4 / 150
最后使用测试集进行检验,一般使用predict函数
- predict <- predict(model.2,newdata=test,type='class')
- result.2<-table(test$Species,predict)
- sum(diag(result.2))/sum(result.2)
结果是
[1] 0.9333333
即93.3%的准确率
这个矩阵的样子如下,对角线上的值代表预测正确的值,用对角线除以总数,就可以得到正确率了。
- table(test$Species,predict)
- predict
- setosa versicolor virginica
- setosa 15 0 0
- versicolor 0 11 1
- virginica 0 2 16
- 【一般用不到】如果列名不正常,可以使用如下代码apply每行的列名为最大值对应列名
- a <- predict(model.2,newdata=test,type='class')
- b <- apply(a, 1, function(t) colnames(a)[which.max(t)])
R语言学习笔记-单一决策树的更多相关文章
- R语言学习笔记—决策树分类
一.简介 决策树分类算法(decision tree)通过树状结构对具有某特征属性的样本进行分类.其典型算法包括ID3算法.C4.5算法.C5.0算法.CART算法等.每一个决策树包括根节点(root ...
- R语言学习笔记之: 论如何正确把EXCEL文件喂给R处理
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html ---- 前言: 应用背景兼吐槽 继续延续之前每个月至少一次更新博客,归纳总结学习心得好习惯. ...
- R语言学习笔记(二)
今天主要学习了两个统计学的基本概念:峰度和偏度,并且用R语言来描述. > vars<-c("mpg","hp","wt") &g ...
- R语言学习笔记:小试R环境
买了三本R语言的书,同时使用来学习R语言,粗略翻下来感觉第一本最好: <R语言编程艺术>The Art of R Programming <R语言初学者使用>A Beginne ...
- R语言学习笔记:基础知识
1.数据分析金字塔 2.[文件]-[改变工作目录] 3.[程序包]-[设定CRAN镜像] [程序包]-[安装程序包] 4.向量 c() 例:x=c(2,5,8,3,5,9) 例:x=c(1:100) ...
- R语言学习笔记——C#中如何使用R语言setwd()函数
在R语言编译器中,设置当前工作文件夹可以用setwd()函数. > setwd("e://桌面//")> setwd("e:\桌面\")> s ...
- R语言学习笔记-机器学习1-3章
在折腾完爬虫还有一些感兴趣的内容后,我最近在看用R语言进行简单机器学习的知识,主要参考了<机器学习-实用案例解析>这本书. 这本书是目前市面少有的,纯粹以R语言为基础讲解的机器学习知识,书 ...
- R语言学习笔记(一)
1.不同的行业对数据集(即表格)的行和列称谓不同,统计学家称其为观测(observation)和变量(variable): 2.R语言存储数据的结构: ①向量:类似于C语言里的一位数组,执行组合功能的 ...
- R语言学习笔记
向量化的函数 向量化的函数 ifelse/which/where/any/all/cumsum/cumprod/对于矩阵而言,可以使用rowSums/colSums.对于“穷举所有组合问题" ...
随机推荐
- FOFA链接爬虫爬取fofa spider
之前一直是用的github上别人爬取fofa的脚本,前两天用的时候只能爬取第一页的链接了,猜测是fofa修改了一部分规则(或者是我不小心删除了一部分文件导致不能正常运行了) 于是重新写了一下爬取fof ...
- 转载 HTTP协议
转载自:http://www.cnblogs.com/TankXiao/archive/2012/02/13/2342672.html 当今web程序的开发技术真是百家争鸣,ASP.NET, PHP, ...
- 第四篇 Scrum 冲刺博客
一.站立式会议 1. 会议照片 2. 工作汇报 团队成员名称 昨日(25日)完成的工作 今天(26日)计划完成的工作 工作中遇到的困难 陈锐基 - 完善表白墙动态的全局状态管理 - 完成发布页面的布局 ...
- window下kettle安装
参考这篇文章 http://note.youdao.com/noteshare?id=a8c536ba952a48d60d7ea8f2cc61a94b
- AcWing 195. 骑士精神
双向BFS (广搜) \(O(8 ^ 7)\) 看到没有双向BFS的题解我就过来了 这道题也可以用双向\(BFS\)来做,时间复杂度与\(IDA*\)不相上下. 双向\(BFS\)的实现有多种: 把初 ...
- fabric智能合约模板
以创建用户为例,我觉得基本都是这个框架,用特殊功能直接再往上加,欢迎留言交流 func createUser(stub shim.ChaincodeStubInterface, args []stri ...
- JavaSE03-运算符&分支语句
1.运算符 1.1 算术运算符 1.1.1 运算符和表达式 运算符:对常量或者变量进行操作的符号 表达式:用运算符把常量或者变量连接起来符合java语法的式子就可以称为表达式. 不同运算符连接的表达式 ...
- Java 8 Lambda表达式-接口实现
Java 8 Lambda表达式在只有一个方法的接口实现代码编写中,可以起到简化作用: (argument list) -> body 具体看Runnable接口的例子 public class ...
- Python高级语法-私有属性-with上下文管理器(4.7.3)
@ 目录 1.说明 2.代码 关于作者 1.说明 上下文管理器 这里使用with open操作文件,让文件对象实现了自动释放资源.我们也能自定义上下文管理器,通过__enter__()和__exit_ ...
- Python之word文档模板套用 - 真正的模板格式套用
Python之word文档模板套用: 1 ''' 2 #word模板套用2:套用模板 3 ''' 4 5 #导入所需库 6 from docx import Document 7 ''' 8 #另存w ...