calcite 概念和架构
1. 前言
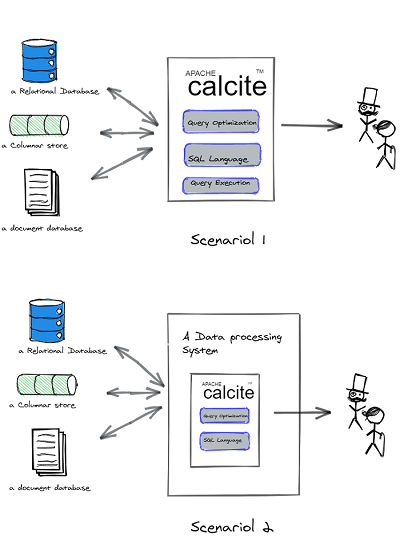
Flink使用Calcite构造SQL引擎,那么他们 是怎么合作的? drill, hive,storm 和其他的一干apache 大数据引擎也用calcite , 那么对于同一个sql 语句(statement) , 无论复杂简单与否,他们和Flink产生的执行计划是不是一样的? 如果不一样, 区别是怎么产生的? 应该在哪里实施优化和发力?优化的手段和原则有那些,等等? 本文不会对calcite 面面做具到的介绍,重点是SQL执行计划的优化框架,流程和策略, 对执行计划进行优化是calcite 的主要业务。为了有助于理解优化框架,对于必要的概念会有介绍, 比如关系,关系代数,关系演算,等价原理,谓词逻辑等。
2. calcite 架构
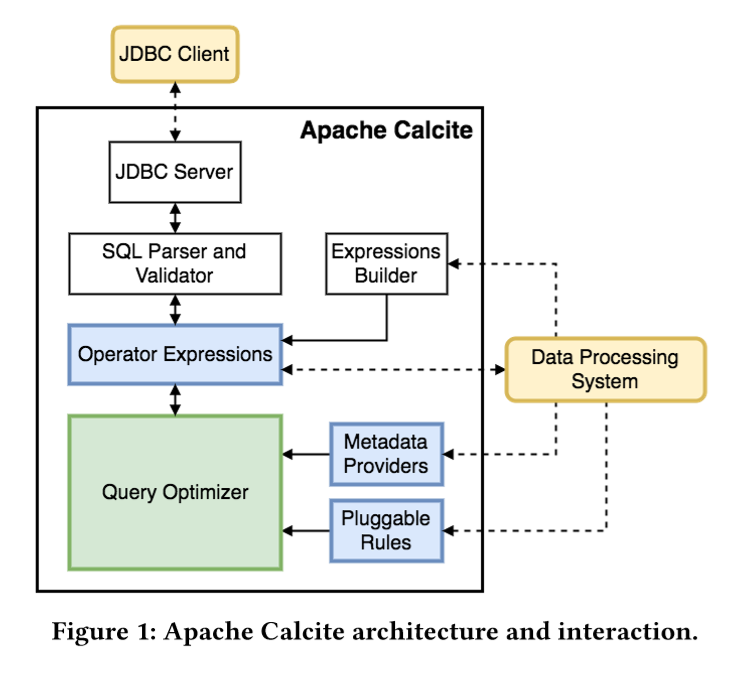

3. 一些关系的概念
Calcite 只支持于关系型数据模型(不支持层次,网状,对象数据库的模型), 那么什么是关系型数据库呢 ? 建议读一下引用5中的那本书 ,虽然我也没读完 。下面解释一下一些比较容易混淆的概念 。
关系:关系一词来自离散数学里的集合论,根据维基百科的的定义,给定任意集合A和B,若 (笛卡尔乘积),则称R为从A到B的二元关系,特别在A=B时,称R为A上的二元关系。如果一个有N列的二维表, 每一列的取值范围为Ai 则该表是定义在A1x..Ai..xAn上的N元关系。可见,关系(Relation)是N元有序序列的集合。关系在数据库的概念里称作表(Table),关系的每一个有序序列叫做元组或行(Row), 元组的每一个量叫分量或列(Column)。
(笛卡尔乘积),则称R为从A到B的二元关系,特别在A=B时,称R为A上的二元关系。如果一个有N列的二维表, 每一列的取值范围为Ai 则该表是定义在A1x..Ai..xAn上的N元关系。可见,关系(Relation)是N元有序序列的集合。关系在数据库的概念里称作表(Table),关系的每一个有序序列叫做元组或行(Row), 元组的每一个量叫分量或列(Column)。
关系模式(Schema):是对关系或表的描述。包括关系名称(Table Name),列名以及列的定义域(Domain)。
关系模型(Model):指的是一系列关系模式的集合, 概念上对应数据库。
维度(Dimension):通常是指列离散定义域的列。定义域上的每一个值称为基(cardinality), 一个关系已经使用的所有的基的个数成为基数 (cardinal number) , 也就是 distinct count , 也成 NDV (Number of Distinct Value) 。
关系代数:是由 Edgar F. Codd提出一种利用具有良好语义的代数结构用于对数据建模和定义查询的理论。代数结构是在一种或多种运算下封闭的一个或多个集合,那么关系代数在闭合关系上的良好语义的运算的集合。通俗的说,关系代数是一种通过由代数运算和输入关系组成的表达式来表达输出关系的理论。 比如 图-3中,SQL 产生的关系可以多个树形的表达式表示,树的形状和节点的排列顺序代表运算的过程(从下到上) 。关系代数是面向过程的。
4. calcite的概念

| 概念 | 解释 | 例子 |
| RelNode | 关系代数中的关系和运算的基类。RelNode 有很多继承者, 见举例。 | TableScan对应一个数据源的一个关系,Filter对应Filter运算 。Filter有一些系列的继承者, 每一个继承者对应一个CallingConvention, 也对应一个优化阶段的使用的数据结构 。 比如Join<-LogicalJoin<-FlinkLocalJoin<-FlinkBatchExecJoin, FlinkExecStreamJoin 。 |
| RelDataType | 代表域,是关系中列的定义域 | 整数,日期,浮点数,定点数,字符串 |
| RexNode | 代表Project里Filter中表达式 | 比如下面关系里一个分量(InputRef),一个常量值(Literal),一个或多个分量函数(RexCall, 加、减、乘、除、CAST 等) |
| RelTrait | 代表关系运算的物理特性,这个应该是calcite 里最让人迷惑的概念了。但Trait, set, subset 是 volcanoPlanner 最依赖的概念。 关系的物理特性是跟关系代数没有关系的一些特性,所以只有跟物理执行系统比较临近的关系运算才会有物理特性,比如FlinkBatchExecFilter 有物理特性, 它是被翻译成FlinkJobGraph的输入计划的节点类型。而LogicalFilter观完全逻辑上的关系观念,因此不会有任何物理特性。 Calcite 有三种类型的特性, 类型叫做TraitDef 。
|
比如Flink中的节点BatchExecJoin在BATCH_PHYSICAL 调用习惯中的运算节点。 |
| AbstractConverter |
当关系表达式的 Convention 发生变化的时候, VolcanoPlanner 会在Relset 里创建Relsubset 代表这种traits, 随后创建AbstractConverter用于转化成真正的表达式。 ExpendConventionRule 配备AbstractConverter, 将它转化成合适的节点, 比如 BroadcastExchange, Sort 等 。 | 参考FlinkExpandConversionRule, calcite: AbstractConverter, Relset.addAbstractConverter。 |
| RelOptRule | 所有的优化规则的基类, 它构造函数第一个参数就是关系运算的类型(比如, Join, Filter 等),(还有一些别的, 不展开了)。当Planner 遍历表达式图的每一个节点时,他会调用匹配这个节点类型的规则 。除了匹配类型,VolcanoPlanner 还会给规则设置优先级,级别高的会别先调用。每一个规则有两个函数: matches() 继续深度判断改规则是否真的应该调用。 onMatch 执行规则实际的动作:根据测量增、减、改变、升级表达式的节点。 优化规则有的会通过元数据提供者查询元数据信息,从而做相应的措施。有的不会。从规则的角度来看,planner 都是无区别的。 所以除了少量的例外(比如前面提到的ExpendConvensionRule),大部分都可以被HepPlanner 和 VocanoPlanner 调用的。 |
例子有很多, 比如有名的谓词下推,子查询替换,join-recorder, 常量替换等。google里搜索一下, 会很多介绍 。 想看全面的, 请参考 org.apache.calcite.rel.rules里面的规则, 或 FlinkBatchRuleSets.scala里面的使用的规则。 |
| RelMetadataProvider RelOptCost |
前文多次提到的统计数据提供者,他是一个能handle不同统计类型数据的handler的集合。比如 RelMdRowCount是提供关系运算产生的rowCount估计, RelMdDistinctRowCount 提供某个列的cardinal number 估计 。RelMdSelectivity 提供关系运算后的rowcount 原来的比例 估计。 RelOptCost是代价模型, calcite 的代价模型是对关系的行数,通常是考虑IO(disk IO + network IO) 和CPU使用率, memory, 和 关系规模(rowcount)的一个综合衡量。 |
Calcite 里有DefaultRelMetadataProvider 提供了各种Handle 缺省计算方法。ReflectiveRelMetadataProvider 由于接受DPS端实现的Provider , 比如 Flink里实现的FlinkDefaultRelMetadataProvider . 还有一个JaninoRelMetadataProvider, 看起来是通过动态编译的生成Provider ? Handler的元数据的估计算法请阅引用5的第13章。 |
| Schema Table Lattice ,Tile |
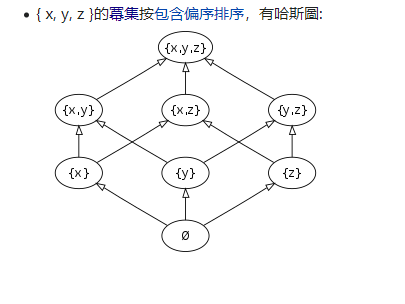
Schema和table的概念全面说过。 Lattice(格) 是除了关系、关系代数之外,另一个来自于数学领域的名词。看起来calcite 是真的很想提升广大数据程序员的数学格调。 格同关系代数一样是一种代数结构(集合+一种二元关系),集合的成员的二元关系是反自反, 和传递的, 而且这个关系有明确的上下界, 则称这种代数结构为格。 很抽象, 可以看引用8中的哈斯图理解 。{ x, y, z }的冪集按包含偏序排序就是一个格。 这个和多维cube聚合计算的物化视图的结构很像。 物化视图里的每一个顶点都是一个tile , 最上面的tile 包含了所有的维度, 最下面的维度为空, 维度集合以及包含关系组成了一个格。 格从上到下是是降维的过程,则低维聚合计算可由高维聚合导出 。所以lattice , Tile 是为 物化视图引入的, 只不过换了一个文艺的名字而已 。 物化视图是一个预计算的结果,物化在硬盘或内存里,如果把查询计划里能够利用物化视图,执行的很定会飞快 。 |
来自引用8 |
| HepVertex HepProgram HepPlanner |
HepVertex是HepProgram里用于组成计划图的顶点。HepProgram 是一些优化规则的集合,HepPlanner 利用HepVertex建立将计划树转化成计划图, 然后利用HepProgram按照一定顺序遍历其中的优化规则。 HepPlanner 调用流程如右侧代码所示。
HepPlanner的寻优 是一个一种贪心的算法,就是当前迭代步会用上一次迭代结果的作为当前最优结果继续优化,如果上一步做错了,下一步也会错下去。只有将迭代运行多次,才有可能避免改正错误。 |
//build program
|
| Relset RelSubset VolcanoProgram ValcanoPlanner |
RelSubset 代表一个目标物理特性, 比如BATCH_PHYSICAL.Broadcast.ANY, 代表一个BATCH_PHYSICAL convention 等价 子计划,行发布方式是广播, 列排序方式为任意。BATCH_PHYSICAL.Hash.ANY,是另为一个subet 。 Relset 是所有具有不同物理特性的等价的RelSubset的集合这些, 比如BATCH_PHYSICAL.Broadcast.[]和 BATCH_PHYSICAL.Hash.[]是等价的。 Relset 还是所有等价关系的集合,比如HashExchange+SortMergeJoin,HashExchange+HashJoin, BroadcastExchange+Hash, ASC sort + SingleExchange+Hash 都是等价关系表达式。 RelSubset 会在从等价关系集合里选择符合自身trait的最便宜的作为他的best 。从上到下的best组成最终的计划图 。 VocanoPlanner 运行流程和HepPlanner类似。
|
5. 优化器流程
HepPlanner 的寻优流程很简单,setRoot重建planGraph, findBestExp 就是按照指定的顺序将HelpProgram里的规则触发一遍。 如果担心有问题贪心算法的问题,可以将这两步多做几次。
VocanoPlanner 的寻优流程如前所述。 TraitSet 通常包含了 Convension, distribution, collation 三个维度 , 这三个维度不同的基的组成的组合(subset)都是等价的但是cost不相等,但并不是代价把最低的subset 输入给上游总代价就会最低的。最低的代价需要综合考把虑上游和下游的情况,寻找最搭配的搭档。所以这个寻优过程需要一个动态规划的方式来求解。在使用动态规划(也就是递归的方法, volcanoPlanner 的命名就来自这里吧 )求解之前, 我们需要把各种可能的计划的每一层的满足需要trait的subset, 以及对应关系求出来。 而满足要求的subset, 而且在考虑到输入的组合,状态转移公式大概如下。
BestExp(subset)) = argmin( cost(rel1 ), cost(rel2), ... )
cost (rel ) = algoCost(rel.self) + cost(BestExp(rel.input1)) + cost(BestExp(rel.input2))
第一行中,rel1, rel2 是满足traits 的等价表达式,表示当前subet的最佳表达式是他们之中里cost最低的表达式。
第二行中, 表示表达式的cost 等于最上层节点自身算法代价估计 和下层输入subset的最佳表达式向上输入的累计的综合代价 。TableScan 的下层输入就是磁盘IO的代价,底层关系的RowCount相关 。这里的加号代表代价计算要综合考虑的因素并不是简单的算数相加 。比如hashJion和sortMergeJoin自身算法的代价不一样(CPU, 内存代价), join的两路输入方式不同代价不一样(IO代价)。
SELECT * from store_sales join date_dim on store_sales.ss_sold_date_sk = date_dim.d_date_sk and date_dim.d_year=2002
1 |
这个表达式里主要有一个HashJoin 和两个TableScan 组成, 如果对HashJoin 的 requriedTraits 是 BATCH_PHYSICAL.ANY.[], HashJoin 对store_sales 和 date_dim的要求分别是BATCH_PYSICAL.forward.[] 和 BATCH_PYSICAL.broadcast.[], 那么上面的公式以下的形式 。
BestExp(join.BATCH_PHYSICAL.ANY.[]) = argmin( cost(shuffledHashjoin), cost(broadcastHashJoin), cost(shuffledSortMergeJoin),... )
cost(broadcastHashJoin)= cost(BestExp(tablenscan_store_sales.BATCH_PHYSICAL.forward.[])) + cost(BestExp(tablenscan_date_dim.BATCH_PHYSICAL.broadcast.[])) + algoCost(HashJoin)

画个图表示一下 relSet, relSubset, 和besExp 还有trait之间的关系吧, 还有这个类似火山喷发的形状。
7. 引用
| 序号 | 描述 | 链接 |
| 1 | Calcite 论文 | dl.acm.org/doi/10.1145/3183713.3190662 |
| 2 | Calcite 官方文档 | calcite.apache.org/docs/ |
| 3 | 关系代数 | en.wikipedia.org/wiki/Relational_algebra |
| 4 | 关系演算 | https://en.wikipedia.org/wiki/Relational_calculus |
| 5 | 数据库系统概念第6版 Abraham Silberschatz 等著 | |
| 6 | 官渡之战 | https://zh.wikipedia.org/wiki/%E5%AE%98%E6%B8%A1%E4%B9%8B%E6%88%98 |
| 7 | SQL on everything, in memory by Julian Hyde | www.slideshare.net/julianhyde/calcite-stratany2014 |
| 8 | 哈斯图 | zh.wikipedia.org/wiki/%E5%93%88%E6%96%AF%E5%9C%96 |
calcite 概念和架构的更多相关文章
- Windows打印体系结构之Print Spooler概念与架构
Windows打印体系结构之Print Spooler概念与架构Windows 思杰之路(陶菘) · 2016-09-06 22:07 房子好不好,对我而言始终都是肉体的栖居.对于灵魂,我从来不知道该 ...
- Impala概念与架构
Impala概念与架构 下面的内容介绍Cloudera Impala的背景资料及特性,以便你更高效的使用它.Where appropriate, the explanations include co ...
- 【阅读笔记】rocketmq 概念与架构 (一)
介绍 rocketmq 框架与基本概念 1. 概念 1.1 namesrv(name server) 记录了 broker 集群信息,消息队列的信息以及 key-value 配置,见 RouteInf ...
- MySQL 主从复制与读写分离概念及架构分析
1.MySQL主从复制入门 首先,我们看一个图: 影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中. 假设,实时的将变化了的日志系统中的数据库事件操作,在MYSQL-A的33 ...
- [转载] 对象存储(2):OpenStack Swift——概念、架构与规模部署
原文: http://www.testlab.com.cn/Index/article/id/1085.html#rd?sukey=fc78a68049a14bb228cb2742bdec2b9498 ...
- MySQL 主从复制与读写分离概念及架构分析 (转)
1.MySQL主从复制入门 首先,我们看一个图: 影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中. 假设,实时的将变化了的日志系统中的数据库事件操作,在MYSQL-A的33 ...
- Kubernetes学习之路(一)之概念和架构解析和证书创建和分发
1.Kubernetes的重要概念 转自:CloudMan老师公众号<每天5分钟玩转Kubernetes>https://item.jd.com/26225745440.html Clus ...
- Druid.io系列(二):基本概念与架构
原文链接: https://blog.csdn.net/njpjsoftdev/article/details/52955788 在介绍Druid架构之前,我们先结合有关OLAP的基本原理来理解Dr ...
- MySQL主从复制与读写分离概念及架构分析
1.MySQL主从复制入门 首先,我们看一个图: 影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中. 假设,实时的将变化了的日志系统中的数据库事件操作,在MYSQL-A的33 ...
随机推荐
- Codeforces Round #645 (Div. 2) D. The Best Vacation (贪心,二分)
题意:一年有\(n\)个月,每月有\(d_{i}\)天,找出连续的\(x\)天,使得这\(x\)天的日期总和最大,任意一年都能选. 题解:首先要先贪心,得到:连续的\(x\)天的最后一天一定是某个月的 ...
- 获取csc.exe路径
using System.Runtime.InteropServices; var frameworkPath = RuntimeEnvironment.GetRuntimeDirectory(); ...
- Leetcode(25)- k个一组翻转链表
给出一个链表,每 k 个节点一组进行翻转,并返回翻转后的链表. k 是一个正整数,它的值小于或等于链表的长度.如果节点总数不是 k 的整数倍,那么将最后剩余节点保持原有顺序. 示例 : 给定这个链表: ...
- P2P协议初步
今天看到一个问题,如何把一个文件快速下发到100w个服务器 如果我们将文件集中式地放在一个服务器或缓存上的话,带宽.连接都会遇到问题. 树状: 1. 每个服务器既具有文件存储能力也应具有 ...
- HDU 6611 K Subsequence(Dijkstra优化费用流 模板)题解
题意: 有\(n\)个数\(a_1\cdots a_n\),现要你给出\(k\)个不相交的非降子序列,使得和最大. 思路: 费用流建图,每个点拆点,费用为\(-a[i]\),然后和源点连边,和后面非降 ...
- 1 line of CSS Layouts
1 line of CSS Layouts 10 modern layouts in 1 line of CSS 1. 绝对居中布局 <div class="container&quo ...
- 如何在Python 中使用UTF-8 编码 && Python 使用 注释,Python ,UTF-8 编码 , Python 注释
如何在Python 中使用UTF-8 编码 && Python 使用 注释,Python ,UTF-8 编码 , Python 注释 PIP $ pip install beauti ...
- Virtual Reality In Action
Virtual Reality In Action VR WebXR immersive 沉浸式 https://github.com/immersive-web/webxr https://imme ...
- js logical operation all in one
js logical operation all in one 逻辑运算 Logical AND (&&) Logical AND assignment (&&=) L ...
- HTTP cache in depth
HTTP cache in depth HTTP 缓存 https://developers.google.com/web/fundamentals/performance/optimizing-co ...