阅读源码,HashMap回顾
本文一是总结前面两种集合,补充一些遗漏,再者对HashMap进行简单介绍。
回顾
因为前两篇ArrayList和LinkedList都是针对单独的集合类分析的,只见树木未见森林,今天分析HashMap,可以结合起来看一下java中的集合框架。下图只是一小部分,而且为了方便理解去除了抽象类。
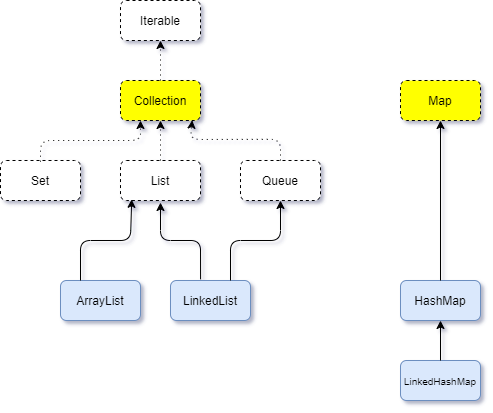
Java中的集合(有时也称为容器)是为了存储对象,而且多数时候存储的不止一个对象。
可以简单的将Java集合分为两类:
一类是Collection,存储的是独立的元素,也就是单个对象。细分之下,常见的有List,Set,Queue。其中List保证按照插入的顺序存储元素。Set不能有重复元素。Queue按照队列的规则来存取元素,一般情况下是“先进先出”。
一类是Map,存储的是“键值对”,通过键来查找值。比如现实中通过姓名查找电话号码,通过身份证号查找个人详细信息等。
理论上说我们完全可以只用Collection体系,比如将键值对封装成对象存入Collection的实现类,之所以提出Map,最主要的原因是效率。
HashMap简介
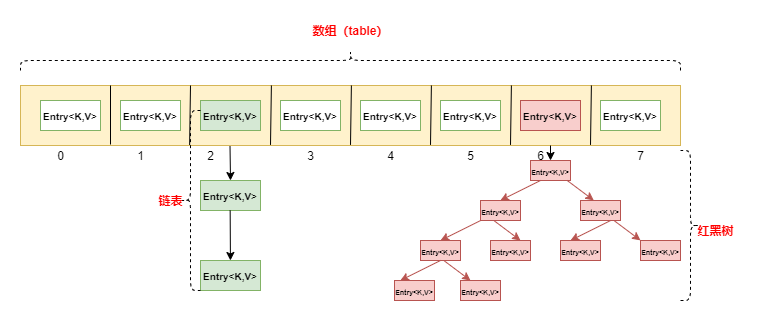
HashMap用来存储键值对,也就是一次存储两个元素。在jdk1.8中,其实现是基于数组+链表+红黑树,简单说就是普通情况直接用数组,发生哈希冲突时在冲突位置改为链表,当链表超过一定长度时,改为红黑树。
可以简单理解为:在数组中存放链表或者红黑树。
- 完全没有哈希冲突时,数组每个元素是一个容量为1的链表。如索引0和1上的元素。
- 发生较小哈希冲突时,数组每个元素是一个包含多个元素的链表。如索引2上的元素。
- 当冲突数量超过8时,数组每个元素是一棵红黑树。如索引6上的元素。
下图为示意图,相关结构没有严格遵循规范。
类签名
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
如下图
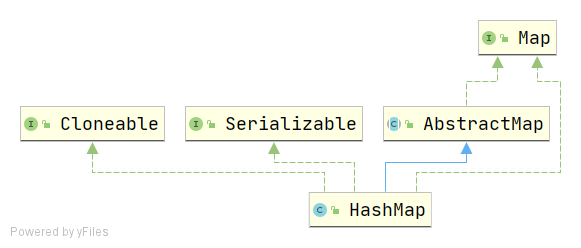
实现Cloneable和Serializable接口,拥有克隆和序列化的能力。
HashMap继承抽象类AbstractMap的同时又实现Map接口的原因同样见上一篇LinkedList。
常量
//序列化版本号
private static final long serialVersionUID = 362498820763181265L;
//默认初始化容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量,2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认负载因子,值为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//以下三个常量应结合看
//链表转为树的阈值
static final int TREEIFY_THRESHOLD = 8;
//树转为链表的阈值,小于6时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
//链表转树时的集合最小容量。只有总容量大于64,且发生冲突的链表大于8才转换为树。
static final int MIN_TREEIFY_CAPACITY = 64;
上述变量的关键在于链表转树和树转链表的时机,综合看:
- 当数组的容量小于64是,此时不管冲突数量多少,都不树化,而是选择扩容。
- 当数组的容量大于等于64时,
- 冲突数量大于8,则进行树化。
- 当红黑树中元素数量小于6时,将树转为链表。
变量
//存储节点的数组,始终为2的幂
transient Node<K,V>[] table;
//批量存入时使用,详见对应构造函数
transient Set<Map.Entry<K,V>> entrySet;
//实际存放键值对的个数
transient int size;
//修改map的次数,便于快速失败
transient int modCount;
//扩容时的临界值,本质是capacity * load factor
int threshold;
//负载因子
final float loadFactor;
数组中存储的节点类型,可以看出,除了K和Value外,还包含了指向下一个节点的引用,正如一开始说的,节点实际是一个单向链表。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//...省略常见方法
}
构造方法
常见的无参构造和一个参数的构造很简单,直接传值,此处省略。看一下两个参数的构造方法。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: "+initialCapacity);
//指定容量不能超过最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//将给定容量转换为不小于其自身的2的幂
this.threshold = tableSizeFor(initialCapacity);
}
tableSizeFor方法
上述方法中有一个非常巧妙的方法tableSizeFor,它将给定的数值转换为不小于自身的最小的2的整数幂。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
比如cap=10,转换为16;cap=32,则结果还是32。用了位运算,保证效率。
有一个问题,为啥非要把容量转换为2的幂?之前讲到的ArrayList为啥就不需要呢?其实关键在于hash,更准确的说是转换为2的幂,一定程度上减小了哈希冲突。
关于这些运算,画个草图很好理解,关键在于能够想到这个方法很牛啊。解释的话配图太多,这里篇幅限制,将内容放在另一篇文章。
添加元素
在上面构造方法中,我们没有看到初始化数组也就是Node<K,V>[] table的情况,这一步骤放在了添加元素put时进行。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
可以看出put调用的是putVal方法。
putVal方法
在此之前回顾一下HashMap的构成,数组+链表+红黑树。数组对应位置为空,存入数组,不为空,存入链表,链表超载,转换为红黑树。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//数组为空,则扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据key计算hash值得出数组中的位置i,位置i上为空,直接添加。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//数组对应位置不为空
else {
Node<K,V> e;
K k;
//对应节点key上的key存在,直接覆盖value
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//为红黑树时
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//为链表时
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//下次添加前需不需要扩容,若容量已满则提前扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
resize()方法比较复杂,最好是配合IDE工具,debug一下,比较容易弄清楚扩容的方式和时机,如果干讲的话反而容易混淆。
获取元素
根据键获取对应的值,内部调用getNode方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
getNode方法
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;
Node<K,V> first,
e; int n;
K k;
//数组不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//第一个节点满足则直接返回对应值
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//红黑树中查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
//链表中查找
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
总结
HashMap的内容太多,每个内容相关的知识点也很多,篇幅和个人能力限制,很难讲清所有内容,比如最基础的获取hash值的方法,其实也很讲究的。有机会再针对具体的细节慢慢详细写吧。
阅读源码,HashMap回顾的更多相关文章
- 阅读源码(III)
往期系列: <由阅读源码想到> <由阅读源码想到 | 下篇> Medium上有一篇文章Why You Don't Deserve That Dream Developer Jo ...
- 阅读源码(IV)
往期系列: <由阅读源码想到> <由阅读源码想到 | 下篇> <阅读源码(III)> Eric S.Raymond的写于2014年的<How to learn ...
- JDK1.8源码分析02之阅读源码顺序
序言:阅读JDK源码应该从何开始,有计划,有步骤的深入学习呢? 下面就分享一篇比较好的学习源码顺序的文章,给了我们再阅读源码时,一个指导性的标志,而不会迷失方向. 很多java开发的小伙伴都会阅读jd ...
- 学会阅读源码后,我觉得自己better了
我有一个大学同学,名叫石磊,我在之前的文章里提到过几次,我们俩合作过很多项目.只要有他在,我就特别放心,因为几乎所有难搞的问题,到他这,都能够巧妙地化解.他给我印象最深刻的一句话就是,"有啥 ...
- 阅读源码,从ArrayList开始
前言 为啥要阅读源码?一句话,为了写出更好的程序. 一方面,只有了解了代码的执行过程,我们才能更好的使用别人提供的工具和框架,写出高效的程序.另一方面,一些经典的代码背后蕴藏的思想和技巧很值得学习,通 ...
- 【转】使用 vim + ctags + cscope + taglist 阅读源码
原文网址:http://my.oschina.net/u/554995/blog/59927 最近,准备跟学长一起往 linux kernel 的门里瞧瞧里面的世界,虽然我们知道门就在那,但我们还得找 ...
- Spring源码解析——如何阅读源码(转)
最近没什么实质性的工作,正好有点时间,就想学学别人的代码.也看过一点源码,算是有了点阅读的经验,于是下定决心看下spring这种大型的项目的源码,学学它的设计思想. 手码不易,转载请注明:xingoo ...
- Spring源码解析——如何阅读源码
最近没什么实质性的工作,正好有点时间,就想学学别人的代码.也看过一点源码,算是有了点阅读的经验,于是下定决心看下spring这种大型的项目的源码,学学它的设计思想. 手码不易,转载请注明:xingoo ...
- How Tomcat works — 一、怎样阅读源码
在编程的道路上,通过阅读优秀的代码来提升自己是很好的办法.一直想阅读一些开源项目,可是没有合适的机会开始.最近做项目的时候用到了shiro,需要做集群的session共享,经过查找发现tomcat的s ...
- 使用 vim + ctags + cscope + taglist 阅读源码
转自:http://my.oschina.net/u/554995/blog/59927 最近,准备跟学长一起往 linux kernel 的门里瞧瞧里面的世界,虽然我们知道门就在那,但我们还得找到合 ...
随机推荐
- 【noi 2.6_8786】方格取数(DP)
题意:N*N的方格图每格有一个数值,要求从左上角每步往右或往下走到右下角,问走2次的最大和. 解法:走一次的很好想,而走2次,不可误以为先找到最大和的路,再找剩下的最大和的路就是正解.而应该认清动态规 ...
- Codeforces Round #570 (Div. 3) B. Equalize Prices、C. Computer Game、D. Candy Box (easy version)、E. Subsequences (easy version)
B题题意: 给你n个物品的价格,你需要找出来一个值b,使得每一个物品与这个b的差值的绝对值小于k.找到最大的b输出,如果找不到,那就输出-1 题解: 很简单嘛,找到上下限直接二分.下限就是所有物品中最 ...
- Codeforces Round #672 (Div. 2 B. Rock and Lever (位运算)
题意:给你一组数,求有多少对\((i,j)\),使得\(a_{i}\)&\(a_{j}\ge a_{i}\ xor\ a_{j}\). 题解:对于任意两个数的二进制来说,他们的最高位要么相同要 ...
- Codeforces Beta Round #92 (Div. 2 Only) B. Permutations
You are given n k-digit integers. You have to rearrange the digits in the integers so that the diffe ...
- .net core面试题
第1题,什么是ASP net core? 首先ASP net core不是 asp net的升级版本.它遵循了dot net的标准架构, 可以运行于多个操作系统上.它更快,更容易配置,更加模块化,可扩 ...
- 📚C#/.NET/.NET Core推荐学习书籍(升职加薪,你值得拥有)
前言: 作为一名程序员,我们无时无刻都要考虑着如何通过不断地学习来提升自己的核心竞争力.古人有云:"书中自有黄金屋,书中只有颜如玉",说明了书籍的重要性,没错工作多年来,发现身边那 ...
- SPI/QSPI通信协议详解和应用
SPi是高速全双工的串行总线,通常应用在通讯速率较高的场合. SS:从设备选择信号线,也称片选信号线 每个从设备都有一个独立的SS信号线,信号线独占主机的一个引脚,及有多少个从设备就有多少个片选信号线 ...
- 手撕 part1
1.宏定义三个数最大值 挺有意思 max((a), (b), (c)) (a) > (b)? ((a) > (c)? (a) : (c)) ((b) > (c)? (b) : (c) ...
- JavaScript调试技巧之console.log()
与alert()函数类似,console.log()也可以接受变量并将其与别的字符串进行拼接: 代码如下: //Use variable var name = "Bob"; con ...
- 2019牛客多校第二场F Partition problem(暴搜)题解
题意:把2n个人分成相同两组,分完之后的价值是val(i, j),其中i属于组1, j属于组2,已知val表,n <= 14 思路:直接dfs暴力分组,新加的价值为当前新加的人与不同组所有人的价 ...