Kafka内部实现原理
Kafka是什么
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于 2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
Kafk内部实现原理

(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
Kafka架构
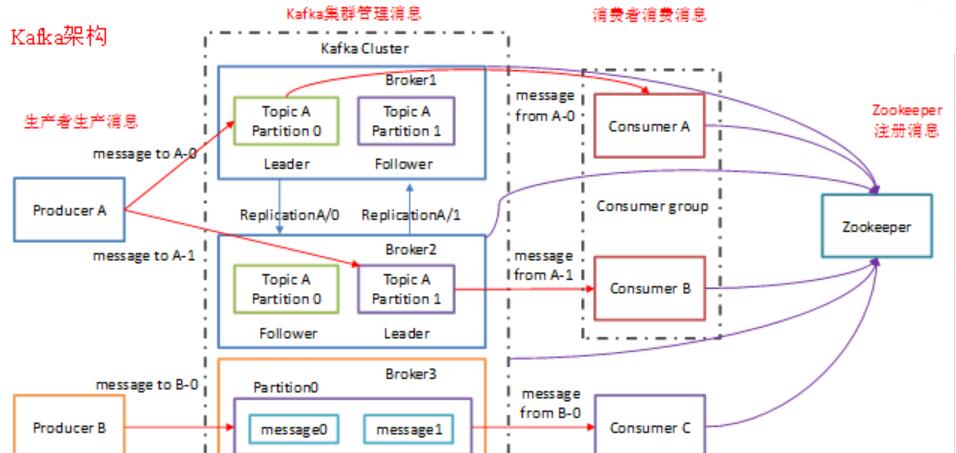
1)Producer :消息生产者,就是向kafka broker发消息的客户端。
2)Consumer :消息消费者,向kafka broker取消息的客户端
3)Topic :可以理解为一个队列。
4) Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制-给consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
7)Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
Kafka分布式模型
Kafka每个主题的多个分区日志分布式地存储在Kafka集群上,同时为了故障容错,每个分区都会以副本的方式复制到多个消息代理节点上。其中一个节点会作为主副本(Leader),其他节点作为备份副本(Follower,也叫作从副本)。主副本会负责所有的客户端读写操作,备份副本仅仅从主副本同步数据。当主副本出现故障时,备份副本中的一个副本会被选择为新的主副本。因为每个分区的副本中只有主副本接受读写,所以每个服务器端都会作为某些分区的主副本,以及另外一些分区的备份副本,这样Kafka集群的所有服务端整体上对客户端是负载均衡的。
Kafka的生产者和消费者相对于服务器端而言都是客户端。
Kafka生产者客户端发布消息到服务端的指定主题,会指定消息所属的分区。生产者发布消息时根据消息是否有键,采用不同的分区策略。消息没有键时,通过轮询方式进行客户端负载均衡;消息有键时,根据分区语义(例如hash)确保相同键的消息总是发送到同一分区。
Kafka的消费者通过订阅主题来消费消息,并且每个消费者都会设置一个消费组名称。因为生产者发布到主题的每一条消息都只会发送给消费者组的一个消费者。所以,如果要实现传统消息系统的“队列”模型,可以让每个消费者都拥有相同的消费组名称,这样消息就会负责均衡到所有的消费者;如果要实现“发布-订阅”模型,则每个消费者的消费者组名称都不相同,这样每条消息就会广播给所有的消费者。
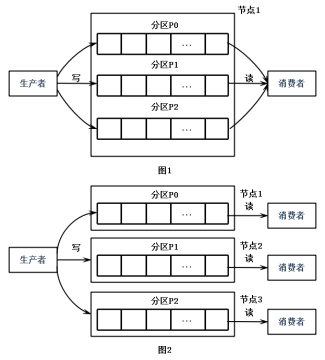
分区是消费者现场模型的最小并行单位。如下图(图1)所示,生产者发布消息到一台服务器的3个分区时,只有一个消费者消费所有的3个分区。在下图(图2)中,3个分区分布在3台服务器上,同时有3个消费者分别消费不同的分区。假设每个服务器的吞吐量时300MB,在下图(图1)中分摊到每个分区只有100MB,而在下图(图2)中,集群整体的吞吐量有900MB。可以看到,增加服务器节点会提升集群的性能,增加消费者数量会提升处理性能。
同一个消费组下多个消费者互相协调消费工作,Kafka会将所有的分区平均地分配给所有的消费者实例,这样每个消费者都可以分配到数量均等的分区。Kafka的消费组管理协议会动态地维护消费组的成员列表,当一个新消费者加入消费者组,或者有消费者离开消费组,都会触发再平衡操作。
Kafka的消费者消费消息时,只保证在一个分区内的消息的完全有序性,并不保证同一个主题汇中多个分区的消息顺序。而且,消费者读取一个分区消息的顺序和生产者写入到这个分区的顺序是一致的。比如,生产者写入“hello”和“Kafka”两条消息到分区P1,则消费者读取到的顺序也一定是“hello”和“Kafka”。如果业务上需要保证所有消息完全一致,只能通过设置一个分区完成,但这种做法的缺点是最多只能有一个消费者进行消费。一般来说,只需要保证每个分区的有序性,再对消息假设键来保证相同键的所有消息落入同一分区,就可以满足绝大多数的应用。
Kafka内部实现原理的更多相关文章
- kafka集群原理介绍
目录 kafka集群原理介绍 (一)基础理论 二.配置文件 三.错误处理 kafka集群原理介绍 @(博客文章)[kafka|大数据] 本系统文章共三篇,分别为 1.kafka集群原理介绍了以下几个方 ...
- Kafka 的这些原理你知道吗
如果只是为了开发 Kafka 应用程序,或者只是在生产环境使用 Kafka,那么了解 Kafka 的内部工作原理不是必须的.不过,了解 Kafka 的内部工作原理有助于理解 Kafka 的行为,也利用 ...
- Kafka 的这些原理你懂吗
如果只是为了开发 Kafka 应用程序,或者只是在生产环境使用 Kafka,那么了解 Kafka 的内部工作原理不是必须的.不过,了解 Kafka 的内部工作原理有助于理解 Kafka 的行为,也利用 ...
- Mininet的内部实现原理简介
原文发表在我的博客主页,转载请注明出处. 前言 之前模拟仿真网络一直用的是Mininet,包括写了一些关于Mininet安装,和真实网络相连接,Mininet简历拓扑的博客,但是大多数都是局限于具体步 ...
- KVO内部实现原理
KVO的原理: 只要给一个对象注册一个监听, 那么在运行时, 系统就会自动给该对象生成一个子类对象, (格式如:NSKVONotifying_className), 并且重写自动生成的子类对象的被监听 ...
- Angular单页应用&AngularJS内部实现原理
回顾 自定义指令 登录后获取登录信息session 首先在登录验证的时候保存一个user 在学生管理页面中运用ajax调用获取到登录的用户信息 对注销按钮添加点击事件:调用ajax在表现层给user赋 ...
- 8. 理解ZooKeeper的内部工作原理
到目前为止,我们已经讨论了ZooKeeper服务的基础知识,并详细了解了数据模型及其属性. 我们也熟悉了ZooKeeper 监视(watch)的概念,监视就是在ZooKeeper命名空间中的znode ...
- kafka知识体系-kafka设计和原理分析
kafka设计和原理分析 kafka在1.0版本以前,官方主要定义为分布式多分区多副本的消息队列,而1.0后定义为分布式流处理平台,就是说处理传递消息外,kafka还能进行流式计算,类似Strom和S ...
- Redis有序集内部实现原理分析(二)
Redis技术交流群481804090 Redis:https://github.com/zwjlpeng/Redis_Deep_Read 本篇博文紧随上篇Redis有序集内部实现原理分析,在这篇博文 ...
随机推荐
- .NET CORE HttpClient使用
自从HttpClient诞生依赖,它的使用方式一直备受争议,framework版本时代产生过相当多经典的错误使用案例,包括Tcp链接耗尽.DNS更改无感知等问题.有兴趣的同学自行查找研究.在.NETC ...
- 牛客IOI周赛17-提高组 卷积 生成函数 多项式求逆 数列通项公式
LINK:卷积 思考的时候 非常的片面 导致这道题没有推出来. 虽然想到了设生成函数 G(x)表示最后的答案的普通型生成函数 不过忘了化简 GG. 容易推出 \(G(x)=\frac{F(x)}{1- ...
- Golang | Go语言多态的实现与interface使用
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是golang专题的第11篇文章,我们一起来聊聊golang当中多态的这个话题. 如果大家系统的学过C++.Java等语言以及面向对象的 ...
- angular2+ 组件间通信
angular2+ 不同于react的redux,vue的vuex,angular2+其实可实现数据状态管理的方法很多,以下方案一般也足够支撑普通业务: 父子组件通信 1.1 父组件向子组件传递信息( ...
- 利用python进行数据分析PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:hi2j 内容简介 [名人推荐] "科学计算和数据分析社区已经等待这本书很多年了:大量具体的实践建议,以及大量综合应用方法.本书在未来几年里肯定会成为Python领域中技术计 ...
- three.js 着色器材质基础(一)
说起three.js,着色器材质总是绕不过的话题,今天郭先生就说一说什么是着色器材质.着色器材质是很需要灵感和数学知识的,可以用简短的代码和绘制出十分丰富的图像,可以说着色器材质是脱离three.js ...
- Qt数据库 QSqlTableModel实例操作(转)
本文介绍的是Qt数据库 QSqlTableModel实例操作,详细操作请先来看内容.与上篇内容衔接着,不顾本文也有关于上篇内容的链接. Qt数据库 QSqlTableModel实例操作是本文所介绍的内 ...
- jQuery 选择器笔记
jquery基础选择器 $('选择器') 基本上与css选择器相同 demo $('ul li') $('.nav') $('#box') 隐试迭代 遍历内 ...
- ConHost.exe机制
- 图计算实现ID_Mapping、Oneid打通数据孤岛
图计算实现ID_Mapping.Oneid打通数据孤岛 ID_Mapping与Oneid的作用 大神告诉我们Oneid能用来做什么 输入数据源格式样例 实现原理 当日代码生成 引用jar包 启动命令 ...