k8s集群调度方案
Scheduler是k8s集群的调度器,主要的任务是把定义好的pod分配到集群节点上
有以下特征:
1 公平 保证每一个节点都能被合理分配资源或者能被分配资源
2 资源高效利用 集群所有资源最大化被利用
3 效率 调度的性能好,能够对大批量pod进行调度
4 灵活 允许用户根据自己的需求控制调取的逻辑
工作原理:
Scheduler是单独运行的程序,启动之后会一直连接API Server,获取值:PodSpec.NodeName为空的pod,也就是对没有标记namespace的pod都会创建一个binding,表明该pod放到哪个节点上。
首先过滤掉不满足条件的节点,这个过程称为:predicate
再通过节点按照优先级排序,这个称为:priority
最后选择优先级最好的节点
若这个期间有一步出错,直接返回错误。若在predicate过程中没有合适的节点,pod会一直处于pending状态,不断重试调度,直到有节点满足为止。如果有多个节点满足条件,就继续priority过程,选择最优node节点
调度过程中,会有一些因素影响调度
1.资源限制
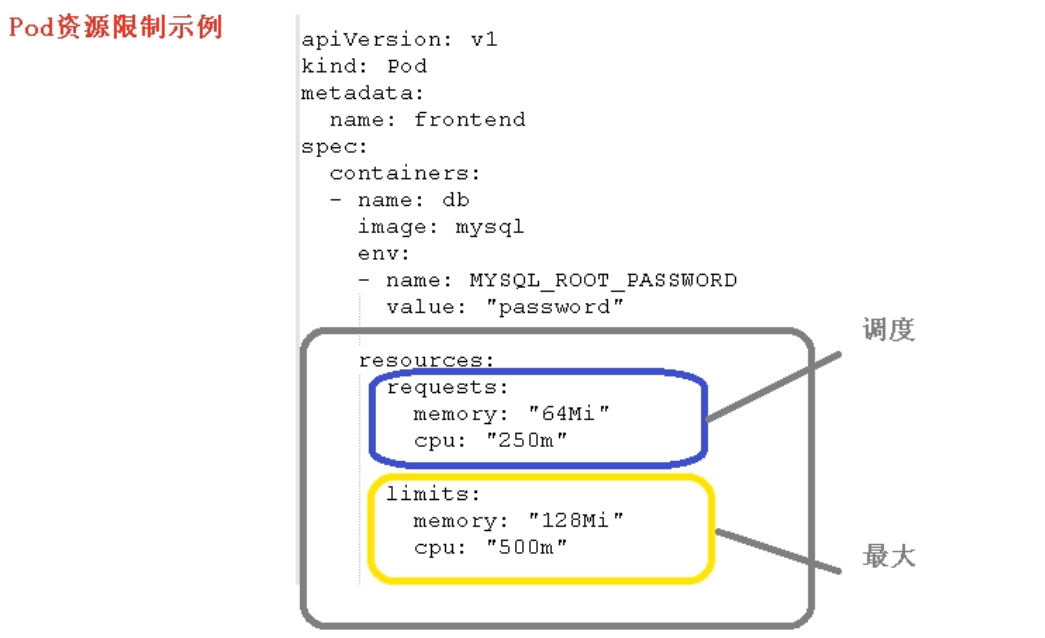
2.节点选择器标签

给node添加标签
[root@k8s-master gisserver]# kubectl label node k8s-node1 node1=iserver
node/k8s-node1 labeled
[root@k8s-master gisserver]# kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready master 22d v1.17.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/master=
k8s-node1 Ready <none> 22d v1.17.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux,node1=iserver
k8s-node2 Ready <none> 22d v1.17.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node2,kubernetes.io/os=linux,node2=gisserver
查看一个指定node标签
[root@k8s-master gisserver]# kubectl get node -l "node1=iserver"
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 22d v1.17.3
删除一个node的标签
[root@k8s-master gisserver]# kubectl label node k8s-node1 node1-
node/k8s-node1 labeled
[root@k8s-master gisserver]# kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready master 22d v1.17.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/master=
k8s-node1 Ready <none> 22d v1.17.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux
k8s-node2 Ready <none> 22d v1.17.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node2,kubernetes.io/os=linux,node2=gisserver
3. 节点的亲和性

4.污点和污点容忍
查看污点
[root@k8s-master gisserver]# kubectl describe node k8s-node1 |grep Taints
Taints: <none>
[root@k8s-master gisserver]# kubectl describe node k8s-node2 |grep Taints
Taints: <none>
[root@k8s-master gisserver]# kubectl describe node k8s-master |grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule
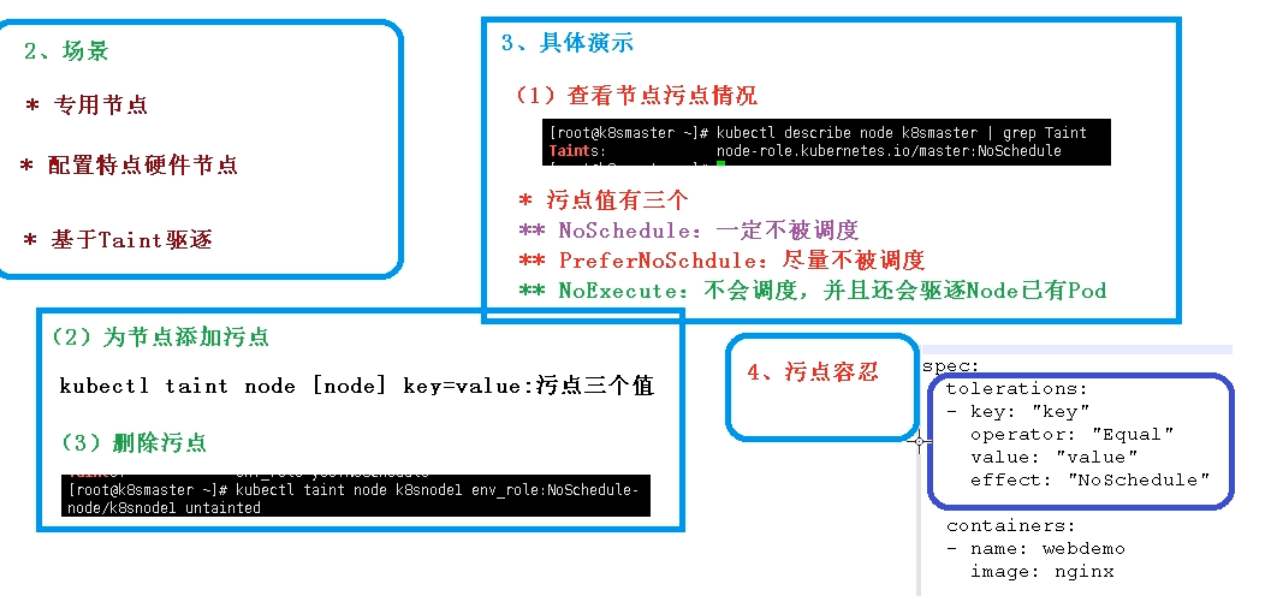
添加节点污点:
[root@k8s-master gisserver]# kubectl taint node k8s-node1 node1=yes:NoSchedule
node/k8s-node1 tainted
[root@k8s-master gisserver]# kubectl describe node k8s-node1 |grep Taints
Taints: node1=yes:NoSchedule
删除污点:
[root@k8s-master gisserver]# kubectl taint node k8s-node1 node1=yes:NoSchedule-
node/k8s-node1 untainted
[root@k8s-master gisserver]# kubectl describe node k8s-node1 |grep Taints
Taints: <none>
污点容忍与软亲和性类似
k8s集群调度方案的更多相关文章
- 高可用的K8S集群部署方案
涉及到的内容 LVS HAProxy Harbor etcd Kubernetes (Master Worker) 整体拓补图 以上是最小生产可用的整体拓补图(相关节点根据需要进行增加,但不能减少) ...
- 十五,K8S集群调度原理及调度策略
目录 k8s调度器Scheduler Scheduler工作原理 请求及Scheduler调度步骤: k8s的调用工作方式 常用预选策略 常用优先函数 节点亲和性调度 节点硬亲和性 节点软亲和性 Po ...
- 详解k8s原生的集群监控方案(Heapster+InfluxDB+Grafana) - kubernetes
1.浅析监控方案 heapster是一个监控计算.存储.网络等集群资源的工具,以k8s内置的cAdvisor作为数据源收集集群信息,并汇总出有价值的性能数据(Metrics):cpu.内存.netwo ...
- k8s学习-集群调度
4.7.集群调度 4.7.1.说明 简介 Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上.听起来非常简单,但有很多要考虑的问题: 公平:如何保 ...
- k8s集群StatefulSets的Pod调度查询丢失问题?
k8s集群StatefulSets的Pod调度查询丢失问题? 考点之简单介绍下StatefulSets 和 Deployment 之间有什么本质区别?特定场景该如何做出选择呢? 考点之你能辩证的说说看 ...
- k8s重要概念及部署k8s集群(一)--技术流ken
重要概念 1. cluster cluster是 计算.存储和网络资源的集合,k8s利用这些资源运行各种基于容器的应用. 2.master master是cluster的大脑,他的主要职责是调度,即决 ...
- 备战双 11!蚂蚁金服万级规模 K8s 集群管理系统如何设计?
作者 | 蚂蚁金服技术专家 沧漠 关注『阿里巴巴云原生』公众号,回复关键词"1024",可获取本文 PPT. 前言 Kubernetes 以其超前的设计理念和优秀的技术架构,在容器 ...
- K8s 集群节点在线率达到 99.9% 以上,扩容效率提升 50%,我们做了这 3 个深度改造
点击下载<不一样的 双11 技术:阿里巴巴经济体云原生实践> 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击上方图片即可下载! 作者 | 张振(守辰) ...
- [转帖]当 K8s 集群达到万级规模,阿里巴巴如何解决系统各组件性能问题?
改天学习一下. https://www.cnblogs.com/alisystemsoftware/p/11570806.html 当 K8s 集群达到万级规模,阿里巴巴如何解决系统各组件性能问题 ...
随机推荐
- delphi DBgrid应用全书
在一个Dbgrid中显示多数据库 在数据库编程中,不必要也不可能将应用程序操作的所有数据库字段放入一个数据库文件中.正确的数据库结构应是:将数据库字段放入多个数据库文件,相关的数据库都包含一个唯 ...
- warning: #1295-D: Deprecated declaration LED_Init - give arg types警告的解决办法
- Java I/O流 复制文件速度对比
Java I/O流 复制文件速度对比 首先来说明如何使用Java的IO流实现文件的复制: 第一步肯定是要获取文件 这里使用字节流,一会我们会对视频进行复制(视频为非文本文件,故使用之) FileInp ...
- 漏桶、令牌桶限流的Go语言实现
限流 限流又称为流量控制(流控),通常是指限制到达系统的并发请求数. 我们生活中也会经常遇到限流的场景,比如:某景区限制每日进入景区的游客数量为8万人:沙河地铁站早高峰通过站外排队逐一放行的方式限制同 ...
- (专题四)06 matlab绘图选项卡
绘图选项卡 例子1--选择已有变量,绘制图形 都是按照选中的先后顺序依次确定坐标, 如果要修改绘制图形 法一,利用绘图工具和停靠图形按钮 法二,命令行窗口中输入命令 >>plottools ...
- 【机器学习】梯度下降 II
Gradient Descent 梯度下降 II 关于 Gradient Descent 的直观解释,参考上一篇博客[机器学习]梯度下降 I 本模块介绍几种梯度下降模型.定义符号标记如下: \(\th ...
- 2.Buffer详解
- java 单例模式的几种写法
一.懒汉式 public class Singleton{ private static Singleton instance = null; private Singleton(){} public ...
- 查看 JVM 参数的默认值
查看初始默认值:-XX:+PrintFlagsInitial HuandeMacBook-Air:~ huanliu$ java -XX:+PrintFlagsInitial [Global flag ...
- Oracle学习(四)SQL高级--表优化相关(序列、视图等)
INDEX(索引) 可以在表中创建索引,以便更加快速高效地查询数据. 用户无法看到索引,它们只能被用来加速搜索/查询. PS:更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引 ...