有关Kafka的那些事
Kafka基本概念
- Producer: 消息和数据的生产者,向kafka的一个topic发布消息的进程、代码、服务。
- Consumer:消息和数据的消费者,订阅数据并且处理器发布的消息的进程、代码、服务。
- Consumer Group:逻辑概念,对于同一个topic,会广播给不同的group,一个group中,只有一个consumer可以消费该消息。
- Broker:物理概念,kafka集群中每个kafka节点
- topic:逻辑概念,kafka消息的类别,对数据进行区分,隔离
- Partition:分区,物理概念,kafka下数据存储的基本单元,一个topic数据,会被分散存储到多个Partition,每一个Partition是有序的。
1. 每一个Topic被切分为多个Partitions
2. 消费者数目小于或等于Partition的数目
3. Broke Group中的每个Broke保存Topic的一个或多个Partitions
4. Consumer Group中有且仅有一个Consumer读取Topic的一个或多个Partitions,并且是唯一的Consumer。 - Replication:副本,同一个Partition可能会有多个Replica,多个Replica之间数据是一样的。
1. 当集群中有Broker挂掉的情况,系统可以主动使Replicas提供服务。
2. 系统默认设置每一个Topic的Replication系数为1,可以在创建Topic时单独设置。
3. Replication的基本单位是Topic的Partition。
4. 所有的读和写都是Leader进,Followers只是作为备份。
5. Follower必须能够及时复制Leader的数据。
6. 增加容错性和可拓展性。 - Replication Leader:一个Partition的多个Replica上,需要一个Leader负责该Partition上与Producer和Consumer交互,一个Partition有且只有一个Leader。
- RepliceManager:负责管理当前broker的所有分区和副本的信息,处理kafkaController发起的一些请求,副本状态的切换、添加/读取消息等
kafka基本结构
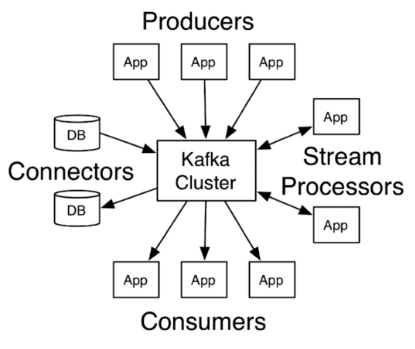
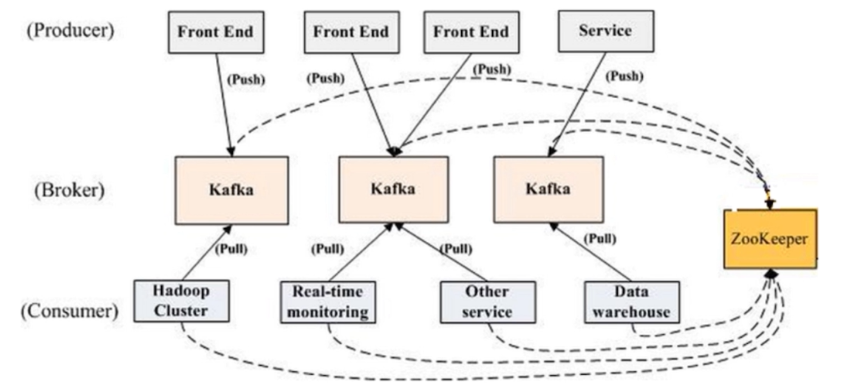
kafka消息结构:

kafka的特点
分布式
- 多分区
- 多副本
- 多订阅者
- 基于ZooKeeper调度
高性能
- 高吞吐量
- 低延时
- 高并发
- 时间复杂度为O(1)
持久性和拓展性
- 数据可持久化
- 容错性
- 支持在线水平拓展
- 消息自动平衡
kafka应用场景
- 消息队列
稳定性,高吞吐性,消息可被重复消费、低延迟性 - 行为跟踪
- 元数据监控
- 日志收集
- 流处理
- 事件源
- 持久性日志(commit log)
kafka高级特性
kafka消息事务
- 为什么要支持事务?
- 满足"读取-处理-写入"模式
- 流处理需求的不断增强
- 数据传输的事务定义
- 最多一次:消息不会别重复发送,最多被传输一次,但也有可能一次不传输
- 最少一次:消息不会被漏发送,最少被传输一次,但也有可能被重复传输
- 精确的一次(Exactly once):不会漏传输也不会重复传输,每个消息都传输且仅仅传输一次,这是大家所期望的
- 事务保证
- 内部重试问题:Producer幂等处理
- 多分区原子写入
- 避免僵尸实例

零拷贝
- 网络传输持久性日志块
- Java Nio channel.transforTo()方法
- Linux sendfile系统调用
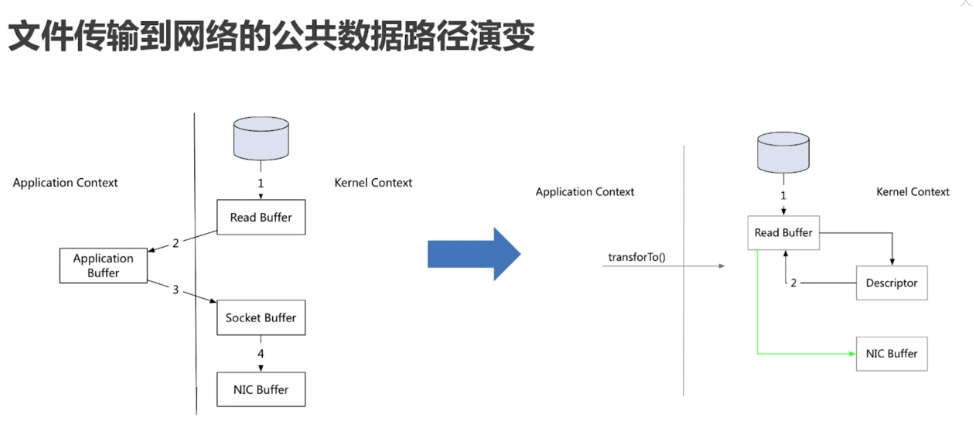
文件传输到网络的公共数据路径
1. 操作系统将数据从磁盘读入到内核空间的页缓存
2. 应用程序将数据从内核空间读入到用户空间缓存中
3. 应用程序将数据写回到内核空间到socket缓存中
4. 操作系统将数据从socket缓存区复制到网卡缓存区,以便将数据经网络发出
零拷贝过程:
1. 操作系统将数据从磁盘读入到内核空间的页缓存
2. 将数据的位置和长度等信息的描述符增加至内核空间(socket缓冲区)
3. 操作系统将数据从内核拷贝到网卡缓冲区,以便将数据经网络发出
零拷贝指的是内核空间和用户空间之间的交互拷贝次数为零
参考
有关Kafka的那些事的更多相关文章
- 饶军:Apache Kafka的过去,现在,和未来
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文首发在云+社区,未经许可,不得转载. 大家好,我大概简单的介绍一下,我叫饶军,我是硅谷的初创公司Confluent的联合创始人之一,我们公 ...
- 聊一聊高并发高可用那些事 - Kafka篇
目录 为什么需要消息队列 1.异步 :一个下单流程,你需要扣积分,扣优惠卷,发短信等,有些耗时又不需要立即处理的事,可以丢到队列里异步处理. 2.削峰 :按平常的流量,服务器刚好可以正常负载.偶尔推出 ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- 转】 Kafka文件存储机制那些事
原博文出自于:http://tech.meituan.com/kafka-fs-design-theory.html 感谢! Kafka是什么 Kafka是最初由Linkedin公司开发,是一个 ...
- 这事没完,继续聊spring cloud stream和kafka的这些小事
上一篇文章讲了如何用spring cloud stream集成kafka,并且跑起来一个demo,如果这一次宣传spring cloud stream的文章,其实到这里就可以啦.但实际上,工程永远不是 ...
- 简单聊一聊spring cloud stream和kafka的那点事
Spring Cloud Stream is a framework for building highly scalable event-driven microservices connected ...
- Vertica的这些事(十四)——Vertica实时消费kafka实现
一. 安装环境 Vertica官方提供了消费kafka的方法,需要注意版本对应 消费kafka原理,是Vertica提供的Udx 首先需要安装相应的环境 /${vertica}/packages/ka ...
- Kafka和RocketMQ底层存储之那些你不知道的事
大家好,我是yes. 我们都知道 RocketMQ 和 Kafka 消息都是存在磁盘中的,那为什么消息存磁盘读写还可以这么快?有没有做了什么优化?都是存磁盘它们两者的实现之间有什么区别么?各自有什么优 ...
随机推荐
- Java 8新特性(四):新的时间和日期API
Java 8另一个新增的重要特性就是引入了新的时间和日期API,它们被包含在java.time包中.借助新的时间和日期API可以以更简洁的方法处理时间和日期. 在介绍本篇文章内容之前,我们先来讨论Ja ...
- 团队作业4:第三篇Scrum冲刺博客(歪瑞古德小队)
目录 一.Daily Scrum Meeting 1.1 会议照片 1.2 项目进展 二.项目燃尽图 三.签入记录 3.1 代码/文档签入记录 3.2 Code Review 记录 3.3 issue ...
- promise和async await的区别
在项目中第一次遇到async await的这种异步写法,来搞懂它 项目场景 :点击登录按钮后执行的事件,先进行表单校验 this.$refs.loginFormRef.validate(element ...
- 超级码力编程赛带着6万奖金和1200件T恤向你跑来了~
炎炎夏日,总是感觉很疲劳,提不起一点精神怎么办?是时候参加一场比赛来唤醒你的激情了!阿里云超级码力在线编程大赛震撼携手全国数百所高校震撼来袭. 它来了,它来了,它带着60000现金和1200件T恤向你 ...
- 也谈基于Web的含工作流项目的一般开发流程
项目包含的通用模块代码等我有时间一并剥离贡献出来(基于WebSocket的通知引擎,工作流整合模块,自定义表单,基于RBAC权限设计),最近太忙了,Web项目有一段时间没碰,有点生疏的感觉,主要在忙G ...
- CSS布局中浮动问题的四种解决方案
一.起因: 子盒子设置浮动之后效果: 由此可见,蓝色的盒子设置浮动之后,因为脱离了标准文档流,它撑不起父盒子的高度,导致父盒子高度塌陷.如果网页中出现了这种问题,会导致我们整个网页的布局紊乱 二.解决 ...
- flutter 设置状态栏的背景与颜色
flutter 设置状态栏的背景与颜色 导包 import 'dart:io'; import 'package:flutter/services.dart'; 在main()函数中添加以下函数, v ...
- vue刷新数组
困扰我两天的问题被一行代码解决了!!! 最近在做某个功能时用到了v-for,页面内容都是根据父页面传递过来的数组生成的,但是当我改变数组内容时页面不会跟着改变.这个问题足足困扰了我两天时间,最终下面的 ...
- c# 可获取系统环境
c# 可获取系统环境, 启动进程执等 *.shell [MenuItem("Tools/DesignHelper/Clean and Pull")] private sta ...
- unity3d屏幕截图功能
function OnGUI(){ if(GUI.Button(Rect(Screen.width*0.5-50,Screen.height*0.5-50,100,100),"screen& ...