python 子进程
1.线程的介绍(理论部分)
1.1 进程线程分工
我们之前讲运行一个py文件,就是开启了一个进程,在内存中开辟一个进程空间,将必要的数据加载到这个进程空间,然后cpu在去调用这个进程的主线程去执行具体的代码。一个进程里默认包含一个主线程。
进程是资源单位,线程是执行单位。
a = 1
b = 2
c = a b
if a:
print(666)
def func():
print(a - b)
return 123
func()
print(111)
1.2 现实举例
工厂车间的例子。

1.3 进程vs线程
- 开启线程的开销低于开启进程的开销。
- 开启线程的速度远高于开启进程的速度,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用。
- 线程之间的数据是共享的,这样数据就不太安全,进程之间的数据隔离的。
1.4 多线程的应用举例
现在我们知道了,如果让你并发或者并行的执行任务,两种方式:
开启多进程。
一个进程下开启多线程。

文件编辑器:
第一个任务监听键盘的输入。
第二个任务输出到屏幕显示器。
第三个任务实时将数据保存在磁盘上。
要用多线程执行:
- 多线程数据共享,避免进程通信的队列的资源浪费。
- 开启多个进程开销大,效率相对低。
2.线程创建的两种方式
2.1函数式创建线程
# 方法一
from threading import Thread
def task(n1,n2):
print(f'{n1}开始心花怒放了...')
# print(f'{n2}正在等待那个他....')
if __name__ == '__main__':
t1 = Thread(target=task, args=('玮哥', '鹏鹏'))
t1.start() # 开销低,无阻塞
print('====主线程')
print('====主线程')
print('====主线程')
print('====主线程')
print('====主线程')
print('====主线程')
2.1.1 线程的开销小于进程
每次运行此代码,主线程永远在子线程开始之后在运行,并不是因为他们是串行,他们肯定是并行,只是因为开启线程的开销很低。
2.1.2 线程之间无父子之分
线程之间是没有主子、父子之分的,我们之所以称主线程、子线程仅仅是为了区分而已;而进程之间是有父子、主子之分,子进程的开启依赖于父进程,子进程的所有的资源都是深copy父进程而且父进程对子进程进行回收。
2.1.3 主线程为什么要等其余线程结束之后在结束。
进程是资源单位,加载各种数据资源的,但是如果进程里面的线程执行完毕,结束了,进程还有存在内存的必要么?但是主进程如果也结束了,其余的线程怎么办?其余线程没有数据资源了,只能强制的结束了,这样不合理。主线程代码执行完毕了之后,不能结束,他要等待其余线程结束了,他在结束,这样进程在结束。
2.2 面向对象式创建线程
from threading import Thread
class MyThread(Thread):
def run(self):
print('子线程开始了')
if __name__ == '__main__':
t1 = MyThread()
t1.start()
print('主')
3.进程vs线程
验证进程与线程的开启速度(开销)
from threading import Thread
import time
def task(n1,n2):
print(f'{n1}开始心花怒放了...')
time.sleep(2)
print(f'{n2}正在等待那个他....')
if __name__ == '__main__':
t1 = Thread(target=task, args=('玮哥', '鹏鹏'))
t1.start() # 线程的开销小,速度快。
print('====主线程')
获取线程的pid
from threading import Thread
import time
import os
def task():
print(f'此线程的pid是{os.getpid()}')
if __name__ == '__main__':
t1 = Thread(target=task)
t2 = Thread(target=task)
t3 = Thread(target=task)
t1.start()
t2.start()
t3.start()
print(f'====主线程的pid是{os.getpid()}')
一个进程下的所有的线程的pid都是这同一个进程的pid。
同一个进程下多线程共享数据。
from threading import Thread
import time
import os
x = 1000
def task():
global x
x = 0
if __name__ == '__main__':
t1 = Thread(target=task)
t1.start()
t1.join()
print(f'====主线程{x}')
同一个进程下的多个线程一定是数据共享的。
4.线程的其他方法
from threading import Thread
import threading
import time
import os
def task():
print('子线程!!!!')
time.sleep(1)
if __name__ == '__main__':
"""
# t1.start()
# print(t1.name) # 获取线程的名字
# t1.join()
# print(t1.is_alive()) # 判断线程是否存活运行
"""
t1 = Thread(target=task, name='线程-1') # 设置线程名字
t2 = Thread(target=task, name='线程-2') # 设置线程名字
t3 = Thread(target=task, name='线程-3') # 设置线程名字
t1.start()
t2.start()
t3.start()
print(threading.enumerate()) # 返回一个列表,存储的是当前活跃的线程对象。
# print(len(threading.enumerate())) # 获取当前活跃的线程的数量
# print(threading.active_count()) # 获取当前活跃的线程的数量
print(threading.get_ident()) # 获取当前线程的id号(线程号)
print(f'====主线程')
print(threading.get_ident()) # 获取当前线程的id号(线程号)
# print(p1.name) # 给自己成起名字
# time.sleep(1)
# print(p1.is_alive()) # 判断子进程是否还存在
# p1.terminate() # 杀死子进程
print(p1.pid) # 获取进程的pid
5.守护线程
先回忆守护进程
from multiprocessing import Process
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
if __name__ == '__main__':
p1 = Process(target=foo)
p2 = Process(target=bar)
p1.daemon = True
p1.start()
p2.start()
print("main-------")
总结:
守护进程是等待**主进程代码**结束即结束。
守护线程
from threading import Thread
import time
def task(n1,n2):
print(f'{n1}开始心花怒放了...')
time.sleep(2)
print(f'{n2}正在等待那个他....')
if __name__ == '__main__':
t1 = Thread(target=task, args=('玮哥', '鹏鹏'))
t1.daemon = True
t1.start()
print('====主线程')
再次测试
```python
from threading import Thread
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
if __name__ == '__main__':
t1 = Thread(target=foo)
t2 = Thread(target=bar)
t1.daemon = True
t1.start()
t2.start()
print("main-------")
```
**守护线程要等待主线程的程序结束之后,在结束,主线程程序什么时候结束?主线程程序要等待其余的子线程结束之后,在结束。**
**守护线程要等待主线程以及其余的非守护线程的子线程全部结束之后,在结束。**
```
from threading import Thread
import time
def foo():
print(123)
time.sleep(3)
print("end123")
def bar():
print(456)
time.sleep(1)
print("end456")
if __name__ == '__main__':
t1 = Thread(target=foo)
t2 = Thread(target=bar)
t1.daemon = True
t1.start()
t2.start()
print("main-------")
```
6.线程join
回忆:进程join是让主进程阻塞等待,等待子进程执行完毕之后,主进程再次执行。线程join同理。
from threading import Thread, currentThread
import time
def task():
print(f'{currentThread().getName()}开始了')
time.sleep(2)
print(f'{currentThread().getName()}结束了')
if __name__ == '__main__':
t1 = Thread(target=task, name='线程1')
t1.start()
t1.join()
print('====主线程')
7.线程锁
7.1 线程操作公共数据问题
from threading import Thread, currentThread
import time
x = 100
def task():
global x
print(1111)
temp = x
print(3333)
temp -= 1
print(22222)
# time.sleep(0.1)
x = temp
if __name__ == '__main__':
t_list = []
for i in range(100):
t = Thread(target=task, )
t.start()
t_list.append(t)
for i in t_list:
i.join()
print(f'====主线程{x}')
7.2 加锁处理
from threading import Thread, currentThread,Lock
import time
x = 100
def task(lock):
global x
print(1111)
lock.acquire()
temp = x
print(3333)
temp -= 1
print(22222)
lock.release()
# time.sleep(0.1)
x = temp
if __name__ == '__main__':
lock = Lock()
t_list = []
for i in range(100):
t = Thread(target=task, args=(lock,))
t.start()
t_list.append(t)
for i in t_list:
i.join()
print(f'====主线程{x}')
小结:
无论是进程还是线程加锁就是为了让锁住的程序变成串行处理,保证数据安全。
8.死锁现象

from threading import Thread, currentThread,Lock
import time
A_lock = Lock()
B_lock = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
A_lock.acquire()
print(f'{self.name}拿到了A锁')
B_lock.acquire()
print(f'{self.name}拿到了B锁')
B_lock.release()
print(f'{self.name}释放了B锁')
A_lock.release()
print(f'{self.name}释放了A锁')
def func2(self):
B_lock.acquire()
print(f'{self.name}拿到了B锁')
time.sleep(1)
A_lock.acquire()
print(f'{self.name}拿到了A锁')
A_lock.release()
print(f'{self.name}释放了A锁')
B_lock.release()
print(f'{self.name}释放了B锁')
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
print('====主')
小结:
虽然锁可以保证数据的安全,但是锁多了之后,容易造成死锁现象。进程锁同理(自己私下测试一下进程,也会出现死锁现象)
如果以后项目中真的需求两把以上的锁才能解决问题,那么我们就不用这种同步锁(互斥锁)了,我们要用递归锁。
9.递归锁
引子
递归锁就是一把锁,这一把锁可以锁多次,也可以释放多次,递归锁上有引用计数功能,锁一次, 1一次,解锁一次,-1一次,递归锁不允许其他的线程或者进程抢夺直到递归锁上的引用计数为0时。
测试
from threading import Thread, RLock
import time
A_lock = RLock()
B_lock = A_lock
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
A_lock.acquire()
print(f'{self.name}拿到了A锁')
B_lock.acquire()
print(f'{self.name}拿到了B锁')
B_lock.release()
print(f'{self.name}释放了B锁')
A_lock.release()
print(f'{self.name}释放了A锁')
def func2(self):
B_lock.acquire()
print(f'{self.name}拿到了B锁')
time.sleep(1)
A_lock.acquire()
print(f'{self.name}拿到了A锁')
A_lock.release()
print(f'{self.name}释放了A锁')
B_lock.release()
print(f'{self.name}释放了B锁')
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
print('====主')
小结:
进程也有递归锁,自己课下测试补充到你的进程笔记中。
10.信号量
10.1 引子
信号量其实也是锁,但是这个锁比较特殊,之前我们讲的互斥锁是同一时刻只允许一个进程(线程)持有这把锁,直到释放掉,其他进程才可以争抢这把锁。而信号量同时可以允许n个进程(线程)持有这把锁,一个或者几个释放掉,其他的一个或者几个才可以进入。
举一个形象但是不文明的例子:信号量就是公共厕所。5个蹲位,同一时刻只能5个人进入,怎么保证进5个人? 门口放5把钥匙,拿一个进一个。当5把钥匙都被取走之后,剩下的人想进入只能等着,等有人释放完毕,将钥匙放到门口,其他的人再去争抢这把钥匙,这就是信号量。
10.2代码测试
from threading import Thread,currentThread,Semaphore
import time
import random
def go_wc(sem):
sem.acquire()
print(f'{currentThread().getName()}成功抢到坑位')
time.sleep(random.randint(1,3))
print(f'{currentThread().getName()}成功结束')
sem.release()
if __name__ == '__main__':
sem = Semaphore(5)
for i in range(20):
t = Thread(target=go_wc,args=(sem,))
t.start()
11. GIL全局解释器锁
11.1 python执行一个文件的过程
引子
知乎,百度一些大v说python并发效率不行,不能多线程,并行不行等等。我们下面就仔细研究一下。
python执行文件的过程
你在终端输入python py文件的路径回车就执行了这个py文件,他在内存中的整个过程是什么样子的 ?
在内存中开启一个进程空间,将python解释器与py文件同时加载到内存。将py文件当做实参,将python解释器当做函数,执行函数的过程,最终返回一个结果。

**理论上来说,**我们的一个py文件可以开启多个线程,这些线程都可以进入CPython解释器然后并行的执行任务。
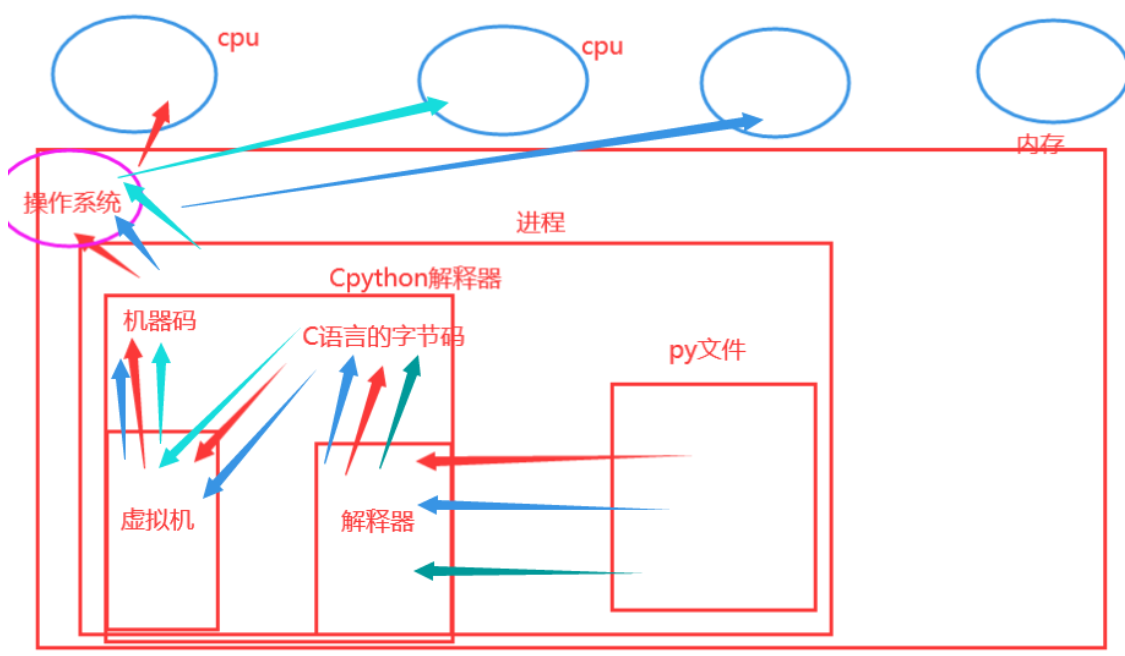
**但是!**这个知识理论上来说的。python的单个进程的多线程应用不了多核。Cpython源码的程序员给进入解释器的线程加了一把锁,就是我们常说的互斥锁。如图:
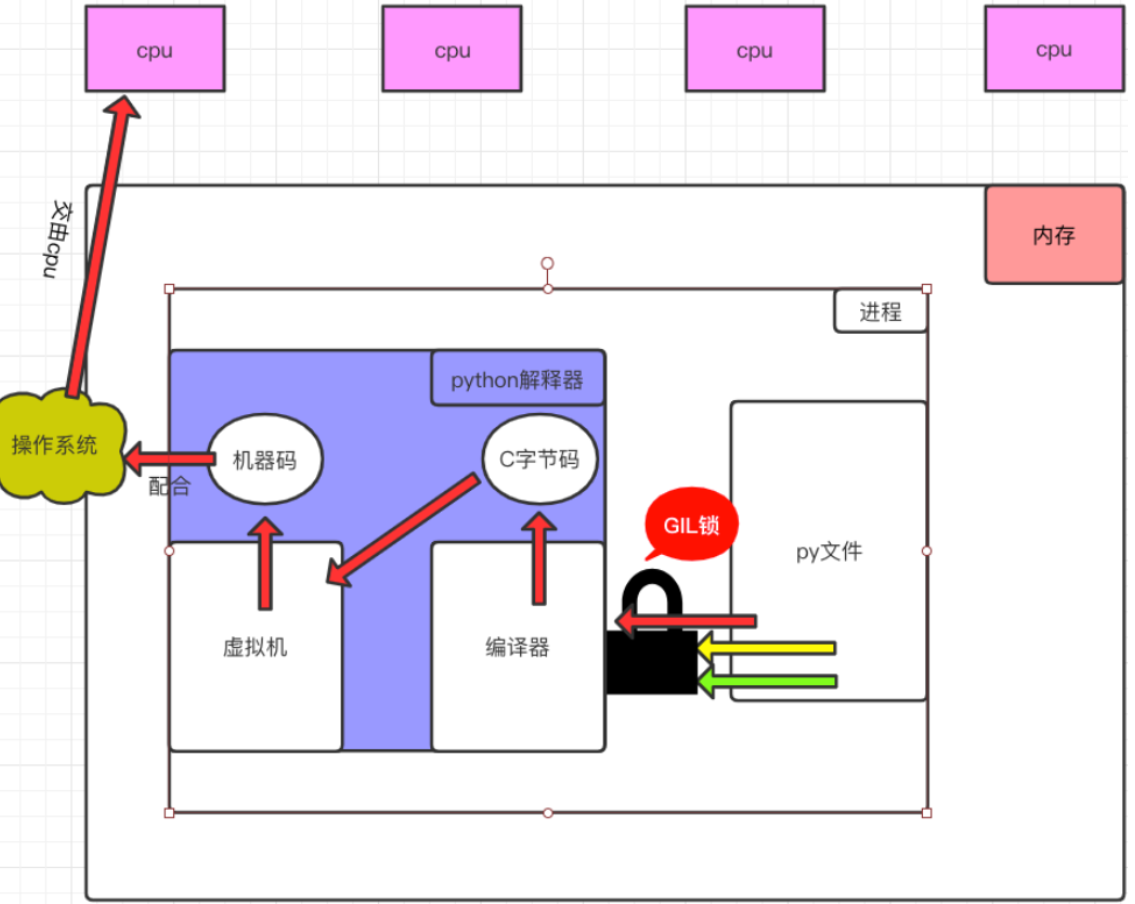
一个进程下的多个线程不能并行,但是可以并发。
11.2 为什么加这把GIL锁?
加这把锁其实是有历史原因的。
当时那个年代是单核时代,而且CPU价格非常昂贵,python起初作为一种脚本语言,面临的需求单核解决足以。
如果不加这把GIL全局解释器锁,同一时刻进入Cpython解释器线程数量不定,我们要保证Cpython解释器的数据资源安全,就需要在源码内部需要主动加入大量的互斥锁保证数据安全性,这样非常麻烦并且对于Cpython源码的开发速度势必减慢。
11.3 为什么不去掉这把锁?
Cpython解释器内部的管理以及业务逻辑全部是围绕单线程实现的,并且从龟叔创建Cpython到现在,Cpython源码已经更新迭代马上到4版本了,源码内容体量庞大,如果你要去掉,这个工程量无异于重新构建python,是比登天还难。
Cpython解释器是官方推荐的解释器,处理速度快,功能强大。
Jpython就是编译成Java识别的字节码,没有GIL锁。
pypy属于动态编译型,规则和漏洞很多,现在还在测试阶段(未来可能会成为主流)没有GIL锁。
只有Cpython解释器有GIL锁,其他类型的解释器以及其他语言都没有。
这把锁不是python语言的缺陷,而是Cpython解释器的缺陷。
11.4 这把锁带来的影响以及如何解决?
这把锁带来的影响是单进程下多线程不能利用多核并行,只能利用单核并发。怎么优化?
我们可以用多进程的并行替代,只不过可能是开启进程有些开销大,但是效率差不多。
我们也可以采用C的模块或者嵌入C语言去处理这种单进程的多线程的并行的问题。
11.5 这把锁真的是影响开发效率么?
我们多线程或者多进程的去处理任务,此时这个任务分两种任务。
IO密集型:我们以后从事的开发面对的业务,基本上都是IO密集型,对于IO密集型单个进程下的多线程并发解决就可以。

IO密集型:操作系统可以操控着CPU遇到IO就将CPU强行的切换执行另一个任务,而这个任务遇到IO阻塞了,马上又会切换,所以IO密集型利用单个进程的多线程并发是最好的解决方式(后面还会有协程也非常好用)。
计算密集型:多个任务都是纯计算都没有IO阻塞,那么此时应该利用多进程并行的处理任务。

小结:
GIL全局解释器锁只存在Cpython解释器中,他是给进入解释器的线程上锁带来的影响:
优点:便于Cpython解释器的内部资源管理,保证了Cpython解释器的数据安全。
缺点:单个进程的多线程不能利用多核。
GIL全局解释器锁并不是让Cpython不能利用多核,多进程是可以利用多核的,况且IO密集型的任务,单个进程的多线程并发处理足以。
IO密集型:单个进程的多线程并发处理。
计算密集型:多个进程并行处理。
12. GIL锁与普通的互斥锁的区别
两把锁保护对象不同
GIL锁保护的是解释器以及各种库的数据安全。而普通的互斥锁保护的是我们自己写的程序的数据安全。
两把锁的性质相同
GIL锁实际上就是互斥锁,性质相同。
13. Cpython解释器并发效率验证
13.1 IO密集型的效率验证
from multiprocessing import Process
from threading import Thread
import time
import random
def task():
res = 0
for i in range(5):
time.sleep(1)
res = 1
if __name__ == '__main__':
# 并行的时间验证
# 多进程的并行
# start_time = time.time()
# l1 = []
# for i in range(4):
# p = Process(target=task,)
# p.start()
# l1.append(p)
#
# for i in l1:
# i.join()
#
# print(f'执行时间是{time.time()-start_time}') # 5.132
# 多线程的并发
start_time = time.time()
l1 = []
for i in range(4):
p = Thread(target=task,)
p.start()
l1.append(p)
for i in l1:
i.join()
print(f'执行时间是{time.time()-start_time}') # 5.046
小结
IO密集型来说,单进程下的多线程的并发与多进程的并行效率差不多。
13.2 计算密集型的效率验证
from multiprocessing import Process
from threading import Thread
import time
def task1():
res = 0
for i in range(1000000):
res = 1
def task2():
res = 0
for i in range(1000000):
res -= 1
def task3():
res = 2
for i in range(1000000):
res *= 2
def task4():
res = 10
for i in range(1000000):
res /= 2
if __name__ == '__main__':
# 并行的时间验证
# # 多进程的并行
# start_time = time.time()
# l1 = []
# p1 = Process(target=task1,)
# p2 = Process(target=task2,)
# p3 = Process(target=task3,)
# p4 = Process(target=task4,)
#
# p1.start()
# p2.start()
# p3.start()
# p4.start()
#
# p1.join()
# p2.join()
# p3.join()
# p4.join()
#
# print(f'执行时间是{time.time()-start_time}') # 15.893516302108765
# 多线程的并发
start_time = time.time()
p1 = Thread(target=task1,)
p2 = Thread(target=task2,)
p3 = Thread(target=task3,)
p4 = Thread(target=task4,)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
print(f'执行时间是{time.time()-start_time}') # 15.893516302108765 16.129521369934082
总结:
面试题:
什么时GIL锁:是全局解释器锁,Cpython专门的一把锁,作用:第一:同一时刻只允许一个线程进入系统,第二:单进程的多线程不能实现并行,所以只能用并发和串行,其他的python解释器没有这把锁
14. 进程池线程池
14.1 基于多线程的socket
服务端
import socket
from threading import Thread
def task(conn, addr):
while 1:
try:
from_client_data = conn.recv(1024)
if from_client_data.upper() == b'Q':
break
print(f'来自{addr}客户的消息:{from_client_data.decode("utf-8")}')
to_client_data = input('>>>')
conn.send(to_client_data.encode('utf-8'))
except Exception:
break
conn.close()
def communication():
server = socket.socket()
server.bind(('127.0.0.1', 8848))
server.listen(5)
while 1:
conn, addr = server.accept() # 阻塞
t1 = Thread(target=task,args=(conn,addr))
t1.start()
communication()
客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8848))
while 1:
to_server_data = input('>>>')
client.send(to_server_data.encode("utf-8"))
if to_server_data.upper() == 'Q':
break
from_server_data = client.recv(1024)
print(f'来自服务端的消息:{from_server_data.decode("utf-8")}')
client.close()
此版本有问题,来多少链接就需要创建多少线程,显然不合理,我们应该控制线程上限。
14.2 线程池
存放线程的容器,线程的数量是固定的。
from concurrent.futures import ThreadPoolExecutor
import time
import threading
import random
import os
def task(n):
print(f'{threading.currentThread()}开始任务')
time.sleep(random.randint(1, 3))
print(f'{threading.currentThread()}结束任务')
if __name__ == '__main__':
thread_poor = ThreadPoolExecutor(max_workers=5)
# max_workers 设置线程池或者进程池的数量
# print(os.cpu_count())
# 给线程池发布一个任务
# thread_poor.submit(task,1)
# thread_poor.submit(task,1)
# thread_poor.submit(task,1)
# thread_poor.submit(task,1)
# thread_poor.submit(task,1)
# thread_poor.submit(task,1)
# thread_poor.submit(task,1)
# 一次性发布20个任务。
for i in range(20):
thread_poor.submit(task, i)
14.3 进程池
存放进程的容器,进程的数量是可控的。
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import time
import threading
import random
import os
def task(n):
print(f'{os.getpid()}开始任务')
time.sleep(random.randint(1, 3))
print(f'{os.getpid()}结束任务')
if __name__ == '__main__':
process_poor = ProcessPoolExecutor(max_workers=5)
# 一次性发布20个任务。
for i in range(20):
process_poor.submit(task, i)
15. 阻塞 非阻塞 同步 异步
在执行程序的角度
阻塞:在程序执行过程中,遇到了IO(网络请求、文件数据库的操作),程序就停住了,此时程序就暂时挂起,cpu被操作系统从此程序中切走,等到IO完毕,操作系统再将cpu切回来。
非阻塞:在程序执行中,没有IO(全部都是计算、运算)或者(程序遇到了IO时,通过程序的某些操作将cpu切换到程序的另一些正在运行的进程中,程序是一直运行的。协程)
在发布任务的角度
同步:发布第一个任务,然后等待,等待第一个任务的返回结果之后,在发布第二个任务。
异步:一次性将所有的任务全部发布,继续向下执行。
异步发布任务,如何获取结果?
面试题:
同步和串行的区别?同步和串行的区别:同步在执行任务的角度,任务里面包含串行、并发、并行,他们的角度不同。
异步和并发的区别?异步和并发的区别:异步在执行任务的角度,任务里面包含串行、并发、并行,他们的角度不同。
16. 同步调用
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time
import threading
import random
import os
def task(n):
# print(f'{threading.currentThread()}开始任务')
time.sleep(random.randint(1, 3))
# print(f'{threading.currentThread()}结束任务')
return n**2
if __name__ == '__main__':
thread_poor = ThreadPoolExecutor(max_workers=5)
# 一次性发布20个任务。
for i in range(20):
obj = thread_poor.submit(task, i) # 返回的是任务的当前的状态对象
# time.sleep(1)
# print(f'obj ====>{obj}')
print(obj.result()) # 索要结果 只有要写了这个就会同步
thread_poor.shutdown(wait=True)
# 1. 让主进程/主线程阻塞,等进程池线程池内所有的进程线程将所有的任务执行完毕之后,主进程线程在执行。
# 2. 在shutdown之后,不允许在给线程池/进程池 发布新的任务
# for i in range(5):
# thread_poor.submit(task,i)
print('====主')
shutdown()
1. **让主进程/主线程阻塞,等进程池线程池内所有的进程线程将所有的任务执行完毕之后,主进程线程在执行。**
2. **在shutdown之后,不允许在给线程池/进程池 发布新的任务**
17. 异步调用
from concurrent.futures import ProcessPoolExecutor
import time
import threading
import random
import os
def task(n):
print(f'{os.getpid()}开始任务')
time.sleep(random.randint(1, 3))
print(f'{os.getpid()}结束任务')
if __name__ == '__main__':
process_poor = 1(max_workers=5)
# 一次性发布20个任务。
for i in range(20):
process_poor.submit(task, i)
print('====主')
18.异步调用 回调函数
18.1 浏览器、爬虫原理
浏览器原理
浏览器会将你的请求数据通过网络发送到百度的服务器,服务器接收到请求数据,验证请求数据之后,返回给浏览器软件一个html页面数据,浏览器接收到这个html页面数据通过浏览器的内核的渲染机制,渲染成美丽的页面。
爬虫的原理
爬虫是模拟一个浏览器向服务器请求数据。
数据请求成功之后,通过数据清洗获取目标的数据。
import requests
ret = requests.get('http://www.baidu.com')
if ret.status_code == 200:
print(ret.text)
18.2 异步调用如何获取结果
发布三个任务:几种回收方式?
所有的任务全部完成之后,统一回收。
哪个任务先完成,回收其任务。
方案一
演示一下统一回收所有的结果。
from concurrent.futures import ThreadPoolExecutor
import requests
def crawling(url: str):
"""
此函数是通过网络爬取指定url的数据,IO密集型
:param url:
:return:
"""
ret = requests.get(url)
if ret.status_code == 200:
return ret.text
def parse(data: str):
"""
此函数是对爬取的数据进行解析,计算密集型(耗时短)
:param data:
:return:
"""
return len(data)
if __name__ == '__main__':
thread_poor = ThreadPoolExecutor(5)
# 方法一 串行 效率低
# obj = thread_poor.submit(crawling, 'http://www.baidu.com')
# parse(obj.result())
# obj = thread_poor.submit(crawling, 'http://www.baidu.com')
# parse(obj.result())
# obj = thread_poor.submit(crawling, 'http://www.baidu.com')
# parse(obj.result())
# 方法二
url_list = [
'http://www.baidu.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.taobao.com',
'https://www.cnblogs.com/jin-xin/articles/7459977.html',
'https://www.luffycity.com/',
'https://www.cnblogs.com/jin-xin/articles/9811379.html',
'https://www.cnblogs.com/jin-xin/articles/11245654.html',
'https://www.sina.com.cn/',
]
task_list = []
for url in url_list:
obj = thread_poor.submit(crawling,url)
task_list.append(obj)
thread_poor.shutdown() # 等待线程池的所有线程将10个IO任务并发的处理完毕
# print(task_list) # 所有的任务对象都是已完成的状态
# 统一回收结果
for obj in task_list:
print(parse(obj.result()))
方案一过程描述:
我们开启了5线程的线程池并发的处理了10个IO密集型的任务,但是我们还有10个计算密集型的任务是通过串行处理的,这样不合理,效率低。
方案二
from concurrent.futures import ThreadPoolExecutor
import requests
def crawling(url: str):
"""
此函数是通过网络爬取指定url的数据,IO密集型
:param url:
:return:
"""
ret = requests.get(url)
if ret.status_code == 200:
return parse(ret.text)
def parse(data: str):
"""
此函数是对爬取的数据进行解析,计算密集型(耗时短)
:param data:
:return:
"""
return len(data)
if __name__ == '__main__':
thread_poor = ThreadPoolExecutor(5)
url_list = [
'http://www.baidu.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.taobao.com',
'https://www.cnblogs.com/jin-xin/articles/7459977.html',
'https://www.luffycity.com/',
'https://www.cnblogs.com/jin-xin/articles/9811379.html',
'https://www.cnblogs.com/jin-xin/articles/11245654.html',
'https://www.sina.com.cn/',
]
task_list = []
for url in url_list:
obj = thread_poor.submit(crawling,url)
task_list.append(obj)
thread_poor.shutdown() # 等待线程池的所有线程将10个IO任务并发的处理完毕
# print(task_list) # 所有的任务对象都是已完成的状态
for obj in task_list:
print(obj.result())
方案二过程:
我们开启了5线程的线程池并发的处理了10个IO密集型的任务(每个任务分两个小任务IO 计算),方案二比方案一效率更高一些,但是也有问题:
利用多线程(多进程,线程池等)处理的任务最好都是IO密集型,不要掺杂着计算密集型,我们现在是一个IO 一个计算两种任务耦合到了一起,增加了耦合性。
无论方案一还是方案二都没有做到实时获取结果。
18.3 异步调用 回调函数
from concurrent.futures import ThreadPoolExecutor
import requests
def crawling(url: str):
"""
此函数是通过网络爬取指定url的数据,IO密集型
:param url:
:return:
"""
ret = requests.get(url)
if ret.status_code == 200:
return ret.text
def parse(obj):
"""
此函数是对爬取的数据进行解析,计算密集型(耗时短)
:param data:
:return:
"""
print(len(obj.result()))
if __name__ == '__main__':
thread_poor = ThreadPoolExecutor(5)
url_list = [
'http://www.baidu.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.taobao.com',
'https://www.cnblogs.com/jin-xin/articles/7459977.html',
'https://www.luffycity.com/',
'https://www.cnblogs.com/jin-xin/articles/9811379.html',
'https://www.cnblogs.com/jin-xin/articles/11245654.html',
'https://www.sina.com.cn/',
]
for url in url_list:
obj = thread_poor.submit(crawling, url)
obj.add_done_callback(parse)
thread_poor.shutdown() # 等待线程池的所有线程将10个IO任务并发的处理完毕
# print(task_list) # 所有的任务对象都是已完成的状态
异步调用 回调函数 机制:
我们开启了5线程的线程池并发的处理了10个IO密集型的任务,并且让每个任务设置了回调函数,回调函数处理的数据解析的功能,10个IO密集型的任务线程池的线程去执行,10个任务的回调函数交由空闲的线程(或者主线程)去执行。
参数解释:
add_done_callback:回调函数,只要有线程或者进程完成了当前网页爬去的任务,剩下的分析结果的任务交由回调函数去执行,线程或者进程继续进行网页爬取的任务。
整体的执行流程:线程池设置4个线程, 异步发起10个任务,每个任务是通过网页获取源码, 并发执行, 当一个任务完成之后,将parse这个分析代码的任务交由剩余的空闲的线程去执行,你这个线程继续去处理其他任务.
什么情况下用异步调用 回调函数的机制呢?
你要具备两种类型的任务:第一种IO密集型的任务,第二种计算密集型(耗时很短)的任务,这样IO密集型的任务我们可以利用并发或者并行处理,任何一个处理完毕得到结果之后,直接抛给回调函数,回调函数一般都是主进程或者主线程(空余线程)处理,所以第二种任务一定要耗时短,尽量无IO阻塞。
进程池 回调函数: 回调函数由主进程去执行。
线程池 回调函数: 回调函数由空闲线程去执行。
19 线程队列
19.1 先进先出队列
import queue
q = queue.Queue(3)
q.put(111)
q.put('王秋雨润')
q.put('易烊千玺')
# q.put('八格牙路')
print(q.get())
print(q.get())
print(q.get())
print(q.get())
19.2 后进先出队列
import queue
q = queue.LifoQueue(4) # last in first out
q.put(111)
q.put(222)
q.put(333)
q.put('玮哥')
print(q.get())
print(q.get())
print(q.get())
print(q.get())
19.3 优先级队列
import queue
q = queue.PriorityQueue(5)
# 每次通过元组的形式插入,元组的第一个元素一定是int类型,数字越低,优先级越高。
q.put((0, '新闻'))
q.put((2, '峰哥'))
q.put((-10, '冲哥'))
q.put((5, '日天哥', 'fdsafd'))
print(q.get())
print(q.get())
print(q.get())
print(q.get())
print(q.get())
20.事件Event
线程与进程都有event存在,先不说什么事件event,我们先聊一聊线程和进程的一个特性:每个线程(进程)都是独立运行且状态不可预测。如果程序中的其他线程(进程)需要通过判断某个线程的状态来确定自己下一步的操作,这时线程(进程)同步问题就会变得非常棘手。其实这是增加了线程(进程)之间的关联性,一个线程(进程)运行到某个节点决定另一个线程(进程)是否继续运行。听起来很神秘,其实没有事件event照样可以实现。
from threading import Thread, Event
# from multiprocessing import Event
import time
import threading
event = Event()
def connect():
print(f'{threading.currentThread()}检查服务器是否开启...')
time.sleep(3)
print(f'{threading.currentThread()}确定服务器已经正常开启')
event.set()
def ask():
print(f'{threading.currentThread()}尝试连接服务器....')
# event.wait() # 阻塞,直到event对象改变了状态在向下进行
# event.wait(timeout=2) # 可以设置阻塞时长,如果超过设置的世间仍未改变状态,则直接向下运行
# event.wait(timeout=4) #
print(f'{threading.currentThread()}连接成功')
if __name__ == '__main__':
t1 = Thread(target=connect,)
t2 = Thread(target=ask,)
t1.start()
t2.start()
同进程的一样,线程的一个关键特性是每个线程都是独立运行且状态不可预测。
如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,
这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。
对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在初始情况下
,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,
那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,
它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行。python 子进程的更多相关文章
- Python子进程 (subprocess包)
Python子进程 (subprocess包) subprocess以及常用的封装函数 当我们运行python的时候,我们都是在创建并运行一个进程.正如我们在Linux进程基础中介绍的那样,一个进程可 ...
- python 子进程 subpocess 的使用方法简单介绍
python的子进程嘛,就是利用python打开一个子进程(当然像是一句废话),但是可能和我们理解的不太一样. 一:如何理解? 我们可能的理解:多开一个进程运行某个python函数(如果只想实现这个功 ...
- python子进程模块subprocess详解与应用实例 之三
二.应用实例解析 2.1 subprocess模块的使用 1. subprocess.call >>> subprocess.call(["ls", " ...
- python子进程模块subprocess详解与应用实例 之一
subprocess--子进程管理器 一.subprocess 模块简介 subprocess最早是在2.4版本中引入的. subprocess模块用来生成子进程,并可以通过管道连接它们的输入/输出/ ...
- python子进程模块subprocess详解
subprocess--子进程管理器一.subprocess 模块简介subprocess最早是在2.4版本中引入的.subprocess模块用来生成子进程,并可以通过管道连接它们的输入/输出/错误, ...
- python子进程模块subprocess详解与应用实例 之二
1.2. Popen 对象 Popen类的实例有下列方法: 1. Popen.poll() 检查子进程是否已经结束,设置并返回返回码值. 2. Popen.wait() 等待子进程结束,设置并返回返回 ...
- python子进程模块subprocess调用shell命令
http://www.cnblogs.com/vamei/archive/2012/09/23/2698014.html
- Python 子进程不能input
from threading import Thread from multiprocessing import Process def f1(): name = input('请输入名字') #EO ...
- 应该了解的Python模块
Python很优雅.使用以下模块有助于保持你的代码整洁.易于维护.欢迎补充. Docopt.忘了optparse和argparse吧,使用docstring来构建优雅的.高可读性.复杂(如果你有这个需 ...
随机推荐
- Python实现微信支付(三种方式)
Python实现微信支付(三种方式) 关注公众号"轻松学编程"了解更多. 如果需要python SDk源码,可以加我微信[1257309054] 在文末有二维码. 一.准备环境 1 ...
- 参悟python元类(又称metaclass)系列实战(一)
写在前面 之前在看廖雪峰python系列的教程时,对元类的章节一直头大,总在思考我到底适不适合学习python,咋这么难,尤其是ORM的部分,倍受打击:后来从0到1手撸了一套ORM,才稍微进阶了一点理 ...
- 『JVM』我不想知道我是怎么来滴,我就想知道我是怎么没滴
我是风筝,公众号「古时的风筝」,一个兼具深度与广度的程序员鼓励师,一个本打算写诗却写起了代码的田园码农! 文章会收录在 JavaNewBee 中,更有 Java 后端知识图谱,从小白到大牛要走的路都在 ...
- Ethernaut靶场练习(0-5)
1.Hello Ethernaut 目标: 安装好metamask,熟悉操作命令. 操作过程: 我们先提交一个实例,然后打开游览器F12.然后跟他的提示走. 先输入contract.info(). c ...
- 国内申请苹果美区ID
首先声明,纯粹是自己为了玩游戏而找到的方法..... 不用翻墙,在国内,就可以申请非国区的apple ID. 1.你自己申请一个自己的国区的apple ID,地址:https://appleid.ap ...
- 论文阅读:An End-to-End Network for Generating Social Relationship Graphs
论文链接:https://arxiv.org/abs/1903.09784v1 Abstract 社交关系智能代理在人工智能领域中越来越引人关注.为此,我们需要一个可以在不同社会关系上下文中理解社交关 ...
- C#使用浏览器打开网址
使用指定浏览器打开网址: System.Diagnostics.Process.Start("360chrome.exe", "http://converter.tele ...
- Netlink 内核实现分析 3
Netlink IPC 数据结构 #define NETLINK_ROUTE 0 /* Routing/device hook */ #define NETLINK_UNUSED 1 /* Unuse ...
- binary hacks读数笔记(objdump命令)
一.首先看一下几个常用参数的基本含义: objdump命令是Linux下的反汇编目标文件或者可执行文件的命令,它还有其他作用,下面以ELF格式可执行文件test为例详细介绍: 1.objdump -f ...
- Azure 静态 web 应用集成 Azure 函数 API
前几次我们演示了如果通过Azure静态web应用功能发布vue跟blazor的项目.但是一个真正的web应用,总是免不了需要后台api服务为前端提供数据或者处理数据的能力.同样前面我们也介绍了Azur ...