Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件
首先说一下,这里解决的问题应用场景:
sparksql处理Hive表数据时,判断加载的是否是分区表,以及分区表的字段有哪些?再进一步限制查询分区表必须指定分区?
这里涉及到两种情况:select SQL查询和加载Hive表路径的方式。这里仅就"加载Hive表路径的方式"解析分区表字段,在处理时出现的一些问题及解决作出详细说明。
如果大家有类似的需求,笔者建议通过解析Spark SQL logical plan和下面说的这种方式解决方案结合,封装成一个通用的工具。
问题现象
sparksql加载指定Hive分区表路径,生成的DataSet没有分区字段。
如,
sparkSession.read.format("parquet").load(s"${hive_path}"),hive_path为Hive分区表在HDFS上的存储路径。
hive_path的几种指定方式会导致这种情况的发生(test_partition是一个Hive外部分区表,dt是它的分区字段,分区数据有dt为20200101和20200102):
1. hive_path为"/spark/dw/test.db/test_partition/dt=20200101"
2. hive_path为"/spark/dw/test.db/test_partition/*"
因为牵涉到的源码比较多,这里仅以示例的程序中涉及到的源码中的class、object和方法,绘制成xmind图如下,想细心研究的可以参考该图到spark源码中进行分析。
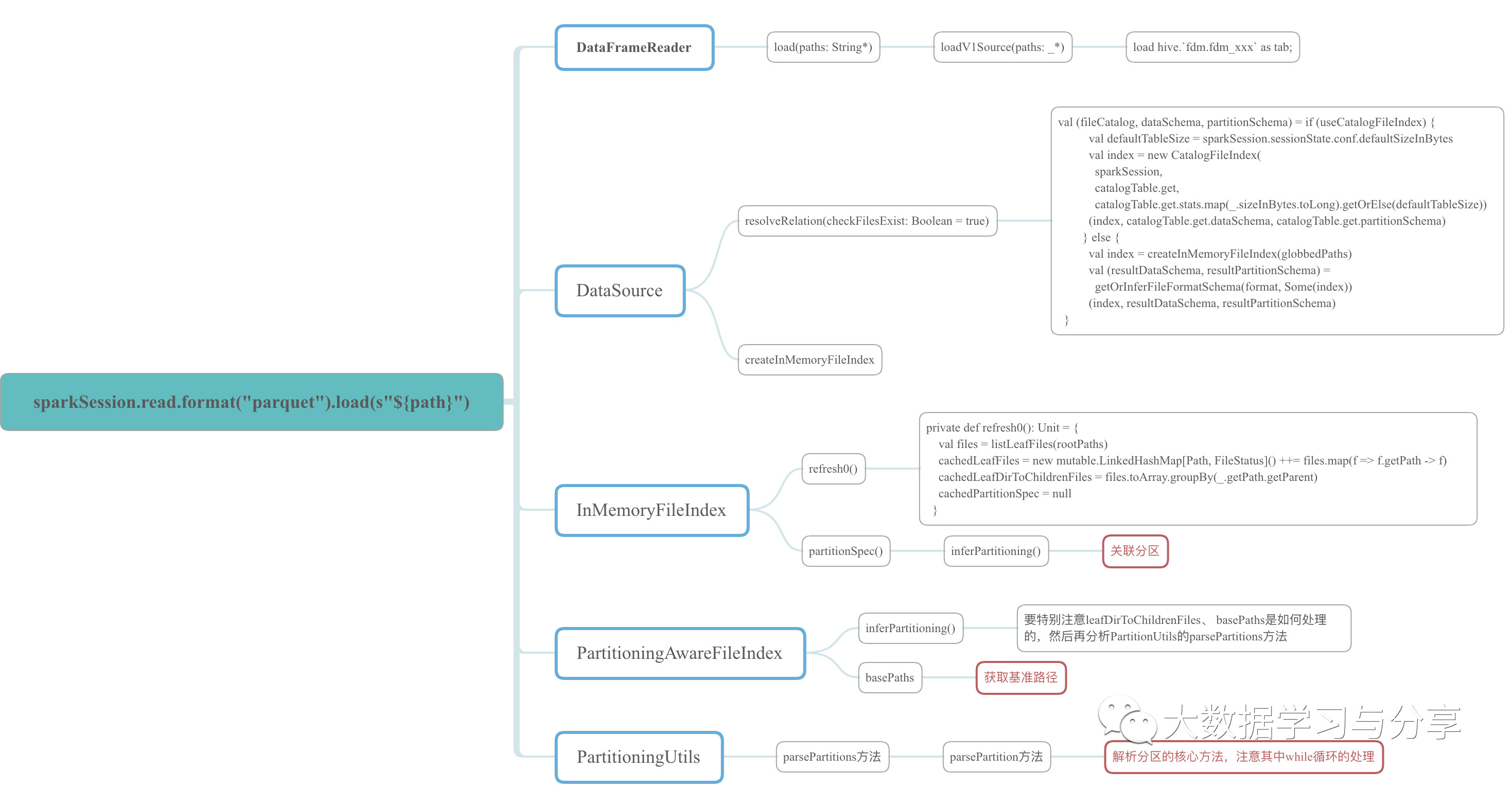
问题分析
我这里主要给出几个源码段,结合上述xmind图理解:
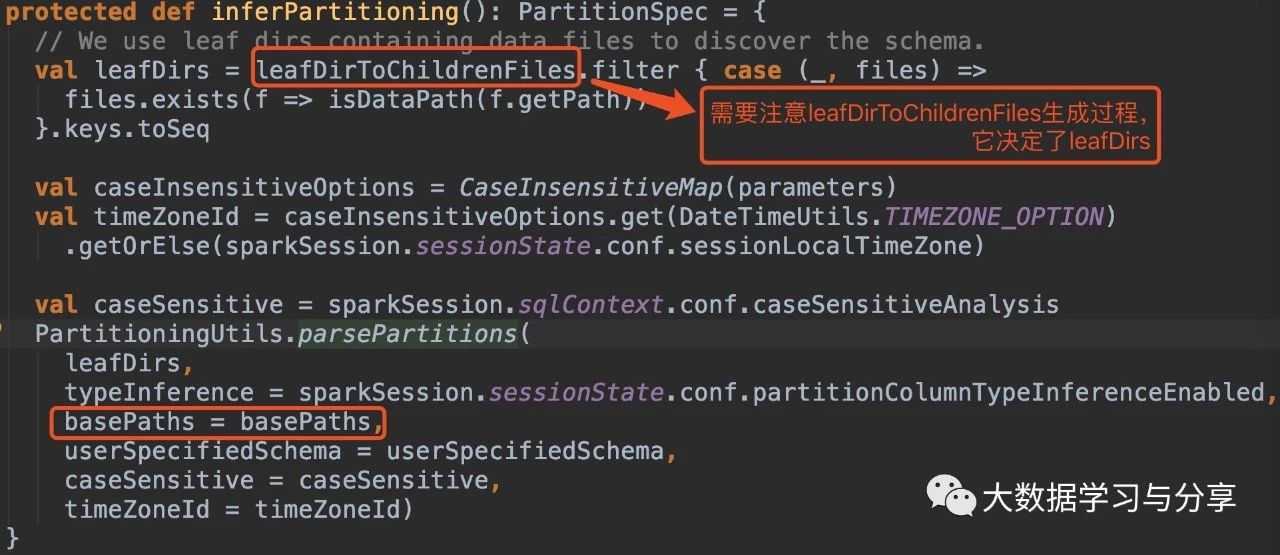
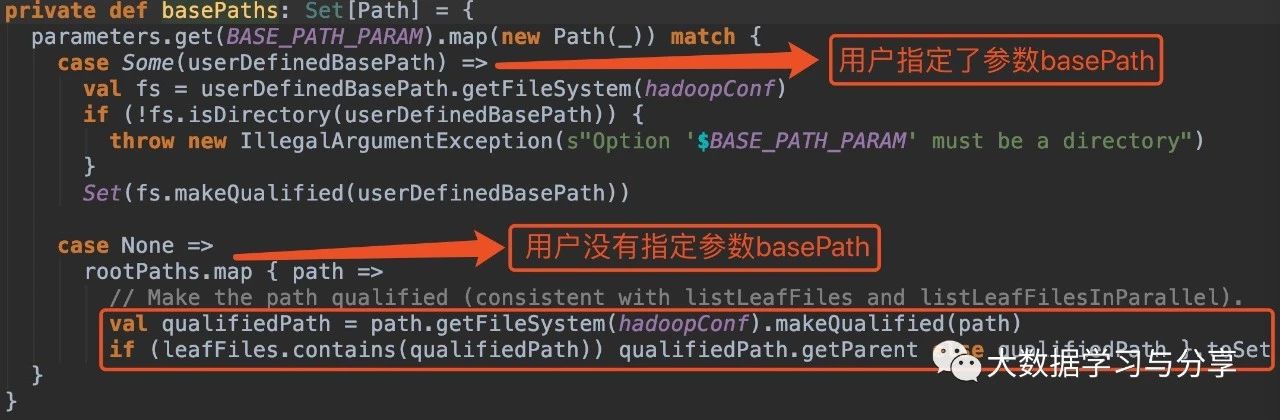
在没有指定参数basePath的情况下:
1. hive_path为/spark/dw/test.db/test_partition/dt=20200101
sparksql底层处理后得到的basePaths: Set(new Path(“/spark/dw/test.db/test_partition/dt=20200101”))【伪代码】
leafDirs: Seq(new Path(“/spark/dw/test.db/test_partition/dt=20200101”))【伪代码】
2. hive_path为/spark/dw/test.db/test_partition/*
sparksql底层处理后得到的basePaths: Set(new Path(“/spark/dw/test.db/test_partition/dt=20200101”),new Path(“/spark/dw/test.db/test_partition/dt=20200102”))【伪代码】
leafDirs: Seq(new Path(“/spark/dw/test.db/test_partition/dt=20200101”),new Path(“/spark/dw/test.db/test_partition/dt=20200102”))【伪代码】
这两种情况导致源码if(basePaths.contains(currentPath))为true,还没有解析分区就重置变量finished为true跳出循环,因此最终生成的结果也就没有分区字段:
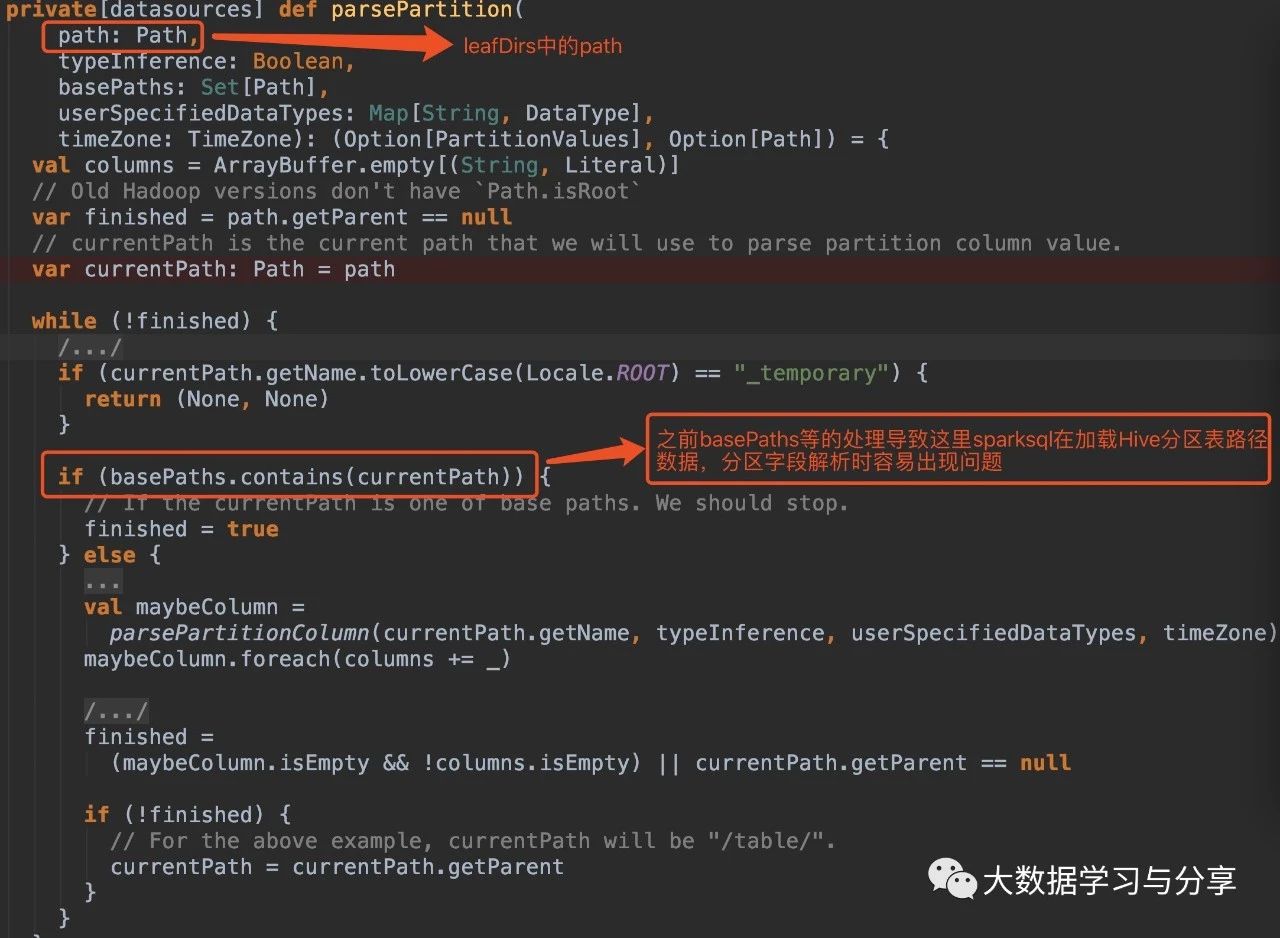
解决方案(亲测有效)
1. 在Spark SQL加载Hive表数据路径时,指定参数basePath,如
sparkSession.read.option("basePath","/spark/dw/test.db/test_partition")
2. 主要重写basePaths方法和parsePartition方法中的处理逻辑,同时需要修改其他涉及的代码。由于涉及需要改写的代码比较多,可以封装成工具
关联文章:
Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件的更多相关文章
- Hive表种map字段的查询取用
建表可以用 map<string,string> 查询时可以按照 aaa[bbb], aaa 是map字段名,bbb是其中的参数名,就可以取到这个参数的值了 当参数名bbb是string时 ...
- Spark访问与HBase关联的Hive表
知识点1:创建关联Hbase的Hive表 知识点2:Spark访问Hive 知识点3:Spark访问与Hbase关联的Hive表 知识点1:创建关联Hbase的Hive表 两种方式创建,内部表和外部表 ...
- 3. Spark SQL解析
3.1 新的起始点SparkSession 在老的版本中,SparkSQL提供两种SQL查询起始点,一个叫SQLContext,用于Spark自己提供的SQL查询,一个叫HiveContext,用于连 ...
- Spark DataFrame vector 类型存储到Hive表
1. 软件版本 软件 版本 Spark 1.6.0 Hive 1.2.1 2. 场景描述 在使用Spark时,有时需要存储DataFrame数据到Hive表中,一般的存储方式如下: // 注册临时表 ...
- 【hive】hive表很大的时候查询报错问题
线上hive使用环境出现了一个奇怪的问题,跑一段时间就报如下错误: FAILED: SemanticException MetaException(message:Exception thrown w ...
- 查找sqlserver数据库中,查询某值所表名和字段名
有时候我们想通过一个值知道这个值来自数据库的哪个表以及哪个字段,通过一个存储过程实现的.只需要传入一个想要查找的值,即可查询出这个值所在的表和字段名. 前提是要将这个存储过程放在所查询的数据库. CR ...
- Oracle 查询库中所有表名、字段名、字段名说明,查询表的数据条数、表名、中文表名、
查询所有表名:select t.table_name from user_tables t;查询所有字段名:select t.column_name from user_col_comments t; ...
- sql server 按月对数据表进行分区
当某张数据表数据量较大时,我们就需要对该表进行分区处理,以下sql语句,会将数据表按月份,分为12个分区表存储数据,废话不多说,直接上脚本: use [SIT_L_TMS] --开启 XP_CMDSH ...
- 【转】Oracle 查询库中所有表名、字段名、表名说明、字段名说明
转自 :http://gis-conquer.blog.sohu.com/170243422.html 查询所有表名:select t.table_name from user_tables t; 查 ...
随机推荐
- 痞子衡嵌入式:基于恩智浦i.MXRT1060的MP4视频播放器(RT-Mp4Player)设计
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是基于i.MXRT1062的MP4播放器参考设计. i.MXRT1062是恩智浦i.MXRT四位数系列的中端型号,外设搭配上很均衡,辅以6 ...
- Positions of Large Groups
Positions of Large Groups In a string S of lowercase letters, these letters form consecutive groups ...
- 自动化测试之Selenium篇(一):环境搭建
当前无论找工作或者是实际项目应用,自动化测试扮演着非常重要的角色,今天我们来学习下Selenium的环境搭建 Selenium简述 Selenium是一个强大的开源Web功能测试工具系列 可进行读入测 ...
- 安装jdk及安装多版本jdk
目录 由于要使用多个版本jdk,所以看下如何在一台电脑安装多个版本jdk 当然,如果你只需要安装一个jdk,本文也适合你,只需要在JAVA_HOME值填你jdk安装的目录即可 一.首先安装好不同的jd ...
- [Codeforces 553E]Kyoya and Train(期望DP+Floyd+分治FFT)
[Codeforces 553E]Kyoya and Train(期望DP+Floyd+分治FFT) 题面 给出一个\(n\)个点\(m\)条边的有向图(可能有环),走每条边需要支付一个价格\(c_i ...
- 执行 yarn init报错,如何解决?
安装yarn以后执行yarn init 命令来初始化项目 报错如下所示: 解决方法: 1.先用npm init初始化项目 在初始化的最后一步 is this ok(yes)? 输入yes回车后,可能会 ...
- margin的讲究
什么元素允许有margin值,无论块状元素还是行内元素都可以,只是各有限制. 先说行内元素,这个是不允许有上下 外边距的, 再说块状元素,上下左右外边距都允许 但是相邻元素的外边距会合并,要注意的是 ...
- gcc编译链接用到的环境变量
PATH ---- 可执行程序寻找路径 C_INCLUDE_PATH ---- 头文件寻找路径 CPLUS_INCLUDE_PATH --- g++ 头文件路径 LD_LIBRARY_PATH ...
- mysql8.0参考手册学习
mysql8.0参考手册链接:https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html#optimizer-hints-join-ord ...
- Linux(CentOS6.8)配置ActiveMQ
1.下载ActiveMQ http://activemq.apache.org/ 注:若是想下载老版本的ActiveMQ可以通过以下链接下载 http://activemq.apache.org/do ...