MYSQL学习(二) --MYSQL框架
MYSQL架构理解
通过对MYSQL重要的几个属性的理解,建立一个基本的MYSQL的知识框架。后续再补充完善。
一、MYSQL架构
这里给的架构描述,是很宏观的架构。有助于建立对MYSQL整体理解。
1. 架构图
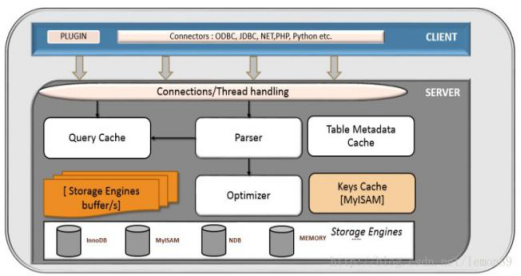
以下是在网上找的两张MYSQL架构图。能反映MYSQL的结构。
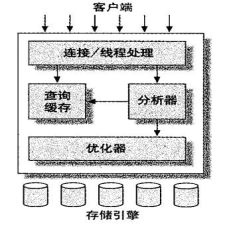
结构基本一致,都是连接、服务和存储引擎三部分。
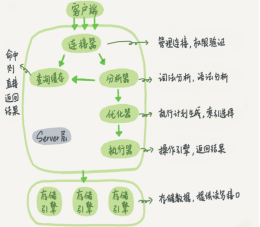
2.分层实现
MYSQL大致分为3个层次。连接层、服务层和引擎层。连接层功能是客户端的链接服务。服务层完成缓存查询、SQL分析、SQL优化。引擎层真正负责MYSQL数据的存储和提取。
1.连接层
核心功能是完成客户端的链接安全服务。负责一些连接处理、授权认证以及相关安全方案。该层提供了线程池功能。为通过安全认证的客户端提供线程。
验证主要是用户名、密码的验证。
2.服务层
服务层提供的服务包括查询的解析、分析(语法、语义)、优化(SQL)、缓存查询、内置函数(日期、数学、时间、加密)、跨存储引擎的功能(存储过程、触发器、视图)等。
3.引擎层
存储引擎层主要负责数据的存储和提取。服务器通过API和引擎层进行通信。
核心需要了解的引擎有InnoDB和MyISAM两种引擎。绝大多数情况下都选择使用使用InnoDB引擎。
- InnoDB:支持事务、支持行表锁(高并发友好-行锁更好的支持并发)、支持主外键、不支持全文检索。
- MyISAM:支持全文检索、不支持事务、只支持表锁(对并发不好--操作一条数据就需要锁住整张表)。
3.查询组件
按照查询过程,描述各组件的功能。
1.连接器
管理数据库链接、权限验证。
2.用户权限是链接时刻的用户权限
一个用户成功建立
连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
- 链接
链接过程比较麻烦,通常使用长链接。
(1) 长链接
如果客户端和服务端链接上之后,客户端有持续的请求,则一直使用同一个链接。
长链接缺点:容易占用内存。在执行语句中使用的内存是管理在链接对象中的。这些资源只有在断开链接的使用才能释放。如果长链接时间较长,可能积累的内存很大,造成内存溢出。解决思路(定期断开重连)。
(2)短链接
连接后执行SQL之后,断开链接,下次使用时,重新链接。
2.查询缓存
核心思想就是看,缓存中是否存在刚刚查询过和当前一样的SQL。如果存在,则直接使用缓存数据返回。如果不存在,才执行后续的查询步骤。缺点是:适合于静态表。如果是动态表,数据实时发生变化。查询以前的缓存数据不准确。
- 查询缓存
建立链接后,首先是在内存中查询,看之前是否执行过这条语句。之前执行过的语句可能以KEY-VALUE的形式保存在内存中。KEY为查询的语句。VALUE是查询的结果。
(1)缓存存在
直接将缓存的数据返回给客户端。
(2)缓存不存在
执行后面的阶段。
3.分析器
将SQL的字符串转成语法树。过程包含词法解析和语法解析。
(1)词法解析
识别字符串中的SQL关键字和函数关键字。
(2)语法解析
在词法分析基础之上,生成语法树。可以向后提交给优化器。
4.优化器
优化器对语法树进行进一步优化,给出更合理的执行计划。从而提高SQL的执行效率。
比如:多个表JOIN的时候,决定表的关联顺序。多个索引时,选择使用哪个索引。
5.执行器
经过优化器优化后的语句,进入执行器阶段。开始执行语句。
(1)判断权限
判断用户有没有对表操作的权限。如果没有,则直接返回该用户没有权限错误。如果有,就继续执行。
(2)调用引擎API,继续执行
打开表,执行器会根据表的引擎定义,去执行这个引擎提供的接口。
二、并发控制
当多个线程,同时修改同一张表的数据的时候,就需要并发控制。MYSQL在两个级别实现并发控制。服务器级(the server level)和存储引擎级(the storage engine level)。加锁实现并发控制。对锁从不同的角度分析,尽量减小锁对并发的影响。从提升并发性能的角度来分析的。
(一)、尽小可能使用互斥,尽大可能使用共享
互斥是实现同步的一种方式。也是代价比较大的一种。对并发性能影响较大。因此,对锁分为共享锁和互斥锁。也是经常说的读锁和写锁。根据不同的情况,在保证正确性的前提下,尽可能使用共享锁(读锁)。
1.读锁(共享锁)
读锁允许多个连接,并发的读取统一资源,互不干涉。读锁之间是共享的。不互斥。
2.写锁(互斥锁、排它锁)
一个写锁阻塞其它写锁和读锁。保证同一时刻只有一个连接写入数据。同时,防止其它用户对这个数据进行读写。
(二)、 力度(尽小范围加锁)
在满足逻辑正确的情况下。加锁范围越小,产生阻塞的可能性越小。并发的性能就越高。因此。从这个角度来分析MYSQL的锁机制。MYSQL中分为表锁和行级锁。
1.表锁
表锁是用户操作的过程中对整张表锁定。只允许一个用户对表进行操作(插入、删除、更新)。MYSQL独立于存储引擎提供表锁,例如,对于ALTER TABLE语句,服务器提供表锁(table-level lock)。
表锁是MYSQL基本的锁策略。也是开销最小的锁策略(因为简单可行)。
2.行级锁
最大程度的支持并发处理。InnoDB支持行级锁。指锁定需要的几行数据即可。也是开销最大的所策略(需要精确的控制,代价很大)。
(三)、 多版本控制
多版本控制的核心是 读事务不用等待锁。从而更加提升了性能。MYSQL的MVCC的实现逻辑。
通过在每行数据后添加两个隐藏列来实现。一个是创建时间,一个死过期时间(删除时间)。这两个列存储的是系统版本号(版本号的大小体现时间的先后顺序)。每开始一个新的事务,版本号都会增加。事务开始时刻的版本号作为这个事务的版本号。
MVCC的具体操作,InnoDB引擎为例
(1)INSERT
插入每行数据,创建时间为当前的系统版本号
(2)DELETE
删除每行数据,保存当前系统版本号为删除时间。
(3)UPDATE
插入一行新数据。当前系统版本号为创建时间。另外,当前版本号为原来行的删除时间
(4)SELECT
读操作不需要等待其它锁
查询的时候,需要满足一下两个条件的数据。
- 只需要找创建时间小于或等于当前版本号的数据。(这样能确保事务读取的行,要么在事务开始之前就已经存在,要么是事务自身插入或者修改的)
- 行的删除时间,要么未定义,要么大于当前版本。
符合以上两个条件的记录,才能作为查询结果。
三、 事务
数据库的事务处理原则是ACID的正确性。
(一)、事务的ACID属性
1.原子性
一个事务被视为最小的工作单元,整个事务所有操作,要么都执行,要么全部回滚,都不执行。不能执行其中的一部分,任务不能分割。
2.一致性
符合逻辑,从一个一致性状态转换到另一个一致性状态。
3.隔离性
提供一定的隔离机制,保证事务在运行过程中不受外部并发操作的影响。一个事务所做的修改,在提交之前,对其它事务不可见。
4.持久性
一旦事务提交,其所做的修改就会保存到数据库中。即事务提交后,对数据的修改是永久性的。
(二)、 隔离级别
隔离规定了,一个事务所做的修改,那些在事务内部和事务间是可见的,那些是不可见的。较低级别的隔离通常可以执行较高的并发。系统的开销更低。
1.未提交读 REDA UNCOMMITED
事务中的修改,即使没有提交,对其它事务也都是可见的。
这种情况下,容易造成脏读。
2.提交读 READ COMMITED
一个事务中的修改,只有在事务提交之后,对其它事务才可见。换句话说,一个事务的修改,在其提交之前,对其余事务是不可见的。
这个级别满足隔离性的定义,也称为不可重复读。因为,即使在一个事务中,重复两次查询,可能得到不一样的结果。
3.可重复读 REPEATABLE READ
同一个事务中,多次读取,记录结果是一致的(因为同一个事务,版本号是一样的,有版本号控制,能够保证,多次查询结果是一致的)。重复读能解决脏读的问题。
可重复读是MYSQL默认的隔离级别。
4.可串行化 SERIALIZABLE
是隔离的最高级别。强制要求事务串行执行。是加锁读。

(三)、 死锁
两个或多个事务,在同一资源上相互占用。并请求占用对方占用的资源。
(四)、MYSQL中的事务
MYSQL默认为自动提交(AUTOCOMMIT)。
1.自动提交
如果不是显示的提交一个事务(START TRANSACTION ---COMMIT),每个查询都会作为一个事务提交。
参数设置:set autocommit = 1;
2.手动提交
所有的查询都是在一个事务中,直至显示的执行commit提交或者rollback回滚,该事务才结束。
参数设置: set autocommit = 0;
(五)、 事务处理的几个问题
由于事务的并发执行,带来以下一些著名的问题:
1.更新丢失(Lost Update)
当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题--最后的更新覆盖了由其他事务所做的更新。
2.脏读(Dirty Reads)
一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些"脏"数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做"脏读"。
3.不可重复读(Non-Repeatable Reads)
一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做"不可重复读"。
4.幻读(Phantom Reads)
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为"幻读"。
四、引擎
数据库中的引擎是真正执行SQL的组件,被MYSQL集成在内部。MYSQL是一个多引擎的数据库管理系统。核心的有InnoDB(默认引擎)和MyISAM。
(一)、 InnoDB
MYSQL默认的存储引擎。最大的特点是支持事务、支持行级锁,因此能支持高并发的访问。不支持全文索引。索引是基于聚簇索引建立的。对主键的查询有很高的性能。
(二)、MyISAM
MYSQL5之前的默认存储引擎。最大的特点是支持全文索引。但是,不支持事务,支持表锁。并发支持性不好。
MYSQL学习(二) --MYSQL框架的更多相关文章
- MySQL学习(二)——MySQL多表
分页操作:使用limit(参数1,参数2) 起始位置(参数1))*每页显示的条数(参数2) .分类表 create table category( cid ) primary key, cname ) ...
- Spring Boot 项目学习 (二) MySql + MyBatis 注解 + 分页控件 配置
0 引言 本文主要在Spring Boot 基础项目的基础上,添加 Mysql .MyBatis(注解方式)与 分页控件 的配置,用于协助完成数据库操作. 1 创建数据表 这个过程就暂时省略了. 2 ...
- MySQL学习笔记-MySQL体系结构总览
MySQL体系结构总览 不管是用哪种数据库,了解数据库的体系结构都是极为重要的.MySQL体系结构主要由数据库和数据库实例构成. 数据库:物理操作系统文件或者其它文件的集合,在mysql中,数据库文件 ...
- 基于【 MySql 】二 || mysql详细学习笔记
mysql重点学习笔记 /* Windows服务 */ -- 启动MySQL net start mysql -- 创建Windows服务 sc create mysql binPath= mysql ...
- MySQL学习(4)---MySQL索引
ps:没有特殊说明,此随笔中默认采用innoDB存储引擎中的索引,且索引都是指B+树(多路平衡搜索树)结构组织的索引.其中聚集索引.复合索引.前缀索引.唯一索引默认都是使用B+树,统称为索引. 索引概 ...
- 我的MYSQL学习心得 mysql的权限管理
这一篇<我的MYSQL学习心得(十三)>将会讲解MYSQL的用户管理 在mysql数据库中,有mysql_install_db脚本初始化权限表,存储权限的表有: 1.user表 2.db表 ...
- 我的MYSQL学习心得 mysql日志
这一篇<我的MYSQL学习心得(十五)>将会讲解MYSQL的日志 MYSQL里的日志主要分为4类,使用这些日志文件,可以查看MYSQL内部发生的事情. 分别是 1.错误日志:记录mysql ...
- MySQL学习(1)---MySQL概述
什么是数据库 概述 数据库(Database)是长期存储在计算机内有组织.大量.共享的数据集合.它可以供各种用户共享,具有最小冗余度和较高的数据独立性.数据库管理系统DBMS(Database Man ...
- MySQL学习11 - MySQL创建用户和授权
权限管理 权限管理 我们知道我们的最高权限管理者是root用户,它拥有着最高的权限操作.包括select.update.delete.update.grant等操作.那么一般情况在公司之后DBA工程师 ...
- MySQL学习笔记——MySQL启动过程(一)
首先去官网或者github下载MySQL5.7的源码. 官网地址:https://dev.mysql.com/downloads/mysql/ github地址:https://github.com/ ...
随机推荐
- cp命令:复制文件和目录
cp命令:复制文件和目录 [功能说明] cp命令可以理解英文单词copy的缩写,其功能为复制文件和目录. [语法格式] 1 cp [option] [source] [dest] 2 cp [选项] ...
- Vue 学习 二 路由详解
1 roter-link 和roter-view组件 2路由配置 a.动态路由 b.嵌套路由 c.别名路由 d.命名路由 3 Js操作路由 4 重定向和别名 1为路由默认绑定 2 使用组件 根据 路由 ...
- 小试牛刀-hello,world!(第一个程序)
1.打开python的IDLE,启动Python解释器(按键盘的windows键,然后输入IDLE),在提示符下>>>输入命令:print("hello,world!&qu ...
- 多测师讲解自动化测试 _RF关键字001_(上)_高级讲师肖sir
讲解案例1: Open Browser http://www.baidu.com gc #打开浏览器 Maximize Browser Window #窗口最大化 sleep 2 #线程等待2秒 In ...
- K8S节点异常怎么办?TKE"节点健康检查和自愈"来帮忙
节点健康检测 意义 在K8S集群运行的过程中,节点常常会因为运行时组件的问题.内核死锁.资源不足等各种各样的原因不可用.Kubelet默认对节点的PIDPressure.MemoryPressure. ...
- web中的HTML CSS
HTML 超文本标记语言 页面的结构 首行声明文档类型>根标记>头部标记/主体标记 标记 div 布局 切割 分割 划分区域 spa ...
- 分布式锁结合SpringCache
1.高并发缓存失效问题: 缓存穿透: 指查询一个一定不存在的数据,由于缓存不命中导致去查询数据库,但数据库也无此记录,我们没有将此次查询的null写入缓存,导致这个不存在的数据每次请求都要到存储层进行 ...
- Helium文档15-WebUI自动化-chromedriver问题
前言 helium库是自带chromedriver的,我们怎么来查看在哪里呢? 目录介绍 用我的电脑上的路径打比方如下: D:\Program Files (x86)\Python38\Lib\sit ...
- RPM与YUM使用
1.RPM 1.1RPM简介 RPM全名RedHat Package Manager 优点: 1. 由于已经编译完成并且打包完毕,所以软件传输与安装上很方便 (不需要再重新编译): 2. 由于软件的信 ...
- CTCall简介(后续会继续补充)
使用CTCall需要导入CoreTelephony.framework框架. CTCall的基本使用 (1)初始化call CFStringRef number = CFSTR("15555 ...