Spark Pipeline官方文档
ML Pipelines(译文)
官方文档链接:https://spark.apache.org/docs/latest/ml-pipeline.html
概述
在这一部分,我们将要介绍ML Pipelines,它提供了基于DataFrame上统一的高等级API,可以帮助使用者创建和调试机器学习工作流;
目录:
- Pipelines中主要的概念:
- DataFrame
- Pipeline组件
- Transformers:转换器
- Estimators:预测器
- Pipelines组件属性
- Pipeline
- 如何工作
- 细节
- 参数
- 机器学习持久化:保存和加载Pipelines
- 机器学习持久化的向后兼容性
- 示例代码:
- 例子:预测器、转换器和参数
- 例子:Pipeline
- 模型选择(超参数调试)
Pipelines中的主要概念
MLlib中机器学习算法相关的标准API使得其很容易组合多个算法到一个pipeline或者工作流中,这一部分包括通过Pipelines API介绍的主要概念,以及是从sklearn的哪部分获取的灵感;
- DataFrame:这个ML API使用Spark SQL中的DataFrame作为ML数据集来持有某一种数据类型,比如一个DataFrame可以有不同类型的列:文本、向量特征、标签和预测结果等;
- Transformer:转换器是一个可以将某个DataFrame转换成另一个DataFrame的算法,比如一个ML模型就是一个将DataFrame转换为原DataFrame+一个预测列的新的DataFrame的转换器;
- Estimator:预测器是一个可以fit一个DataFrame得到一个转换器的算法,比如一个学习算法是一个使用DataFrame并训练得到一个模型的预测器;
- Pipeline:一个Pipeline链使用多个转换器和预测器来指定一个机器学习工作流;
- Parameter:所有的转换器和预测器通过一个通用API来指定其参数;
DataFrame
机器学习可以作用于很多不同的数据类型,比如向量、文本、图像和结构化数据等,DataFrame属于Spark SQL,支持多种数据类型;
DataFrame支持多种基础和结构化数据;
一个DataFrame可以通过RDD创建;
DataFrame中的列表示名称,比如姓名、年龄、收入等;
Pipeline组件
Transformers - 转换器
转换器是包含特征转换器和学习模型的抽象概念,严格地说,转换器需要实现transform方法,该方法将一个DataFrame转换为另一个DataFrame,通常这种转换是通过在原基础上增加一列或者多列,例如:
- 一个特征转换器接收一个DataFrame,读取其中一列(比如text),将其映射到一个新的列上(比如feature vector),然后输出一个新的DataFrame包含映射得到的新列;
- 一个学习模型接收一个DataFrame,读取包含特征向量的列,为每个特征向量预测其标签值,然后输出一个新的DataFrame包含标签列;
Estimators - 预测器
一个预测器是一个学习算法或者任何在数据上使用fit和train的算法的抽象概念,严格地说,一个预测器需要实现fit方法,该方法接收一个DataFrame并产生一个模型,该模型实际上就是一个转换器,例如,逻辑回归是一个预测器,调用其fit方法可以得到一个逻辑回归模型,同时该模型也是一个转换器;
Pipeline组件属性
转换器的transform和预测器的fit都是无状态的,未来可能通过其他方式支持有状态的算法;
每个转换器或者预测器的实例都有一个唯一ID,这在指定参数中很有用;
Pipeline
在机器学习中,运行一系列的算法来处理数据并从数据中学习是很常见的,比如一个简单的文档处理工作流可能包含以下几个步骤:
- 将每个文档文本切分为单词集合;
- 将每个文档的单词集合转换为数值特征向量;
- 使用特征向量和标签学习一个预测模型;
MLlib提供了工作流作为Pipeline,包含一系列的PipelineStageS(转换器和预测器)在指定顺序下运行,我们将使用这个简单工作流作为这一部分的例子;
如何工作
一个Pipeline作为一个特定的阶段序列,每一阶段都是一个转换器或者预测器,这些阶段按顺序执行,输入的DataFrame在每一阶段中都被转换,对于转换器阶段,transform方法作用于DataFrame,对于预测器阶段,fit方法被调用并产生一个转换器(这个转换器会成功Pipeline模型的一部分或者fit pipeline),该转换器的transform方法同样作用于DataFrame上;
下图是一个使用Pipeline的简单文档处理工作流:
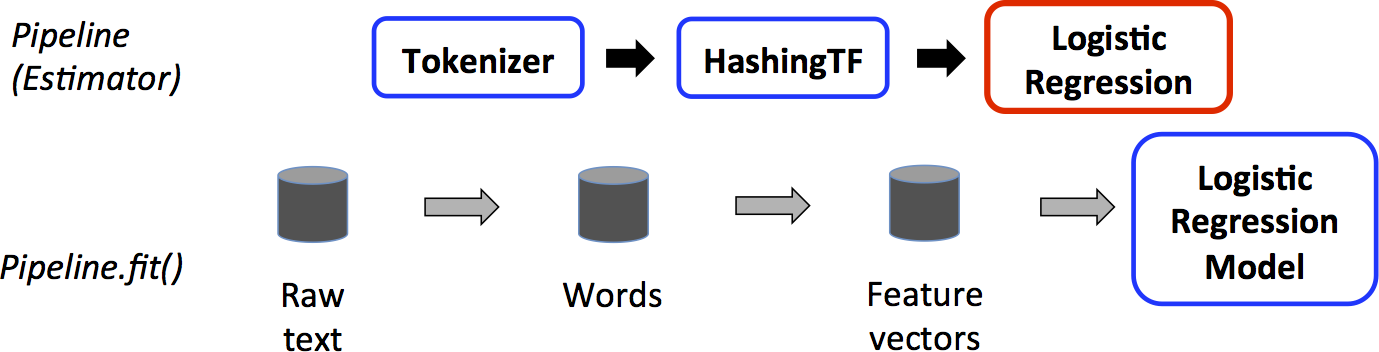
上图中,上面一行表示一个包含三个阶段的Pipeline,Tokenizer和HashingTF为转换器(蓝色),LogisticRegression为预测器(红色),下面一行表示数据流经过整个Pipeline,圆柱体表示DataFrame,Pipeline的fit方法作用于包含原始文本数据和标签的DataFrame,Tokenizer的transform方法将原始文本文档分割为单词集合,作为新列加入到DataFrame中,HashingTF的transform方法将单词集合列转换为特征向量,同样作为新列加入到DataFrame中,目前,LogisticRegression是一个预测器,Pipeline首先调用其fit方法得到一个LogisticRegressionModel,如果Pipeline中还有更多预测器,那么就会在进入下一个阶段前先调用LogisticRegressionModel的transform方法(此时该model就是一个转换器);
一个Pipeline就是一个预测器,因此,在Pipeline的fit方法运行后会产生一个PipelineModel,同样是一个转换器,这个PipelineModel在测试时间使用,下图介绍了该阶段:
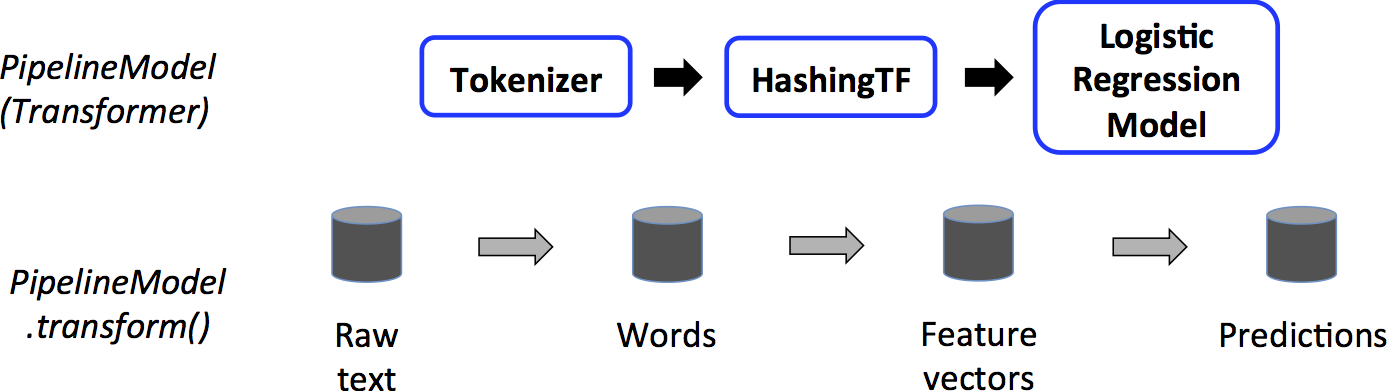
上图中,PipelineModel与原Pipeline有同样数量的阶段,但是原Pipeline中所有的预测器都变成了转换器,当PipelineModel的tranform方法在测试集上调用时,数据将按顺序经过被fit的Pipeline,每个阶段的transform方法将更新DataFrame并传递给下一个阶段;
Pipeline和PipelineModel帮助确定训练和测试数据经过完全一致的特征处理步骤;
细节
DAG Pipeline(有向无环图Pipeline):一个Pipeline的各个阶段被指定作为一个顺序数组,之前的例子都是线性的Pipeline,即每个阶段使用的数据都是前一个阶段提供的,只要数据流图来自于DAG,那么是有可能创建非线性的Pipeline的,这个图是当前指定的基于每个阶段的输入输出列名(通常作为参数指定),如果Pipeline来自DAG,那么各个阶段必须符合拓扑结构顺序;
运行时检查:由于Pipeline可以操作DataFrame可变数据类型,因此它不能使用编译期类型检查,Pipeline和PipelineModel在真正运行会进行运行时检查,这种类型的检查使用DataFrame的schema,schema是一种对DataFrmae中所有数据列数据类型的描述;
唯一Pipeline阶段:一个Pipeline阶段需要是唯一的实例,比如同一个实例myHashingTF不能两次添加到Pipeline中,因为每个阶段必须具备唯一ID,然而,不同的类的实例可以添加到同一个Pipeline中,比如myHashingTF1和myHashingTF2,因为这两个对象有不同的ID,这里的ID可以理解为对象的内容地址,所以myHashingTF2=myHashingTF1也是不行的哈;
参数
MLlib预测器和转换器使用统一API指定参数;
一个参数是各个转换器和预测器自己文档中命名的参数,一个参数Map就是参数的k,v对集合;
这里有两种主要的给算法传参的方式:
- 为一个实例设置参数,比如如果lr是逻辑回归的实例对象,可以通过调用lr.setMaxIter(10)指定lr.fit()最多迭代10次,这个API与spark.mllib包中的类似;
- 传一个参数Map给fit和transform方法,参数Map中的任何一个参数都会覆盖之前通过setter方法指定的参数;
参数属于转换器和预测器的具体实例,例如,如果我们有两个逻辑回归实例lr1和lr2,然后我们创建一个参数Map,分别指定两个实例的maxIter参数,将会在Pipeline中产生两个参数不同的逻辑回归算法;
机器学习持久化:保存和加载Pipeline
大多数时候为了之后使用将模型或者pipeline持久化到硬盘上是值得的,在Spark 1.6,一个模型的导入/导出功能被添加到了Pipeline的API中,截至Spark 2.3,基于DataFrame的API覆盖了spark.ml和pyspark.ml;
机器学习持久化支持Scala、Java和Python,然而R目前使用一个修改后的格式,因此R存储的模型只能被R加载,这个问题将在未来被修复;
机器学习持久化的向后兼容性
通常来说,MLlib为持久化保持了向后兼容性,即如果你使用某个Spark版本存储了一个模型或者Pipeline,那么你就应该可以通过更新的版本加载它,然而依然有小概率出现异常;
模型持久话:模型或者Pipeline是否通过Spark的X版本存储模型,通过Spark的Y版本加载模型?
- 主版本:不保证兼容,但是会尽最大努力保持兼容;
- 次版本和patch版本:保证向后兼容性;
- 格式提示:不保证有一个稳定的持久化格式,但是模型加载是通过向后兼容性决定的;
模型行为:模型或Pipeline是否在Spark的X版本和Y版本具有一致的行为?
- 主版本:不保证,但是会尽最大努力保证一致;
- 次版本和patch版本:行为一致,除非是为了修复bug;
为了模型持久化和模型行为,任何破坏兼容性和一致性的次版本或者patch都会在版本更新笔记中报告出来,如果一个改变没有被报告,那么它应该是为了修复bug出现的;
示例代码
这部分针对上述讨论的内容给出代码示例,更多相关信息,可以查看API文档(Scala、Java、Python);
例子:预测器、转换器和参数
这个例子包含预测器、转换器和参数的主要概念;
Scala:
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.sql.Row
// Prepare training data from a list of (label, features) tuples.
val training = spark.createDataFrame(Seq(
(1.0, Vectors.dense(0.0, 1.1, 0.1)),
(0.0, Vectors.dense(2.0, 1.0, -1.0)),
(0.0, Vectors.dense(2.0, 1.3, 1.0)),
(1.0, Vectors.dense(0.0, 1.2, -0.5))
)).toDF("label", "features")
// Create a LogisticRegression instance. This instance is an Estimator.
val lr = new LogisticRegression()
// Print out the parameters, documentation, and any default values.
println(s"LogisticRegression parameters:\n ${lr.explainParams()}\n")
// We may set parameters using setter methods.
lr.setMaxIter(10)
.setRegParam(0.01)
// Learn a LogisticRegression model. This uses the parameters stored in lr.
val model1 = lr.fit(training)
// Since model1 is a Model (i.e., a Transformer produced by an Estimator),
// we can view the parameters it used during fit().
// This prints the parameter (name: value) pairs, where names are unique IDs for this
// LogisticRegression instance.
println(s"Model 1 was fit using parameters: ${model1.parent.extractParamMap}")
// We may alternatively specify parameters using a ParamMap,
// which supports several methods for specifying parameters.
val paramMap = ParamMap(lr.maxIter -> 20)
.put(lr.maxIter, 30) // Specify 1 Param. This overwrites the original maxIter.
.put(lr.regParam -> 0.1, lr.threshold -> 0.55) // Specify multiple Params.
// One can also combine ParamMaps.
val paramMap2 = ParamMap(lr.probabilityCol -> "myProbability") // Change output column name.
val paramMapCombined = paramMap ++ paramMap2
// Now learn a new model using the paramMapCombined parameters.
// paramMapCombined overrides all parameters set earlier via lr.set* methods.
val model2 = lr.fit(training, paramMapCombined)
println(s"Model 2 was fit using parameters: ${model2.parent.extractParamMap}")
// Prepare test data.
val test = spark.createDataFrame(Seq(
(1.0, Vectors.dense(-1.0, 1.5, 1.3)),
(0.0, Vectors.dense(3.0, 2.0, -0.1)),
(1.0, Vectors.dense(0.0, 2.2, -1.5))
)).toDF("label", "features")
// Make predictions on test data using the Transformer.transform() method.
// LogisticRegression.transform will only use the 'features' column.
// Note that model2.transform() outputs a 'myProbability' column instead of the usual
// 'probability' column since we renamed the lr.probabilityCol parameter previously.
model2.transform(test)
.select("features", "label", "myProbability", "prediction")
.collect()
.foreach { case Row(features: Vector, label: Double, prob: Vector, prediction: Double) =>
println(s"($features, $label) -> prob=$prob, prediction=$prediction")
}
Java:
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.classification.LogisticRegression;
import org.apache.spark.ml.classification.LogisticRegressionModel;
import org.apache.spark.ml.linalg.VectorUDT;
import org.apache.spark.ml.linalg.Vectors;
import org.apache.spark.ml.param.ParamMap;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
// Prepare training data.
List<Row> dataTraining = Arrays.asList(
RowFactory.create(1.0, Vectors.dense(0.0, 1.1, 0.1)),
RowFactory.create(0.0, Vectors.dense(2.0, 1.0, -1.0)),
RowFactory.create(0.0, Vectors.dense(2.0, 1.3, 1.0)),
RowFactory.create(1.0, Vectors.dense(0.0, 1.2, -0.5))
);
StructType schema = new StructType(new StructField[]{
new StructField("label", DataTypes.DoubleType, false, Metadata.empty()),
new StructField("features", new VectorUDT(), false, Metadata.empty())
});
Dataset<Row> training = spark.createDataFrame(dataTraining, schema);
// Create a LogisticRegression instance. This instance is an Estimator.
LogisticRegression lr = new LogisticRegression();
// Print out the parameters, documentation, and any default values.
System.out.println("LogisticRegression parameters:\n" + lr.explainParams() + "\n");
// We may set parameters using setter methods.
lr.setMaxIter(10).setRegParam(0.01);
// Learn a LogisticRegression model. This uses the parameters stored in lr.
LogisticRegressionModel model1 = lr.fit(training);
// Since model1 is a Model (i.e., a Transformer produced by an Estimator),
// we can view the parameters it used during fit().
// This prints the parameter (name: value) pairs, where names are unique IDs for this
// LogisticRegression instance.
System.out.println("Model 1 was fit using parameters: " + model1.parent().extractParamMap());
// We may alternatively specify parameters using a ParamMap.
ParamMap paramMap = new ParamMap()
.put(lr.maxIter().w(20)) // Specify 1 Param.
.put(lr.maxIter(), 30) // This overwrites the original maxIter.
.put(lr.regParam().w(0.1), lr.threshold().w(0.55)); // Specify multiple Params.
// One can also combine ParamMaps.
ParamMap paramMap2 = new ParamMap()
.put(lr.probabilityCol().w("myProbability")); // Change output column name
ParamMap paramMapCombined = paramMap.$plus$plus(paramMap2);
// Now learn a new model using the paramMapCombined parameters.
// paramMapCombined overrides all parameters set earlier via lr.set* methods.
LogisticRegressionModel model2 = lr.fit(training, paramMapCombined);
System.out.println("Model 2 was fit using parameters: " + model2.parent().extractParamMap());
// Prepare test documents.
List<Row> dataTest = Arrays.asList(
RowFactory.create(1.0, Vectors.dense(-1.0, 1.5, 1.3)),
RowFactory.create(0.0, Vectors.dense(3.0, 2.0, -0.1)),
RowFactory.create(1.0, Vectors.dense(0.0, 2.2, -1.5))
);
Dataset<Row> test = spark.createDataFrame(dataTest, schema);
// Make predictions on test documents using the Transformer.transform() method.
// LogisticRegression.transform will only use the 'features' column.
// Note that model2.transform() outputs a 'myProbability' column instead of the usual
// 'probability' column since we renamed the lr.probabilityCol parameter previously.
Dataset<Row> results = model2.transform(test);
Dataset<Row> rows = results.select("features", "label", "myProbability", "prediction");
for (Row r: rows.collectAsList()) {
System.out.println("(" + r.get(0) + ", " + r.get(1) + ") -> prob=" + r.get(2)
+ ", prediction=" + r.get(3));
}
Python:
from pyspark.ml.linalg import Vectors
from pyspark.ml.classification import LogisticRegression
# Prepare training data from a list of (label, features) tuples.
training = spark.createDataFrame([
(1.0, Vectors.dense([0.0, 1.1, 0.1])),
(0.0, Vectors.dense([2.0, 1.0, -1.0])),
(0.0, Vectors.dense([2.0, 1.3, 1.0])),
(1.0, Vectors.dense([0.0, 1.2, -0.5]))], ["label", "features"])
# Create a LogisticRegression instance. This instance is an Estimator.
lr = LogisticRegression(maxIter=10, regParam=0.01)
# Print out the parameters, documentation, and any default values.
print("LogisticRegression parameters:\n" + lr.explainParams() + "\n")
# Learn a LogisticRegression model. This uses the parameters stored in lr.
model1 = lr.fit(training)
# Since model1 is a Model (i.e., a transformer produced by an Estimator),
# we can view the parameters it used during fit().
# This prints the parameter (name: value) pairs, where names are unique IDs for this
# LogisticRegression instance.
print("Model 1 was fit using parameters: ")
print(model1.extractParamMap())
# We may alternatively specify parameters using a Python dictionary as a paramMap
paramMap = {lr.maxIter: 20}
paramMap[lr.maxIter] = 30 # Specify 1 Param, overwriting the original maxIter.
paramMap.update({lr.regParam: 0.1, lr.threshold: 0.55}) # Specify multiple Params.
# You can combine paramMaps, which are python dictionaries.
paramMap2 = {lr.probabilityCol: "myProbability"} # Change output column name
paramMapCombined = paramMap.copy()
paramMapCombined.update(paramMap2)
# Now learn a new model using the paramMapCombined parameters.
# paramMapCombined overrides all parameters set earlier via lr.set* methods.
model2 = lr.fit(training, paramMapCombined)
print("Model 2 was fit using parameters: ")
print(model2.extractParamMap())
# Prepare test data
test = spark.createDataFrame([
(1.0, Vectors.dense([-1.0, 1.5, 1.3])),
(0.0, Vectors.dense([3.0, 2.0, -0.1])),
(1.0, Vectors.dense([0.0, 2.2, -1.5]))], ["label", "features"])
# Make predictions on test data using the Transformer.transform() method.
# LogisticRegression.transform will only use the 'features' column.
# Note that model2.transform() outputs a "myProbability" column instead of the usual
# 'probability' column since we renamed the lr.probabilityCol parameter previously.
prediction = model2.transform(test)
result = prediction.select("features", "label", "myProbability", "prediction") \
.collect()
for row in result:
print("features=%s, label=%s -> prob=%s, prediction=%s"
% (row.features, row.label, row.myProbability, row.prediction))
例子:Pipeline
这个例子是基于上述的简单文本文档处理的例子;
Scala:
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// Prepare training documents from a list of (id, text, label) tuples.
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// Fit the pipeline to training documents.
val model = pipeline.fit(training)
// Now we can optionally save the fitted pipeline to disk
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// We can also save this unfit pipeline to disk
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
// And load it back in during production
val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model")
// Prepare test documents, which are unlabeled (id, text) tuples.
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// Make predictions on test documents.
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
Java:
import java.util.Arrays;
import org.apache.spark.ml.Pipeline;
import org.apache.spark.ml.PipelineModel;
import org.apache.spark.ml.PipelineStage;
import org.apache.spark.ml.classification.LogisticRegression;
import org.apache.spark.ml.feature.HashingTF;
import org.apache.spark.ml.feature.Tokenizer;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
// Prepare training documents, which are labeled.
Dataset<Row> training = spark.createDataFrame(Arrays.asList(
new JavaLabeledDocument(0L, "a b c d e spark", 1.0),
new JavaLabeledDocument(1L, "b d", 0.0),
new JavaLabeledDocument(2L, "spark f g h", 1.0),
new JavaLabeledDocument(3L, "hadoop mapreduce", 0.0)
), JavaLabeledDocument.class);
// Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
Tokenizer tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words");
HashingTF hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol())
.setOutputCol("features");
LogisticRegression lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001);
Pipeline pipeline = new Pipeline()
.setStages(new PipelineStage[] {tokenizer, hashingTF, lr});
// Fit the pipeline to training documents.
PipelineModel model = pipeline.fit(training);
// Prepare test documents, which are unlabeled.
Dataset<Row> test = spark.createDataFrame(Arrays.asList(
new JavaDocument(4L, "spark i j k"),
new JavaDocument(5L, "l m n"),
new JavaDocument(6L, "spark hadoop spark"),
new JavaDocument(7L, "apache hadoop")
), JavaDocument.class);
// Make predictions on test documents.
Dataset<Row> predictions = model.transform(test);
for (Row r : predictions.select("id", "text", "probability", "prediction").collectAsList()) {
System.out.println("(" + r.get(0) + ", " + r.get(1) + ") --> prob=" + r.get(2)
+ ", prediction=" + r.get(3));
}
Python:
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
# Prepare training documents from a list of (id, text, label) tuples.
training = spark.createDataFrame([
(0, "a b c d e spark", 1.0),
(1, "b d", 0.0),
(2, "spark f g h", 1.0),
(3, "hadoop mapreduce", 0.0)
], ["id", "text", "label"])
# Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.001)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
# Fit the pipeline to training documents.
model = pipeline.fit(training)
# Prepare test documents, which are unlabeled (id, text) tuples.
test = spark.createDataFrame([
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
], ["id", "text"])
# Make predictions on test documents and print columns of interest.
prediction = model.transform(test)
selected = prediction.select("id", "text", "probability", "prediction")
for row in selected.collect():
rid, text, prob, prediction = row
print("(%d, %s) --> prob=%s, prediction=%f" % (rid, text, str(prob), prediction))
模型选择(超参数调试)
机器学习Pipeline的一个巨大用处是调参,点击这里获取更多自动模型选择的相关信息;
Spark Pipeline官方文档的更多相关文章
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark Streaming官方文档学习--上
官方文档地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html Spark Streaming是spark ap ...
- Spark Streaming官方文档学习--下
Accumulators and Broadcast Variables 这些不能从checkpoint重新恢复 如果想启动检查点的时候使用这两个变量,就需要创建这写变量的懒惰的singleton实例 ...
- Spark监控官方文档学习笔记
任务的监控和使用 有几种方式监控spark应用:Web UI,指标和外部方法 Web接口 每个SparkContext都会启动一个web UI,默认是4040端口,用来展示一些信息: 一系列调度的st ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
- lda spark 代码官方文档
http://spark.apache.org/docs/1.6.1/mllib-clustering.html#latent-dirichlet-allocation-lda http://spar ...
- Spark官方文档 - 中文翻译
Spark官方文档 - 中文翻译 Spark版本:1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 引入Spark(Linki ...
- 别被官方文档迷惑了!这篇文章帮你详解yarn公平调度
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由@edwinhzhang发表于云+社区专栏 FairScheduler是yarn常用的调度器,但是仅仅参考官方文档,有很多参数和概念文 ...
- StackExchange.Redis 官方文档(六) PipelinesMultiplexers
原文:StackExchange.Redis 官方文档(六) PipelinesMultiplexers 流水线和复用 糟糕的时间浪费.现代的计算机以惊人的速度产生大量的数据,而且高速网络通道(通常在 ...
随机推荐
- 关于dubbo扩展点的一点分析
扩展点能力 能load class,这个class除了顶层接口class(在ExtensionLoader中对应type字段),还能load各实现类的class. 能创建instance. 能指定这个 ...
- 使用部分函数时并未include其所在头文件,但是能编译成功且能运行,为什么?
最近在看APUE,试了上面的一些例子,其中有个例子是使用getpid函数获取进程id,但是在我写demo时,并未引入其所在的头文件unistd.h,结果也能编译成功,也能运行,于是就琢磨下为啥. En ...
- 记一次mysql数据库被勒索(中)
背景在上一篇文章里面已经提过了. 现在面临的问题是nextcloud没有mysql数据库,用不起来了. 因为文件没丢,一种方法是启动新的mysql数据库,把文件重新提交一次. 为了程序员的面子,没有选 ...
- MongoDB最新4.2.7版本三分片集群修改IP实操演练
背景 重新组网,需要对现有MongoDB分片集群服务器的IP进行更改,因此也需要对MongoDB分片集群的IP也进行相应的更新,而MongoDB分片集群的IP修改不能单纯的通过配置来进行,需要一番折腾 ...
- Java中实现对集合中对象按中文首字母排序
有一个person对象如下: public class Person { private String id;private String nam; } 一个list集合如下: List<Emp ...
- 精讲响应式WebClient第4篇-文件上传与下载
本文是精讲响应式WebClient第4篇,前篇的blog访问地址如下: 精讲响应式webclient第1篇-响应式非阻塞IO与基础用法 精讲响应式WebClient第2篇-GET请求阻塞与非阻塞调用方 ...
- vs _ 用户代码片段 _ html模板
自定义模板:首选项 -> 用户代码片段 - >(如果没有自己创个)html.json t : 表示缩进 n:表示换行 ----------------------------------- ...
- Android自动化测试,5个必备的测试框架
Appium Appium是一个开源的移动测试工具,支持iOS和Android,它可以用来测试任何类型的移动应用(原生.网络和混合).作为一个跨平台的工具,你可以在不同的平台上运行相同的测试.为了实现 ...
- Python画图库Turtle库详解篇
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行 ...
- Webpack 入门指迷
大概算是一份教程吧, 只不过效果肯定不如视频演示之类的好..Webpack 最近在英文社区上经常看到, 留了心, 但进一步了解是通过下边的视频:视频: How Instagram.com Works, ...