数据标准化方法及其Python代码实现
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
常见的方法有:min-max标准化(Min-max normalization),log函数转换,atan函数转换,z-score标准化(zero-mena normalization,此方法最为常用),模糊量化法,均值归一化。本文只介绍min-max标准化、Z-score标准化方法、均值归一化、log函数转换、atan函数转换。
data = [1, 3, 4, 5, 2, 13, 23, 71, 11, 19, 9, 24, 38]
一、min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:

from __future__ import print_function, division # min-max标准化方法
data0 = [(x - min(data))/(max(data) - min(data)) for x in data]
二、Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:

from __future__ import print_function
import math # 均值
average = float(sum(data))/len(data) # 方差
total = 0
for value in data:
total += (value - average) ** 2 stddev = math.sqrt(total/len(data)) # z-score标准化方法
data1 = [(x-average)/stddev for x in data]
三、均值归一化
两种方式,以max为分母的归一化方法和以max-min为分母的归一化方法
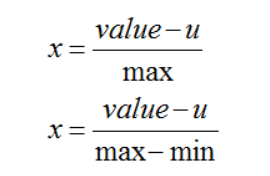
from __future__ import print_function # 均值
average = float(sum(data))/len(data) # 均值归一化方法
data2_1 = [(x - average )/max(data) for x in data] data2_2 = [(x - average )/(max(data) - min(data)) for x in data]
四、log函数转换方法
from __future__ import print_function import math # log2函数转换
data3_1 = [math.log2(x) for x in data] # log10函数转换
data3_2 = [math.log10(x) for x in data]
五、atan函数转换方法
from __future__ import print_function import math # atan函数转换方法
data4 = [math.atan(x) for x in data]
数据标准化方法及其Python代码实现的更多相关文章
- Z-Score数据标准化处理(python代码)
#/usr/bin/python def Z_Score(data): lenth = len(data) total = sum(data) ave = float(total)/lenth tem ...
- JQuery 获取json数据$.getJSON方法的实例代码
这篇文章介绍了JQuery 获取json数据$.getJSON方法的实例代码,有需要的朋友可以参考一下 前台: function SelectProject() { var a = new Array ...
- YoloV4当中的Mosaic数据增强方法(附代码详细讲解)码农的后花园
上一期中讲解了图像分类和目标检测中的数据增强的区别和联系,这期讲解数据增强的进阶版- yolov4中的Mosaic数据增强方法以及CutMix. 前言 Yolov4的mosaic数据增强参考了CutM ...
- 在代理中托管特殊方法的python代码实现
任务简单的介绍是: 在新风格对象模型中,Python操作其实是在类中查找特殊方法的(经典对象是在实例中进行操作的),现在需要将一些新风格的实例包装到代理中,,此代理可以选择将一些特殊的方法委托给内部的 ...
- 1.由于测试某个功能,需要生成500W条数据的txt,python代码如下
txt内容是手机号,数量500W,采用python代码生成,用时60S,本人技能有限,看官如果有更快的写法,欢迎留言交流. import random f = open("D:\\data. ...
- 优化Python代码的4种方法
介绍 作为数据科学家,编写优化的Python代码非常非常重要.杂乱,效率低下的代码即浪费你的时间甚至浪费你项目的钱.经验丰富的数据科学家和专业人员都知道,当我们与客户合作时,杂乱的代码是不可接受的. ...
- 用SVM处理XSS时,数据清洗打标数据标准化处理的方法和意义
def get_len(url): return len(url) def get_url_count(url): if re.search('(http://)|(https://)', url, ...
- 利用 pandas 进行数据的预处理——离散数据哑编码、连续数据标准化
数据的标准化 数据标准化就是将不同取值范围的数据,在保留各自数据相对大小顺序不变的情况下,整体映射到一个固定的区间中.根据具体的实现方法不同,有的时候会映射到 [ 0 ,1 ],有时映射到 0 附近的 ...
- 转:数据标准化/归一化normalization
转自:数据标准化/归一化normalization 这里主要讲连续型特征归一化的常用方法.离散参考[数据预处理:独热编码(One-Hot Encoding)]. 基础知识参考: [均值.方差与协方差矩 ...
随机推荐
- iOS UI调试工具 -- UIDebuggingInformationOverlay
英文原文: http://ryanipete.com/blog/ios/swift/objective-c/uidebugginginformationoverlay/ 无意中看到iOS自带调试工具 ...
- (转)移动端开发总结(一)视口viewport总结
转载链接:移动端开发中,关于适配问题的一点总结(一) 视口 布局视口layout viewport 视觉视口visual viewport 理想视口 缩放 一个重大区别 最小缩放 和最大缩放 分辨率 ...
- UART驱动分析
在linux用户层上要操作底层串口需要对/dev/ttySxxx操作,这里的ttySx指实际的终端串口. 以下以全志A64为实例,分析UART驱动以及浅谈TTY架构. linux-3.10/drive ...
- Base64加密算法
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法.可查看RFC2045-RFC2049,上面有MIME的详细规范. Ba ...
- FastAdmin 一键 CRUD 生成时方法不存在的问题分析
FastAdmin 一键 CRUD 生成时方法不存在的问题分析 有群友反馈 使用 一键 CRUD 生成时不成功. 我试了以下命令 php think crud -t test -u 1 是成功的. 再 ...
- windows下通过Git Bash使用Git常用命令
Git跟SVN最大不同的地方就是分布式.SVN的集中式与Git的分布式决定各自的业务场景.既然是分布式的,那么大部分操作就是本地操作.一般Git操作都是通过IDE,比如Eclipse,如果装了Git ...
- 用Toast来增加调试效率的小技巧
import android.content.Context; import android.widget.Toast; /** * Created by apple on 10/7/15. */ p ...
- Array数组(PHP学习)
什么是数组? 答:就是一组数. 数组的创建: <?php $Arr = array('姓名'=>'张三','身高'=>'174','家乡'=>'上海'); print_r($A ...
- php redis 常用方法
一些php redis 常用的方法: 1.hGet($key,$hashKey) Redis Hget 命令用于返回哈希表中指定字段的值. <?php $redis = new redis(); ...
- Fiddler2 模拟文件上传
最近遇到一个需求,需要上传音频文件, 服务端使用webService 通过spring3 进行文件上传.代码完成后使用 html 通过post 方式请求接口成功了,但不知道如何使用Fiddler2工具 ...