【Python3 爬虫】03_urllib.error异常处理
urllib.error可以接受来自urllib.request产生的异常。urllib.error有两个方法:①URLError ②HTTPError

URLError
URLError产生的原因
①网络无连接,即本机无法上网
②连接不到特定的服务器
③服务器不存在
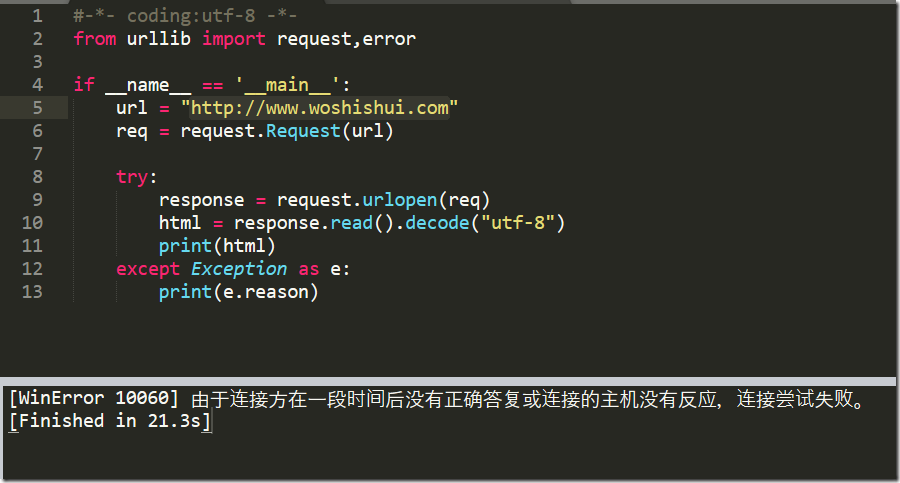
运行结果表明:连接超时
HTTPError
HTTPError是URLError的子类,在你利用URLopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中他包含一个数字“状态码”,例如response是一个重定向,需定位到别的地址获取文档,urllib将对此进行处理。
其他不能处理的,URLopen会产生一个HTTPError,对应相应的状态码,HTTP状态码表示HTTP协议所返回的响应的状态。状态码归结如下:
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304:请求的资源未更新 处理方式:丢弃
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复
HTTPError实例产生后会有一个code属性,这就是服务器发送的相关错误号。因为urllib可以为你处理重定向,也就是3开头的代号可以被处理,并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
下面我们写一个例子来感受一下,捕获的异常是HTTPError,它会带有一个code属性,就是错误代号,另外我们又打印了reason属性,这是它的父类URLError的属性。
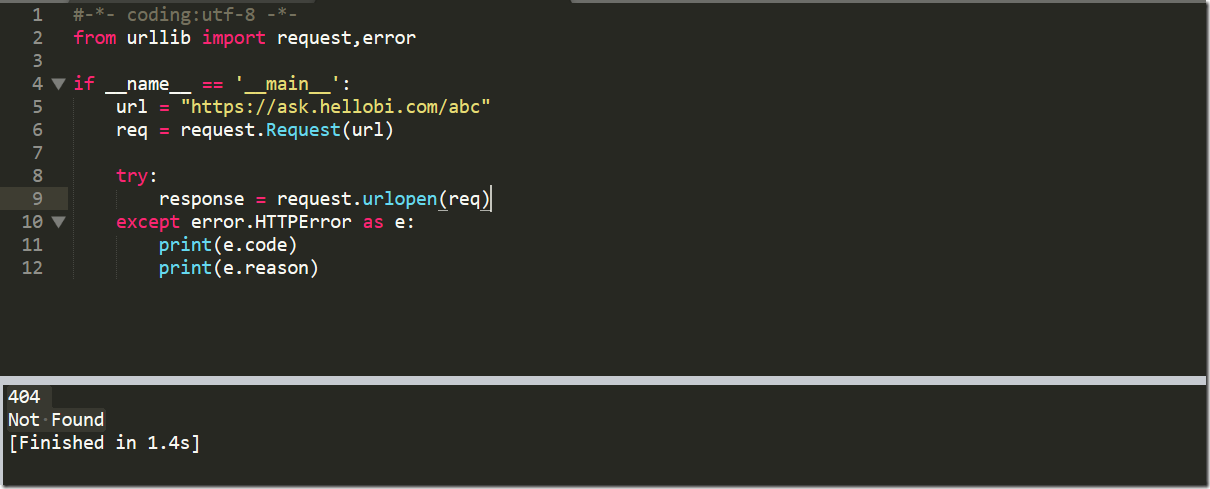
404
Not Found
结果分析:错误代码是404,错误原因是Not Found找不到网页
HTTPError与URLError一起使用
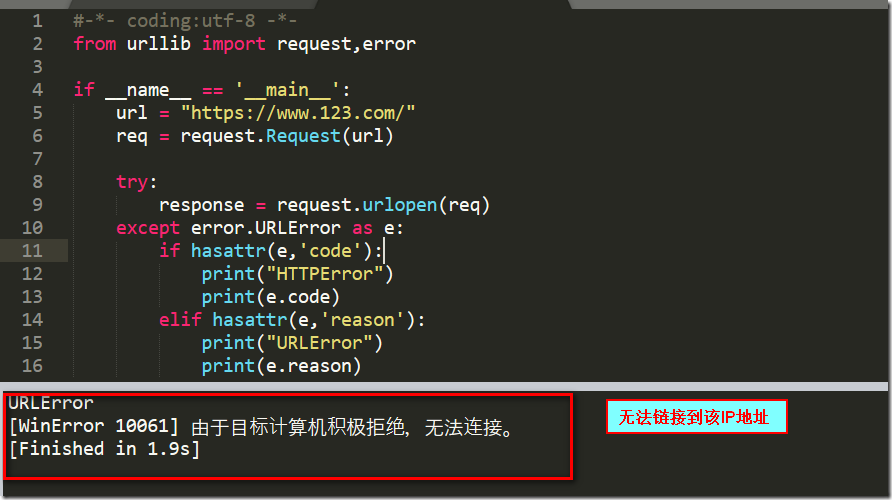
最后值得注意的一点是,如果想用HTTPError和URLError一起捕获异常,那么需要将HTTPError放在URLError的前面,因为HTTPError是URLError的一个子类。如果URLError放在前面,出现HTTP异常会先响应URLError,这样HTTPError就捕获不到错误信息了。
使用hasattr函数判断URLError含有的属性,如果含有reason属性表明是URLError,如果含有code属性表明是HTTPError
【Python3 爬虫】03_urllib.error异常处理的更多相关文章
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- Python3爬虫一之(urllib库)
urllib库是python3的内置HTTP请求库. ython2中urllib分为 urllib2.urllib两个库来发送请求,但是在python3中只有一个urllib库,方便了许多. urll ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- python3爬虫中文乱码之请求头‘Accept-Encoding’:br 的问题
当用python3做爬虫的时候,一些网站为了防爬虫会设置一些检查机制,这时我们就需要添加请求头,伪装成浏览器正常访问. header的内容在浏览器的开发者工具中便可看到,将这些信息添加到我们的爬虫代码 ...
- Python3 爬虫之 Scrapy 框架安装配置(一)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scr ...
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
随机推荐
- Unable to set localhost. This prevents creation of a GUID
原因:tomcat无法解析hostname 解决方案:解决方案:在/etc/hosts文件中添加hostname解析
- 7/26 CSU-ACM2018暑期训练3-递归&递推-选讲
题目链接 把M个同样的苹果放在N个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法?(用K表示)5,1,1和1,5,1 是同一种分法. Input 第一行是测试数据的数目t(0 <= ...
- 利用ipv6技术,废旧笔记本变成互联网server
如果你家的路由器已经get到了ipv6地址,并且你家的电脑也获取了有效的ipv6地址,在广域网的设备可以访问到.那恭喜你,再配合我这个ddns,你可以完美地把你家的电脑当服务器使用. 1.确保你家的宽 ...
- Codeforces #442 Div2 F
#442 Div2 F 题意 给出一些包含两种类型(a, b)问题的问题册,每本问题册有一些题目,每次查询某一区间,问有多少子区间中 a 问题的数量等于 b 问题的数量加 \(k\) . 分析 令包含 ...
- 【动态规划】矩形嵌套 (DGA上的动态规划)
[动态规划]矩形嵌套 时间限制: 1 Sec 内存限制: 128 MB提交: 23 解决: 9[提交][状态][讨论版] 题目描述 有n个矩形,每个矩形可以用a,b来描述,表示长和宽.矩形X(a, ...
- HTTP状态代码集
所有 HTTP 状态代码及其定义. 代码 指示 2xx 成功 200 正常:请求已完成. 201 正常:紧接 POST 命令. 202 正常:已接受用于处 ...
- java.sql.SQLException: Access denied for user ''@'localhost' (using password: No)
出错原因: 连接数据库是忘记配username 和 password 了 刚在学hiberbate4,把持久层从纯粹的jdbc改为hiberbate 出现的错误.(原来的是直接读取properties ...
- 【函数式权值分块】【分块】bzoj1901 Zju2112 Dynamic Rankings
论某O(n*sqrt(n))的带修改区间k大值算法. 首先对序列分块,分成sqrt(n)块. 然后对权值分块,共维护sqrt(n)个权值分块,对于权值分块T[i],存储了序列分块的前i块的权值情况. ...
- Java高级架构师(一)第26节:测试并调整登录的业务功能
主Index的处理Java: package com.sishuok.architecture1; import org.springframework.beans.factory.annotatio ...
- 语言基础之description方法
1.description方法的一般用处 1: // 指针变量的地址 2: NSLog(@"%p", &p); 3: // 对象的地址 4: NSLog(@"%p ...