python序列化_json,pickle,shelve模块
序列化
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes
- 把内存数据 转成字符,叫序列化
- 把字符 转成内存数据,叫反序列化
模块 json
json.dumps() 序列化一个对象
import json
data = {
'roles':[
{'role':'monster','type':'pig','life':50},
{'role':'hero','type':'关羽','life':80},
]
}
d = json.dumps(data) #转成字符串
print(type(d))
print(d)
打印结果:
<class 'str'>
{"roles": [{"role": "monster", "type": "pig", "life": 50}, {"role": "hero", "type": "\u5173\u7fbd", "life": 80}]}
json.lodads() 从一个对象加载数据
import json
data = {
'roles':[
{'role':'monster','type':'pig','life':50},
{'role':'hero','type':'关羽','life':80},
]
}
d = json.dumps(data) #仅转成字符串
d2 = json.loads(d)
print(type(d2),d2)
#<class 'dict'>
#{'roles': [{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': '关羽', 'life': 80}]}
json.dump() 将一个对象序列化存入文件
import json
data = {
'roles':[
{'role':'monster','type':'pig','life':50},
{'role':'hero','type':'关羽','life':80},
]
}
f = open('test.json',mode='w')
json.dump(data, f) #转成字符并写入文件
结果:会将 data中的数据写入文件
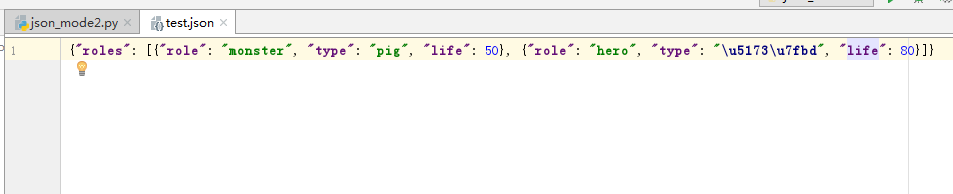
json.load() 从一个打开的文件句柄加载数据
import json
f = open('test.json','r')
data = json.load(f)
print(data['roles'])
打印:
[{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': '关羽', 'life': 80}]
import json
f = open('json_file.json','w',encoding='utf-8')
data1 = {'name':'nurato','skill':'螺旋丸'}
data2 = [1,2,3,'sunshine']
json.dump(data1, f)
json.dump(data2, f)
结果:
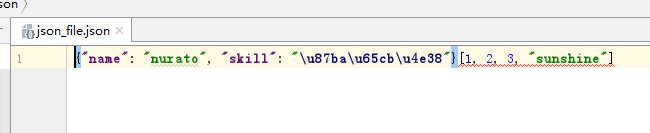
说明: 可以dump多次数据并写入文件
我们现在json.load 一下
f = open('json_file.json','r',encoding='utf-8')
json.load(f)
# 程序报错:json.decoder.JSONDecodeError
只load 一次,并且json格式有问题,会报错
------------------------------------------------分割线------------------------------------------------
模块pickle
import pickle
data1 = {'name':'nurato','skill':'螺旋丸'}
f = open('data.pkl','wb')
pickle.dump(data1,f)
结果:创建了一个 名为 data.pkl 的文件
import pickle
f = open('data.pkl','rb')
d = pickle.load(f)
print(type(d))
print(d)
#<class 'dict'>
#{'name': 'nurato', 'skill': '螺旋丸'}
关于json 和 pickle
JSON:
优点:跨语言、体积小
缺点:只能支持int\str\list\tuple\dict
Pickle:
优点:专为python设计,支持python所有的数据类型
缺点:只能在python中使用,存储数据占空间大
---------------------------------------分割线-------------------------------------------
序列化 shelve 模块
import shelve
f = shelve.open('shelve_test') #打开一个文件
names = ['python', 'html', 'java']
info = {'name': 'jack', 'age': 25}
f['names'] = names
f['info_dic'] = info
f.close()
结果:会创建 shelve_test 文件
import shelve
f = shelve.open('shelve_test') #打开一个文件
print(list(f.keys())) #['names', 'info_dic']
print(list(f.items())) #[('names', ['python', 'html', 'java']), ('info_dic', {'name': 'jack', 'age': 25})]
print(f.get('names')) #['python', 'html', 'java']
print(f.get('info_dic')) #{'name': 'jack', 'age': 25}
增加内容:
import shelve
f = shelve.open('shelve_test') #打开一个文件
f['book'] = [1,2,3,4,5] #增加内容
f.close()
f2 = shelve.open('shelve_test')
print(list(f2.keys())) # ['names', 'info_dic', 'book']
print(f2['book'])
我们来修改一下内容:(只能通过 f['book'] = [1,2,'肖申克的救赎',4,5]) 这样的方式重新赋值来更改
f['book'][0] = 'new book' 这样的方式是不可以的。
import shelve
f = shelve.open('shelve_test') # 打开一个文件
f['book'] = [1,2,'肖申克的救赎',4,5]
f.close()
f2 = shelve.open('shelve_test')
print(f2['book']) # [1, 2, '肖申克的救赎', 4, 5]
删除内容:
import shelve
f = shelve.open('shelve_test') #打开一个文件
del f['book']
f.close()
f2 = shelve.open('shelve_test')
print(list(f2.items()))
# 打印 : [('names', ['python', 'html', 'java']), ('info_dic', {'name': 'jack', 'age': 25})]
python序列化_json,pickle,shelve模块的更多相关文章
- Python(序列化json,pickle,shelve)
序列化 参考:https://www.cnblogs.com/yuanchenqi/articles/5732581.html # dic = str({'1':'111'}) # # f = ope ...
- python序列化: json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- day6_python序列化之 json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- Python全栈之路----常用模块----序列化(json&pickle&shelve)模块详解
把内存数据转成字符,叫序列化:把字符转成内存数据类型,叫反序列化. Json模块 Json模块提供了四个功能:序列化:dumps.dump:反序列化:loads.load. import json d ...
- Day 21 序列化模块_Json,Pickle,Shelve
序列化 , 数据类型,列表 元组, 字符串 只有字符串能被写入文件中. 能在网络上传输的只能是bytes - 字符串 把要传输的和要存储的内容转换成字符串. 字符串 转换回 要传输和存储的内容 序列化 ...
- Python序列化,json&pickle&shelve模块
1. 序列化说明 序列化可将非字符串的数据类型的数据进行存档,如字典.列表甚至是函数等等 反序列化,将通过序列化保存的文件内容反序列化即可得到数据原本的样子,可直接使用 2. Python中常用的序列 ...
- 12 python json&pickle&shelve模块
1.什么叫序列化 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes(字节) 2.用于序列化的两个模块,json和pickle ...
- Python学习 :json、pickle&shelve 模块
数据交换格式 json 模块 json (JavaScript Object Notation)是一种轻量级的数据交换语言,以文字为基础,且易于让人阅读.尽管 json 是JavaScript的一个子 ...
随机推荐
- Eclipse设置JVM的内存参数
打开Eclipse 或者 MyEclipse 打开 Windows -> Preferences -> Java -> Installed JREs 选中你所使用的 JDK,然后点击 ...
- "Sorry this application cannot run under a virtual machine" Error
错误: 运行一个程序是出现了 “sorry this application cannot run under a virtual machine” 错误. 如何解决: 控制面板-->卸载程序- ...
- Java Bean Validation(参数校验) 最佳实践
转载来自:http://www.cnblogs.com 参数校验是我们程序开发中必不可少的过程.用户在前端页面上填写表单时,前端js程序会校验参数的合法性,当数据到了后端,为了防止恶意操作,保持程序的 ...
- 1个示例 学会 mvc 常用标签
HtmlHelper用法大全3:Html.LabelFor.Html.EditorFor.Html.RadioButtonFor.Html.CheckBoxFor @Html.***For:为由指定 ...
- HTML5 总结 (1)
HTML5新表单 1.Input 新类型:email url tel number range date color date week month....... <html> < ...
- ASP.NET生命周期详解(转)
看到好文章需要分享. 最近一直在学习ASP.NET MVC的生命周期,发现ASP.NET MVC是建立在ASP.NET Framework基础之上的,所以原来对于ASP.NET WebForm中的很多 ...
- springboot 整合kafka
本文介绍如何在springboot项目中集成kafka收发message. 1.先解决依赖 springboot相关的依赖我们就不提了,和kafka相关的只依赖一个spring-kafka集成包 &l ...
- 对 Vue 的理解(一)
一.什么是 Vue ? 首先,Vue 是一个 MVVM 框架,M -- 模型,就是用来定义驱动的数据,V -- 视图,是经过数据改变后的 html,VM -- 框架视图,就是用来实现双向绑定的中间桥梁 ...
- SQL Server 2008 R2如何开启数据库的远程连接(转)
SQL Server 2008默认是不允许远程连接的,如果想要在本地用SSMS连接远程服务器上的SQL Server 2008,远程连接数据库.需要做两个部分的配置: SQL Server Manag ...
- 菜鸟学习Spring——SpringMVC注解版在服务器端获取Json字符串并解析
一.概述. SpringMVC在服务端把客户端传过来的JSON字符串,并把JSON字符串转成 JSON对象并取得其中的属性值,这个在项目中经常用到. 二.代码演示. 需要添加的jar包. 2.1 we ...