Hive(1)-基本概念
一. 什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL(Hive Query Language)转化成MapReduce程序
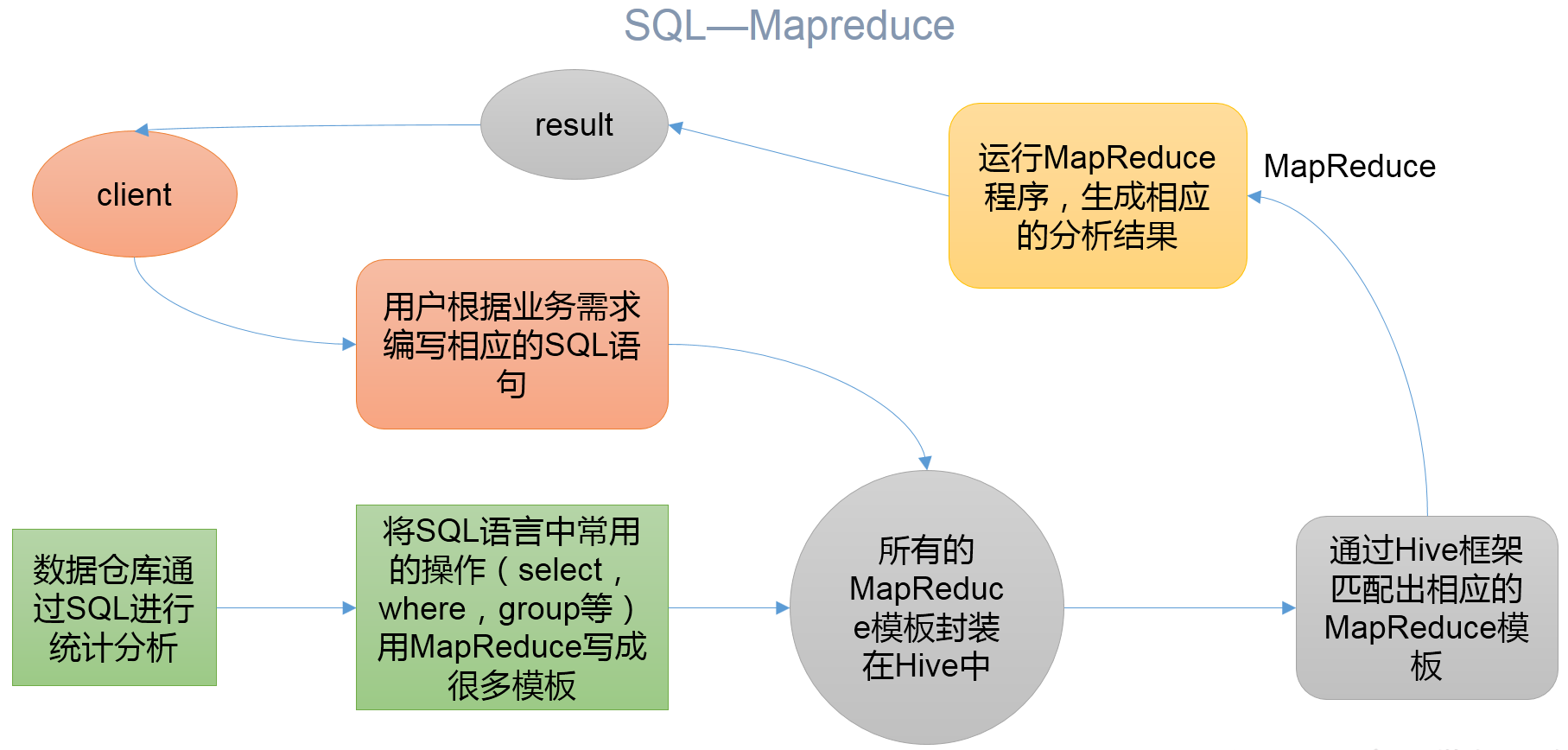
1)Hive处理的数据存储在HDFS
2)Hive分析数据底层的实现是MapReduce
3)执行程序运行在Yarn上
二.Hive的优缺点
1.优点
1). 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
2). 避免了去写MapReduce,减少开发人员的学习成本。
3). Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
4). Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5). Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
2.缺点
1). Hive的HQL表达能力有限
①迭代式算法无法表达
②数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
2). Hive的效率比较低
①Hive自动生成的MapReduce作业,通常情况下不够智能化
②Hive调优比较困难,粒度较粗
三. Hive架构原理
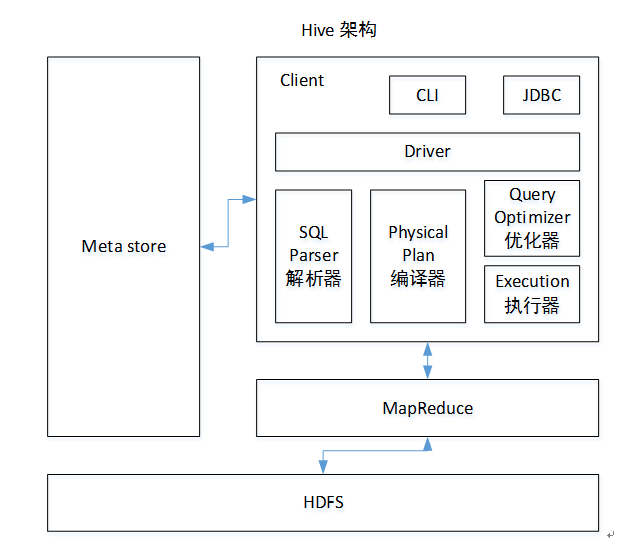
1. 用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2. 元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3. Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
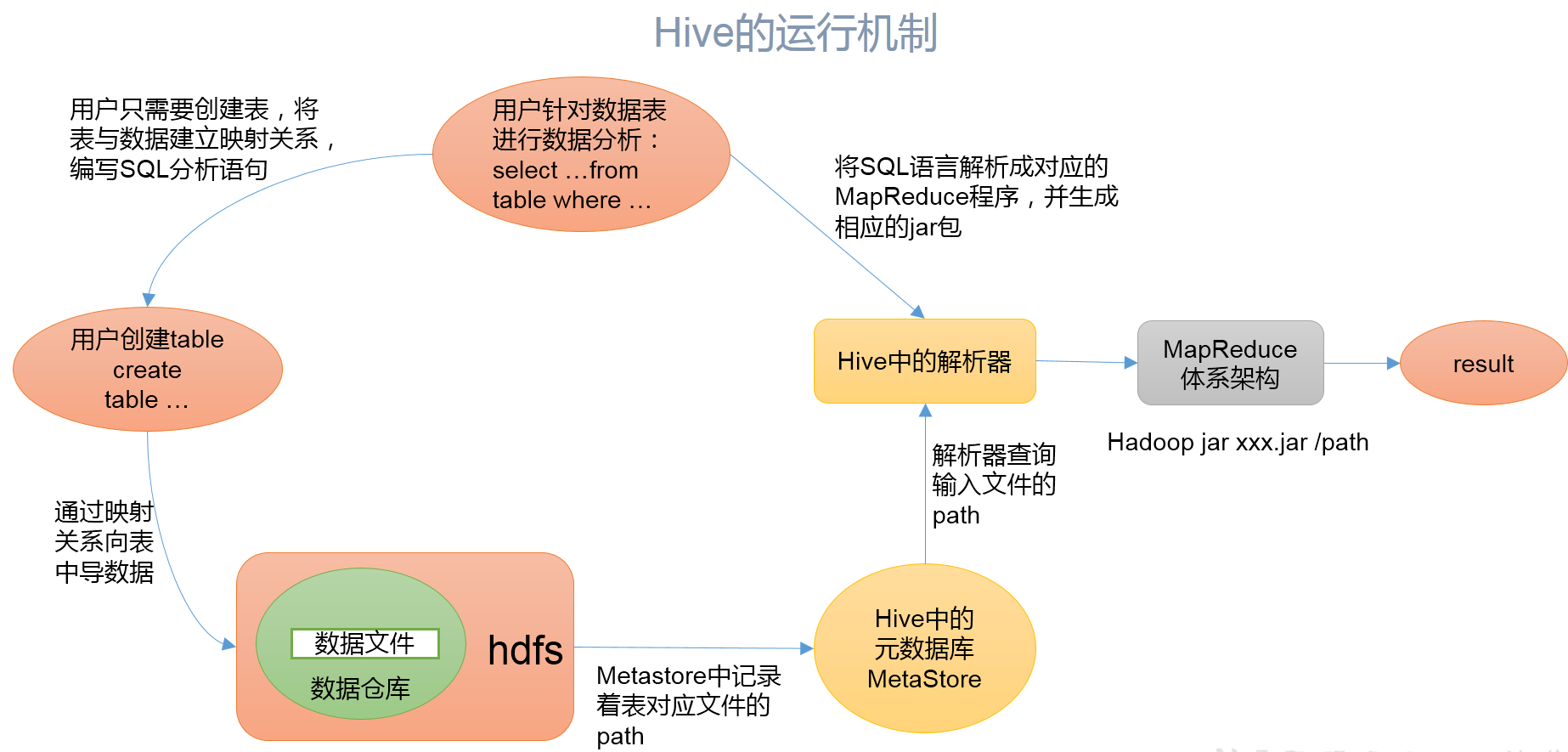
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
四. Hive和数据库比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
1. 查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
2.数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3.数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不建议对数据进行改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据。
4. 执行
Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
5. 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
6. 可扩展性
由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的。而数据库由于事物ACID 的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右。
7.数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive(1)-基本概念的更多相关文章
- 【Hadoop离线基础总结】数据仓库和hive的基本概念
数据仓库和Hive的基本概念 数据仓库 概述 数据仓库英文全称为 Data Warehouse,一般简称为DW.主要目的是构建面向分析的集成化数据环境,主要职责是对仓库中的数据进行分析,支持我们做决策 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- Hive的基本概念和常用命令
原文链接: https://www.toutiao.com/i6766571623727235595/?group_id=6766571623727235595 一.概念: 1.结构化和非结构化数据 ...
- Hive 的基本概念
Hadoop开发存在的问题 只能用java语言开发,如果是c语言或其他语言的程序员用Hadoop,存在语言门槛. 需要对Hadoop底层原理,api比较了解才能做开发. Hive概述 Hive是基于H ...
- Hive从概念到安装使用总结
一.Hive的基本概念 1.1 hive是什么? (1)Hive是建立在hadoop数据仓库基础之上的一个基础架构: (2)相当于hadoop之上的一个客户端,可以用来存储.查询和分析存储在hadoo ...
- Hive深入浅出
1. Hive是什么 1) Hive是什么? 这里引用 Hive wiki 上的介绍: Hive is a data warehouse infrastructure built on top of ...
- Hive分区(静态分区+动态分区)
Hive分区的概念与传统关系型数据库分区不同. 传统数据库的分区方式:就oracle而言,分区独立存在于段里,里面存储真实的数据,在数据进行插入的时候自动分配分区. Hive的分区方式:由于Hive实 ...
- Hive的HQL语句及数据倾斜解决方案
[版权申明:本文系作者原创,转载请注明出处] 文章出处:http://blog.csdn.net/sdksdk0/article/details/51675005 作者: 朱培 ID ...
- Hive篇--相关概念和使用二
一.基本概念 Hive分桶: 1.概念 分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储.对于hive中每一个表.分区都可以进一步进行分桶.(可以对列,也可以对表进行分桶)由列的哈希值除以桶 ...
随机推荐
- CSS3中的Flexbox弹性布局(二)
flexbox详解 flexbox的出现是为了解决复杂的web布局,因为这种布局方式很灵活.容器的子元素可以任意方向进行排列.此属性目前处于非正式标准. flex布局模型不同于块和内联模型布局,块和内 ...
- linux c 遍历目录及文件
#include <dirent.h>void recovery_backend() { DIR * pdir ; struct dirent * pdirent; struct stat ...
- React学习笔记 - JSX简介
React Learn Note 2 React学习笔记(二) 标签(空格分隔): React JavaScript 一.JSX简介 像const element = <h1>Hello ...
- JavaScript获取当前网页的源码
通过 outerHTML document.documentElement.outerHTML 通过异步请求 $.get(window.location.href,function(res){ con ...
- python接口测试-项目实践(二)获取接口响应,取值(re、json)
一 分别请求3个接口,获取响应. 第三方接口返回有两种:1 纯字符串 2 带bom头的json字串 import requests api1 = 'url1' response1 = request ...
- LeetCodeOJ刷题之12【Integer to Roman】
Integer to Roman Given an integer, convert it to a roman numeral. Input is guaranteed to be within t ...
- { ($0, Resolver($0.box)) }(Promise<T>(.pending)):闭包的定义与执行合一
public class func pending() -> (promise: Promise<T>, resolver: Resolver<T>) { return ...
- 「bzoj3687: 简单题」
题目 发现需要一个\(O(n\sum a_i )\)的做法 于是可以直接做一个背包,\(dp[i]\)表示和为\(i\)的子集是否有奇数种 \(bitset\)优化一下就好了 #include< ...
- mybatis学习记录三——SqlMapConfig.xml相关参数详解
5 SqlMapConfig.xml mybatis的全局配置文件SqlMapConfig.xml,配置内容如下: properties(属性) settings(全局配置参数) ty ...
- SSM命名规范框架
文件名 作用 src 根目录,没什么好说的,下面有main和test. main 主要目录,可以放java代码和一些资源文件. java 存放我们的java代码,这个文件夹要使用Build Path ...