MySQL单表数据查询(DQL)
数据准备工作:
CREATE TABLE student(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(10),
age TINYINT,
city VARCHAR(10),
score TINYINT
); INSERT INTO student VALUES (NULL,"曹操",28,"洛阳",95);
INSERT INTO student VALUES (NULL,"刘备",27,"成都",80);
INSERT INTO student VALUES (NULL,"孙权",17,"建业",85);
INSERT INTO student VALUES (NULL,"孔明",21,"成都",98);
INSERT INTO student VALUES (NULL,"关羽",25,"成都",70);
INSERT INTO student VALUES (NULL,"张飞",24,"成都",50);
INSERT INTO student VALUES (NULL,"鲁肃",22,"建业",90);
INSERT INTO student VALUES (NULL,"周瑜",19,"建业",97);
INSERT INTO student VALUES (NULL,"郭嘉",23,"洛阳",98);
INSERT INTO student VALUES (NULL,"小乔",18,"建业",70);
INSERT INTO student VALUES (NULL,"貂蝉",26,NULL,65);
一、简单查询
语法:select select选项 字段列表 from 数据源;
select选项:系统该如何对待查询得到的结果
all:默认的,表示保存所有的记录
distinct:去重,去除重复的记录(所有的字段值都相同),只保留一条
字段列表:对查询结果显示哪些列名
*:全部列名
as:给列名起别名,解决从多张表获取数据存在列名冲突的问题
from数据源:只要是一个符合二维表结构的数据即可
单表数据:from 表名
多表数据:from 表名1,表名2...
动态数据:from (select select选项 字段列表 from 数据源) as 别名
1.1 查询所有学生
查询指令:select * from student;
mysql> select * from student;
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 1 | 曹操 | 28 | 洛阳 | 95 |
| 2 | 刘备 | 27 | 成都 | 80 |
| 3 | 孙权 | 17 | 建业 | 85 |
| 4 | 孔明 | 21 | 成都 | 98 |
| 5 | 关羽 | 25 | 成都 | 70 |
| 6 | 张飞 | 24 | 成都 | 50 |
| 7 | 鲁肃 | 22 | 建业 | 90 |
| 8 | 周瑜 | 19 | 建业 | 97 |
| 9 | 郭嘉 | 23 | 洛阳 | 98 |
| 10 | 小乔 | 18 | 建业 | 70 |
| 11 | 貂蝉 | 26 | NULL | 65 |
+-----+--------+------+--------+-------+
11 rows in set (0.03 sec)
1.2 查询学生姓名和年龄
查询指令:select sname,age from student;
mysql> select sname,age from student;
+--------+------+
| sname | age |
+--------+------+
| 曹操 | 28 |
| 刘备 | 27 |
| 孙权 | 17 |
| 孔明 | 21 |
| 关羽 | 25 |
| 张飞 | 24 |
| 鲁肃 | 22 |
| 周瑜 | 19 |
| 郭嘉 | 23 |
| 小乔 | 18 |
| 貂蝉 | 26 |
+--------+------+
11 rows in set (0.00 sec)
1.3 运算查询:将所有学生的年龄+10进行显示
查询指令:select sname,age+10 from student;
mysql> select sname,age+10 from student;
+--------+--------+
| sname | age+10 |
+--------+--------+
| 曹操 | 38 |
| 刘备 | 37 |
| 孙权 | 27 |
| 孔明 | 31 |
| 关羽 | 35 |
| 张飞 | 34 |
| 鲁肃 | 32 |
| 周瑜 | 29 |
| 郭嘉 | 33 |
| 小乔 | 28 |
| 貂蝉 | 36 |
+--------+--------+
11 rows in set (0.00 sec)
1.4 别名查询:将列名sname,age分别用中文显示
查询指令:select sname as 姓名,age as 年龄 from student;
mysql> select sname as 姓名,age as 年龄 from student;
+--------+--------+
| 姓名 | 年龄 |
+--------+--------+
| 曹操 | 28 |
| 刘备 | 27 |
| 孙权 | 17 |
| 孔明 | 21 |
| 关羽 | 25 |
| 张飞 | 24 |
| 鲁肃 | 22 |
| 周瑜 | 19 |
| 郭嘉 | 23 |
| 小乔 | 18 |
| 貂蝉 | 26 |
+--------+--------+
11 rows in set (0.00 sec)
二、高级查询
语法:select select选项 字段列表 from 数据源 where 条件 group by 分组 having 条件 order by 排序 limit 分页 ;
2.1 where 子句
作用:针对表去对应的磁盘处获取所有的记录,where的作用就是在拿到一条结果就开始进行判断,判断是否符合
条件,如果符合就获取放到内存中去,如果不符合条件就不获取。
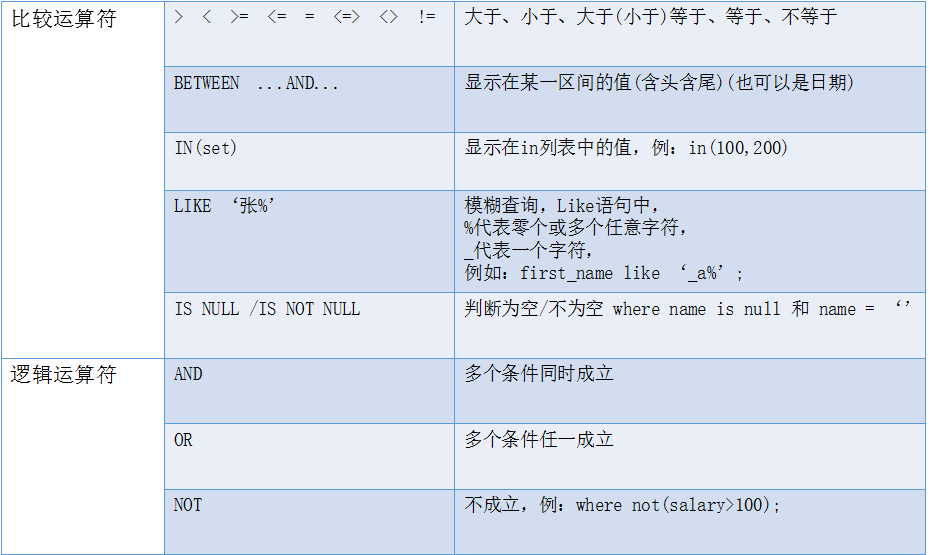
2.1.1 查询年龄大于24的学生
查询指令:select * from student where age > 24;
mysql> select * from student where age > 24;
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 1 | 曹操 | 28 | 洛阳 | 95 |
| 2 | 刘备 | 27 | 成都 | 80 |
| 5 | 关羽 | 25 | 成都 | 70 |
| 11 | 貂蝉 | 26 | NULL | 65 |
+-----+--------+------+--------+-------+
4 rows in set (0.00 sec)
2.1.2 查询年龄是18到22的学生
查询指令:select * from student where age between 18 and 22;
mysql> select * from student where age between 18 and 22;
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 4 | 孔明 | 21 | 成都 | 98 |
| 7 | 鲁肃 | 22 | 建业 | 90 |
| 8 | 周瑜 | 19 | 建业 | 97 |
| 10 | 小乔 | 18 | 建业 | 70 |
+-----+--------+------+--------+-------+
4 rows in set (0.00 sec)
2.1.3 查询地址是成都或洛阳的学生
查询指令:select * from student where city in ("成都","洛阳");
mysql> select * from student where city in ("成都","洛阳");
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 1 | 曹操 | 28 | 洛阳 | 95 |
| 2 | 刘备 | 27 | 成都 | 80 |
| 4 | 孔明 | 21 | 成都 | 98 |
| 5 | 关羽 | 25 | 成都 | 70 |
| 6 | 张飞 | 24 | 成都 | 50 |
| 9 | 郭嘉 | 23 | 洛阳 | 98 |
+-----+--------+------+--------+-------+
6 rows in set (0.00 sec)
2.1.4 查询姓孙的学生
查询指令:select * from student where sname like "孙%";
mysql> select * from student where sname like "孙%";
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 3 | 孙权 | 17 | 建业 | 85 |
+-----+--------+------+--------+-------+
1 row in set (0.00 sec)
2.1.5 查询地址不为空的学生
查询指令:select * from student where city is not null;
mysql> select * from student where city is not null;
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 1 | 曹操 | 28 | 洛阳 | 95 |
| 2 | 刘备 | 27 | 成都 | 80 |
| 3 | 孙权 | 17 | 建业 | 85 |
| 4 | 孔明 | 21 | 成都 | 98 |
| 5 | 关羽 | 25 | 成都 | 70 |
| 6 | 张飞 | 24 | 成都 | 50 |
| 7 | 鲁肃 | 22 | 建业 | 90 |
| 8 | 周瑜 | 19 | 建业 | 97 |
| 9 | 郭嘉 | 23 | 洛阳 | 98 |
| 10 | 小乔 | 18 | 建业 | 70 |
+-----+--------+------+--------+-------+
10 rows in set (0.00 sec)
2.1.6 查询地址为成都或洛阳,且年龄大于25的学生
查询指令:select * from student where city in ("成都","洛阳") and age > 25;
mysql> select * from student where city in ("成都","洛阳") and age > 25;
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 1 | 曹操 | 28 | 洛阳 | 95 |
| 2 | 刘备 | 27 | 成都 | 80 |
+-----+--------+------+--------+-------+
2 rows in set (0.00 sec)
2.1.7 查询地址不是成都或洛阳的学生
查询指令:select * from student where city not in ("成都","洛阳");
mysql> select * from student where city not in ("成都","洛阳");
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 3 | 孙权 | 17 | 建业 | 85 |
| 7 | 鲁肃 | 22 | 建业 | 90 |
| 8 | 周瑜 | 19 | 建业 | 97 |
| 10 | 小乔 | 18 | 建业 | 70 |
+-----+--------+------+--------+-------+
4 rows in set (0.00 sec)
2.2 group by 子句
作用:根据指定的字段,将数据进行分组,分组的目标是为了统计。
聚合函数:对分组数据进行统计操作。
count():统计每组中的数量,如果统计目标是字段,那么不统计为空NULL字段,如果为*,则统计记录数
avg():求平均值
sum():求和
max():求最大值
min():求最小值
2.2.1 统计各个地方的人数
查询指令:select city,count(*) from student group by city;
mysql> select city,count(*) from student group by city;
+--------+----------+
| city | count(*) |
+--------+----------+
| NULL | 1 |
| 建业 | 4 |
| 成都 | 4 |
| 洛阳 | 2 |
+--------+----------+
4 rows in set (0.02 sec)
2.2.2 统计各个地方的平均年龄
查询指令:select city,avg(age) from student group by city;
mysql> select city,avg(age) from student group by city;
+--------+----------+
| city | avg(age) |
+--------+----------+
| NULL | 26.0000 |
| 建业 | 19.0000 |
| 成都 | 24.2500 |
| 洛阳 | 25.5000 |
+--------+----------+
4 rows in set (0.01 sec)
2.2.3 统计各个地方的成绩总和
查询指令: select city,sum(score) from student group by city;
mysql> select city,sum(score) from student group by city;
+--------+------------+
| city | sum(score) |
+--------+------------+
| NULL | 65 |
| 建业 | 342 |
| 成都 | 298 |
| 洛阳 | 193 |
+--------+------------+
4 rows in set (0.00 sec)
2.2.4 统计各个地方的最大成绩与最小成绩
查询指令:select city,max(score),min(score) from student group by city;
mysql> select city,max(score),min(score) from student group by city;
+--------+------------+------------+
| city | max(score) | min(score) |
+--------+------------+------------+
| NULL | 65 | 65 |
| 建业 | 97 | 70 |
| 成都 | 98 | 50 |
| 洛阳 | 98 | 95 |
+--------+------------+------------+
4 rows in set (0.01 sec)
2.3 having 子句
作用:对分组后的数据进行筛选
having与where的区别:
1.having是在分组后对数据进行过滤,where是在分组前对数据进行过滤
2.having后面可以使用统计函数过滤数据,where后面不可以使用统计函数
2.3.1 统计各个地方的学生人数,获取人数大于2的数据
查询指令:select city,count(*) as num from student group by city having num > 2;
mysql> select city,count(*) as num from student group by city having num > 2;
+--------+-----+
| city | num |
+--------+-----+
| 建业 | 4 |
| 成都 | 4 |
+--------+-----+
2 rows in set (0.00 sec)
注意:having是在group by之后,group by是在where之后,where的时候表示将数据从磁盘拿到内存,
where之后的所有操作都是内存操作。
2.4 order by 子句
作用:对查询结果进行排序显示,默认按升序,可以对多个字段进行排序
asc:升序排序
desc:降序排序
2.4.1 把所有学生先按成绩进行降序排序,再按年龄进行升序排序
查询指令:select * from student order by score desc,age asc;
mysql> select * from student order by score desc,age asc;
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 4 | 孔明 | 21 | 成都 | 98 |
| 9 | 郭嘉 | 23 | 洛阳 | 98 |
| 8 | 周瑜 | 19 | 建业 | 97 |
| 1 | 曹操 | 28 | 洛阳 | 95 |
| 7 | 鲁肃 | 22 | 建业 | 90 |
| 3 | 孙权 | 17 | 建业 | 85 |
| 2 | 刘备 | 27 | 成都 | 80 |
| 10 | 小乔 | 18 | 建业 | 70 |
| 5 | 关羽 | 25 | 成都 | 70 |
| 11 | 貂蝉 | 26 | NULL | 65 |
| 6 | 张飞 | 24 | 成都 | 50 |
+-----+--------+------+--------+-------+
11 rows in set (0.00 sec)
2.5 limit 子句
作用:利用limit来限制获取指定区间的数据。
基本语法:limit offset,length;
offset:偏移量,从哪条记录开始,第一条记录为0
length:长度,获取多少条记录
2.5.1 对成绩进行排名,获取成绩是第6名到第10名的学生
查询指令:select * from student order by score desc limit 5,5;
mysql> select * from student order by score desc limit 5,5;
+-----+--------+------+--------+-------+
| sid | sname | age | city | score |
+-----+--------+------+--------+-------+
| 3 | 孙权 | 17 | 建业 | 85 |
| 2 | 刘备 | 27 | 成都 | 80 |
| 5 | 关羽 | 25 | 成都 | 70 |
| 10 | 小乔 | 18 | 建业 | 70 |
| 11 | 貂蝉 | 26 | NULL | 65 |
+-----+--------+------+--------+-------+
5 rows in set (0.00 sec)
MySQL单表数据查询(DQL)的更多相关文章
- MySQL多表数据查询(DQL)
数据准备: /* ------------------------------------创建班级表------------------------------------ */ CREATE TAB ...
- MySQL单表数据不超过500万:是经验数值,还是黄金铁律?
今天,探讨一个有趣的话题:MySQL 单表数据达到多少时才需要考虑分库分表?有人说 2000 万行,也有人说 500 万行.那么,你觉得这个数值多少才合适呢? 曾经在中国互联网技术圈广为流传着这么一个 ...
- MySQL单表数据不要超过500万行:是经验数值,还是黄金铁律?
本文阅读时间大约3分钟. 梁桂钊 | 作者 今天,探讨一个有趣的话题:MySQL 单表数据达到多少时才需要考虑分库分表?有人说 2000 万行,也有人说 500 万行.那么,你觉得这个数值多少才合适呢 ...
- MySQL单表数据量过千万,采坑优化记录,完美解决方案
问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡死.严重影响业务 ...
- MySql数据库之单表数据查询
查询数据 1.查询所有数据: select * from 表名; 2.根据指定条件查询数据:
- MySQL单表最大记录数不能超过多少?
MySQL单表最大记录数不能超过多少? 很多人困惑这个问题.其实,MySQL本身并没有对单表最大记录数进行限制,这个数值取决于你的操作系统对单个文件的限制本身. 从性能角度来讲,MySQL单表数据不要 ...
- MYSQL单表可以存储多少条数据???
MYSQL单表可以存储多少条数据??? 单表存储四千万条数据,说MySQL不行的自己打脸吧. 多说一句话,对于爬虫来说,任何数据库,仅仅是存储数据的地方,最关心的是 能否存储数据和存储多少数据以及存储 ...
- Mysql 单表查询 子查询 关联查询
数据准备: ## 学院表create table department( d_id int primary key auto_increment, d_name varchar(20) not nul ...
- MySQL学习总结(五)表数据查询
查询数据记录,是指从数据库对象表中获取所要查询的数据记录,该操作可以说是数据最基本的操作之一,也是使用频率最高.最重要的数据操作. 1.单表数据记录查询 1.1.简单数据查询 SELECT field ...
随机推荐
- 生成对抗式网络 GAN的理解
转自:https://zhuanlan.zhihu.com/p/24767059,感谢分享 生成式对抗网络(GAN)是近年来大热的深度学习模型.最近正好有空看了这方面的一些论文,跑了一个GAN的代码, ...
- python进程与线程介绍
很多同学都听说过,现代操作系统比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统. 什么叫“多任务”呢?简单地说,就是操作系统可以同时运行多个任务.打个比方,你 ...
- angularJS 单页面 两个及以上个 ng-app 的处理方式
<div ng-app="myApp1" ng-controller="myCtrl1"> 名: <input type="text ...
- 分布式消息队列kafka
下载地址:http://kafka.apache.org/downloads.html 先启动zookeeper服务器 bin/zookeeper-server-start.sh config/zoo ...
- redis的使用方式
常用的语法以及使用方式: key中不能包含回车空格等,key不要太长,占用内存. 概念介绍: 差集: a:{1,2,3} b:{2,3,4},以a为锚点,差集 ...
- sqlserver内存管理之lazy writer
任何在缓冲区被修改的页都会被标记为“脏”页.将这个脏页写入到数据磁盘就是CheckPoint或者Lazy Writer的工作.前面就大体说了一下checkpoint,这会就简单的理解一下这个lazy ...
- ORA-01795: 列表中的最大表达式数为1000的解决方法
IN中的数据量不能超过1000条. 解决方案:把条件分成多个少于1000的IN即: DELETEFROMT_MM_SECTION_SITE_UPDATEWHERE T.T_MM_SECTION_SL_ ...
- codis学习
一.codis-proxy 结构 1.Topology 2.Slots 3.ServerGroup 4.Server 二.codis-proxy 启动过程 1.初始化ProxyInfo Id ...
- C语言 返回指针的函数
#include <stdio.h> char * test() { return "itcast"; } int main(int argc, const char ...
- jmeter自动生成测试报告
环境要求1:jmeter3.0版本之后开始支持动态生成测试报表 2:jdk版本1.7以上 3:需要jmx脚本文件 基本操作 1:在你的脚本文件路径下,执行cmd命令:jmeter -n -t test ...