Python爬虫爬取百度翻译之数据提取方法json
工具:Python 3.6.5、PyCharm开发工具、Windows 10 操作系统
说明:本例为实现输入中文翻译为英文的小程序,适合Python爬虫的初学者一起学习,感兴趣的可以做英文翻译为中文的功能,如单词查询功能等。推荐使用谷歌浏览器或火狐浏览器检查元素。使用之前需要先安装模块:pip install request pip install json。
数据提取方法:json
1、数据交换格式,看起来像Python类型(列表,字典)的字符串
2、使用json之前需要导入
3、json.loads
(1)、把json字符串转化为Python类型
(2)、json.loads(json字符串)
4、json.dumps
(1)、把Python类型转化为json字符串
(2)、json.dumps({})
(3)、json.dumps(ret1,ensure_ascii=False,indent=2)
ensure_ascii让中文显示成中文
indent:能够让下一行在上一行的基础上空格
代码:
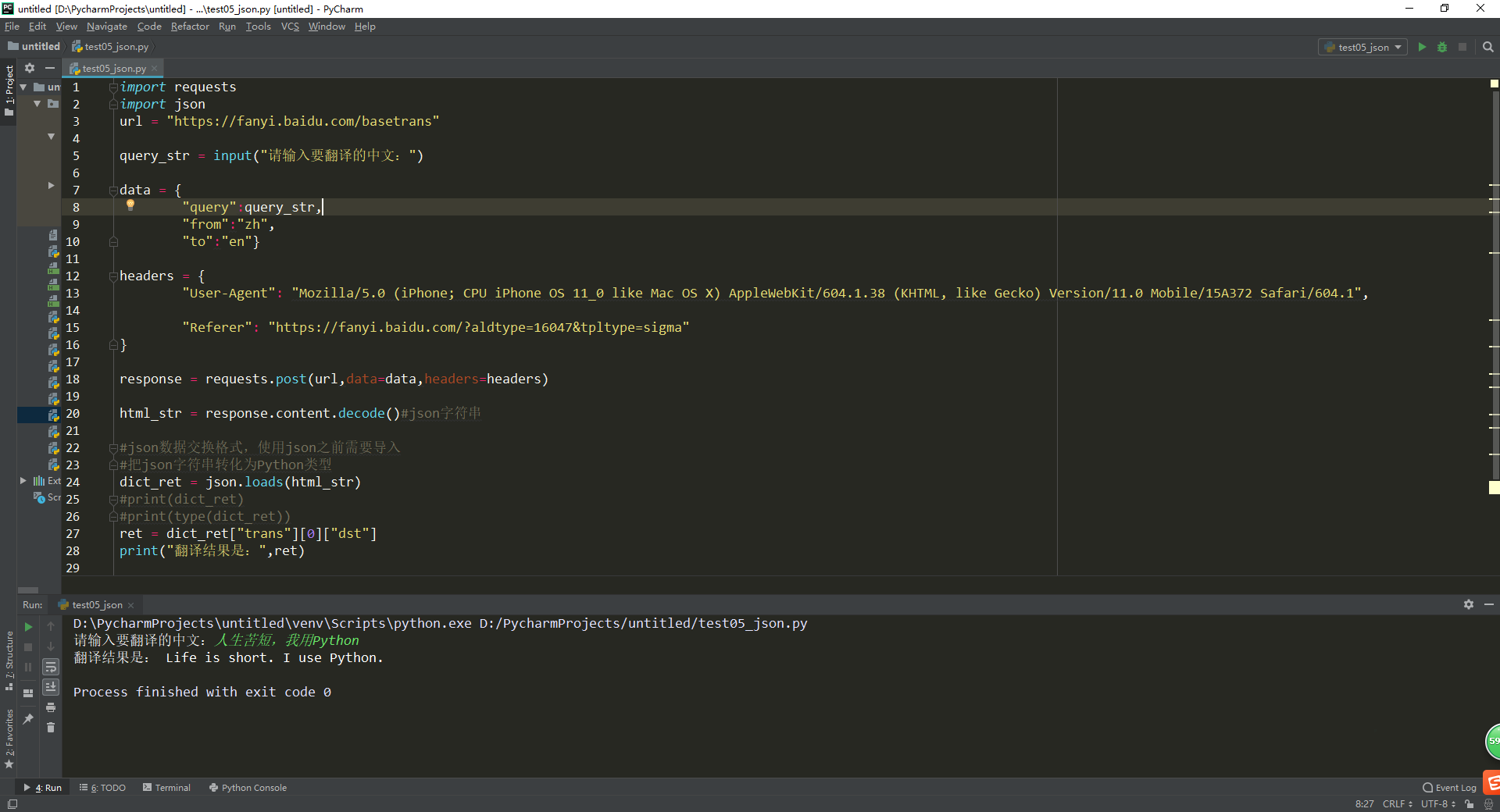
import requests
import json
url = "https://fanyi.baidu.com/basetrans" query_str = input("请输入要翻译的中文:") data = {
"query":query_str,
"from":"zh",
"to":"en"} headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1", "Referer": "https://fanyi.baidu.com/?aldtype=16047&tpltype=sigma"
} response = requests.post(url,data=data,headers=headers) html_str = response.content.decode()#json字符串 #json数据交换格式,使用json之前需要导入
#把json字符串转化为Python类型
dict_ret = json.loads(html_str)
#print(dict_ret)
#print(type(dict_ret))
ret = dict_ret["trans"][0]["dst"]
print("翻译结果是:",ret)
运行效果:
Python爬虫爬取百度翻译之数据提取方法json的更多相关文章
- python --爬虫--爬取百度翻译
import requestsimport json class baidufanyi: def __init__(self, trans_str): self.lang_detect_url = ' ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urlli ...
- Python爬虫爬取百度贴吧的图片
根据输入的贴吧地址,爬取想要该贴吧的图片,保存到本地文件夹,仅供参考: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urllib2i ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- Python爬虫-爬取百度贴吧帖子
这次主要学习了替换各种标签,规范格式的方法.依然参考博主崔庆才的博客. 1.获取url 某一帖子:https://tieba.baidu.com/p/3138733512?see_lz=1&p ...
随机推荐
- (一)selenium发展史(专治selenium小白)
Jason Huggins在2004年发起了Selenium项目,当时身处ThoughtWorks的他,为了不想让自己的时间浪费在无聊的重复性工作中,幸运的是,所有被测试的浏览器都支持Javascri ...
- IOS JPush 集成步骤(极光远程推送解决方案,支持android和iOS两个平台)
● 什么是JPush ● 一套远程推送解决方案,支持android和iOS两个平台 ● 它能够快捷地为iOS App增加推送功能,减少集成APNs需要的工作量.开发复杂 度 ● 更多的信息,可 ...
- C++11新特性之 std::forward(完美转发)
我们也要时刻清醒,有时候右值会转为左值,左值会转为右值. (也许“转换”二字用的不是很准确) 如果我们要避免这种转换呢? 我们需要一种方法能按照参数原来的类型转发到另一个函数中,这才完美,我们称之为完 ...
- Bootstrap table分页问题汇总
首先非常感谢作者针对bootstrap table分页问题进行详细的整理,并分享给了大家,希望通过这篇文章可以帮助大家解决Bootstrap table分页的各种问题,谢谢大家的阅读. 问题1 :服务 ...
- HDU 1521 指数型母函数
方法一: DFS 方法二:生成函数 每个数可以重复一定次数,求排列组合数,这是裸的指数型生成函数: #include <bits/stdc++.h> using namespace std ...
- 【转】jQuery源码分析-03构造jQuery对象-源码结构和核心函数
作者:nuysoft/高云 QQ:47214707 EMail:nuysoft@gmail.com 毕竟是边读边写,不对的地方请告诉我,多多交流共同进步.本章还未写完,完了会提交PDF. 前记: 想系 ...
- http://codeforces.com/gym/100623/attachments E题
http://codeforces.com/gym/100623/attachments E题第一个优化它虽然是镜像对称,但它毕竟是一一对称的,所以可以匹配串和模式串都从头到尾颠倒一下第二个优化,与次 ...
- 2018.12.20 Spring环境如何搭建
Spring学习 1.导入spring约束 为后续创建xml文件做铺垫 2.开始搭建Spring环境 1.创建Web项目,引入spring的开发包(根据下面的图来引入) 2.引入jar包 coreCo ...
- EF Ccore 主从配置 最简化
业务需要 配置一主多从数据库 读写分离 orm用的ef core , 把思路和代码写下 1. 配置2个数据库上下文 ETMasterContext ETSlaveContext(把增删改功能禁用掉 ...
- Android学习笔记_5_文件操作
1.Activity提供了openFileOutput()方法可以用于把数据输出到文件中,具体的实现过程与在J2SE环境中保存数据到文件中是一样的. package com.example.servi ...