详解C程序编译、链接与存储空间布局
被隐藏了的过程
现如今在流行的集成开发环境下我们很少需要关注编译和链接的过程,而隐藏在程序运行期间的细节过程可不简单,即使使用命令行来编译一个源代码文件,简单的一句"gcc hello.c"命令就包含了非常复杂的过程。
#include<stdio.h>
int main()
{
printf("Hello word\n");
return ;
}

在Linux系统下使用gcc编译程序时只须简单的命令:
$gcc hello.c
$/a.out
Hello word
不管哪种编辑器,以上过程可分为4个步骤,分别是预编译(Prepressing)、编译(Compilation)、汇编(Assembly)、链接(Linking)。
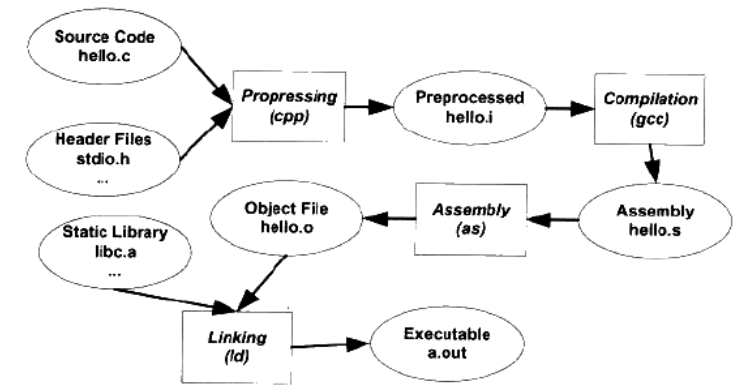
GCC 编译过程分解
预编译
首先是将源代码文件hello.c和相关的头文件,如stdio.h等被编译器Cpp预编译成一个.i文件。主要处理那些源文件中以“#”开始的预编译指令,如“#include"、”#define“等,主要规则如下:
•宏定义展开:将所有的”#define“删除,并且展开所有的宏定义;
•处理所有条件预编译指令,比如”#if”、”#ifdef“、”#elif“等;
•头文件展开:处理”#include“预编译命令,将被包含的文件插入到该预编译指令的位置。注意,这个过程是递归进行的,也就是说被包含的文件可能还包含其他文件;
•去注释:删除所有的注释”//“和”/**/“;
•添加行号和文件名标识,比如#2”hello.c“2,以便于编译器产生调试用时的行号信息及用于编译时产生编译错误或警告时能显示行号;
•保留所有的#pragma编译器指令,因为预编译器需要用他们。
在Linux系统下使用gcc预编译程序时命令:$gcc -E hello.c -o hello.i
编译
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析、生成汇编文件,这个过程是是整个程序构建的核心部分,也是最复杂的部分之一。编译过程相当于如下过程命令:
$gcc -S hello.i -o hello.s
gcc将预编译和编译合并成一个步骤,使用如下命令:
$gcc -S hello.c -o hello.s
可得到会变输出文件 hello.s 。实际上gcc这个命令只是这些后台程序的包装,它会根据不同的参数要求去调用预编译编译程序cc1、汇编器as、链接器ld。
编译器职责
词法分析 经过预编译的源代码程序被输入到扫描器(Scanner),扫描器对其进行简单的词法分析,运用一种类似于有限状态机的算法将源代码的字符列分割成一系列的记号。如:关键字、标识符、字面量(包含数字、字符串等)和特殊符号(如加号、等号)。在标别记号的同时扫描器也完成了其他如将标识符存放到符号表,将数字、字符串常量存放到文件表等的工作,以备后面的步骤使用。(lex程序可实现词法扫描,按照一定的词法规则完成标别记号等功能,所以无需为每个编译器开发一个独立开发扫描器,而是根据需要改变语法规则即可。)
语法分析 语法分析器采用上下文无关语法的分析手段对扫描器产生的记号(Token)进行语法分析,从而生成语法树,即以表达式为节点的树。同时很多运算符的含义和优先级也被确定下来。编译器也会报告出语法分析阶段的错误。(如词法分析有像lex一样语法分析有现成工具ycc程序,它可根据语法规则对输入的记号序列构建出一颗语法树。对不同的编程语言只须改变语法规则即可。)
语义分析 语义分析由语义分析器完成,它所能分析的语义是静态语义,即编译期间可以确定的语义,运行期间才能确定的语义是指动态语义,比如将0作为除数是一个运行期间的语义错误。静态语义通常包括声明和类型匹配,类型转换,如浮点型到整型转换。经过语义分析以后整个语法树都被标识了类型,如果有些类型需要做隐式转换,语义分析程序会在语法树中插入相应的转换节点。语义分析器对符号表里的符号类型也做了更新。语法分析仅仅完成对表达式语法层面的分析, 该语句是否有意义不进行检测。
生成中间代码和目标代码 语义分析完成后,源码优化器会在源代码级别进行优化,它往往将整个语法树转换成中间代码,它是语法树的顺序表示,已非常接近目标代码。中间代码有多种类型,常见的有三地址码,P-代码。中间代码使得编译器可分成前端和后端,前段即产生中间代码,后端将中间代码转换成目标机器代码。后端编辑器主要包括代码生成器和目标代码优化器。代码生成器将中间代码转换成目标机器代码。目标代码优化器再对其进行优化,如选择合适的寻址方式、使用位移来代替乘法运算、删除多余指令等。
汇编
汇编器是将汇编代码变成机器可以执行的指令,每一条汇编语句几乎都对应一条机器指令,根据汇编指令和机器指令对照表一一翻译即可。目标文件中还包括链接是所需要的一些调试信息: 比如符号表、 调试信息、 字符串等。前述汇编过程可以可调用汇编器as来完成:
$as hello.s -o hello.o
或者使用gcc汇编程序命令:$gcc -c hello.s -o hello.o
或者使用gcc命令从C源代码文件开始,经过预编译、编译、汇编、直接输出目标文件:
$gcc -c hello.c -o hello.o
目标文件:就是源代码编译后,但未进行链接的那些中间文件,它与链接之后形成的可执行文件在内容和结构上非常相似,按一种格式存储,且动态链接库与静态链接库都按照可执行文件格式存储(Linux下为ELF格式)。
链接
人们把每个源代码模块独立的进行编译,然后按照需要将它们组装起来,这个组装的过程就是链接(Linking)。其主要内容就是把各个模块之间相互引用的部分都处理好,使得各个模块之间能够正确地衔接。链接过程主要包括地址空间分配、符号决议和重定位。每个模块的源代码文件经编译器编译生成目标文件(.o或.obj),目标文件和库一起链接形成可执行文件。
静态链接是指在编译阶段直接把静态库加入到可执行文件中去,这样可执行文件会比较大。
动态链接则是指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
静态链接
两步链接:1、空间与地址分配。扫描输入的目标文件,获得各个段长度、属性、位置,合并符号表、合并相似段(为合并的“bss”段分配虚拟地址空间),计算输出文件中各个段合并后的长度与位置,并建立映射关系;
可使用链接器 ld 将“hello1.o”与“hello2.o”链接起来:
$ ld hello1.o hello2.o -e main -o hello
"-e mian"将main函数作为程序入口,ld 链接器默认为_start。
"-o hello"表示链接输出文件名为hello 默认为a.out。
使用 objdump 可查看链接前后虚拟地址空间分配情况(Linux下ELF可执行文件默认从地址0x08048000开始分配)。
2、符号解析与重定位
首先,符号解析。解析符号就是将每个符号引用与它输入的可重定位目标文件中的符号表中的一个确定的符号定义联系起来。若找不到,则出现编译时错误。
其次是重定位;不同的处理器指令对于地址的格式和方式都不一样。我们这里采用的是32位的x86处理器,介绍两种寻址方式。绝对寻址修正与相对寻址修正。
静态库可以简单看作是一组可目标文件的集合。与静态库链接的过程是这样的:ld链接器自动查找全局符号表,找到那些为决议的符号,然后查出它们所在的目标文件,将这些目标文件从静态库中“解压”出来,最终将它们链接在一起成为一个可执行文件。也就是说只有少数几个库和目标文件被链接入了最终的可执行文件,而非所有的库一股脑地被链接进了可执行文件。
动态链接
1、为什么要有动态链接?
第一,考虑内存和磁盘空间。静态链接极大地浪费内存空间。因为在静态链接的情况下,假设有两个程序共享一个模块,那么在静态链接后输出的两个可执行文件中各有一个共享模块的副本。如果同时运行这两个可执行文件,那么这个共享模块将在磁盘和内存中都有两个副本,对磁盘和内存造成极大地浪费;第二,程序的更新。一旦程序中的一个模块被修改,那么整个程序都要重新链接、发布给用户。如果这个程序相当的大,那么后果就会更加严重!
2、动态链接做了什么?
务必知道,动态链接是相对于共享对象而言的。动态链接器将程序所需要的所有共享库装载到进程的地址空间,并且将程序汇总所有为决议的符号绑定到相应的动态链接库(共享库)中,并进行重定位工作。
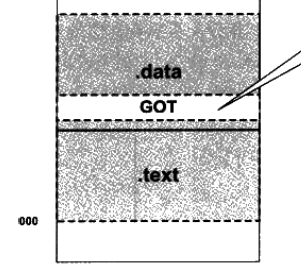
对于共享模块来说,要实现共享,那么其代码对数据的访问必须是地址无关(就是代码中的地址是固定的,这里用的相对地址)的,如何做到地址无关,编译器是这么干的,每一个共享模块,都会在其代码段有一个GOT(global offset table)段,如上图所示,Got是一个指针数组,用来存储外部变量的地址,而代码相对于Got的距离是固定的,当对外部模块变量数据和函数进行访问时,就去访问变量在GOT中的位置。
共享模块对于数据的访问方式:
本模块的全局变量和函数------相对地址
外模块的全局变量和函数-------GOT段
动态链接重定位时修改GOT中的值就实现了对变量的正确访问。
3、动态链接基本分为三步:先是启动动态链接器本身,然后装载所有需要的共享对象,最后重定位和初始化。
(1)启动动态链接器本身
动态链接器有其自身的特殊性:首先,动态链接器本身不可以依赖其他任何共享对象(人为控制);其次动态链接器本身所需要的全局和静态变量的重定位工作由它自身完成(自举代码)。
在Linux下,动态链接器ld.so实际上也是一个共享对象,操作系统同样通过映射的方式将它加载到进程的地址空间中。操作系统在加载完动态链接器之后,就将控制权交给动态链接器。动态链接器入口地址即是自举代码的入口。动态链接器启动后,它的自举代码即开始执行。自举代码首先会找到它自己的GOT(全局偏移表,记录每个段的偏移位置)。而GOT的第一个入口保存的就是“.dynamic”段的偏移地址,由此找到动态链接器本身的“.dynamic”段。通过“.dynamic”段中的信息,自举代码便可以获得动态链接器本身的重定位表和符号表等,从而得到动态链接器本身的重定位入口,然后将它们重定位。完成自举后,就可以自由地调用各种函数和全局变量。
(2)装载共享对象
完成自举后,动态链接器将可执行文件和链接器本身的符号表都合并到一个符号表当中,称之为“全局符号表”。然后链接器开始寻找可执行文件所依赖的共享对象:从“.dynamic”段中找到DT_NEEDED类型,它所指出的就是可执行文件所依赖的共享对象。由此,动态链接器可以列出可执行文件所依赖的所有共享对象,并将这些共享对象的名字放入到一个装载集合中。然后链接器开始从集合中取出一个所需要的共享对象的名字,找到相应的文件后打开该文件,读取相应的ELF文件头和“.dynamic”,然后将它相应的代码段和数据段映射到进程空间中。如果这个ELF共享对象还依赖于其他共享对象,那么将依赖的共享对象的名字放到装载集合中。如此循环,直到所有依赖的共享对象都被装载完成为止。当一个新的共享对象被装载进来的时候,它的符号表会被合并到全局符号表中。所以当所有的共享对象都被装载进来的时候,全局符号表里面将包含动态链接器所需要的所有符号。
(3)重定位和初始化
当上述两步完成以后,动态链接器开始重新遍历可执行文件和每个共享对象的重定位表,将表中每个需要重定位的位置进行修正,原理同前。
重定位完成以后,如果某个共享对象有“.init”段,那么动态链接器会执行“.init”段中的代码,用以实现共享对象特有的初始化过程。
此时,所有的共享对象都已经装载并链接完成了,动态链接器的任务也到此结束。同时装载链接部分也将告一段落!接下来便是程序的执行了。。。
4、静态库与动态库的区别:
库: 指由标准常用函数编译而成的文件,旨在提高常用函数的可重用性,减轻开发人员负担。常用的sdtio.h,math.h等 库便是C函数库的冰山一角。
(1)静态库:指编译链接阶段将整个库复制到可执行文件
优点:静态链接的程序不依赖外界库支持,具有良好的可移植性。
缺点: 每次库更新都需要重新编译程序,即使更新很小或只是局部。
缺点:每个静态链接的程序都有一份库文件,存储时增加了硬盘空间消耗,运行时则增加了内存消耗。
(2).动态库:指直道运行时才将库链接到可执行程序
优点: 动态链接方式的程序不需要包含库(编辑链接时节省时间),占用的空间小很多。
优点: 运行时系统内存只需提供一个共享库给所有程序动态链接,内存消耗减少。
缺点: 需要系统中动态库支持才可运行,可能有动态库不兼容问题
小结:在linux系统中:静态库 .a , 动态库 .so
在windows中:静态库 .lib , 动态库 .dll
未解决的符号表: 列出本单元里有引用但是不在本单元定义的符号以及地址。导出符号表: 本单元中定义的一些符号(全局、静态变量和函数) 和地址的映射表。地址重定向表: 提供了本编译单元所有对自身地址的引 用记录连接器的工作顺序:当连接器链接的时候, 首先决定各个目标文件在最终可执行文件里的位置。然后访问所有目标文件的地址重定义表, 对其中记录的地址进行重定向 (加上一个偏移量, 即该编译单元在可执行文件上的起始地址) 。然后遍历所有目标文件的未解决符号表, 并且在所有的导出符号表里查找匹配的符号, 并在未解决符号表中所记录的位置上填写实际地址。最后把所有的目标文件的内容写在各自的位置上,和库(Library)一起链接,形成最终的可执行文件。
总结:

C程序的存储空间分配
如下图所示:
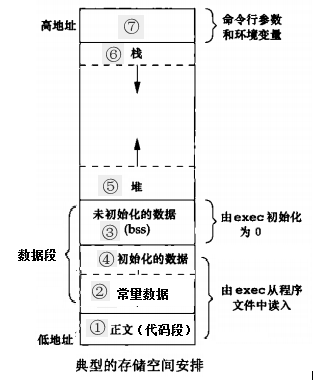

静态数据区还分为“data”段与“bss”段,分别存放已初始化全局变量和局部静态变量与未初始化全局变量和局部静态变量。未初始化全局变量和局部静态变量默认初始化为0,没有必要在“data”分配空间存放0,而在程序运行期间它们的确要占内存的,且可执行文件需要记录未初始化全局变量和局部静态变量的大小总和记为“.bss”段,所以目标文件和可执行文件中的".bss"段只是为未初始化全局变量和局部静态变量预留位置,并没有内容,也不占据空间,只是在链接装载时占用地址空间。
代码区存放程序指令,静态区存放数据,为什么要将指令与数据分开呢?
1、程序被装载后数据与指令分别映射到两个虚存区域,进程对数据区可读可写,而对指令区只读,所以对两个虚存区的权限分别设置为可读写和只读,防止指令被改写。
2、CPU缓存被设置为数据缓存与指令缓存分离,程序指令与数据分开放可提高CPU缓存命中率。
3、最重要的原因是共享指令。当系统中运行着大量该程序副本时只需,内存中只需存一份该程序的指令部分。而数据区域不一样,为进程私有。可以节省大量的内存。
示例代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int a = ; // 全局初始化区(④区)
char *p1; // 全局未初始化区(③区)
int main()
{
int b; // 栈区
char s[] = "abc"; // 栈区
char *p2; // 栈区
char *p3 = ""; // 123456\0 在常量区(②),p3在栈上,体会与 char s[]="abc"; 的不同
static int c = ; // 全局初始化区
p1 = (char *)malloc(), // 堆区
p2 = (char *)malloc(); // 堆区
// 123456\0 放在常量区,但编译器可能会将它与p3所指向的"123456"优化成一个地方
strcpy(p1, "");
}
详解C程序编译、链接与存储空间布局的更多相关文章
- 详解C/C++ 编译 g++ gcc 的区别
我们在编译c/c++代码的时候,有人用gcc,有人用g++,于是各种说法都来了,譬如c代码用gcc,而c++代码用g++, 或者说编译用gcc,链 接用g++,一时也不知哪个说法正确,如果再遇上个ex ...
- 读书笔记-详解C程序开发中 .c和.h文件的区别
一个简单的问题:.c和.h文件的区别 学了几个月的C语言,反而觉得越来越不懂了.同样是子程序,可以定义在.c文件中,也可以定义在.h文件中,那这两个文件到底在用法上有什么区别呢? 2楼: 子程序不要定 ...
- Linux程序编译链接动态库版本号的问题
不同版本号的动态库可能会不兼容,假设程序在编译时指定动态库是某个低版本号.执行是用的一个高版本号,可能会导致无法执行. Linux上对动态库的命名採用libxxx.so.a.b.c的格式.当中a代表大 ...
- AFNetworking详解和相关文章链接
写在开头: 作为一个iOS开发,也许你不知道NSUrlRequest.不知道NSUrlConnection.也不知道NSURLSession...(说不下去了...怎么会什么都不知道...)但是你一定 ...
- (转)C++内存分配方式详解——堆、栈、自由存储区、全局/静态存储区和常量存储区
程序在内存有五个存在区域: A:动态区域中的栈区 B:动态区域中的栈区 C:静态区域中:全局变量 和静态变量 (这个区域又可以进一步细分为:初始化的全局变量和静态变量 以及 未初始 ...
- linux c 链接详解1-多目标文件链接
1. 多目标文件的链接 摘自:linux c编程一站式学习 http://learn.akae.cn/media/index.html 可以学会在linux下将多个c语言文件一起编译. 现在我们把例 ...
- C++内存分配方式详解——堆、栈、自由存储区、全局/静态存储区和常量存储区
栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区.里面的变量通常是局部变量.函数参数等.在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用.和堆一样 ...
- 【校招面试 之 C/C++】第14题 C++ 内存分配方式详解——堆、栈、自由存储区、全局/静态存储区和常量存储区(堆栈的区别)
栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区.里面的变量通常是局部变量.函数参数等.在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用.和堆一样 ...
- 详解分布式应用程序协调服务Zookeeper
主从结构:HDFS.Yarn.HBase.storm.spark.zookeeper都存在单点故障问题 hadoop1.x没有解决方案 hadoop2.x利用zookeeper实现HA zookeep ...
随机推荐
- python的扩展包requests的高级用法
Python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的 API 太渣了.它是为另一个时代.另一个互联网所创建的.它需要巨量的工作,甚至包括各种方法覆盖,来完成最 ...
- 一个是EF内联多表查询,一个是EF中写SQL文。
public IList<MenuModel> GetAllMenu() { using (IMMEntities context = new IMMEntities()) { var m ...
- SpringSecurityOAuth认证配置及Token的存储
⒈pom依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...
- go 单引号,双引号,反引号区别
go里面双引号是字符串,单引号是字符,不存在单引号字符串. 但有反引号字符串,就是esc键下面1键左边tab键上面那个键,区别是反引号字符串允许换行符
- 海马玩模拟器——搭建React Native环境
Visual Studio Emulator for Android 模拟器国内这网络环境不太用,所以使用海马玩模拟器,给大家推荐一下! 下面开始配置环境: 1)下载1.8+JDK,配置JDK环境参考 ...
- 【转】python模块分析之typing(三)
[转]python模块分析之typing(三) 前言:很多人在写完代码一段时间后回过头看代码,很可能忘记了自己写的函数需要传什么参数,返回什么类型的结果,就不得不去阅读代码的具体内容,降低了阅读的速度 ...
- python中的正则表达式--re模块
参考博客:https://www.cnblogs.com/tina-python/p/5508402.html 这里说一下python的re模块即正则表达式模块,先列出其中涉及到的各种字符和模式等: ...
- python使用pudb调试
pudb是pdb的升级版本 安装 pip3 install pudb 使用方法 在程序文件的开头导入包 from pudb import set_trace set_trace()#断点位置 运行的时 ...
- fabric.js PatternBrush
// Original canvas const canvas = new fabric.Canvas('canvas'); fabric.Image.fromURL('https://picsum. ...
- 简单的三级联动demo
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...