【Hadoop】2、Hadoop高可用集群部署
1.服务器设置
集群规划
Namenode-Hadoop管理节点
10.25.24.92
10.25.24.93
Datanode-Hadoop数据存储节点
10.25.24.89
10.25.24.90
10.25.24.91
Zookeeper—高可用推举机制
1- 标识需要安装
NN-namenode
DN-datanode
|
服务器名 |
NN |
DN |
ZK |
|
|
10.25.24.92 |
jyh-zhzw-inline-25 |
1 |
1(1) |
|
|
10.25.24.93 |
jyh-zhzw-inline-26 |
1 |
1(2) |
|
|
10.25.24.91 |
jyh-zhzw-inline-24 |
1 |
1(5) |
1.1 设置hostname
用root用户


重启网络服务
2.设置ssh免密登录
ssh-keygen -t rsa
ssh-keygen -m PEM -t rsa
(这个是生成PEM的模式)
这里重新设置免密登录
获取到公钥文件之后,复制所有公钥到一个文件,然后分发到各个服务器
cat id_rsa.pub > authorized_keys

设置文件权限,authoriz.. 必须是600
重新生成rsa密钥:
清空所有的authorized_keys
拷贝其他主机的id_rsa.pub到临时目录,并追加内容到authorized_keys
Ip依次改动91,92,93,94
scp oss@10.25.24.94:/home/oss/.ssh/id_rsa.pub ./tmp/
cat ./tmp/id_rsa.pub >> authorized_keys
最后修改权限chmod 600 authorized_keys
然后拷贝文件到各个子节点
3.Zookeeper配置
下载地址:https://apache.org/dist/zookeeper/zookeeper-3.4.13/
上传服务器,并解压
tar -zxvf zookeeper-3.4.13.tar.gz
创建zk数据目录
/home/oss/hadoop/zookeeper-3.4.13/zkData
如果要启动zookeeper首先必须配置conf/zoo.cfg文件
cp zoo_sample.cfg zoo.cfg
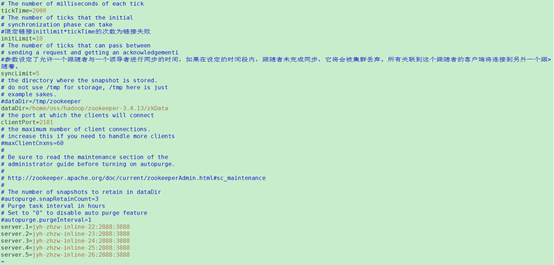
最后的server.x
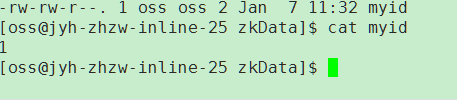
注意server.x 这个X一定要和myid对应起来,并且前面不用的服务器先注解调
4.设置Hadoop配置文件
4.1设置Hadoop的jdk路径




4.2 设置hdfs配置

设置一个逻辑名称,定义一个新的集群名称
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
配置这个namenode下的其他集群
- <property>
- <name>dfs.ha.namenodes.mycluster</name>
- <value>nn1,nn2</value>
- </property>
这里注意下,如果有NFS共享磁盘,那么我们
<property>
<name>dfs.namenode.shared.edits.dir[x3] </name>
<value>file:///mnt/filer1/dfs/ha-name-dir-shared</value>
</property>
可以配置一个绝对路径
总体配置:
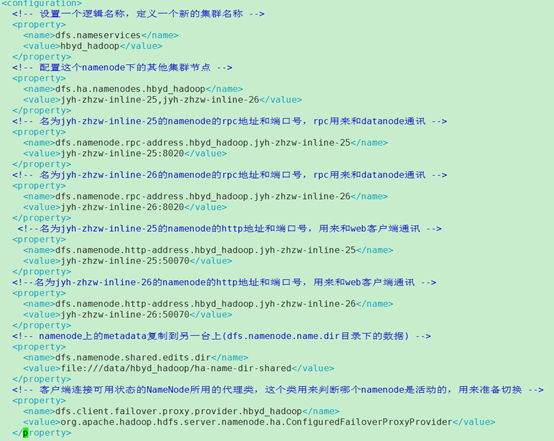
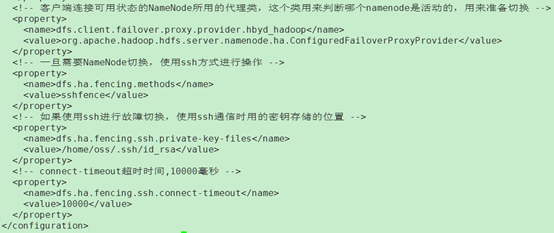
如果使用高可用HA配置,使用ZK部署,那么还需要配置
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
4.3 修改core-site.xml
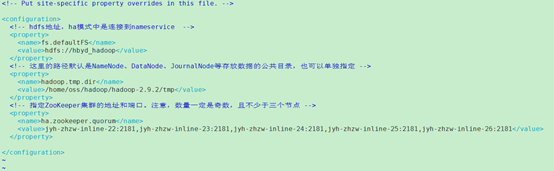
4.4 采用yarn作为mapreduce的资源调度框架
vi mapred-site.xml
这个运行框架可选:
local, classic or yarn.
Local:则不会使用YARN集群来分配资源,在本地节点执行。在本地模式运行的任务,无法发挥集群的优势
Yarn: mapreduce.framework.name设置为yarn,当客户端配置mapreduce.framework.name为yarn时, 客户端会使用YARNRunner与服务端通信, 而YARNRunner真正的实现是通过ClientRMProtocol与RM交互, 包括提交Application, 查询状态等功能
老一些的版本还有一个JobTracker的实现类,即:classic。用于和MapReduce1.X兼容用的,高一些的版本已经没有这个实现类了。
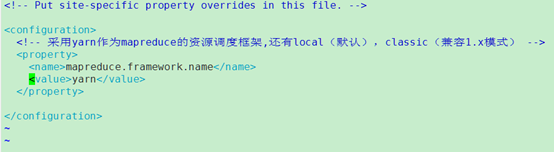
编辑配置yarn-site.xml

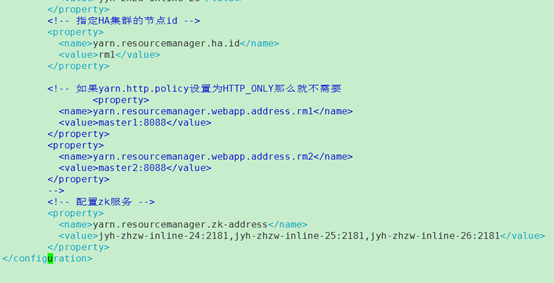
4.5 配置文件设置子文件
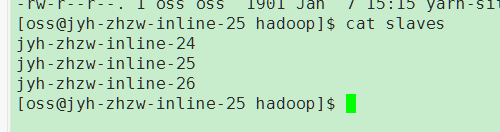
5.启动集群
配置path环境变量bin目录
如果手动管理集群上的服务,则需要在运行名称节点的每台计算机上手动启动zkfc守护程序。
./hadoop-daemon.sh --script /home/oss/hadoop/hadoop-2.9.2/bin/hdfs start zkfc
5.1 启动zk
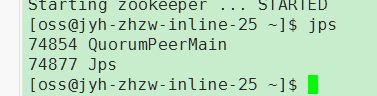
每个节点都启动一下

5.2 启动Hadoop集群
格式化namenode
- [hdfs]$ $HADOOP_PREFIX/bin/hdfs namenode -format <cluster_name>
hdfs namenode -format hbyd_hadoop
启动namenode
- [hdfs]$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
启动namenode
./hadoop-daemon.sh --config /home/oss/hadoop/hadoop-2.9.2/etc/hadoop --script hdfs start namenode
如果ssh配置好了,启动所有hdfs配置
Sbin/start-dfs.sh
格式化ZK(只用在一台namenode上执行)
Hdfs zkfc -formatZK
Hadoop启动ZK管控切换
./hadoop-daemon.sh start zkfc
5.3 启动yarn资源管理集群
注意我们需要手动启动另外一个resourceManager节点
yarn-daemon.sh start resourcemanager手动启动。
查看节点状态
yarn rmadmin -getServiceState rm1
active
yarn rmadmin -getServiceState rm1
6.动态添加节点
6.1 添加datanode节点
6.1.1 先设置hostname
这个要root用户
设置主节点到对应子节点的域名配置
92,93设置一下

6.1.2 设置ssh免密登录(2台namenode都要)
ssh-keygen -m PEM -t rsa
(这个是生成PEM的模式)
这里重新设置免密登录
获取到公钥文件之后,复制所有公钥到一个文件,然后分发到各个服务器
cat id_rsa.pub > authorized_keys

设置文件权限,authoriz.. 必须是600
重新生成rsa密钥:
清空所有的authorized_keys
拷贝其他主机的id_rsa.pub到临时目录,并追加内容到名称节点的authorized_keys
6.1.3 部署子节点
拷贝Hadoop部署包到相应的子节点
修改主节点slave文件,添加新增节点的ip信息(集群重启时使用)
6.1.4 启动datanode节点
配置子节点环境变量(子节点对namenode也要互通)
运行sbin/hadoop-daemon.sh start datanode
启动子节点nodemanager
6.1.5 启动子节点yarn服务
在新增节点,运行sbin/yarn-daemon.sh start nodemanager即可
问题:
1.无法启动namenode,显示50070端口被占用
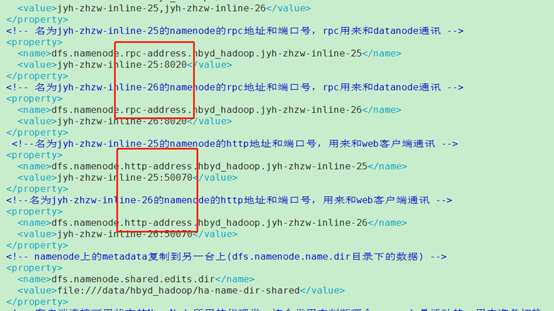
之前把http-address写成了rcp和上面重复了
2.第二个namenode无法启动,namespaceid冲突
是否是第二个节点没有格式化
拷贝namenode1的tmp目录中的namenode的配置文件进入第二个namenode节点的tmp目录中
3.部署好了无法切换namenode Unable to fence service by any configured method
2019-01-09 14:27:59,677 INFO org.apache.hadoop.ha.NodeFencer: Trying method 1/1: org.apache.hadoop.ha.SshFenceByTcpPort(null)
2019-01-09 14:27:59,677 WARN org.apache.hadoop.ha.SshFenceByTcpPort: Unable to create SSH session
com.jcraft.jsch.JSchException: invalid privatekey: [B@54e5974c
提示是SSH错误的密钥
这里我们改一下配置试一下
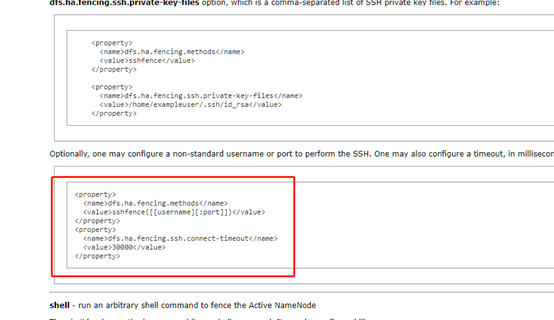
最后发现是centos7默认生成的密钥文件是OPENSSH开头的
- 而JSch
无法识别。。。。
只能识别-----BEGIN RSA PRIVATE KEY-----这种
气死我了,浪费我时间。。。。,这个算jsch自己的不完善吧。。。
[x1]参数设定了允许一个跟随者与一个领导者进行同步的时间,如果在设定的时间段内,跟随者未完成同步,它将会被集群丢弃。所有关联到这个跟随者的客户端将连接到另外一个跟随着。
[x2]表单server.x的条目列出了组成ZooKeeper服务的服务器。当服务器启动时,它通过在dataDir中查找文件myid来知道它是哪个服务器。该文件包含服务器号,以ASCII格式。
[x3]上述配置调整完毕后,我们就可以启动journalNodes守护进程,默认的"sbin/start-dfs.sh"脚本会根据"dfs.namenode.shared.edits.dir"配置,在相应的Datanode上启动journalNodes。当然我们可以使用::"bin/hdfs start journalnode"分别在相应的机器上启动。
一旦JournalNodes启动成功,它们将会从Namenode上同步metadata。
1、如果你的HDFS集群是新建的,那么需要在每个Namenode上执行"hdfs namenode -format"指令。
2、如果你的namenodes已经format了,或者是将non-ha转换成ha架构,你应该在将其中一个namenode上的metadata复制到另一台上(dfs.namenode.name.dir目录下的数据),然后在那个没有format的新加入的namenode上执行"hdfs namenode -bootstrapStandby"。运行这个指令需要确保JournalNodes中持有足够多的edits。
3、如果你将一个non-ha的Namenode(比如backup,其已经formated)切换成HA,你需要首先运行"hdfs -initializeSharedEdits",这个指令将本地Namenode中的edits初始化Journalnodes。
此后,你就可以启动HA Namenodes。可以通过配置指定的HTTP地址(dfs.namenode.https-address)来查看各个Namenode的状态,Active or Standby。
【Hadoop】2、Hadoop高可用集群部署的更多相关文章
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- RocketMQ的高可用集群部署
RocketMQ的高可用集群部署 标签(空格分隔): 消息队列 部署 1. RocketMQ 集群物理部署结构 Rocket 物理部署结构 Name Server: 单点,供Producer和Cons ...
- RabbitMQ的高可用集群部署
RabbitMQ的高可用集群部署 标签(空格分隔): 消息队列 部署 1. RabbitMQ部署的三种模式 1.1 单一模式 单机情况下不做集群, 仅仅运行一个RabbitMQ. # docker-c ...
- rocketmq高可用集群部署(RocketMQ-on-DLedger Group)
rocketmq高可用集群部署(RocketMQ-on-DLedger Group) rocketmq部署架构 rocketmq部署架构非常多,都是为了解决一些问题,越来越高可用,越来越复杂. 单ma ...
- MySQL MHA 高可用集群部署及故障切换
MySQL MHA 高可用集群部署及故障切换 1.概念 2.搭建MySQL + MHA 1.概念: a)MHA概念 : MHA(MasterHigh Availability)是一套优秀的MySQL高 ...
- Hadoop部署方式-高可用集群部署(High Availability)
版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客的高可用集群是建立在完全分布式基础之上的,详情请参考:https://www.cnblogs.com/yinzhengjie/p/90651 ...
- Centos6.9下RocketMQ3.4.6高可用集群部署记录(双主双从+Nameserver+Console)
之前的文章已对RocketMQ做了详细介绍,这里就不再赘述了,下面是本人在测试和生产环境下RocketMQ3.4.6高可用集群的部署手册,在此分享下: 1) 基础环境 ip地址 主机名 角色 192. ...
- Kubernetes容器集群 - harbor仓库高可用集群部署说明
之前介绍Harbor私有仓库的安装和使用,这里重点说下Harbor高可用集群方案的部署,目前主要有两种主流的Harbor高可用集群方案:1)双主复制:2)多harbor实例共享后端存储. 一.Harb ...
- 【转】harbor仓库高可用集群部署说明
之前介绍Harbor私有仓库的安装和使用,这里重点说下Harbor高可用集群方案的部署,目前主要有两种主流的Harbor高可用集群方案:1)双主复制:2)多harbor实例共享后端存储. 一.Harb ...
随机推荐
- ci框架nginx访问
url:http://localhost:20082/index.php/welcome/index 问题:apache环境下可以访问,nginx环境下不可以
- Android学习(三)
学号 20189214 <Android程序开发>第八周学习总结 教材学习内容总结 GridView GridView和ListView一样是AbsListView的子类; 都需要一个Ad ...
- dubbo入门学习 二 RPC框架
rpc框架解释 谁能用通俗的语言解释一下什么是 RPC 框架? - 远程过程调用协议RPC(Remote Procedure Call Protocol) 首先了解什么叫RPC,为什么要RPC,RPC ...
- 464. Can I Win
https://leetcode.com/problems/can-i-win/description/ In the "100 game," two players take t ...
- 解决使用Mybatis 传入多参数使用map封装遇到的 “坑”问题
好久没来写些东西了,今天 我分享一下自己遇到的一个“小 坑”,这也许对您来说不是个问题,但是我还是希望对没有遇到过这类问题的朋友给个小小的帮助吧 是这样的,需求:需要实现根据多条件 且分页展示数据 1 ...
- ApocalypseSomeday
ApocalypseSomeday CountDownLatch和CyclicBarrier分别都是在什么时候使用的? Charles使用(apphttp抓包,request拦截,response拦截 ...
- Atcoder Beginner Contest 115 D Christmas 模拟,递归 B
D - Christmas Time limit : 2sec / Memory limit : 1024MB Score : 400 points Problem Statement In some ...
- javabean转换为map对象
在调用第三方接口发现对方使用map进行接收(不包括秘钥等),将bean类属性转换为map,直接贴代码: /** * JavaBean对象转化成Map对象 * * @param javaBean */p ...
- 16.The Effect of Advertisement 广告的影响
16.The Effect of Advertisement 广告的影响 (1) The appeal of advertising to buying motives can have both n ...
- Day08 (黑客成长日记) 命名空间和作用域
Day08:命名空间和作用域: 1.命名空间: (1)内置命名空间(python解释器): 就是python解释器一旦启动就可以使用的名字储存在内置命名空间中: eg: len() print() a ...