MapReduce的二次排序
附录之前总结的一个例子:
http://www.cnblogs.com/DreamDrive/p/7398455.html
另外两个有价值的博文:
http://www.cnblogs.com/xuxm2007/archive/2011/09/03/2165805.html
http://blog.csdn.net/heyutao007/article/details/5890103
一.MR的二次排序的需求说明
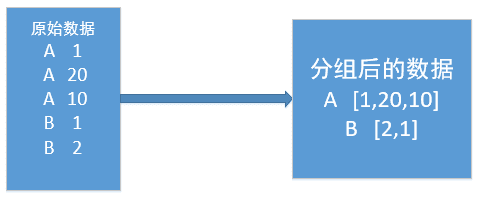
在mapreduce操作时,shuffle阶段会多次根据key值排序。但是在shuffle分组后,相同key值的values序列的顺序是不确定的(如下图)。如果想要此时value值也是排序好的,这种需求就是二次排序。
二.测试的文件数据
| a 1 a 5 a 7 a 9 b 3 b 8 b 10 |
三.未经过二次排序的输出结果
|
四.第一种实现思路
直接在reduce端对分组后的values进行排序。
reduce关键代码
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException { List<Integer> valuesList = new ArrayList<Integer>(); // 取出value
for(IntWritable value : values) {
valuesList.add(value.get());
}
// 进行排序
Collections.sort(valuesList); for(Integer value : valuesList) {
context.write(key, new IntWritable(value));
} }
输出结果:
a 1
a 5
a 7
a 9
b 3
b 8
b 10
很容易发现,这样把排序工作都放到reduce端完成,当values序列长度非常大的时候,会对CPU和内存造成极大的负载。
注意的地方(容易被“坑”)
在reduce端对values进行迭代的时候,不要直接存储value值或者key值,因为reduce方法会反复执行多次,但key和value相关的对象只有两个,reduce会反复重用这两个对象。需要用相应的数据类型.get()取出后再存储。
五.第二种实现思路
将map端输出的<key,value>中的key和value组合成一个新的key(称为newKey),value值不变。这里就变成<(key,value),value>,在针对newKey排序的时候,如果key相同,就再对value进行排序。
需要自定义的地方
1.自定义数据类型实现组合key
实现方式:继承WritableComparable
2.自定义partioner,形成newKey后保持分区规则任然按照key进行。保证不打乱原来的分区。
实现方式:继承partitioner
3.自定义分组,保持分组规则任然按照key进行。不打乱原来的分组
实现方式:继承RawComparator
自定义数据类型关键代码
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable; public class PairWritable implements WritableComparable<PairWritable> {
// 组合key
private String first;
private int second; public PairWritable() {
} public PairWritable(String first, int second) {
this.set(first, second);
} /**
* 方便设置字段
*/
public void set(String first, int second) {
this.first = first;
this.second = second;
} /**
* 反序列化
*/
@Override
public void readFields(DataInput arg0) throws IOException {
this.first = arg0.readUTF();
this.second = arg0.readInt();
}
/**
* 序列化
*/
@Override
public void write(DataOutput arg0) throws IOException {
arg0.writeUTF(first);
arg0.writeInt(second);
} /*
* 重写比较器
*/
public int compareTo(PairWritable o) {
int comp = this.first.compareTo(o.first); if(comp != 0) {
return comp;
} else { // 若第一个字段相等,则比较第二个字段
return Integer.valueOf(this.second).compareTo(
Integer.valueOf(o.getSecond()));
}
} public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
自定义分区规则
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner; public class SecondPartitioner extends Partitioner<PairWritable, IntWritable> { @Override
public int getPartition(PairWritable key, IntWritable value, int numPartitions) {
/*
* 默认的实现 (key.hashCode() & Integer.MAX_VALUE) % numPartitions
* 让key中first字段作为分区依据
*/
return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
自定义分组比较器
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.WritableComparator; public class SecondGroupComparator implements RawComparator<PairWritable> { /*
* 对象比较
*/
public int compare(PairWritable o1, PairWritable o2) {
return o1.getFirst().compareTo(o2.getFirst());
} /*
* 字节比较
* arg0,arg3为要比较的两个字节数组
* arg1,arg2表示第一个字节数组要进行比较的收尾位置,arg4,arg5表示第二个
* 从第一个字节比到组合key中second的前一个字节,因为second为int型,所以长度为4
*/
public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3, int arg4, int arg5) {
return WritableComparator.compareBytes(arg0, 0, arg2-4, arg3, 0, arg5-4);
}
}
map关键代码
private PairWritable mapOutKey = new PairWritable();
private IntWritable mapOutValue = new IntWritable();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String lineValue = value.toString();
String[] strs = lineValue.split("\t"); //设置组合key和value ==> <(key,value),value>
mapOutKey.set(strs[0], Integer.valueOf(strs[1]));
mapOutValue.set(Integer.valueOf(strs[1])); context.write(mapOutKey, mapOutValue);
}
reduce关键代码
private Text outPutKey = new Text();
public void reduce(PairWritable key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//迭代输出
for(IntWritable value : values) {
outPutKey.set(key.getFirst());
context.write(outPutKey, value);
} }
输出结果:
a 1
a 5
a 7
a 9
b 3
b 8
b 10
原理:
在map阶段:
使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块splites,同时InputFormat提供一个RecordReder的实现。
本例子中使用的是TextInputFormat,他提供的RecordReder会将文本的一行的行号作为key,这一行的文本作为value。这就是自定义Map的输入是<LongWritable, Text>的原因。
然后调用自定义Map的map方法,将一个个<LongWritable, Text>对输入给Map的map方法。注意输出应该符合自定义Map中定义的输出<IntPair, IntWritable>。最终是生成一个List<IntPair, IntWritable>。
在map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,每个分区映射到一个reducer。每个分区内又调用job.setSortComparatorClass设置的key比较函数类排序。
可以看到,这本身就是一个二次排序。如果没有通过job.setSortComparatorClass设置key比较函数类,则使用key的实现的compareTo方法。
在reduce阶段:
reducer接收到所有映射到这个reducer的map输出后,也是会调用job.setSortComparatorClass设置的key比较函数类对所有数据对排序。
然后开始构造一个key对应的value迭代器。这时就要用到分组,使用jobjob.setGroupingComparatorClass设置的分组函数类。
只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器,而这个迭代器的key使用属于同一个组的所有key的第一个key。
最后就是进入Reducer的reduce方法,reduce方法的输入是所有的(key和它的value迭代器)。同样注意输入与输出的类型必须与自定义的Reducer中声明的一致。
MapReduce的二次排序的更多相关文章
- MapReduce自定义二次排序流程
每一条记录开始是进入到map函数进行处理,处理完了之后立马就入自定义分区函数中对其进行分区,当所有输入数据经过map函数和分区函数处理完之后,就调用自定义二次排序函数对其进行排序. MapReduce ...
- Mapreduce实例--二次排序
前言部分: 在Map阶段,使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块splites,同时InputFormat提供一个RecordRed ...
- MapReduce二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- MapReduce 二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop.2.x_高级应用_二次排序及MapReduce端join
一.对于二次排序案例部分理解 1. 分析需求(首先对第一个字段排序,然后在对第二个字段排序) 杂乱的原始数据 排序完成的数据 a,1 a,1 b,1 a,2 a,2 [排序] a,100 b,6 == ...
- Hadoop学习笔记: MapReduce二次排序
本文给出一个实现MapReduce二次排序的例子 package SortTest; import java.io.DataInput; import java.io.DataOutput; impo ...
- (转)MapReduce二次排序
一.概述 MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的.在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求 ...
随机推荐
- windows2012 raid架构 忘记系统管理员密码的解决方法
1. http://bbs.51cto.com/thread-939710-1.html 2. https://wenku.baidu.com/view/115783cd0b4e767f5acfcef ...
- RT-thread-------------------信号量
信号量:用于解决线程间同步问题的内核对象,线程可以获取或释放它,从而达到同步或互斥的目的.(互斥量只能由持有线程释放,而信号量则可以由任何线程释放) 在rtt中,信号量分为计数型信号量和二值信号量(作 ...
- 主要的Ajax框架都有什么?
* Dojo(dojotoolkit.org):* Prototype和Scriptaculous (www.prototypejs.org和script.aculo.us):* Direct We ...
- AJAX随笔1
[1] AJAX简介 > 全称: Asynchronous JavaScript And XML > 异步的JavaScript和XML > AJAX就是通过JavaSc ...
- zookeeper名字服务
10.12.67.31 #!/bin/shmkdir -p /data/zk-install/cd /data/zk-install/wget -q -O ons_agent-1.0.5.tar.gz ...
- Unity3D编辑器扩展(六)——模态窗口
前面我们已经写了5篇关于编辑器的,这是第六篇,也是最后一篇: Unity3D编辑器扩展(一)——定义自己的菜单按钮 Unity3D编辑器扩展(二)——定义自己的窗口 Unity3D编辑器扩展(三)—— ...
- PLSQL设置细节
1. tnsnames.ora 文件设置中,前面不能包含空格,否则:无法解析连接字符串 2. 当一切配置都正确,但是还是无法连接:“身份证明检索失败” 解决:打开tns_admin配置连接串的目录,修 ...
- CentOS 6下升级Python版本
CentOS6.8默认的python版本是2.6,而现在好多python组件开始只支持2.7以上的版本,比如说我今天遇到的pip install pysqlite,升级python版本是一个痛苦但又常 ...
- SVN服务端和客户端的说明与操作
版权声明:本文为博主原创文章,转载请注明原文出处. https://blog.csdn.net/zzfenglin/article/details/50936888 本节我们进一步了解SVN服务端和客 ...
- Storm知识点笔记
Spark和Storm Spark基于MapReduce算法实现的分布式计算,不同于MapReduce的是,作业中间结果可以保存在内存中,而不要再读写HDFS, Spark适用于数据挖掘和机器学习等需 ...