day16 函数的用法:内置函数,匿名函数
思维导图需要补全 :

一共有68个内置函数:

- #内置:python自带
- # def func():
- # a = 1
- # b = 2
- # print(locals())
- # print(globals())
- # func()
- # range(100) #[0,100)
- # range(5,100) #[5,100)
- # range(1,100,2)
- #可迭代对象,可以for循环,惰性运算
- # range(100).__iter__()
- # iterator = iter(range(100)) #拿到一个迭代器
- # print(iterator.__next__())
- # print(next(iterator))
- # for i in range(100):
- # print(i)
- # def iter():
- # return range(100).__iter__()
- # print(dir([]))
- # print(dir(5))
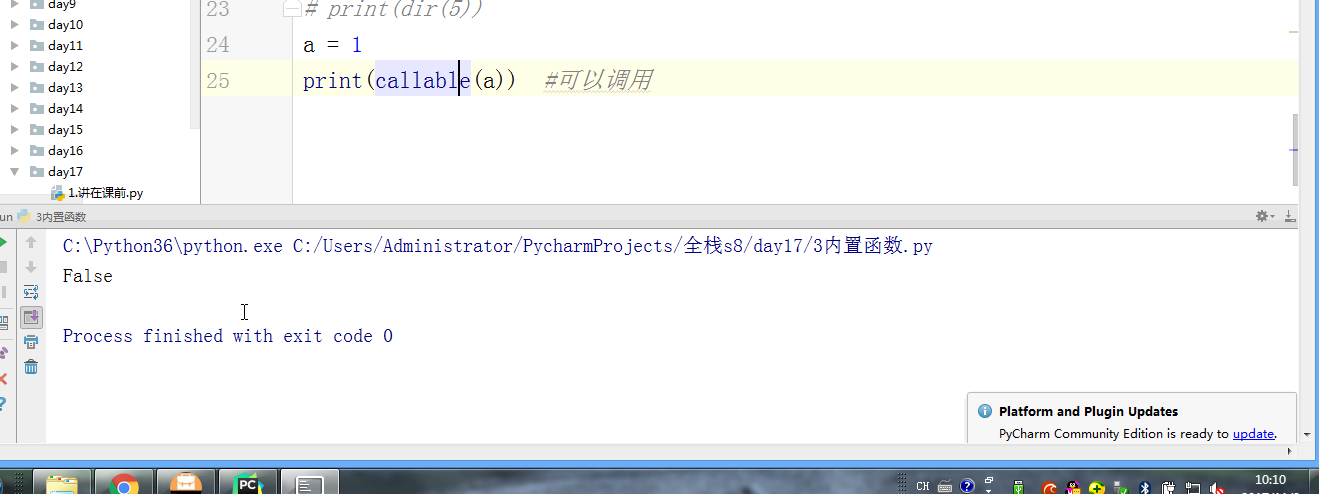
- # a = 1
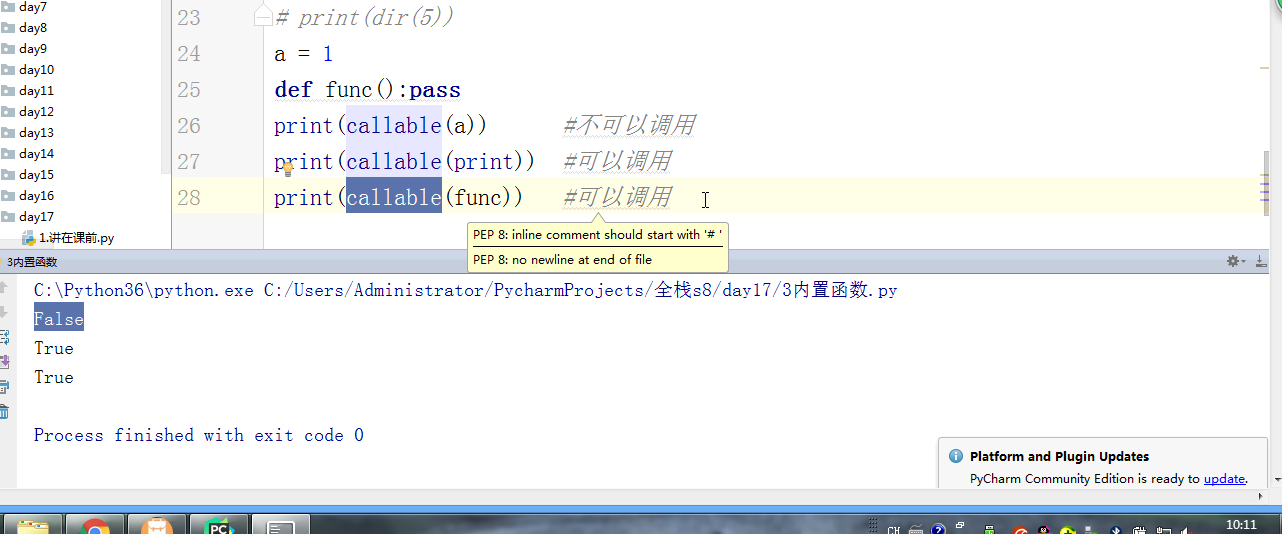
- # def func():pass
- # print(callable(a)) #不可以调用
- # print(callable(print)) #可以调用
- # print(callable(func)) #可以调用
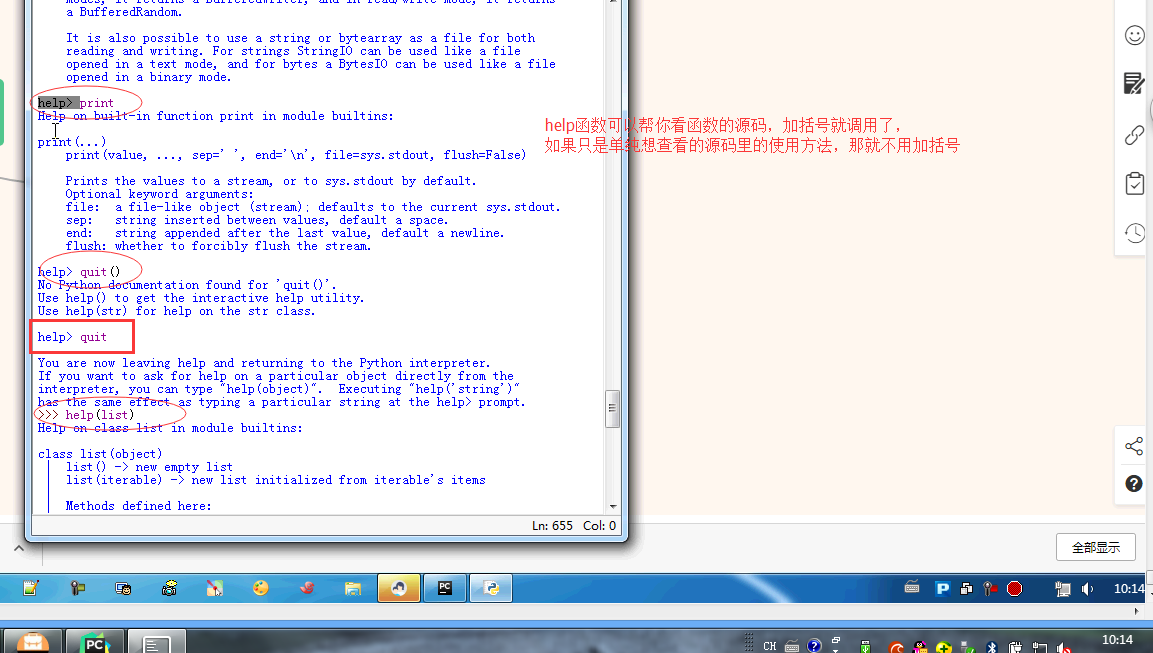
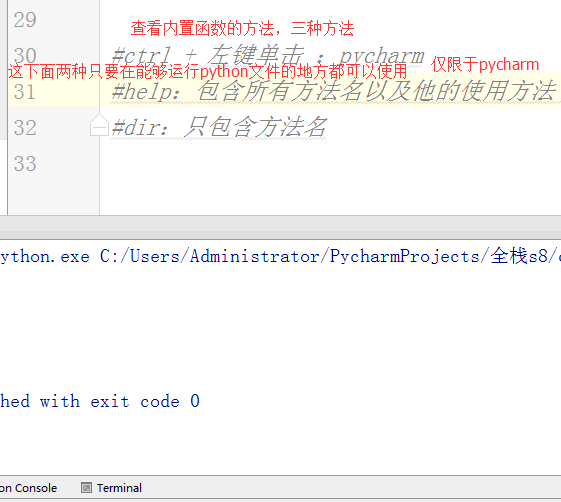
- #ctrl + 左键单击 :pycharm
- #help:包含所有方法名以及他的使用方法 —— 不知道用法
- #dir:只包含方法名 —— 想查看某方法是否在这个数据类型中
- import time #时间
- import os #操作系统
- # f = open('文件名','w',encoding='utf-8')
- #打开模式:r、w、a、rb、wb,ab
- #编码 utf-8/GBK
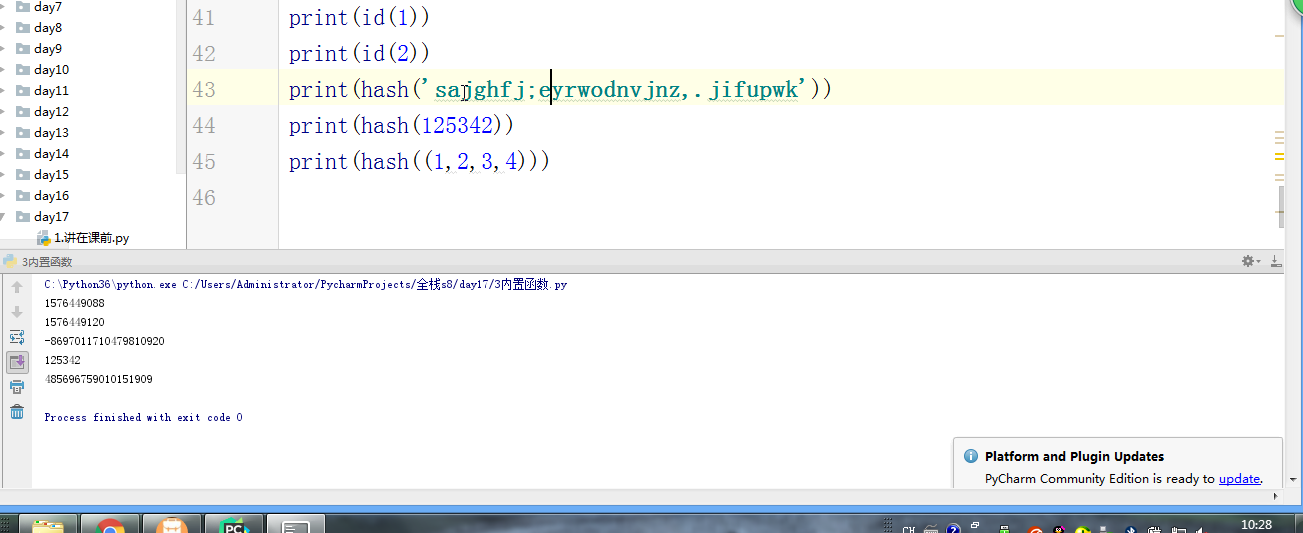
- # print(id(1))
- # print(id(2))
- # print(hash('sajghfj;eyrwodnvjnz,.jifupwk')) #算法
- # print(hash(125342))
- # print(hash((1,2,3,4)))
- #数据的存储和查找
- #模块:hashlib
- # {'k':'v'}
- # [1,2,3,4,5,6,]
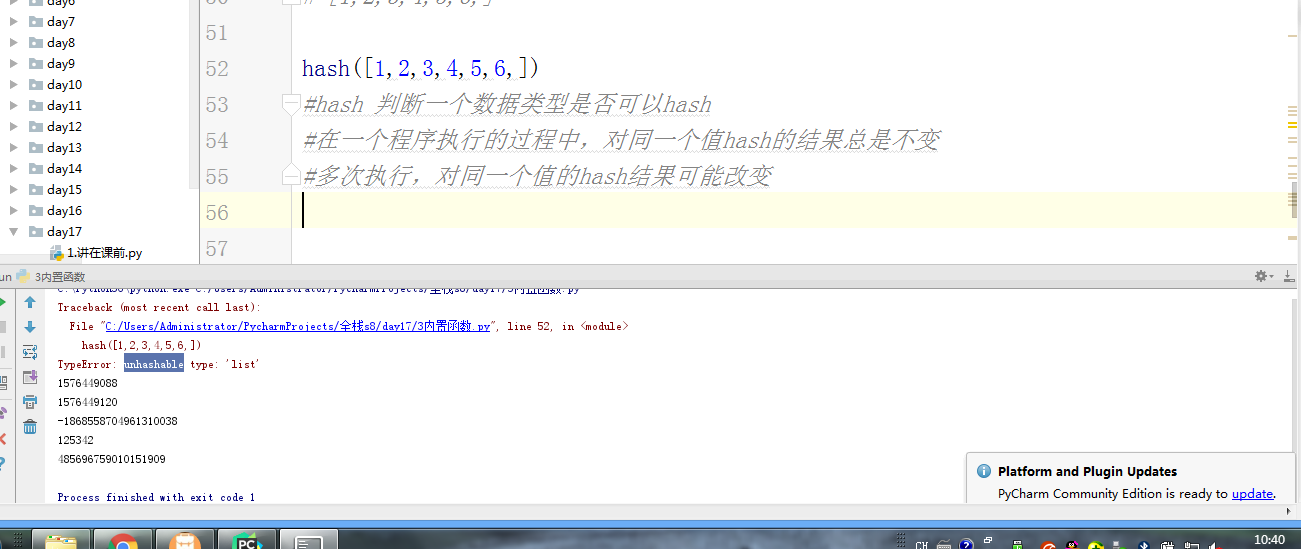
- # hash([1,2,3,4,5,6,])
- #hash 判断一个数据类型是否可以hash
- #在一个程序执行的过程中,对同一个值hash的结果总是不变
- #多次执行,对同一个值的hash结果可能改变
- # s = input('提示:')
- # print(1,2,3,4,5,sep='*') #sep是指定多个要打印的内容之间的分隔符
- # print(1,2,sep=',') #print('%s,%s'%(1,2))
- # f = open('a','w')
- # print('abc\n')
- # print(2)
- # import time
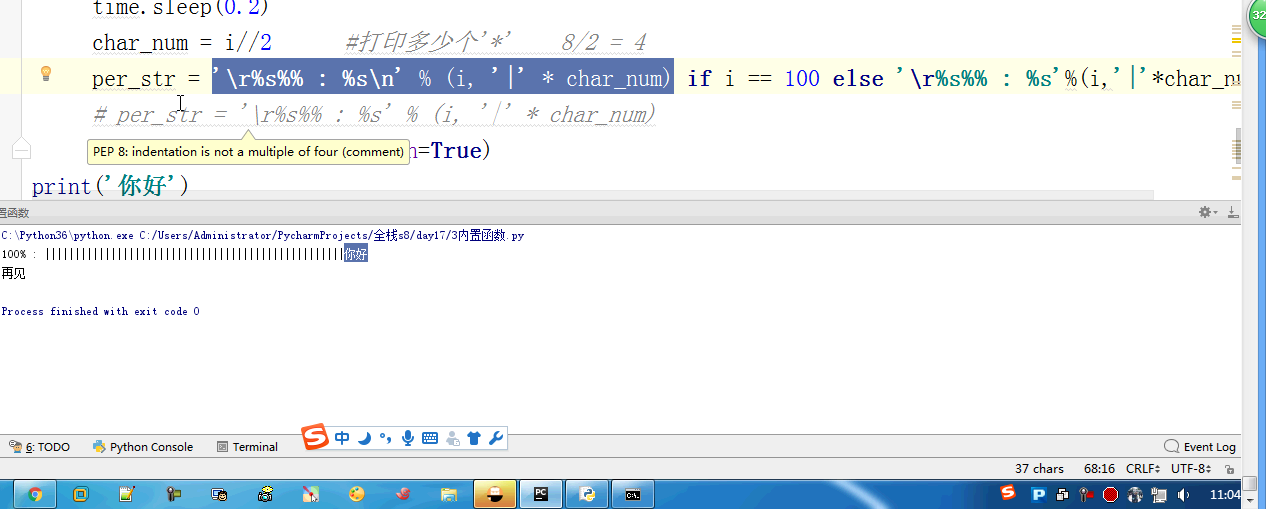
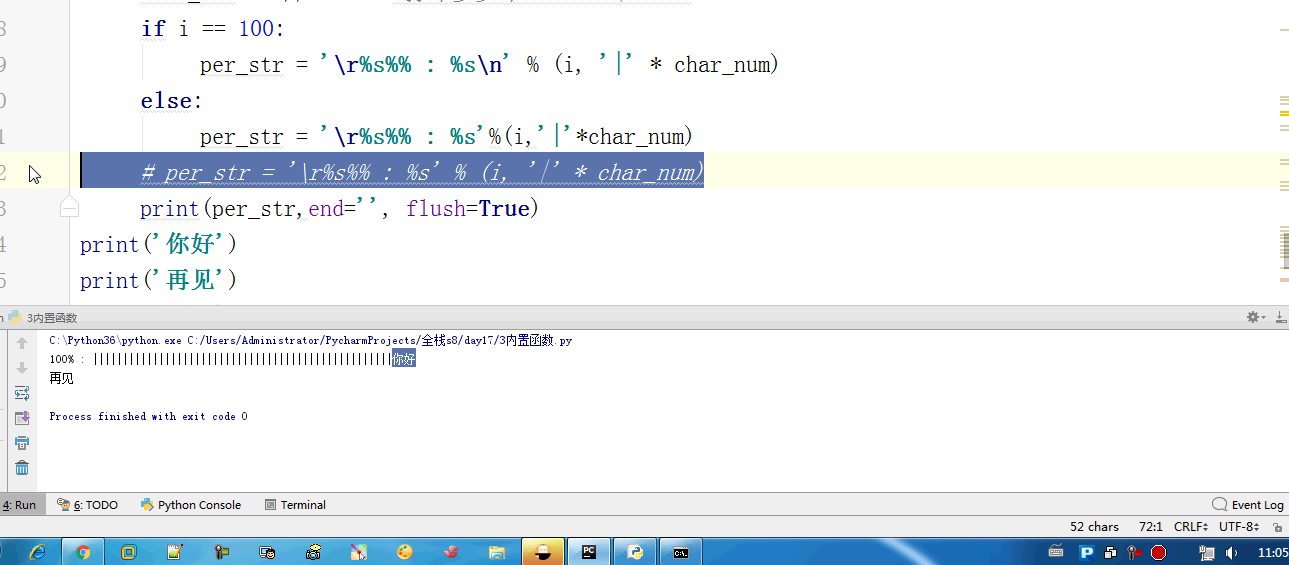
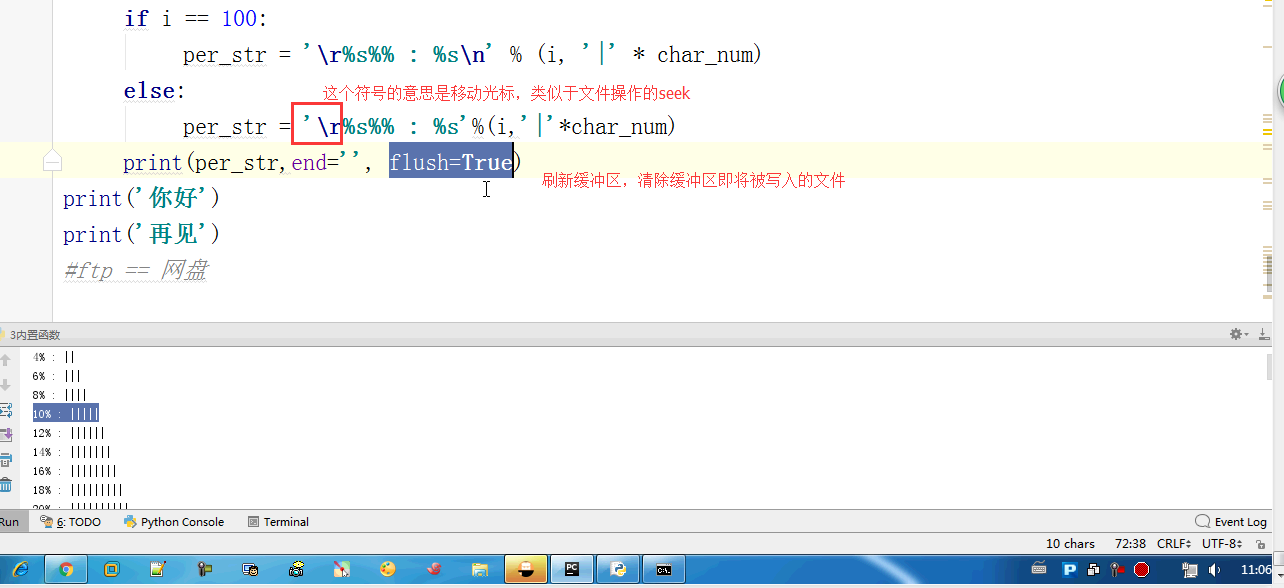
- # for i in range(0,101,2): #[0,2,4,6,8...100]
- # time.sleep(0.2)
- # char_num = i//2 #打印多少个'*' 8/2 = 4
- # if i == 100:
- # per_str = '\r%s%% : %s\n' % (i, '|' * char_num)
- # else:
- # per_str = '\r%s%% : %s'%(i,'|'*char_num)
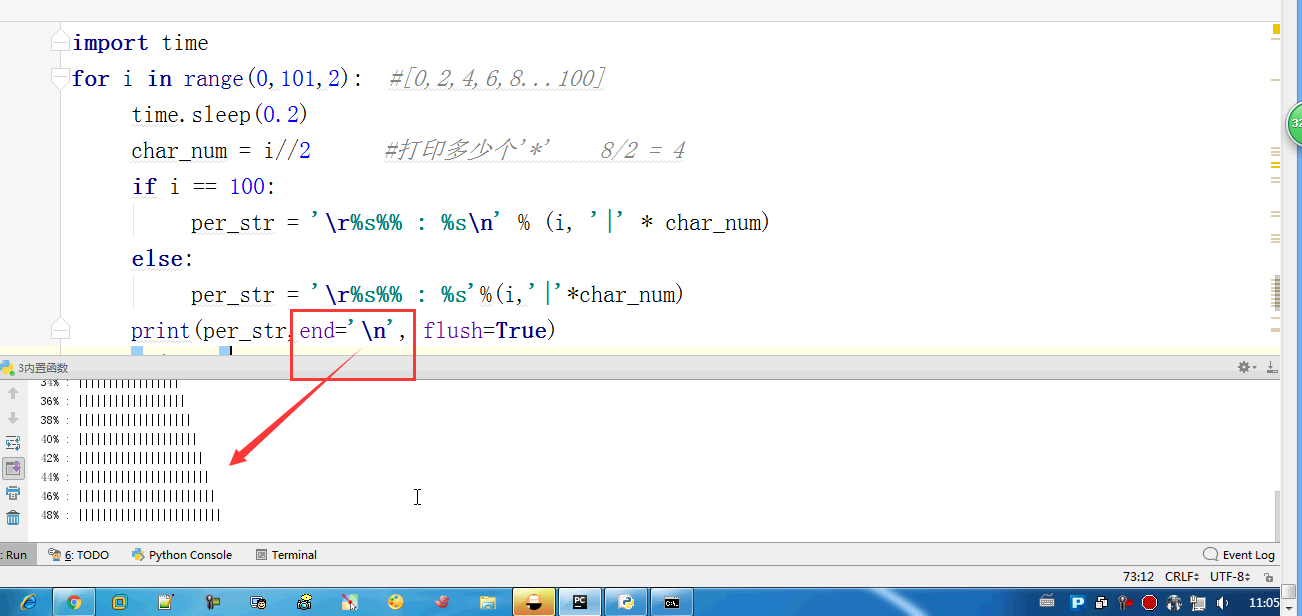
- # print(per_str,end='', flush=True)
- # print('你好')
- # print('再见')
- #ftp == 网盘
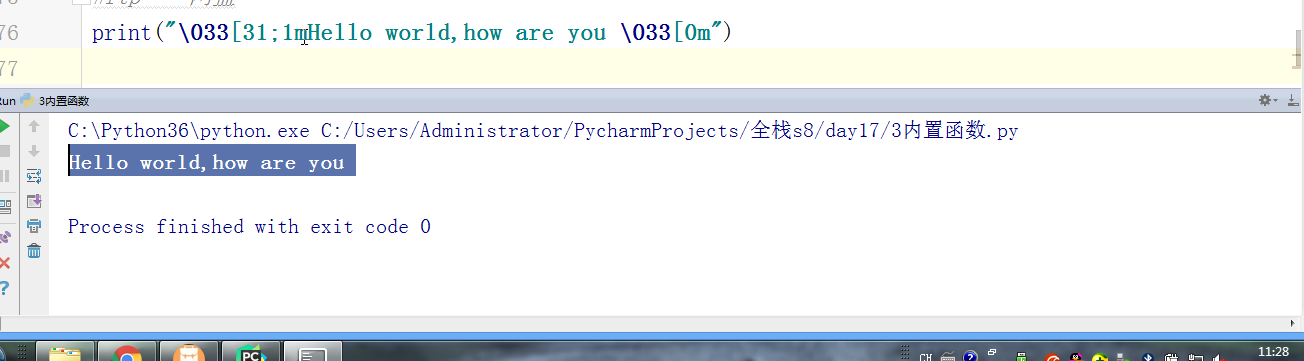
- # print("\033[31;1mHello world,how are you \033[0m")
- # print('\033[4;32;41m金老师')
- # print('egon')
- # print('alex \033[0m')
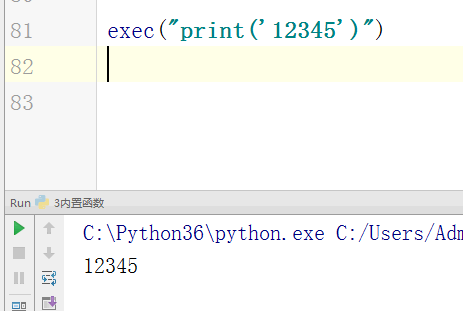
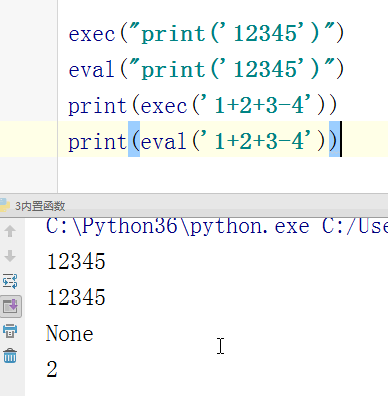
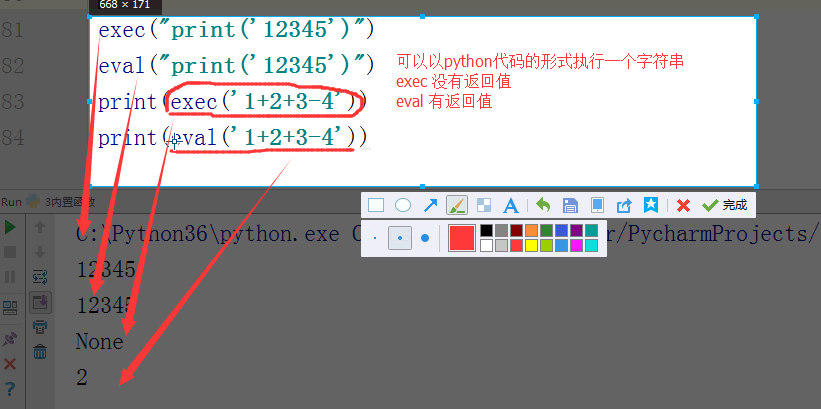
- # exec("print('12345')")
- # eval("print('12345')")
- # print(exec('1+2+3-4'))
- # print(eval('1+2+3-4'))
- # a = 1+2+3-4
- # print(1+2+3-4)
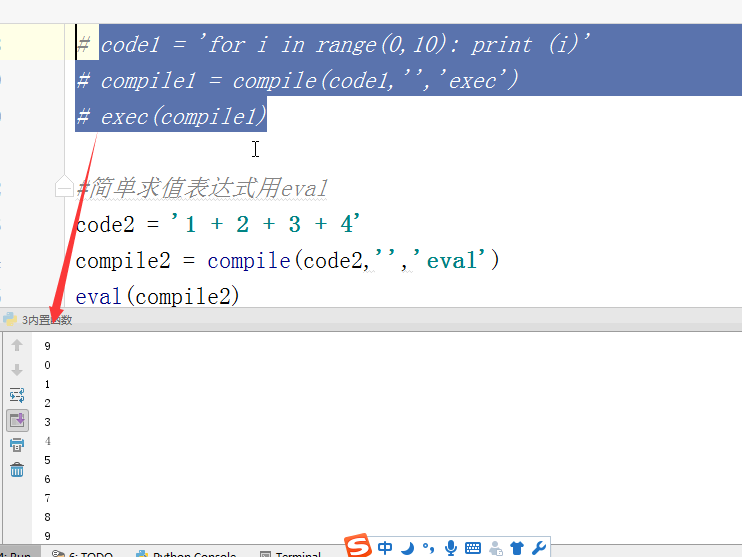
- # code1 = 'for i in range(0,10): print (i)'
- # compile1 = compile(code1,'','exec')
- # exec(compile1)
- #简单求值表达式用eval
- # code2 = '1 + 2 + 3 + 4'
- # compile2 = compile(code2,'','eval')
- # print(eval(compile2))
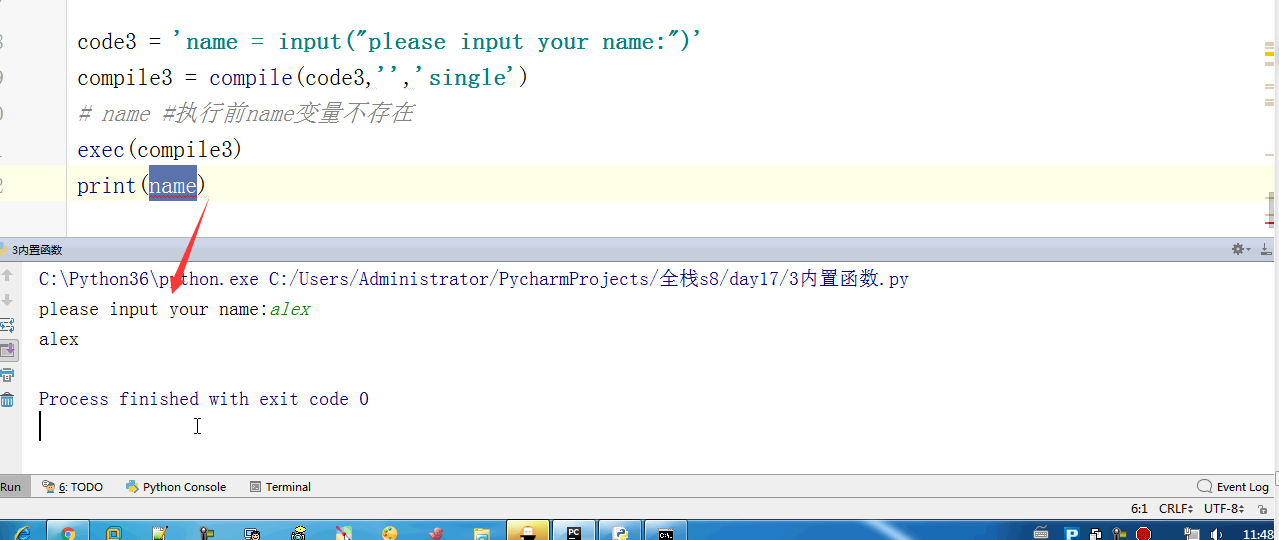
- # code3 = 'name = input("please input your name:")'
- # compile3 = compile(code3,'','single')
- # # name #执行前name变量不存在
- # exec(compile3)
- # print(name)
- #exec
- #eval
- #compile
- # print(abs(5))
- # ret = divmod(10,2) #商余
- # print(ret)
- # ret = divmod(3,2)
- # print(ret)
- # ret = divmod(7,2)
- # print(ret)
- #
- #
- # divmod(107,10)
- # print(round(3.14159,2))
- # print(pow(2,3.5)) #幂运算
- # print(pow(3,2))
- # print(pow(2,3,2))
- # print(pow(2,3,3)) #x**y%z
- # print(sum([1,2,3,4,5,6],-2))
- # print(sum(range(100)))
- #sum接收一个可迭代对象
- #min
- # print(min([1,4,0,9,6]))
- # print(min([],default=0))
- print(min([-9,1,23,5],key=abs))#匿名函数
- # print(min({'z':1,'a':2}))
- # t = (-25,1,3,6,8)
- # print(max(t))
- # print(max(t,key = abs))
- # print(max((),default=100))
前情概要:
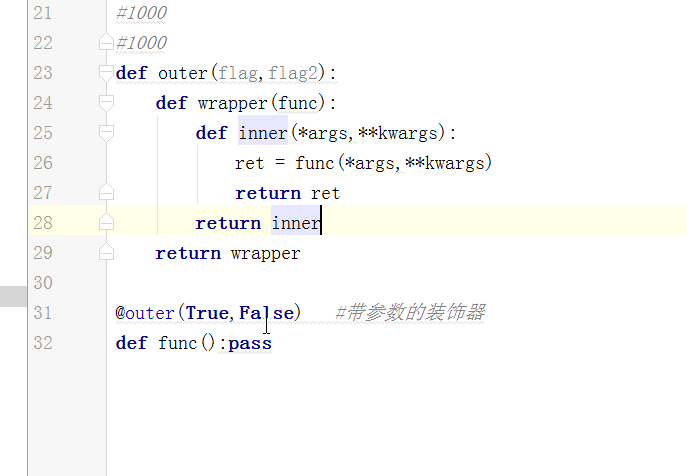
- def wrapper1(func):
- def inner1(*args,**kwargs):
- print('in wrapper 1,before')
- ret = func(*args,**kwargs) #qqxing
- print('in wrapper 1,after')
- return ret
- return inner1
- def wrapper2(func): #inner1
- def inner2(*args,**kwargs):
- print('in wrapper 2,before')
- ret = func(*args,**kwargs) #inner1
- print('in wrapper 2,after')
- return ret
- return inner2
- @wrapper2
- @wrapper1
- def qqxing():
- print('qqxing')
- qqxing() #inner2
内置函数补全:
- # l = [3,4,2,5,7,1,5] #
- # ret = reversed(l)
- # print(ret)
- # print(list(ret))
- # #next ,__next__
- # #for
- # l.reverse()
- # print(l)
- # l = (1,2,23,213,5612,342,43)
- # sli = slice(1,5,2) #实现了切片的函数
- # print(l[sli])
- #
- # #l[1:5:2] 语法糖
- # print(format('test', '<20'))
- # print(format('test', '>20'))
- # print(format('test', '^20'))
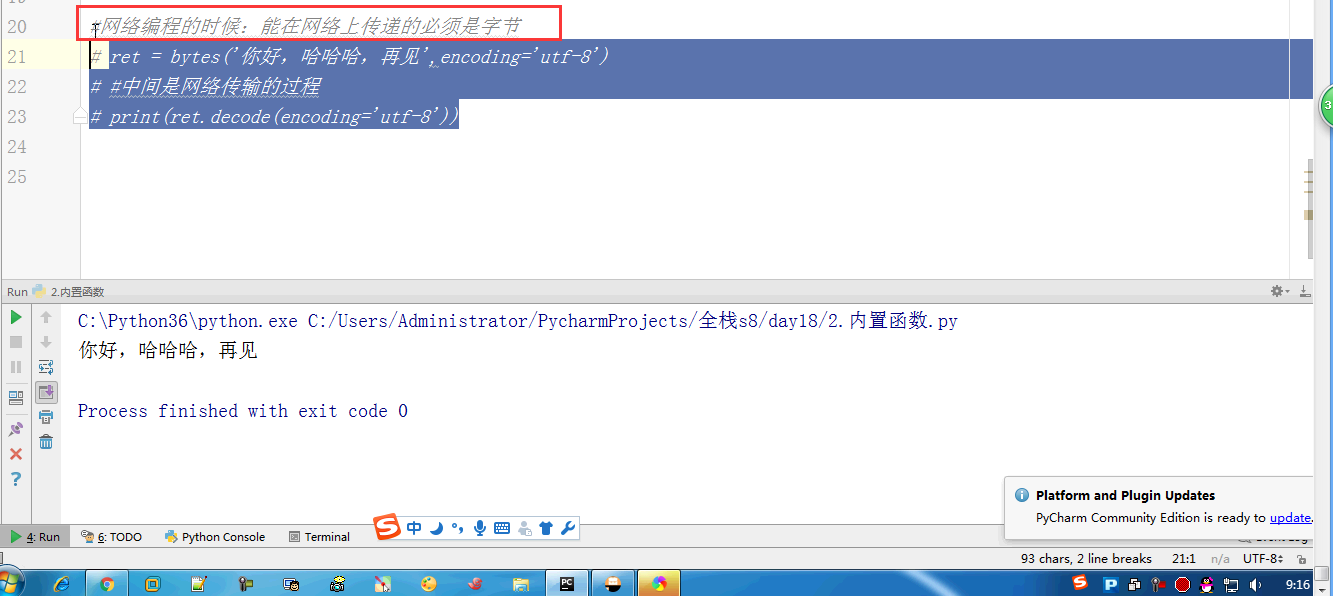
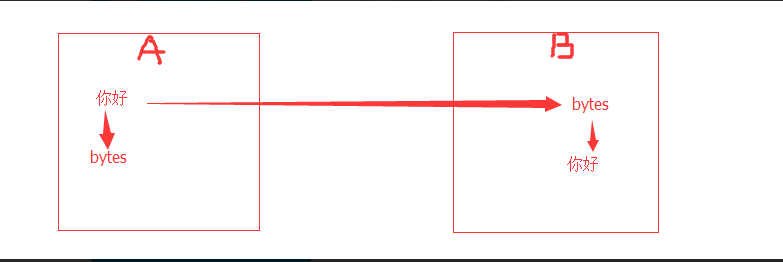
- #网络编程的时候:能在网络上传递的必须是字节
- # ret = bytes('你好,哈哈哈,再见',encoding='utf-8')
- # #中间是网络传输的过程
- # print(ret.decode(encoding='utf-8'))
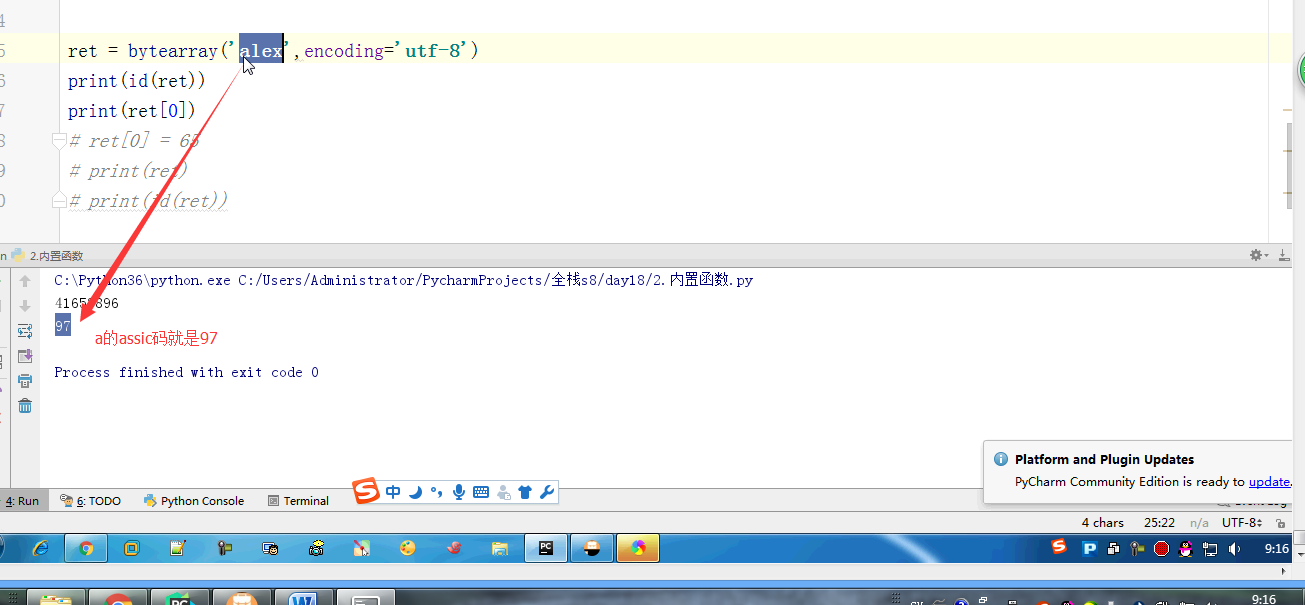
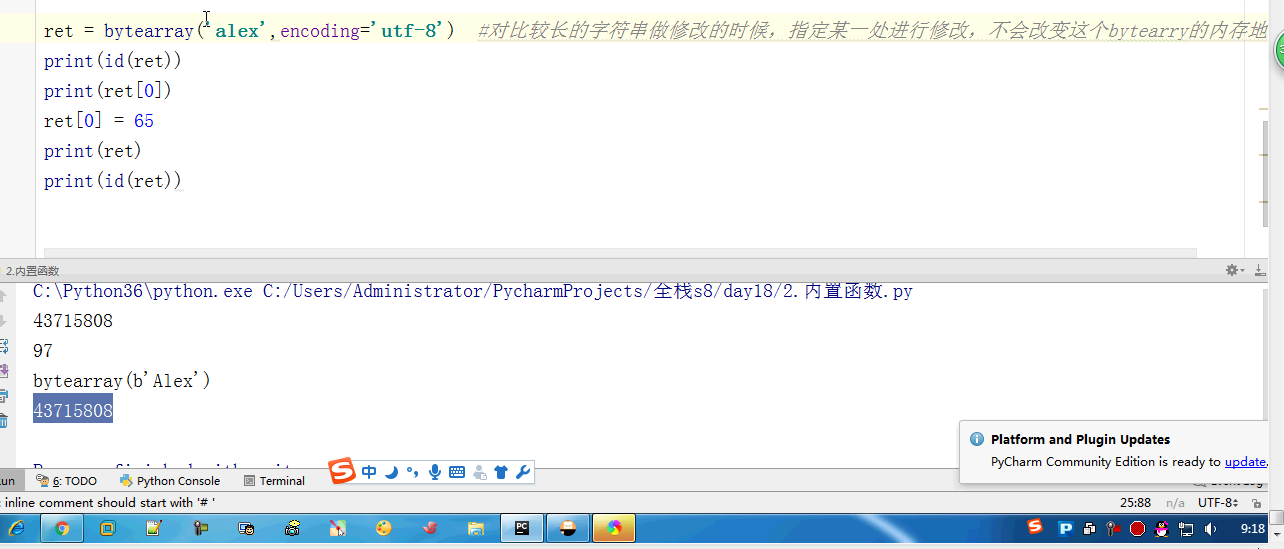
- # ret = bytearray('alex',encoding='utf-8') #对比较长的字符串做修改的时候,指定某一处进行修改,不会改变这个bytearry的内存地址
- # print(id(ret))
- # print(ret[0])
- # ret[0] = 65
- # print(ret)
- # print(id(ret))
- #切片
- # l = [1,2,3,4,5,60]
- # l[1:3]
- # ret = memoryview(bytes('你好',encoding='utf-8'))
- # print(ret)
- # print(len(ret))
- # print(ret[:3])
- # print(bytes(ret[:3]).decode('utf-8'))
- # print(bytes(ret[3:]).decode('utf-8'))
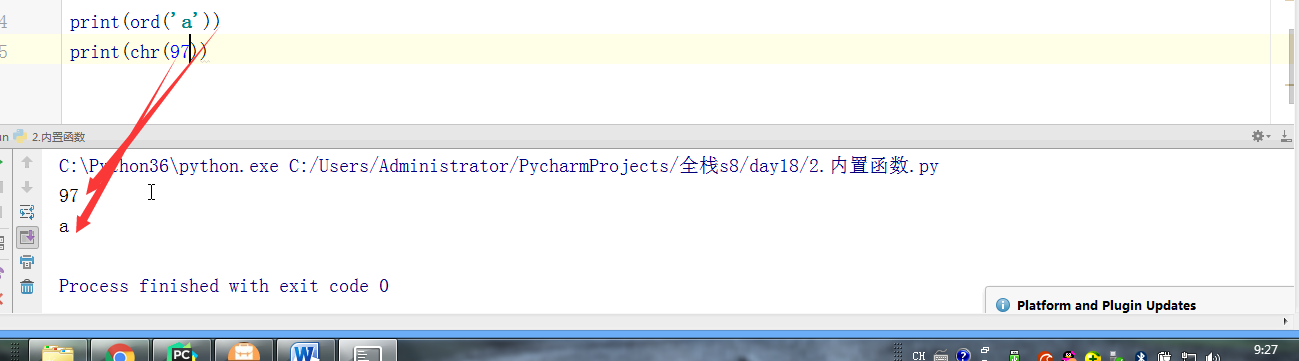
- # print(ord('a'))
- # print(chr(97))
- # print(ascii(97))
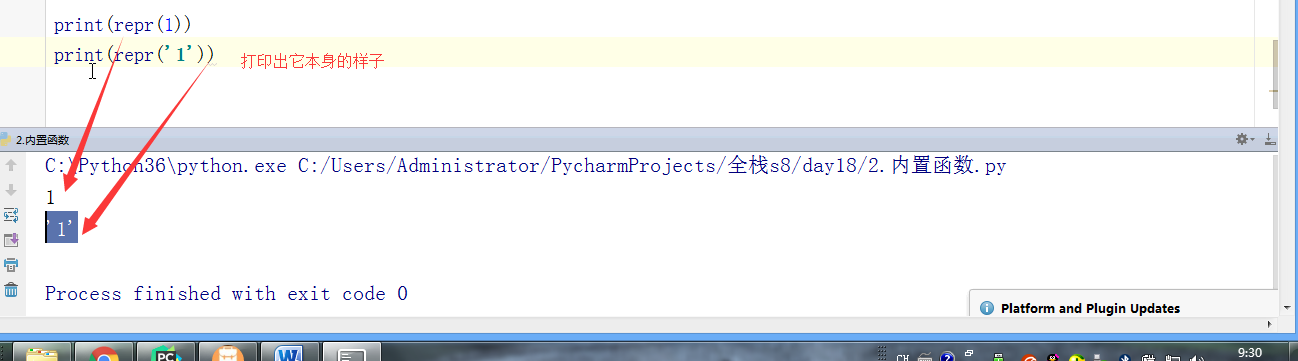
- # print(repr(1))
- # print(repr('1'))
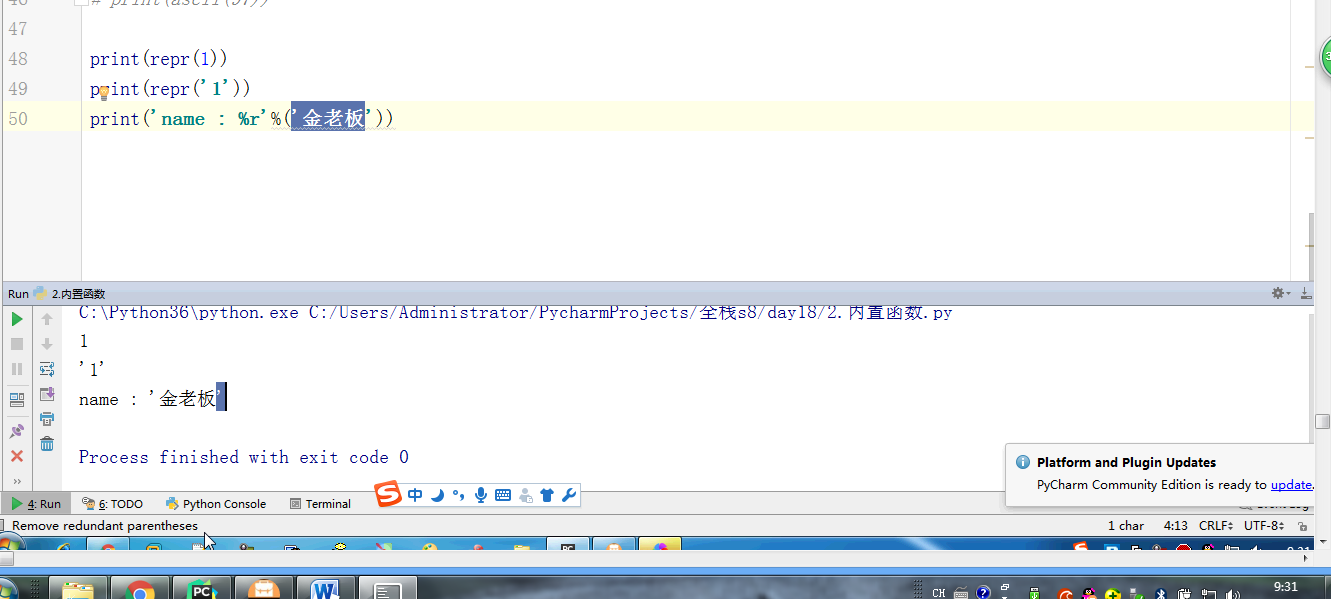
- # print('name : %r'%('金老板'))
- # l = ['笔记本','phone','apple','banana']
- # for i,j in enumerate(l,1):
- # print(i,j)
- # print(all([1,2,3,4,0]))
- # print(all([1,2,3,4]))
- # print(all([1,2,3,None]))
- # print(all([1,2,3,'']))
- # print(any([True,None,False]))
- # print(any([False,None,False]))
- #拉链函数
- # print(list(zip([0,1,2,3,4],[5,6,7,8],['a','b'])))
- #过滤函数
- # def is_odd(x):
- # if x>10:
- # return True
- # ret = filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
- # print(list(ret))
- # def is_odd(x):
- # if x%2 == 0:
- # return True
- # ret = filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
- # print(list(ret))
- #filter就是有一个可迭代对象,想要一个新的内容集,是从原可迭代对象中筛选出来的
- # def func(x):
- # #return x.strip() #‘ ’.strip() ==> '' ==> return False
- # # 'test'.strip() ==> 'test'
- # return x and x.strip() #None False and
- #去掉所有的空内容和字符串中的空格
- # l = ['test', None, '', 'str', ' ', 'END']
- # ret = filter(func,l)
- # print(list(ret))
- #新内容少于等于原内容的时候,才能用到filter
- #新内容的个数等于原内容的个数
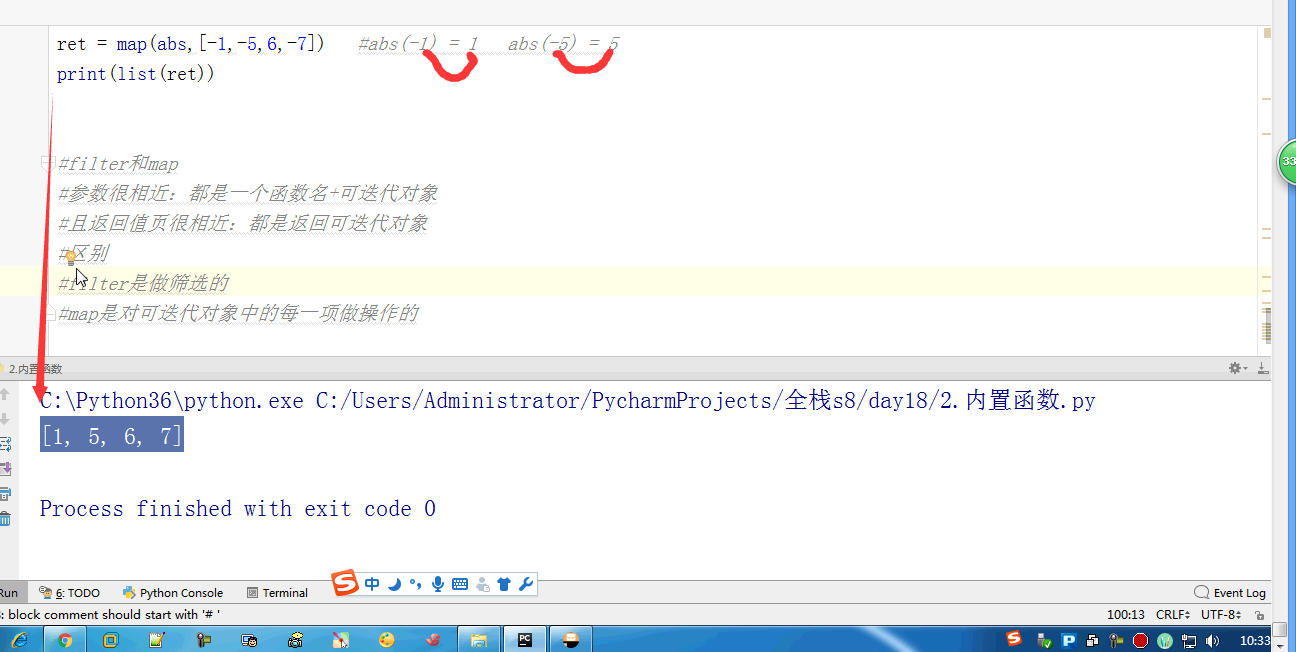
- # ret = map(abs,[-1,-5,6,-7]) #abs(-1) = 1 abs(-5) = 5
- # print(list(ret))
- #filter和map
- #参数很相近:都是一个函数名+可迭代对象
- #且返回值页很相近:都是返回可迭代对象
- #区别
- #filter是做筛选的,结果还是原来就在可迭代对象中的项
- #map是对可迭代对象中的每一项做操作的,结果不一定是原来就在可迭代对象中的项
- #有一个list, L = [1,2,3,4,5,6,7,8],我们要将f(x)=x^2作用于这个list上,那么我们可以使用map函数处理
- # def func(x):
- # return x*x
- # ret = map(func,[1,2,3,4,5,6,7,8])
- # print(list(ret))
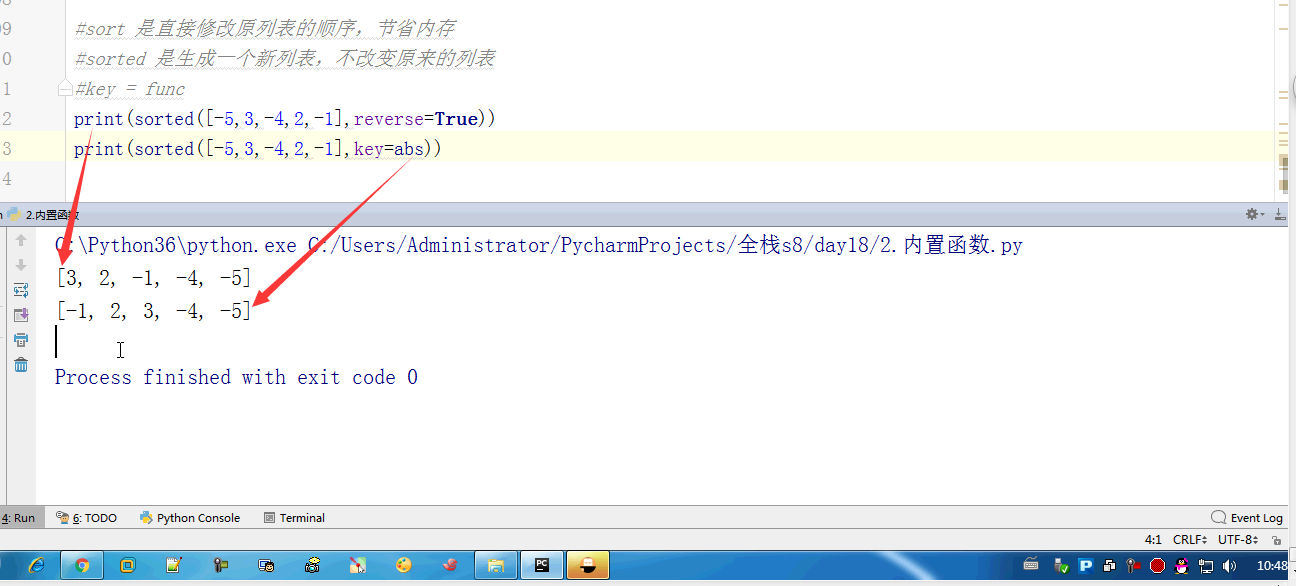
- #sort 是直接修改原列表的顺序,节省内存
- #sorted 是生成一个新列表,不改变原来的列表
- #key = func
- # print(sorted([-5,3,-4,2,-1],reverse=True))
- # print(sorted([-5,3,-4,2,-1],key=abs))
- # l2 = ['ajkhs',(1,2),'a',[1,2,3,4]]
- # print(sorted(l2,key=len,reverse=True))
- # print(ascii('a'))
- # print(ascii(1))
匿名函数:
- # def calc(n):return n**n
- # print(calc(10))
- # cal = lambda n:n**n #lambda表达式、匿名函数
- # cal = lambda: 1==2 #lambda表达式、匿名函数
- # cal = lambda n: True if 1==2 else False #lambda表达式、匿名函数
- # print(cal())
- # def add(x,y):return x+y
- # add = lambda x,y:x+y
- # print(add(1,2))
- # print(max([1,2,3,4,-5],key=abs))
- # dic={'k1':10,'k2':100,'k3':30}
- # # print(max(dic.values()))
- # # print(max(dic))
- # print(max(dic,key=lambda k:dic[k]))
- # def func(x):
- # return x*x
- # ret = map(lambda x:x*x,[1,2,3,4,5,6,7,8])
- # print(list(ret))
- # def func(num):
- # return num>99 and num<1000
- ret = filter(lambda num: num>99 and num<1000,[1,4,6,823,67,23])
- print(list(ret))
- # def func(num):
- # if num > 10:
- # return True
- #return num>10
- ret = filter(lambda num:num>10,[1,4,6,823,67,23])
- ret = filter(lambda num:True if num>10 else False,[1,4,6,823,67,23])
- print(list(ret))
- #max min
- #map filter
这是一道经典题:关于lambda表达式加上列表生成式
- def num():
- return [lambda x:i*x for i in range(4)]
"""
这里的range(4)就是循环0,1,2,3到3截止,然后得到的是4个lambda函数,这个列表是列表生成式,这个生成式直接就把执行后的结果返回给了这个列表里面,
所以我们得到的这个列表本身就是里面的for循环执行后的结果,那么这个for循环执行完这个i就是3,所以就得到下面的lambda表达式里面的i=3
[lambda x:3*x,lambda x:3*x,lambda x:3*x,lambda x:3*x]这里就是返回值,
一个列表,每一个列表中的元素都是一个lambda函数
]
"""- print([m(2) for m in num()])这里也是一个列表生成式,里面的num()会先执行,就触发了我们上面的函数,得到返回值是一个列表,列表里面是一个个lambda表达式的函数,
然后循环这个列表,把每一个函数进行传参调用,得到的就是我们上面的函数被调用加上参数的结果,就是lambda 2:2*3 结果就是6,每一个lambda都是6这个结果,最终打印的结果是[6,6,6,6]
匿名函数进阶的面试题:
- # d = lambda p:p*2
- # t = lambda p:p*3
- # x = 2
- # x = d(x) #4 = d(2)
- # x = t(x) #12 = t(4)
- # x = d(x) #24 = d(12)
- # print(x)
- #2.现有两元组(('a'),('b')),(('c'),('d')),
- # 请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
- # t1 = (('a'),('b'))
- # t2 = (('c'),('d'))
- # t3 = zip(t1,t2) #[('a','c'),('b','d')]
- # print(list(map(lambda t:{t[0]:t[1]},[('a','c'),('b','d')])))
- #3.
- def multipliers():
- return (lambda x:i*x for i in range(4))
- print([m(2) for m in multipliers()])
- # i = 0
- # m = lambda x:i*x
- # m(2)
- # i = 1
- # m = lambda x:i*x
- # m(2)
这些面试题里面最后一道题太难了,需要加上注释,要周末的时候把它搞明白,然后把加了注释的版本贴上来。



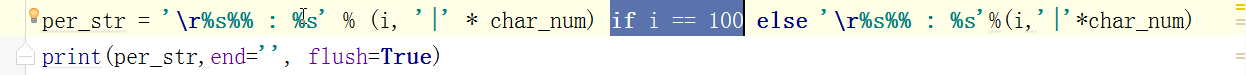























内置函数未完待续。。。
day16 函数的用法:内置函数,匿名函数的更多相关文章
- python学习日记(内置、匿名函数练习题)
用map来处理字符串列表 用map来处理字符串列表,把列表中所有水果都变成juice,比方apple_juice fruits=['apple','orange','mango','watermelo ...
- python(内置高阶函数)
1.高阶函数介绍: 一个函数可以作为参数传给另外一个函数,或者一个函数的返回值为另外一个函数(若返回值为该函数本身,则为递归),如果满足其一,则为高阶函数. 常见的高阶函数:map().sorted( ...
- Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
本博文的主要内容如下: Hive文件存储格式 Hive 操作之表操作:创建外.内部表 Hive操作之表操作:表查询 Hive操作之表操作:数据加载 Hive操作之表操作:插入单表.插入多表 Hive语 ...
- 生成器的send方法、递推函数、匿名函数及常用内置函数
生成器的send方法 在使用yield方法创建生成器时,不仅可以使用next方法进行取值,还可以通过send方法向生成器的内部传值 什么是send方法? send方法相当于高级的next方法,send ...
- Python中匿名函数与内置高阶函数详解
大家好,从今天起早起Python将持续更新由小甜同学从 初学者的角度 学习Python的笔记,其特点就是全文大多由 新手易理解 的 代码与注释及动态演示 .刚入门的读者千万不要错过! 很多人学习pyt ...
- 文成小盆友python-num3 集合,函数,-- 部分内置函数
本接主要内容: set -- 集合数据类型 函数 自定义函数 部分内置函数 一.set 集合数据类型 set集合,是一个无序且不重复的元素集合 集合基本特性 无序 不重复 创建集合 #!/bin/en ...
- python 函数 装饰器 内置函数
函数 装饰器 内置函数 一.命名空间和作用域 二.装饰器 1.无参数 2.函数有参数 3.函数动态参数 4.装饰器参数 三.内置函数 salaries={ 'egon':3000, 'alex':10 ...
- JMeter 内置日期(时间)函数总结
JMeter 内置日期(时间)函数总结 by:授客 QQ:1033553122 1. 测试环境 apache-jmeter-3.3 下载地址: http://jmeter.apache.org/c ...
- python 练习题:请利用Python内置的hex()函数把一个整数转换成十六进制表示的字符串
# -*- coding: utf-8 -*- # 请利用Python内置的hex()函数把一个整数转换成十六进制表示的字符串 n1 = 255 n2 = 1000 print(hex(n1)) pr ...
- JavaScript封装一个函数效果类似内置方法concat()
JavaScript封装一个函数效果类似内置方法concat() 首先回忆concat()的作用: concat() 方法用于连接两个或多个数组.该方法不会改变现有的数组,而仅仅会返回被连接数组的一个 ...
随机推荐
- 10分钟了解Android的Handler机制
Handler机制是Android中相当经典的异步消息机制,在Android发展的历史长河中扮演着很重要的角色,无论是我们直接面对的应用层还是FrameWork层,使用的场景还是相当的多.分析源码一探 ...
- IOS 将状态栏改为白色
1.将 View controller-based status bar appearance 删除(默认为 YES),或设置为YES 2.设置rootViewcontroller,如果为viewC ...
- oracle_基本SQL语言
一:DDL数据定义语言 1:create(创建) 创建表 CREATE TABLE <table_name>( column1 DATATYPE [NOT NULL] [P ...
- Confluence 6 自定义主面板
主面板(dashboard)是你 Confluence 站点的默认载入页面.这个页面能够给用户能够找到其他页面的所有必须的工具,重新进入未完成的工作或者快速导航到喜欢的空间和页面 站点的欢迎信息将会在 ...
- java 命令行JDBC连接Mysql
环境:Windows10 + java8 + mysql 8.0.15 + mysql-connector-java-8.0.15.jar mysql驱动程序目录 项目目录 代码: //package ...
- tensorflow(4):神经网络框架总结
#总结神经网络框架 #1,搭建网络设计结构(前向传播) 文件forward.py def forward(x,regularizer): # 输入x 和正则化权重 w= b= y= return y ...
- 第八周学习总结-C#、C++
2018年9月2日 今天是小学期开始第三天,本周前几天看了看C#和C++,用C#窗体做了个计算器,然后还用Scratch做了一个贪吃蛇的脚本. 31号小学期开始,到今天我把A类基本做完了.一开始做通讯 ...
- Python if __name__ == '__main__':(以主程序形式执行)
在外部调用某个模块时,可能会将只能在本模块执行的代码给执行了,有没有什么办法让某些特定的代码指定只能在自身运行时才执行被调用时不执行呢?使用if __name__ == '__main__':. 示例 ...
- bat 获取拖放文件路径或名称
获取路径: @echo offset path=%~dp1echo %path%pause 获取路径及名称: @echo offset path=%~dp1%~nx1echo %path%pause
- Play框架--初学笔记
目录结构 web_app 根目录 | sbt SBT Unix 批处理脚本用于启动sbt-launch.jar | sbt.bat SBT Windows 批处理脚本用于启动sbt-launch.ja ...