Day4 Python基础之数据类型(三)
计算机中,一切皆为对象
世界万物,皆为对象,一切对象皆可分类
------------------------------------我是分割线------------------------------------
1.IDE集成开发环境(Integrated Development Enviroment)
VIM:经典的Linux下的文本编辑器
Emacs:Linux文本编辑器,相对于VIM更友好一点
Eclipse:Java IDE,支持python,c,c++
Visual Studio:微软的IDE,支持python,c++,java,c#等
Notepad++
sublime:python开发的
pycharm:主要用于python开发的IDE
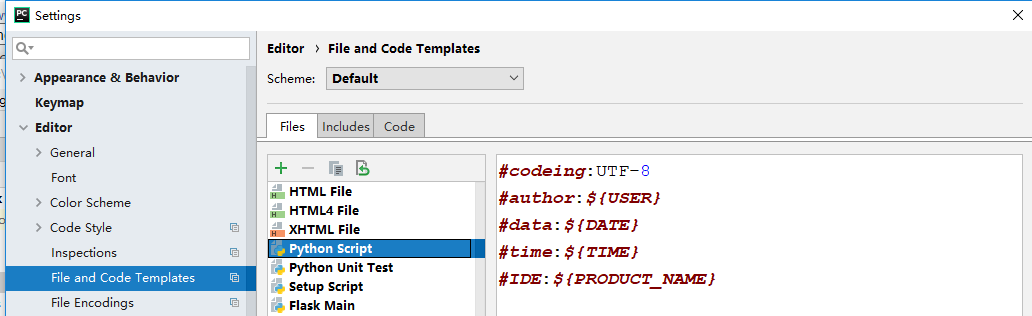
2.pycharm设置模板默认添加作者、时间、IDE等信息
(1). 打开Pycharm,选择 File > Settings(Ctrl + Alt + S)
(2). 找到"File and Code Templates", 右侧菜单选择"Python Script",对模板进行编辑
格式为: ${<variable_name>},如常用的:
${USER} 当前系统用户
${DATE} 当前系统日期
${TIME} 当前系统时间
${PRODUCT_NAME} 创建文件的IDE名称
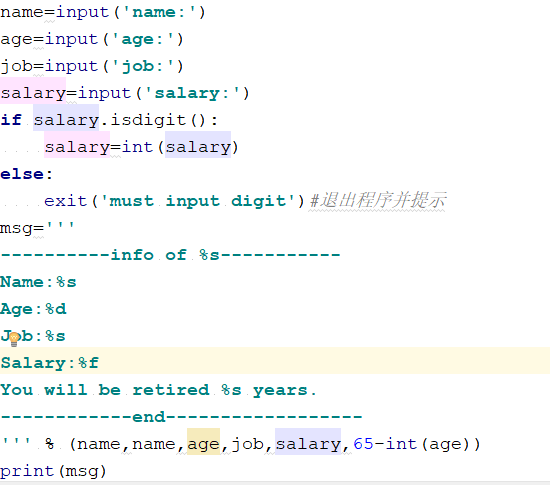
3.格式化输出
常用的占位符:%s s是string的意思 %d d是digit的意思 %f f是float的意思
变量.isdigit() 判断是不是数字
exit('string') 退出程序
4.数据类型
可变类型:列表、字典
不可变类型:整型、字符串、元组
4.1 数字
int(整型):表示比较小的整数
long(长整型):表示比较大的整数
注:在python3中不区分int和long,在python2,java,c中是被严格区分的
float(浮点型):大部分情况下是指小数
complex(复数):a+bj
4.2 布尔值
True or False
4.3 字符串
字符串拼接如果用逗号或加号,不仅拼写麻烦,而且每使用一个加号都需要开辟一片新的内存,这使得运行效率降低,因此常用格式化输出(%)
4.4 列表List[ ]
列表:list1=['a','b','c','d','e'],这样就可以把一些元素变成有关联的了,对其操作有增删改查等list内置方法
增:insert(看可以插入任意位置)、append(只能默认插入最后一个位置) extend(list2)(将list2扩展到list1,对list2没有影响)
list1.append('f')
list1.insert(2,'f')
list1.extend(list2)
删:remove(根据内容删除元素,括号里面的东西是一个整体,也就是说不能切片)、
pop(根据索引删除元素,并且可以返回所删除的内容)、
del(不是list内置方法,适用于删除其它如常量、字典等)
list1.remove(list1[3]) #删除索引为3的元素
pop1=list1.pop(3) #根据索引删除索引为3 的元素,并返回删除的元素给pop1;如果没有参数,则会删除列表最后一个元素
改:
list1[2]='g' #替换索引为2的元素 的值
list1[1;3]=[‘h’,'i'] #替换索引为1,2的元素的值
查:顾头不顾尾(学会切片,即取出列表的子列表)
list1[0:] #取到最后一个元素
list1[0:-1] #取到倒数第二个值
list1[0: :2] #以步长为2依次从左到右取值
list1[4::-2] #以步长为2依次从右到左取值
list1.count('a') #统计元素a的个数
list1.index('b') #取出元素‘b’的索引,如果有多个,只会返回第一个‘b’的索引
(如果一定要得到其它几个‘b’的索引,在得到第一个‘b’的索引后,切片得到子列表,然后获得另一个‘b’在子列表中的索引,通过适当运算就得到在原列表里的索引)
排序
list1.reverse() #将列表list1里面的元素反转
list1.sort() #将列表中的元素排序(按照ASCII编码规则排序) ,默认的是list1.sort(reverse=False),还可以设置为list1.sort(reverse=True)
4.5元组Tuple()
注:(1)元组只读,不能修改(用途:如果你自己在编写程序的时候,有些数据不想让别人修改,就可以用元组)
(2)元组在映射时可以当键使用,而列表不行
(3)如果你的元组里面只有一个元素,最后在后面加一个逗号,此时在web中才认为它是一个元组
4.6 字典Dictionary{ }
键值对(key-value),键必须是不可变数据类型
定义字典的两种方法 info2=dict(([key,value],[key,value])) (不常用) info3=dict([[key,value],[key,value]]) (不常用) |
|
增:
info1[key]=value
info1.setdefault(key,value) #如果键存在,不改动,返回键相对应的值;如果键不存在,增加新的键值对,并返回对应的值
删:
del info1[key] #删除键值对
del info1 #删除整个字典
info1.clear() #清空字典
info1.pop(key) #删除键值对,返回key对应的value
info1.popitem() #随机删除一个键值对,并以元组返回键值对
改:
info1['stu1101']=new value #通过键查找值
info1.update(info2) #将字典info2中的的键值对全部加入info1,如果有重复的key,info2会会覆盖info1的内容
查:
info1.keys() #查看字典中所有的键,返回的不是列表,是一种新的数据类型dict_item,可以转换成列表供使用,list(info1.keys())
info1.values() #查看字典中的值
info1.items() #查看字典中所有的键值对
info1['stu1101'] #通过键查找值
其它操作及涉及到的方法
|
fromkeys #可以初始化一个字典,但是基本上不用,因为在使用过程中会存在问题 Info4.fromkeys([key1,key2,key3],value) #value会赋值给key1,key2,key3 |
| 多级嵌套 |
| sorted(字典) #默认按照键值排序 |
|
字典遍历 效率高:for key in info1: print(key,info[key]) 效率低:for i,j in info.items(): print(i,j) (因为要把items的使用有一个列表转换的过程,所以比较慢) |
4.7 字符串
print(字符串*20) #重复输出20次
print(字符串[0:]) #通过切片的方式获得字符串中的字符,操作和列表一样
string1 in string2 #判断字符串1 是否在字符串2中
string1 + string2 #字符串拼接,占内存多,导致效率低,可以通过格式化输出或join方法
| 字符串st内置方法 | 功能 |
| c='-----'.join([a,b,c,d]) | #join是字符串内置方法(所以引号里面只能是字符串),通过引号里面的字符串,将后面的a,b,c,d拼接在一起 |
| st.count('字符a') | #统计字符a的个数 |
| st.capitalize() | #首字母大写 |
| st.center(50,'-') | #居中打印:总共打印50个字符,st居中,其余的用‘-’填充 |
| st.ljust(50,‘*’) | #居左 |
| st.rjust(50,‘#’) | #居右 |
| st.encode() | |
| st.endswith('字符串') | #判断字符串是否以某字符串为结尾 |
| st.startswith('字符串') | #判断字符串是否以某字符串为开头,在文件处理中经常处理到 |
| st.expandtabs(tabsize=10) | #扩展字符串中字符之间的空格,一般用不到 |
|
st.find('字符') |
#查找到st中第一个字符的位置,并返回该字符的索引值,默认从左往右 |
|
st.rfind('字符') |
#从右往左找第一个值(索引值是唯一的) |
| st.format(name='venus') |
st='hello kitty {name},{age}' st.format(name='venus',age=27) #以赋值的方式 print(st) #格式化输出,此时的输出值是hello kitty venus,27 |
| st.format_map(name='venus') |
st='hello kitty {name},{age}' st.format_map({name:'venus',age:27}) #以键值对的方式 print(st) #格式化输出,此时的输出值是hello kitty venus,27 |
| st.index('字符') | #和find的功能一样,所不同的是,找不到内容时会报错,而find会返回-1,也是没有找到的意思 |
| st.isalnum() | #判断字符串是不是由数字和字母组成的 ,一般用不到 |
| st.isdecimal() | #判断字符串是不是只包含十进制数,一般不用 |
| st.isdigit() | #判断字符串是不是只包含数字(整数) |
| st.isnumeric() | #判断字符串是不是只包含数字(整数) |
| st.isidentifier() | #判断非法变量的 |
|
st.islower() st.isupper() |
#判断字符串是不是全都小写/大写 |
|
st.lower() st.upper() |
#大写变小写、或小写变大写 |
|
st.swapcase() |
#大写变小写并且小写变大写 |
|
st.isspace() |
#判断字符串是否有空格 |
|
st.istitle() |
#判断单词的首字母是不是大写 |
|
st.strip() |
#帮我们去掉所有的空格和换行符,在文本处理中也是经常用到 |
|
st.lstrip() st.rstrip() |
#去左去右空格和换行 |
|
st.replace('old内容',‘new内容’) |
#内容替换 |
|
st.split() st.split(‘分割标志’) |
#把字符串变成列表,如果想要把列表变成字符串,可以用join #将字符串按照分割标志位进行分割(这个分割标志位来自字符串中) split 是非常重要的字符串方法,它是join的逆方法,用来将字符串分割成序列 >>> '1+2+3+4+5'.split('+') 如果不提供任何分隔符,程序会把所有空格作为分隔符 |
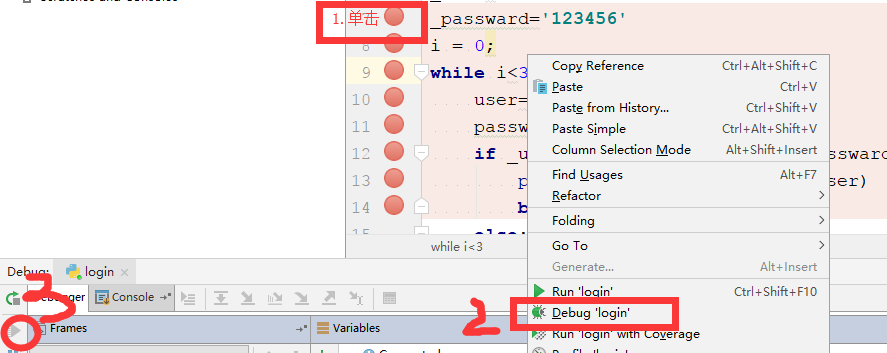
5.技巧之pycharm的Debug调试模式
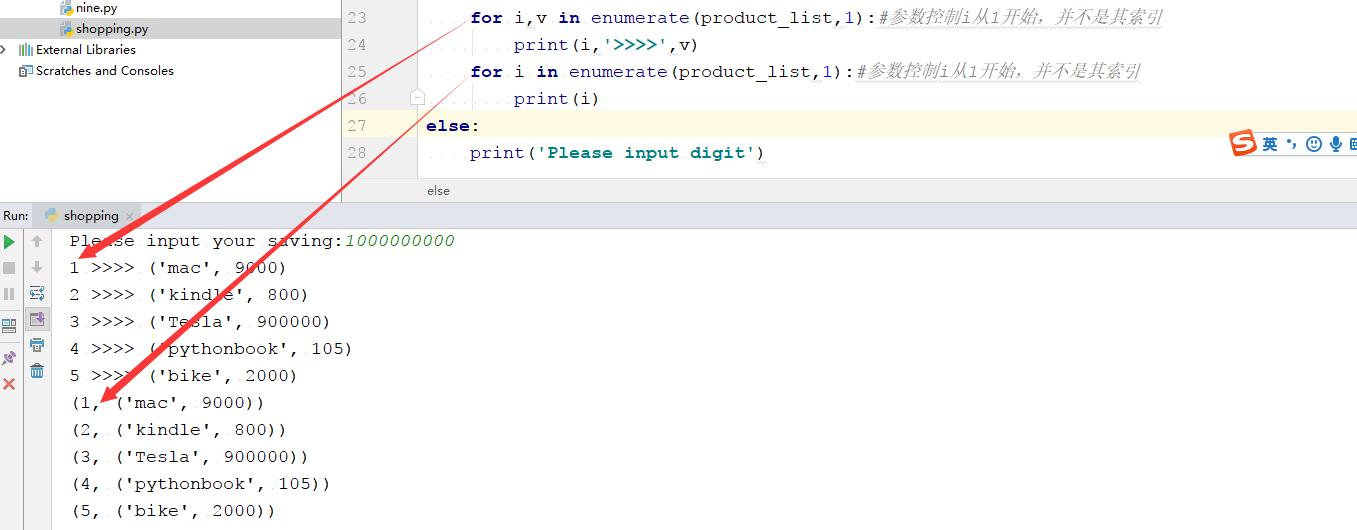
6.作业----购物功能
(1)向我展示购物车中的商品及属性
(2)用户选择所要购买的商品,并显示你可以所拥有的资金,买完后所剩资金是多少
(3)提示用户还需不需要购买其他商品,可用资金
6.1 enumerate函数的使用方法:遍历列表(可以返回两个变量或返回一个变量)
(enumerate是枚举的意思)
7.一些常用命令
len(list1) #查看列表的长度
id(变量) #查看变量的内存ID
Day4 Python基础之数据类型(三)的更多相关文章
- Python之路,Day4 - Python基础4 (new版)
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- Day4 - Python基础4 迭代器、装饰器、软件开发规范
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- Python基础之数据类型
Python基础之数据类型 变量赋值 Python中的变量不需要声明,变量的赋值操作既是变量声明和定义的过程. 每个变量在内存中创建,都包括变量的标识,名称和数据这些信息. 每个变量在使用前都必须赋值 ...
- Python基础语法(三)
Python基础语法(三) 1. 数值型数据结构 1.1 要点 在之前的博客也有提到,数值型数据结构在这里就不过多介绍了.在这里提及一些需要知道的知识点. int.float.complex.bool ...
- 第二章:python基础,数据类型
"""第二章:python基础,数据类型2.1 变量及身份运算补充2.2 二进制数2.3 字符编码每8位所占的空间位一个比特,这是计算机中最小的表示单位.每8个比特组成一 ...
- python基础一数据类型之字典
摘要: python基础一数据类型之一字典,这篇主要讲字典. 1,定义字典 2,字典的基础知识 3,字典的方法 1,定义字典 1,定义1个空字典 dict1 = {} 2,定义字典 dict1 = d ...
- python基础篇(三)
PYTHON基础篇(三) 装饰器 A:初识装饰器 B:装饰器的原则 C:装饰器语法糖 D:装饰带参数函数的装饰器 E:装饰器的固定模式 装饰器的进阶 A:装饰器的wraps方法 B:带参数的装饰器 C ...
- 第三篇:python基础之数据类型与变量
阅读目录 一.变量 二.数据类型 2.1 什么是数据类型及数据类型分类 2.2 标准数据类型: 2.2.1 数字 2.2.1.1 整型: 2.2.1.2 长整型long: 2.2.1.3 布尔bool ...
- 第一节 Python基础之数据类型(整型,布尔值,字符串)
数据类型是每一种语言的基础,就比如说一支笔,它的墨有可能是红色,有可能是黑色,也有可能是黄色等等,这不同的颜色就会被人用在不同的场景.Python中的数据类型也是一样,比如说我们要描述一个人的年龄:小 ...
随机推荐
- Linux下键盘值 对应input_evnet的code值。
最近做了一个linux下面的模拟鼠标和键盘的app,但不是很清楚字符对应的键值:查找内核源码,在kernel/include/uapi/linux/input.h文件中找到: 下面给出普通键盘上面对应 ...
- SQL server 数据库的索引和视图、存储过程和触发器
1.索引:数据排序的方法,快速查询数据 分类: 唯一索引:不允许有相同值 主键索引:自动创建的主键对应的索引,命令方式不可删 聚集索引:物理顺序与索引顺序一致,只能创建一个 非聚集索引:物理顺序与索引 ...
- 基于centOS7:新手篇→nginx安装
一.首先安装编译工具和库 #安装make zlib gcc OpenSSL yum -y install make zlib zlib-devel gcc-c++ libtool openssl op ...
- PHP实现类似题库抽题效果
PHP实现类似题库抽题效果 大家好,我顾某人又回来了,最近学了一点PHP,然后就想写个简单小例子试试,于是就写了一个类似于从题库抽题的东西,大概就是先输入需要抽题的数量,然后从数据库中随机抽取题目. ...
- js获取请求地址后面带的参数
浏览器输入页面地址的时候在后面带有请求参数, 页面加载后需要获取携带的参数, 可以使用js, 在页面加载js的时候获取参数 http://localhost:8080/demo/index.html? ...
- Python Numpy-基础教程
目录 1. 为什么要学习numpy? 2. Numpy基本用法 2.1. 创建np.ndarry 2.2. Indexing and Slicing Boolean Index 2.3. Univer ...
- 用栈来实现队列的golang实现
使用栈实现队列的下列操作: push(x) -- 将一个元素放入队列的尾部. pop() -- 从队列首部移除元素. peek() -- 返回队列首部的元素. empty() -- 返回队列是否为空. ...
- SpringMVC-DispatcherServlet工作流程及web.xml配置
工作流程: Web中,无非是请求和响应: 在SpringMVC中,请求的第一站是DispatcherServlet,充当前端控制器角色: DispatcherServlet会查询一个或多个处理器映射( ...
- Git 安装及用法 github 代码发布 gitlab私有仓库的搭建
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统. 这个版本控制软件,有 svn还有git,是一个工具. git是由linux的作者开发的 git是一个分布式版本控制系统 ...
- P2080 增进感情(背包DP)
思路:将好感度x+y作为体积, 幸福度x-y作为作为价值, 然后就是一个经典的背包问题了.emmmmm,还可以特判一下,因为幸福度为0时就是最小了,没有必要看后面的了吧. 其实,我自己做的时候,沙雕的 ...