YARN集群的mapreduce测试(一)
hadoop集群搭建中配置了mapreduce的别名是yarn
[hadoop@master01 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[hadoop@master01 hadoop]$ vi mapred-site.xml
<property>
<name>mapreduce.framework.name </name>
<value>yarn</value>
</property>
单词分类计数可以联系到sql语句的分组进行理解;
根据key设置的不同来进行计数,再传递给reduceTask按照设定的key值进行汇总;
测试准备:
首先同步时间,然后master先开启hdfs集群,再开启yarn集群;用jps查看:
master上: 先有NameNode、SecondaryNameNode;再有ResourceManager;
slave上: 先有DataNode;再有NodeManager;
如果master启动hdfs和yarn成功,但是slave节点有的不成功,则可以使用如下命令手动启动:
| hadoop-daemon.sh start datanode |
| yarn-daemon.sh start nodemanager |
在本地创建几个txt文件,并上传到集群的"/data/wordcount/src"目录下;

单词计数:
工程结构图:
代码:大数据学习交流QQ群:217770236 让我们一起学习大数据
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; /**
* 这个是Mapper类,每一个Mapreduce作业必须存在Mapper类,Reduce类则是可选;
* Mapper类的主要作用是完成数据的筛选和过滤
*
* 自定义的Mapper类必须继承于Hadoop提供的Mapper类,并重写其中的方法完成MapTask
* 超类Mapper的泛型参数从左到右依次表示:
* 读取记录的键类型、读取记录的值类型、写出数据的键类型、写出数据的值类型
*
* Hadoop官方提供了一套基于高效网络IO传送的数据类型(如:LongWritable、Text等),
* 数据类型于java中原生的数据类型相对应,比如:LongWritable即为Long类型、Text即为String类型
*
* Hadoop的数据类型转换为Java类型只需要调用get方法即可(特例:Text转换为String类型调用toString)
* Java数据类型转换为Hadoop类型只需要使用构造方法包装即可,如:
* Long k = 10L;
* LongWritable lw = new LongWritable(k);
*
* @author hadoop
*
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text outKey;
private LongWritable outValue;
/**
* 这是Mapper类的实例初始化方法,每一个MapTask对应一个Mapper实例,
* 每一个Mapper类被实例化之后将首先调用setup方法完成初始化操作,
* 对于每一个MapTask,setup方法有且仅被调用一次;
*/
@Override
protected void setup(Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
outKey = new Text();
outValue = new LongWritable();
} /**
* 此方法在setup方法之后,cleanup方法之前调用,此方法会被调用多次,被处理的文件中的每一条记录都会调用一次该方法;
* 第一个参数:key 代表所读取记录相对于文件开头的起始偏移量(单位:byte)
* 第二个参数:value 代表所读取到的记录内容本身
* 第三个参数:contex 记录迭代过程的上下文
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException { FileSplit fp = (FileSplit) context.getInputSplit();
String fileName = fp.getPath().getName();
// int i = fileName.lastIndexOf(".");
// String fileNameSimple = fileName.substring(0, 1); String line = value.toString();
String[] words = line.split("\\s+");
for (String word : words) {
outKey.set(fileName+":: "+word);
outValue.set(1);
context.write(outKey, outValue);
}
} /**
* 这是Mapper类的实例销毁方法,
* 每一个Mapper类的实例将数据处理完成之后,于对象销毁之前有且仅调用一次cleanup方法
*/
@Override
protected void cleanup(Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
outKey = null;
outValue = null;
} }
WordCountMapper
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
* 这是Reducer类,该类是可选的,不是必须的;一般在需要统计和分组的业务中都存在Reducer类;
* Reducer类产生的实例被ReducerText所调用,ReducerText,任务结束之后Reducer实例被销毁
*
* 四个泛型参数从左到右依次表示:
* 读取记录的键类型(读取到的记录来自于MapTask的输出)
* 读取记录的值类型
* 读出记录的键类型
* 读出记录的值类型
*
* 有ReducerText的MapReducer作业,其ReducerText的输出结果作为整个Job的最终输出结果
* 没有ReducerText的MapReducer作业,其MapText的输出结果作为整个Job的最终输出结果
*
* @author hadoop
*
*/
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable outValue; //将需要多次使用的对象定义为全局变量
/**
* 用于Reducer实例的初始化:
* 在Reducer类被实例化之后,首先调用此方法,该方法有且仅被调用一次,
*/
@Override
protected void setup(Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
outValue = new LongWritable();//在此处进行一次初始化
} /**
* 此方法是迭代方法,该方法会针对每条记录被调用一次
* key: MapTask的输出键
* values: MapTask输出值集合
* context: reduceTask运行的上下文
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
Long sum = 0L;
for (LongWritable count : values) {
sum += count.get();//将关键词相同的循环遍历相加
}
outValue.set(sum);
context.write(key, outValue);
} /**
* 用于Reducer实例销毁之前处理的工作:
* 该方法有且仅被调用一次
*/
@Override
protected void cleanup(Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
outValue = null; //用完之后进行销毁
} }
WordCountReducer
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountDriver { private static FileSystem fs;
private static Configuration conf;
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (null==args || args.length<2) return;
//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[0]);
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[1]); //如果输入目录已经存在,则将其删除并重建
if (!fs.exists(inputPath)) {
return;
}
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);//true表示递归删除
}
//fs.mkdirs(outputPath); //获取Job实例
Job wcJob = Job.getInstance(conf, "WordCountJob");
//设置运行此jar包入口类
//wcJob的入口是WordCountDriver类
wcJob.setJarByClass(WordCountDriver.class);
//设置Job调用的Mapper类
wcJob.setMapperClass(WordCountMapper.class);
//设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setReducerClass(WordCountReducer.class); //设置MapTask的输出键类型
wcJob.setMapOutputKeyClass(Text.class);
//设置MapTask的输出值类型
wcJob.setMapOutputValueClass(LongWritable.class); //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setOutputKeyClass(Text.class);
//设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setOutputValueClass(LongWritable.class); //设置整个Job需要处理数据的输入路径
FileInputFormat.setInputPaths(wcJob, inputPath);
//设置整个Job计算结果的输出路径
FileOutputFormat.setOutputPath(wcJob, outputPath); //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag = wcJob.waitForCompletion(true);
System.exit(flag?0:1);
}
}
WordCountDriver(主类)
运行时传入参数是:
如果在eclipse上运行:传参需要加上集群的master的uri即 hdfs://master01:9000
输入路径参数: /data/wordcount/src
输出路径参数: /data/wordcount/dst
运行结果:
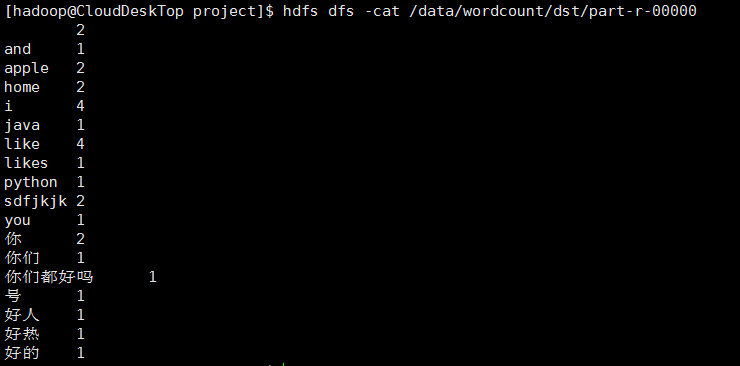
1、出现第一张图的结果表示有可能成功了,因为成功创建了输出目录;
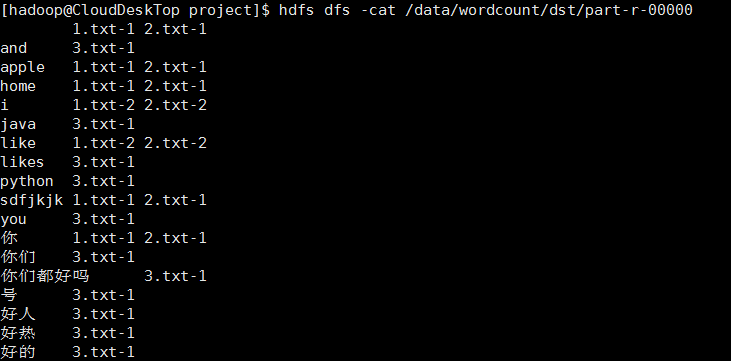
2、进入part-r-00000查看内容,确认的确成功;

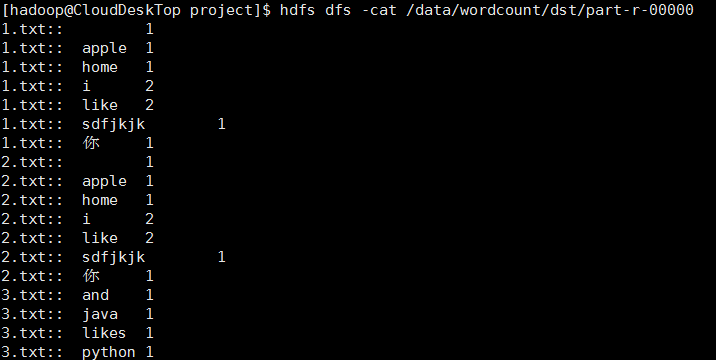
单词计数(按文件统计):
只需要将单词计数的代码中的WordCountMapper类中的map方法添加如下代码片段:
FileSplit fp=(FileSplit)context.getInputSplit();
String fileName=fp.getPath().getName();
在给outKey设置值时就需要传“word+"\t"+filename”;
运行时传入参数是:
如果在eclipse上运行:传参需要加上集群的master的uri即 hdfs://master01:9000
输入路径参数: /data/wordcount/src
输出路径参数: /data/wordcount/dst
运行结果:
单词计数(每个文件中的出现次数):
工程结构图:
代码:
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class WordTimeMapper01 extends Mapper<LongWritable, Text, Text, LongWritable>{ private Text outKey;
private LongWritable outValue; @Override
protected void setup(Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
outKey = new Text();
outValue = new LongWritable(1L);
} @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
FileSplit fp= (FileSplit) context.getInputSplit();
String fileName = fp.getPath().getName(); String line = value.toString();
String[] words = line.split("\\s+"); for (String word : words) {
outKey.set(word+"\t"+fileName);
context.write(outKey, outValue);
} } @Override
protected void cleanup(Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
outKey = null;
outValue = null;
} }
WordTimeMapper01
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.util.Iterator; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class WordTimeReducer01 extends Reducer<Text, LongWritable, Text, LongWritable> { private LongWritable outValue;
@Override
protected void setup(Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
outValue = new LongWritable();
} @Override
protected void reduce(Text key, Iterable<LongWritable> values,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long count = 0L;
for (Iterator<LongWritable> its = values.iterator(); its.hasNext();) {
count += its.next().get();
}
outValue.set(count);
context.write(key, outValue);//key和outValue默认用\t分割 } @Override
protected void cleanup(Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
outValue = null;
} }
WordTimeReducer01
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* @author hadoop
*
*/
/**
* @author hadoop
*
*/
/**
* @author hadoop
*
*/
public class WordTimeDriver01 { private static FileSystem fs;
private static Configuration conf;
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job wcJob = getJob(args);
if (null == wcJob) {
return;
}
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag = false;
flag = wcJob.waitForCompletion(true);
System.exit(flag?0:1);
} /**
* 获取Job实例
* @param args
* @return
* @throws IOException
*/
public static Job getJob(String[] args) throws IOException {
if (null==args || args.length<2) return null;
//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[0]);
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[1]); //如果输入目录已经存在,则将其删除并重建
if (!fs.exists(inputPath)) {
return null;
}
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);//true表示递归删除
}
//fs.mkdirs(outputPath); //获取Job实例
Job wcJob = Job.getInstance(conf, "WordCountJob");
//设置运行此jar包入口类
//wcJob的入口是WordCountDriver类
wcJob.setJarByClass(WordTimeDriver01.class);
//设置Job调用的Mapper类
wcJob.setMapperClass(WordTimeMapper01.class);
//设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setReducerClass(WordTimeReducer01.class); //设置MapTask的输出键类型
wcJob.setMapOutputKeyClass(Text.class);
//设置MapTask的输出值类型
wcJob.setMapOutputValueClass(LongWritable.class); //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setOutputKeyClass(Text.class);
//设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setOutputValueClass(LongWritable.class); //设置整个Job需要处理数据的输入路径
FileInputFormat.setInputPaths(wcJob, inputPath);
//设置整个Job计算结果的输出路径
FileOutputFormat.setOutputPath(wcJob, outputPath); return wcJob;
} }
WordTimeDriver01
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class WordTimeMapper02 extends Mapper<LongWritable, Text, Text, Text>{ private Text outKey;
private Text outValue; @Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
outKey = new Text();
outValue = new Text();
} @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException { //将第一次的分组结果,用关键字再次切分:单词、文件名、出现次数
String line = value.toString();
String[] filesAndTimes = line.split("\t");
String word = filesAndTimes[0];
String fileName = filesAndTimes[1];
String times = filesAndTimes[2]; outKey.set(word);//将单词设置为关键字分组
outValue.set(fileName+"-"+times);//将文件名和出现次数作为输出
context.write(outKey, outValue);//写一次 } @Override
protected void cleanup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
outKey = null;
outValue = null;
} }
WordTimeMapper02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.util.Iterator; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class WordTimeReducer02 extends Reducer<Text, Text, Text, Text> { private Text outValue;
@Override
protected void setup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
outValue = new Text();
} @Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringBuilder builder = new StringBuilder();
Iterator<Text> its = values.iterator();
while (its.hasNext()) {
String fileNameAndTimes = its.next().toString();
builder.append(fileNameAndTimes+"\t");
} if (builder.length()>0) {
builder.deleteCharAt(builder.length()-1);
} outValue.set(builder.toString());
context.write(key, outValue);
} @Override
protected void cleanup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
outValue = null;
} }
WordTimeReducer02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordTimeDriver02 { private static FileSystem fs;
private static Configuration conf;
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job wcJob = getJob(args);
if (null == wcJob) {
return;
}
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag = wcJob.waitForCompletion(true);
System.exit(flag?0:1);
} /**
* 获取Job实例
* @param args
* @return
* @throws IOException
*/
public static Job getJob(String[] args) throws IOException {
if (null==args || args.length<2) return null;
//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[0]);
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[1]); //如果输入目录已经存在,则将其删除并重建
if (!fs.exists(inputPath)) {
return null;
}
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);//true表示递归删除
}
//fs.mkdirs(outputPath); //获取Job实例
Job wcJob = Job.getInstance(conf, "WordCountJob");
//设置运行此jar包入口类
//wcJob的入口是WordCountDriver类
wcJob.setJarByClass(WordTimeDriver02.class);
//设置Job调用的Mapper类
wcJob.setMapperClass(WordTimeMapper02.class);
//设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setReducerClass(WordTimeReducer02.class); //设置MapTask的输出键类型
wcJob.setMapOutputKeyClass(Text.class);
//设置MapTask的输出值类型
wcJob.setMapOutputValueClass(Text.class); //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setOutputKeyClass(Text.class);
//设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句)
wcJob.setOutputValueClass(Text.class); //设置整个Job需要处理数据的输入路径
FileInputFormat.setInputPaths(wcJob, inputPath);
//设置整个Job计算结果的输出路径
FileOutputFormat.setOutputPath(wcJob, outputPath);
return wcJob;
}
}
WordTimeDriver02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordTimeDriver { private static FileSystem fs;
private static Configuration conf;
private static final String TEMP= "hdfs://master01:9000/data/wordcount/tmp";
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { String[] params01 = {args[0], TEMP}; //运行第1个Job
Job wcJob01 = WordTimeDriver01.getJob(params01);
if (null == wcJob01) {
return;
}
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag01 = wcJob01.waitForCompletion(true);
if (!flag01) {
return;
} //运行第2个Job
String[] params02 = {TEMP, args[1]};
Job wcJob02 = WordTimeDriver02.getJob(params02);
if (null == wcJob02) {
return;
}
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag02 = wcJob02.waitForCompletion(true);
if (flag02) {//等待Job02完成后就删掉中间目录并退出;
fs.delete(new Path(TEMP), true);
System.exit(0);
}
System.out.println("job is failing......");
System.exit(1);
} }
WordTimeDriver(主类)
运行时传入参数是:
如果在eclipse上运行:传参需要加上集群的master的uri即 hdfs://master01:9000
输入路径参数: /data/wordcount/src
输出路径参数: /data/wordcount/dst
运行结果:
测试完毕,先关闭yarn集群,再关闭hdfs集群。
运行时查看详情:
| http://master的IP:50070 |
| http://master的IP:8088 |
YARN集群的mapreduce测试(一)的更多相关文章
- YARN集群的mapreduce测试(六)
两张表链接操作(分布式缓存): ----------------------------------假设:其中一张A表,只有20条数据记录(比如group表)另外一张非常大,上亿的记录数量(比如use ...
- YARN集群的mapreduce测试(五)
将user表计算后的结果分区存储 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryNameN ...
- YARN集群的mapreduce测试(四)
将手机用户使用流量的数据进行分组,排序: 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryN ...
- YARN集群的mapreduce测试(三)
将user表.group表.order表关:(类似于多表关联查询) 测试准备: 首先同步时间,然后 开启hdfs集群,开启yarn集群:在本地"/home/hadoop/test/" ...
- YARN集群的mapreduce测试(二)
只有mapTask任务没有reduceTask的情况: 测试准备: 首先同步时间,然后 开启hdfs集群,开启yarn集群:在本地"/home/hadoop/test/"目录创建u ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- HDFS集群和YARN集群
Hadoop集群环境搭建(一) 1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要 ...
- Spark on Yarn 集群运行要点
实验版本:spark-1.6.0-bin-hadoop2.6 本次实验主要是想在已有的Hadoop集群上使用Spark,无需过多配置 1.下载&解压到一台使用spark的机器上即可 2.修改配 ...
- 使用Cloudera Manager搭建MapReduce集群及MapReduce HA
使用Cloudera Manager搭建MapReduce集群及MapReduce HA 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.通过CM部署MapReduce On ...
随机推荐
- python循环解压rar文件
python循环解压rar文件 C:. │ main.py │ ├─1_STL_算法简介 │ STL_算法简介.rar │ └─2_STL_算法_填充新值 STL_算法_填充新值.rar 事情是这样的 ...
- Sudoku(POJ2676/3074)
Sudoku is one of the metaphysical techniques. If you understand the essence of it, you will have the ...
- Linux(Ubuntu-CentOS)
2017.3.29 查看已安装软件版本 dpkg-query --list 2017.3.3 Ubuntu 14.04 安装 phpmyadmin make sure apache works wel ...
- 6 week work 3
sticky vs fixed sticky:表示粘贴到某个位置.当组件设置了该属性值后,当页面滑动时,组件会跟着页面移动,当组件触及到窗体后,页面若继续滑动,组件则处在与窗体接触的位置不动.元素的定 ...
- bash基础特性1
shell俗称壳(用来区别于内核),是指“提供使用者使用界面”的软件,就是一个命令行解释器. BASH是SHELL的一种,是大多数LINUX发行版默认的SHELL,除BASH SHELL外还有C SH ...
- The test form is only available for requests from the local machine
使用浏览器测试Web服务时出现提示“The test form is only available for requests from the local machine.”的解决办法 在Web服务项 ...
- EmpireCMS_V7.5的一次审计
i春秋作家:Qclover 原文来自:EmpireCMS_V7.5的一次审计 EmpireCMS_V7.5的一次审计 1概述 最近在做审计和WAF规则的编写,在CNVD和CNNVD等漏洞平台寻找 ...
- 从零开始单排学设计模式「策略模式」黑铁 II
阅读本文大概需要 1.7 分钟. 本篇是设计模式系列的第三篇,虽然之前也写过相应的文章,但是因为种种原因后来断掉了,而且发现之前写的内容也很渣,不够系统.所以现在打算重写,加上距离现在也有一段时间了, ...
- rabbitMQ的安装和创建用户
rabbitMQ的安装和创建用户 在计算机科学中,消息队列(英语:Message queue)是 一种 进程间通信或同一进程的不同 线程 间的通信方式,软件的贮列用来处理一系列的输入,通常是来自用户. ...
- Kali学习笔记29:默认安装漏洞
文章的格式也许不是很好看,也没有什么合理的顺序 完全是想到什么写一些什么,但各个方面都涵盖到了 能耐下心看的朋友欢迎一起学习,大牛和杠精们请绕道 默认安装漏洞: 早期Windows默认自动开启很多服务 ...