Linux 线程与进程,以及通信
http://blog.chinaunix.net/uid-25324849-id-3110075.html
部分转自:http://blog.chinaunix.net/uid-20620288-id-3025213.html
1、首先要明确进程和线程的含义:
进程(Process)是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。与程序相比,程序只是一组指令的有序集合,它本身没有任何运行的含义,只是一个静态实体。进程是程序在某个数据集上的执行,是一个动态实体。它因创建而产生,因调度而运行,因等待资源或事件而被处于等待状态,因完成任务而被撤消,反映了一个程序在一定的数据集上运行的全部动态过程。
每个正在系统上运行的程序都是一个进程。每个进程包含一到多个线程。进程也可能是整个程序或者是部分程序的动态执行。线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行。也可以把它理解为代码运行的上下文。所以线程基本上是轻量级的进程,它负责在单个程序里执行多任务。通常由操作系统负责多个线程的调度和执行。
多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率。线程是在同一时间需要完成多项任务的时候实现的。
使用线程的好处有以下几点:
a)使用线程可以把占据长时间的程序中的任务放到后台去处理
b)用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
c)程序的运行速度可能加快
d)在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
2、其次来看下线程和进程的关系
线程是属于进程的,线程运行在进程空间内,同一进程所产生的线程共享同一内存空间,当进程退出时该进程所产生的线程都会被强制退出并清除。线程可与属于同一进程的其它线程共享进程所拥有的全部资源,但是其本身基本上不拥有系统资源,只拥有一点在运行中必不可少的信息(如程序计数器、一组寄存器和栈)。
3、然后我们来看下线程和进程间的比较
|
子进程继承父进程的属性: |
子线程继承主线程的属性: |
|
实际用户ID,实际组ID,有效用户ID,有效组ID; 附加组ID; 进程组ID; 会话ID; 控制终端; 设置用户ID标志和设置组ID标志; 当前工作目录; 根目录; 文件模式创建屏蔽字(umask); 信号屏蔽和安排; 针对任一打开文件描述符的在执行时关闭(close-on-exec)标志; 环境; 连接的共享存储段; 存储映射; 资源限制; |
进程中的所有信息对该进程的所有线程都是共享的; 可执行的程序文本; 程序的全局内存; 堆内存; 栈; 文件描述符; 信号的处理是进程中所有线程共享的(注意:如果信号的默认处理是终止该进程那么即是把信号传给某个线程也一样会将进程杀掉); |
|
父子进程之间的区别: |
子线程特有的: |
|
fork的返回值(=0子进程); 进程ID不同; 两个进程具有不同的父进程ID; 子进程的tms_utime,tms_stime,tms_cutime以及tms_ustime均被设置为0; 不继承父进程设置的文件锁; 子进程的未处理闹钟被清除; 子进程的未处理信号集设置为空集; |
线程ID; 一组寄存器值; 栈; 调度优先级和策略; 信号屏蔽字; errno变量; 线程私有数据; |
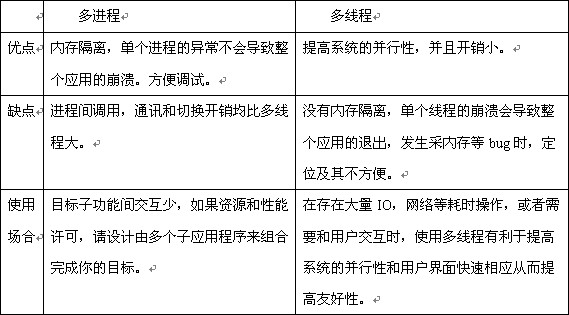
3、设计时考虑的使用技巧
1.尽量避免长驻内存的进程,例如那些很少用到的功能,或周期性很长(10分钟以上),把它们的功能提取出来,做成一个小的应用程序。需要的时候再把它们拉起来(如通过crontab配置,或直接system)。
2.把目标设计成子功能系统的组合可用提高重用的易用性和维护性。
把目标根据功能划分不同的子系统,子系统间遵循特定的协议(文本或XML),由通讯联系起来,协作完成目标。
也就是说,我们在做设计的时候可以如下考虑:
1、线程的创建以及线程间的通信和同步都比进程要快。在多核CPU上的任务分割是对线程而言的,不是进程。
2、如果不需要频繁的创建和销毁 执行的效率是并不多的,需要频繁创建的话,线程快。
3、其它的就根据你的实际情况选择了, 要是没有数据通信什么的,线程间的通信比进程间方便。最关键的一点,多线程可以让同一个程序的不同部分并发执行。
所以在做安防系统的时候,报警系统和监控系统之间可以用多进程来做,对于报警系统中可以用多线程来实现如果发生意外,可以向用户发送消息,同时鸣笛,以及如果是火警的话,可以打开阀门等。
进程间通信
unix系统主要进程间通信机制(IPC)
管道
FIFO(命名管道)
消息队列
共享内存
信号量
套接字
3. 管道
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207407
管道是最常见的IPC机制,是单工的,如果要两个进程实现双向传输则需要两个管道,管道创建的时候既有两端,一个读端和一个写端。两个进程要协调好,一个进程从读的方向读,一个进程从写的方向写,并且只能在关系进程间进行,比如父子进程,通过系统调用pipe()函数实现。
#include
int pipe(int fd[2]);
fd[0]:文件描述符,用于读操作
fd[1]:文件描述符,用于写操作
返回值:成功返回0,如果创建失败将返回-1并记录错误码
4. FIFO
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207413
FIFO又称命名管道,通过FIFO的通信可以发生在任何两个进程之间,且只需要对FIFO有适当的访问权限,对FIFO的读写操作与普通文件类似,命名管道的创建是通过mkfifo()函数创建的。
#include
int mkfifo(const char *filename, mode_t mode)
filename:命名管道的文件名
mode:访问权限
返回值:若成功则返回0,否则返回-1,错误原因存于errno中。
4.1 FIFO服务器实例
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define SERVER_FIFO_NAME "./serv_fifo"
#define CLIENT_FIFO_NAME "./cli_%d_fifo"
#define BUFFER_SIZE 20
struct data_to_pass_st {
pid_t client_pid;
char some_data[BUFFER_SIZE - 1];
};
int main()
{
int server_fifo_fd, client_fifo_fd;
struct data_to_pass_st my_data;
int read_res;
char client_fifo[256];
char *tmp_char_ptr;
mkfifo(SERVER_FIFO_NAME, 0777);
server_fifo_fd = open(SERVER_FIFO_NAME, O_RDONLY);
if (server_fifo_fd == -1) {
fprintf(stderr, "Server fifo failure\n");
exit(EXIT_FAILURE);
}
sleep(10); /* lets clients queue for demo purposes */
do {
read_res = read(server_fifo_fd, &my_data, sizeof(my_data));
if (read_res > 0) {
tmp_char_ptr = my_data.some_data;
while (*tmp_char_ptr) {
*tmp_char_ptr = toupper(*tmp_char_ptr);
tmp_char_ptr++;
}
sprintf(client_fifo, CLIENT_FIFO_NAME, my_data.client_pid);
client_fifo_fd = open(client_fifo, O_WRONLY);
if (client_fifo_fd != -1) {
write(client_fifo_fd, &my_data, sizeof(my_data));
close(client_fifo_fd);
}
}
} while (read_res > 0);
close(server_fifo_fd);
unlink(SERVER_FIFO_NAME);
exit(EXIT_SUCCESS);
}
4.2 FIFO客户实例
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define SERVER_FIFO_NAME "./serv_fifo"
#define CLIENT_FIFO_NAME "./cli_%d_fifo"
#define BUFFER_SIZE 20
struct data_to_pass_st {
pid_t client_pid;
char some_data[BUFFER_SIZE - 1];
};
int main()
{
int server_fifo_fd, client_fifo_fd;
struct data_to_pass_st my_data;
int times_to_send;
char client_fifo[256];
server_fifo_fd = open(SERVER_FIFO_NAME, O_WRONLY);
if (server_fifo_fd == -1) {
fprintf(stderr, "Sorry, no server\n");
exit(EXIT_FAILURE);
}
my_data.client_pid = getpid();
sprintf(client_fifo, CLIENT_FIFO_NAME, my_data.client_pid);
if (mkfifo(client_fifo, 0777) == -1) {
fprintf(stderr, "Sorry, can't make %s\n", client_fifo);
exit(EXIT_FAILURE);
}
for (times_to_send = 0; times_to_send < 5; times_to_send++) {
sprintf(my_data.some_data, "Hello from %d", my_data.client_pid);
printf("%d sent %s, ", my_data.client_pid, my_data.some_data);
write(server_fifo_fd, &my_data, sizeof(my_data));
client_fifo_fd = open(client_fifo, O_RDONLY);
if (client_fifo_fd != -1) {
if (read(client_fifo_fd, &my_data, sizeof(my_data)) > 0) {
printf("received: %s\n", my_data.some_data);
}
close(client_fifo_fd);
}
}
close(server_fifo_fd);
unlink(client_fifo);
exit(EXIT_SUCCESS);
}
5. 消息队列
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207459
消息队列有如下特点:
(1) 通过消息队列key值来定义和生成消息队列
(2) 任何进程只要有访问权限并且知道key就可以访问消息队列
(3) 消息队列为内存块方式数据段
(4) 消息队列的消息长度可为系统参数限制内的任何长度
(5) 消息队列有消息类型,访问可以按类型访问
(6) 在一次读写操作前都必须取得消息标识符,即访问权,访问后脱离关系
(7) 消息队列中的某条消息被读后立即自动的从消息队列中删除
(8) 消息队列具有加锁处理机制
(9) 在权限允许时,消息队列的信息可以双向传递
6. 共享内存
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207467
共享内存是效率最高的IPC机制,他允许任何两个进程访问相同的逻辑内存区,它具有一下特点:
(1) 通过共享内存key值定义和生成共享内存
(2) 任何进程只要有访问权限并且知道key就可以访问共享内存
(3) 共享内存为内存块方式数据段
(4) 共享内存的消息长度可为系统参数限制内的任何长度
(5) 共享内存的访问方式与数组的访问方式相同
(6) 在取得共享内存标识符将共享内存与进程数据段连接后即可以开始对其进行读写操作,在所有操作完成之后再做共享内存与进程数据段的脱离操作,才完成内存访问的过程
(7) 共享内存中的数据不会因为数据被进程读取后消失
(8) 共享内存不具备锁机制,所有共享内存最好与信号量一起使用来保证数据的一致性
(9) 在权限允许时,共享内存的信息传递时双向的
7. 信号量
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207464
信号量是一种同步机制,主要用途是保护临界资源(在一个时刻只能被一个进程所拥有),通常与共享内存一起使用。
6.1 semget()函数
#include
int semget(key_t key, int num_sems, int sem_flags)
key:信号量集合的键
num_sems:信号量集合里面元素个数
sem_flags:任选参数
返回值:返回信号量集合标识符,出错返回-1
6.2 semop()函数
#include
int semop(int sem_id, struct sembuf *sem_ops , size_t num_sem_ops)
sem_id: 信号量集合标识符
sem_ops:信号量操作结构的指针
num_sem_ops:信号量操作结构的个数
6.3 semctl)函数
#include
int semctl (int sem_id, int sem_num, int command, …)
sem_id: 信号量集合标识符
sem_num:信号量元素编号
command:控制命令
…:命令参数列表
返回值:根据命令返回相应的值,出错返回-1
http://timyang.net/linux/linux-process/
上周碰到部署在真实服务器上某个应用CPU占用过高的问题,虽然经过tuning, 问题貌似已经解决,但我对tuning的方式只是基于大胆的假设并最终生效了。我更希望更多的求证一下程序背后CPU及OS kernel当时的运作机制。所以我读了一些Linux内核设计与实现及其他一些相关资料,对Linux process的机制与切换有了更多一些体会。本文尽可能条理一点,但由于牵涉点较多,同时自己可能觉得某些点有记录的价值,因此文字可能会零散。
- 进程状态
Linux进程的状态比较容易理解,值得注意的是 UNINTERRUPTIBLE 及 ZOMBIE
TASK_RUNNING
TASK_INTERRUPTIBLE
TASK_UNINTERRUPTIBLE 此时进程不接收信号,这就是为什么有时候kill一个繁忙的进程没有响应。
TASK_ZOMBIE 我们经常 kill -9 pid 之后运行ps会发现被kill的进程仍然存在,状态为 zombie。zombie的进程实际上已经结束,占用的资源也已经释放,仅由于kernel的相关进程描述符还未释放。
TASK_STOPPED
- Kernel space and user space
Kernel space是供内核,设备驱动运行的内存区域。user space是供普通应用程序运行的区域。每一个进程都运行在自己的虚拟内存区域,不能访问其他进程的内存空间。普通进程不能访问kernel space, 只能通过系统调用来间接进行。当系统内存比较紧张时,非当前运行进程user space可能会被swap到磁盘。
使用命令 pmap -x 可以查看进程的内存占用信息; lsof -a -p 可以查看一个进程打开的文件信息。ps -Lf 可以查看进程的线程数。
另外procfs也是一个分析进程结构的好地方。procfs是一个虚拟的文件系统,它把系统中正在运行的进程都显现在/proc/目录下。
- 进程创建
进程创建通常调用fork实现。创建后子进程和父进程指向同一内存区域,仅当子进程有write发生时候,才会把改动的区域copy到子进程新的地址空间,这就是copy-on-write技术,它极大的提高了创建进程的速度。
- Linux的线程实现
Linux线程是通过进程来实现。Linux kernel为进程创建提供一个clone()系统调用,clone的参数包括如 CLONE_VM, CLONE_FILES, CLONE_SIGHAND 等。通过clone()的参数,新创建的进程,也称为LWP(Lightweight process)与父进程共享内存空间,文件句柄,信号处理等,从而达到创建线程相同的目的。
Linux 2.6的线程库叫NPTL(Native POSIX Thread Library)。POSIX thread(pthread)是一个编程规范,通过此规范开发的多线程程序具有良好的跨平台特性。尽管是基于进程的实现,但新版的NPTL创建线程的效率非常高。一些测试显示,基于NPTL的内核创建10万个线程只需要2秒,而没有NPTL支持的内核则需要长达15分钟。
在Linux 2.6之前,Linux kernel并没有真正的thread支持,一些thread library都是在clone()基础上的一些基于user space的封装,因此通常在信号处理、进程调度(每个进程需要一个额外的调度线程)及多线程之间同步共享资源等方面存在一定问题。为了解决这些问题,当年IBM曾经开发一套NGPT(Next Generation POSIX Threads), 效率比 LinuxThreads有明显改进,但由于NPTL的推出,NGPT也完成了相关的历史使命并停止了开发。
NPTL的实现是在kernel增加了futex(fast userspace mutex)支持用于处理线程之间的sleep与wake。futex是一种高效的对共享资源互斥访问的算法。kernel在里面起仲裁作用,但通常都由进程自行完成。
NPTL是一个1×1的线程模型,即一个线程对于一个操作系统的调度进程,优点是非常简单。而其他一些操作系统比如Solaris则是MxN的,M对应创建的线程数,N对应操作系统可以运行的实体。(N<m),优点是线程切换快,但实现稍复杂。< p="">
- 信号
进程接收信号有两种:同步和异步。同步信号比如SEGILL(非法访问), SIGSEGV(segmentation fault)等。发生此类信号之后,系统会立即转到内核陷阱处理程序,因此同步信号也称为陷阱。异步信号如kill, lwp_kill, sigsend等调用产生的都是,异步信号也称为中断。
kill 调用的是 SIGTERM, 此信号可以被捕获和忽略。
kill -9 调用的是 SIGKILL, 杀掉进程,不能被捕获和忽略。
SIGHUP是在终端被断开时候调用,如果信号没有被处理,进程会终止。这就是为什么突然断网刚通过远程终端启动的进程都终止的原因。防止的方法是在启动的命令前加上 nohup 命令来忽略 SIGHUP信号。如 nohup ./startup.sh &
很多应用程序通常捕获SIGHUP用来实现一些自定义特性,比如通过控制台传递信号让正在运行的程序重新加载配置文件,避免重启带来的停止服务的副作用。可惜的是,在JAVA中没法直接使用这一功能,SUN JVM没有官方的signal支持,尽管它已经可以实现,详情可参看Singals and Java.
另外有个有趣的现象是 zombie 状态的进程 kill/kill -9 都没有任何作用,这是由于进程本身已经不存在,所以没有相应的进程来处理signal, zombie状态的进程只是kernel中的进程描述符及相关数据结构没有释放,但进程实体已经不存在了。
关于僵尸进程,也可参看下酷壳上的这篇Linux 的僵尸(zombie)进程,从程序的角度解释了相关原理。
几种进程通信方法的研究和比较
(宁波大学科学技术学院理工分院浙江宁波315211)
1.引言
为了提高计算机系统的效率.增强计算机系统内各种硬件
的并行操作能力.操作系统要求程序结构必须适应并发处理的
需要.为此引入了进程的概念。进程是操作系统的核心,所有基
于多道程序设计的操作系统都建立在进程的概念之上。目前的
计算机系统均提供了多任务并行环境.无论是应用程序还是系
统程序.都需要针对每一个任务创建相应的进程。进程是设计和
分析操作系统的有力工具。然而不同的进程之间.即使是具有家
族联系的父子进程.都具有各自不同的进程映像。由于不同的进
程运行在各自不同的内存空间中.一方对于变量的修改另一方
是无法感知的.因此.进程之间的信息传递不可能通过变量或其
它数据结构直接进行,只能通过进程间通信来完成。并发进程之
间的相互通信是实现多进程间协作和同步的常用工具.具有很
强的实用性
2.进程通信分类
进程通信是操作系统内核层极为重要的部分 根据进程通
信时信息量大小的不同,可以将进程通信划分为两大类型:控制
信息的通信和大批数据信息的通信.前者称为低级通信,后者称
为高级通信
低级通信主要用于进程之间的同步、互斥、终止、挂起等等
控制信息的传递,主要有以下三种方式:
(1)利用系统调用睡眠SLEEP()和唤醒WAKEUP()实现
进程之间的同步,互斥。SLE EP可以使调用它的进程以指定的优
先级在系统的某个等待队列上睡眠.而WAKEUP则用来唤醒在
指定队列上睡眠的进程
(2)利用系统调用WAIT'()和EXIT()实现父子进程之间的
同步 调用WAIT的父进程必须等待子进程运行结束才能继续
运行,而EXIT则可以用来终止某一个进程,并把相关状态返回
给它的父进程
(3)利用软中断信号实现同一用户的各进程之间的通信。
高级通信主要用于进程间数据块的交换和共享 常见的高级通
信有管道(PIPE)、消息队列(MESSAGE)、共享内存(SHARED
MEM0RY)等。
3.软中断通信
软中断信号是一种简单且最基本的进程间通信机制.它最
大的特点是提供了一种简单的处理异步事件的方法。例如,我们
常见的用户从键盘输入组合键Ctrl+C来中断一个程序的运行.
或者在两个进程之间通过某个信号来通知发生了异步事件.或
者向系统或进程报告突发的硬件故障如非法指令、运算溢出等
等 更重要的是用户进程还可以向自己发送信号以中断程序的
执行.并自动转入指定的软中断处理函数中去执行用户自行安
排的处理内容.处理完毕后再返回用户进程继续执行.从而为应
用程序提供了由用户自行处理随机事件的通信机制。
因此,软中断信号实现(signal implementation)是操作系统
用来通知进程有事件发生的一种机制 由于这种信号总是在进
程处于运行状态时才会去响应的.故称之为软中断信号。
软中断信号的使用者是操作系统和用户源程序.操作系统
事先将系统中可以使用的软中断信号进行集中编码并定义相应
含义后.提交用户使用。用户可以通过相应的软中断序号或软中
断名称来使用软中断
4.管道通信(PIPE)
管道是一种常用的单向进程间通信机制 两个进程利用管
道进行通信时.发送信息的进程称为写进程.接收信息的进程称
为读进程。管道通信方式的中间介质就是文件.通常称这种文件
为管道文件.它就像管道一样将一个写进程和一个读进程连接
在一起,实现两个进程之间的通信。写进程通过写入端(发送端)
往管道文件中写入信息;读进程通过读出端(接收端)从管道文
件中读取信息。两个进程协调不断地进行写和读,便会构成双方
通过管道传递信息的流水线。
利用系统调用PIPE()可以创建一个无名管道文件,通常称
为无名管道或PIPE;利用系统调用MKNOD()可以创建一个有
名管道文件.通常称为有名管道或FIFO。无名管道是一种非永
久性的管道通信机构.当它访问的进程全部终止时,它也将随之
被撤消。无名管道只能用在具有家族联系的进程之间。有名管道
可以长期存在于系统之中.而且提供给任意关系的进程使用,但
是使用不当容易导致出错.所以操作系统将命名管道的管理权
交由系统来加以控制
管道文件被创建后,可以通过系统调用WRITE()和READ
()来实现对管道的读写操作;通信完毕后,可用CLOSE()将管道
文件关闭。
5.消息缓冲通信(MESSAGE)
多个独立的进程之间可以通过消息缓冲机制来相互通信.
这种通信的实现是以消息缓冲区为中间介质.通信双方的发送
和接收操作均以消息为单位。在存储器中,消息缓冲区被组织成
队列,通常称之为消息队列。消息队列一旦创建后即可由多进程
共享.发送消息的进程可以在任意时刻发送任意个消息到指定
的消息队列上,并检查是否有接收进程在等待它所发送的消息。
若有则唤醒它:而接收消息的进程可以在需要消息的时候到指
定的消息队列上获取消息.如果消息还没有到来.则转入睡眠状
态等待。
由于一个消息队列由多个进程共享.因此挂在队列上的消
息需要统一规格。以Linux为例.系统定义了一个公用的消息缓
冲区数据结构msgbuf.而消息队列则是由若干msgbuf构成的链
表。利用系统调用MSGGET()可以创建消息队列,这一步工作也
被称为消息队列的初始化。在进行消息缓冲通信时.发送消息进
程使用系统调用MSGSND()将消息挂人消息队列,接收消息进
程使用系统调用MSGREC()从消息队列上摘取消息。在需要改
变队列的使用权限及其它一些特性时,用MSGCTL()来实现。
共享的消息队列是一个临界资源,针对同一消息队列的诸
发送和接收进程必须保证互斥进入,这种进程间的同步和互斥
是由系统提供的系统调用自动实现的,所以用户在使用时不需
要再考虑它们之间的同步关系.非常方便。
但是消息发送进程在发送消息前必须先请求一个msgbuf,
然后将要发送的消息从私有的地址空间中复制
到msgbuf中才能发送;消息接收进程则相反,必须先从消息队
列上摘取消息msgbuf.再将msgbuf中的信息复制到自己的程序
空间中。因此,在消息缓冲通信方式中需要进行大量额外的复制
操作,这是消息缓冲通信方式的缺点。
6.共享内存通信(SHARED MEMORY)
针对消息缓冲需要占用CPU进行消息复制的缺点.OS提
供了一种进程间直接进行数据交换的通信方式一共享内存 顾
名思义.这种通信方式允许多个进程在外部通信协议或同步,互
斥机制的支持下使用同一个内存段(作为中间介质)进行通信.
它是一种最有效的数据通信方式,其特点是没有中间环节.直接
将共享的内存页面通过附接.映射到相互通信的进程各自的虚
拟地址空间中.从而使多个进程可以直接访问同一个物理内存
页面.如同访问自己的私有空间一样(但实质上不是私有的而是
共享的)。因此这种进程间通信方式是在同一个计算机系统中的
诸进程间实现通信的最快捷的方法.而它的局限性也在于此.即
共享内存的诸进程必须共处同一个计算机系统.有物理内存可
以共享才行。
与消息缓冲通信类似.在进行共享内存通信之前.必须先通
过系统调用SHMGET()创建一个共享内存段.然后使用系统调
用SHMAT()和SHMDT()来实现共享内存的映射和分离.用系
统调用SHMCTL()来改变共享内存段的存取权限及其它一些特
性。
共享内存通信与消息缓冲通信有很多相似之处:多个进程
都是通过获取共享内存的标识符来访问指定的共享内存.都要
进行权限检查等等。不同的是共享内存一旦附接后就作为进程
地址空间的一部分提供给进程使用 对于该共享内存的读写操
作如同对进程私有的缓冲区一样.操作系统不再关心进程间是
如何使用这个共享内存,更无法进行干预。因此。系统提供的共
享内存系统调用函数是不带同步工具的. 多个进程对共享内存
的读写操作所需要的同步和互斥则必须由各进程通过使用其它
的同步工具来解决。
7.几种通信方法总结
综上所述.进程之间的多种通信方法各自有各自的优点和
缺点:
如果用户传递的信息较少.或是需要通过信号来触发某些
行为.前文提到的软中断信号机制不失为一种简捷有效的进程
间通信方式.但若是进程间要求传递的信息量比较大或者进程
间存在交换数据的要求,那就需要考虑别的通信方式了。
无名管道简单方便.但局限于单向通信的工作方式.并且只
能在创建它的进程及其子孙进程之间实现管道的共享:有名管
道虽然可以提供给任意关系的进程使用.但是由于其长期存在
于系统之中,使用不当容易出错.所以普通用户一般不建议使
用。
消息缓冲可以不再局限于父子进程.而允许任意进程通过
共享消息队列来实现进程间通信.并由系统调用函数来实现消
息发送和接收之间的同步.从而使得用户在使用消息缓冲进行
通信时不再需要考虑同步问题.使用方便,但是信息的复制需要
额外消耗CPU的时间.不适宜于信息量大或操作频繁的场合。
共享内存针对消息缓冲的缺点改而利用内存缓冲区直接交
换信息,无须复制,快捷、信息量大是其优点。但是共享内存的通
信方式是通过将共享的内存缓冲区直接附加到进程的虚拟地址
空间中来实现的.因此,这些进程之间的读写操作的同步问题操
作系统无法实现。必须由各进程利用其他同步工具解决。另外,
由于内存实体存在于计算机系统中.所以只能由处于同一个计
算机系统中的诸进程共享。不方便网络通信。
不同的进程通信方式有不同的优点和缺点.因此.对于不同
的应用问题,要根据问题本身的情况来选择进程间的通信方式。
参考文献:
1.胡明庆、高魏、钟梅.操作系统与实验教程.清华大学出版社.2006年
8月
2.庞丽萍。操作系统原理.牟中科技大学出版社。2ooo卑
3.黄超.1mux高级开发技术.机械工业出版社.2002年
Linux 线程与进程,以及通信的更多相关文章
- Linux 线程(进程)数限制分析
1.问题来源公司线上环境出现MQ不能接受消息的异常,运维和开发人员临时切换另一台服务器的MQ后恢复.同时运维人员反馈在出现问题的服务器上很多基本的命令都不能运行,出现如下错误:2. 初步原因分析和 ...
- linux学习之进程,线程和程序
程序.进程和线程的概念 1:程序和进 ...
- Linux下的进程与线程(二)—— 信号
Linux进程之间的通信: 本文主要讨论信号问题. 在Linux下的进程与线程(一)中提到,调度器可以用中断的方式调度进程. 然而,进程是怎么知道自己需要被调度了呢?是内核通过向进程发送信号,进程才得 ...
- linux下的进程,子进程,线程
1.相同点:(a)二者都具有ID,一组寄存器,状态,优先级以及所要遵循的调度策略.(b) 每个进程都有一个进程控制块,线程也拥有一个线程控制块.(c) 线程和子进程共享父进程中的资源:线程和子进程独立 ...
- LINUX操作系统知识:进程与线程详解
当一个程序开始执行后,在开始执行到执行完毕退出这段时间内,它在内存中的部分就叫称作一个进程. Linux 是一个多任务的操作系统,也就是说,在同一时间内,可以有多个进程同时执行.我们大家常用的单CPU ...
- 六、linux基础-计算机网络_线程_进程
6 计算机网络-线程和进程6.1 TCP/IP协议 TCP/IP是Unix/Linux世界的网络基础,在某种意义上,Unix网络就是Tcp/ip,而且Tcp/ip就是网络互连的标准他不是一个独立的协议 ...
- linux中的进程和线程
应用程序:可以被操作系统执行的一组指令和参数的集合,是静态的,并存储在磁盘空间中: 进程:在操作系统中在运行程序后,处于运行状态的程序,是应用程序的一个执行过程,同时也是操作系统分配内存,cpu等系统 ...
- Linux系统编程@进程通信(一)
进程间通信概述 需要进程通信的原因: 数据传输 资源共享 通知事件 进程控制 Linux进程间通信(IPC)发展由来 Unix进程间通信 基于System V进程间通信(System V:UNIX系统 ...
- linux 线程的内核栈是独立的还是共享父进程的?
需要考证 考证结果: 其内核栈是独立的 206 static struct task_struct *dup_task_struct(struct task_struct *orig) 207 { 2 ...
随机推荐
- zabbix监控windows主机网卡流量
监控windows主机网卡流量 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 欢迎加入:高级运维工程师之路 598432640 客户端配置:(172.30.1.120,wi ...
- SQL order by 两个字段排序
select * from emp;
- bzoj4547 小奇的集合
当序列中最大和次大都是负数的时候,其相加会是一个更小的负数,因此答案为(Σai)+(m1+m2)*k,如果最大是正数次大是负数,那么一直相加直到两个数都为正数,当最大和次大都是正数时,做一下矩阵乘法即 ...
- SQL Server XML基础学习之<7>--XML modify() 方法对 XML 数据中插入、更新或删除
/*------------------------------------------------------------------------------+ #| = : = : = : = : ...
- jquery stop
stop():停止当前活动的动画,但允许已排队的动画向前执行 stop(true):停止当前活动的动画,并清空动画队列:因此元素上的所有动画都会停止 stop(true,true):会立即完成当前活动 ...
- (转) 关于Oracle EBS邮件服务无法使用的报错
来源http://blog.itpub.net/23850820/viewspace-1060596/ 也可以检查如下网站:http://blog.sina.com.cn/s/blog_5b021b4 ...
- Hibernate开始上手总结
1,导入hibernate 的jar包,c3p0jar包 2,创建和表关联的实体类,创建关联实体类的配置文件 package com.entity; public class News { priva ...
- 夺命雷公狗---2016-linux---2之软件实现远程登录
废话不多说,操作方法如下所示:
- js 中的call()函数
a.call(b); 官方说:什么对象替换什么对象. a对象的方法应用到b对象上(函数apply的意思正好说明符合这样理解:a对象应用到b对象上去) a对象既然添加到b对象上了.那么b对象自然就拥有了 ...
- Python File.readlines() 方法
python3的用法: