《利用python进行数据分析》读书笔记--第十章 时间序列(三)
7、时间序列绘图
pandas时间序列的绘图功能在日期格式化方面比matplotlib原生的要好。
#-*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
from pandas import Series,DataFrame
from datetime import datetime
from dateutil.parser import parse
import time
from pandas.tseries.offsets import Hour,Minute,Day,MonthEnd
import pytz
#下面两个参数,一个是解析日期形式,一个是将第一列作为行名
close_px_all = pd.read_csv('E:\\stock_px.csv',parse_dates = True,index_col = 0)
print close_px_all.head(),'\n'
close_px = close_px_all[['AAPL','MSFT','XOM']]
close_px = close_px.resample('B',fill_method = 'ffill')
print close_px.head()
#注意下面的索引方式即可
close_px['AAPL'].plot()
close_px.ix[''].plot()
close_px['AAPL'].ix['01-2011':'03-2011'].plot()
#季度型频率的数据会用季度标记进行格式化,这种事情手工的话会很费力……(真是有道理……)
appl_q = close_px['AAPL'].resample('Q-DEC',fill_method = 'ffill')
appl_q.ix['':].plot()
#作者说交互方式右键按住日期会动态展开或收缩,实际自己做,没效果……
plt.show()
>>>
AA AAPL GE IBM JNJ MSFT PEP SPX XOM
1990-02-01 4.98 7.86 2.87 16.79 4.27 0.51 6.04 328.79 6.12
1990-02-02 5.04 8.00 2.87 16.89 4.37 0.51 6.09 330.92 6.24
1990-02-05 5.07 8.18 2.87 17.32 4.34 0.51 6.05 331.85 6.25
1990-02-06 5.01 8.12 2.88 17.56 4.32 0.51 6.15 329.66 6.23
1990-02-07 5.04 7.77 2.91 17.93 4.38 0.51 6.17 333.75 6.33 AAPL MSFT XOM
1990-02-01 7.86 0.51 6.12
1990-02-02 8.00 0.51 6.24
1990-02-05 8.18 0.51 6.25
1990-02-06 8.12 0.51 6.23
1990-02-07 7.77 0.51 6.33
[Finished in 37.5s]
下面是作出的几张图:
8、移动窗口函数
在移动窗口(可以带有指数衰减权数)上计算的各种统计函数也是一类常见于时间序列的数组变换。作者将其称为移动窗口函数(moving window function),其中还包括那些窗口不定长的函数(如指数加权移动平均)。跟其他统计函数一样,移动窗口函数也会自动排除缺失值。这样的函数通常需要指定一些数量的非NA观测值。
#-*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
from pandas import Series,DataFrame
from datetime import datetime
from dateutil.parser import parse
import time
from pandas.tseries.offsets import Hour,Minute,Day,MonthEnd
import pytz #rolling_mean是其中最简单的一个。它接受一个TimeSeries或DataFrame以及一个window(表示期数)
close_px_all = pd.read_csv('E:\\stock_px.csv',parse_dates = True,index_col = 0)
print close_px_all.head(),'\n'
close_px = close_px_all[['AAPL','MSFT','XOM']]
close_px = close_px.resample('B',fill_method = 'ffill')
close_px.AAPL.plot()
pd.rolling_mean(close_px.AAPL,250).plot()
plt.show()
#默认情况下,诸如rolling_mean这样的涵涵素需要指定数量的非NA观测值。可以修改该行为以解决缺失数据的问题,其实,
#在时间序列开始处尚不足窗口期的那些数据就是个特例(也就是前250期均线值是没有的)
#看一下下面的图
#有个参数是min_periods,文档中说的是窗口中应该有值的最小的序列标号,可是如果是250期的标准差值,250之前怎么会有数呢?。。。难道是自动转换了周期?
#YES!确实是这样,min_periods是指自这个标号开始,计算前面所有数的std,比如min_periods = 10时,计算前10个数的,min_periods = 20时,计算前20个数的,知道min_periods = 250为止,这就是所谓的“指定的非NA观测值”
close_px.AAPL.plot()
appl_std250 = pd.rolling_std(close_px.AAPL,250,min_periods = 10)
print appl_std250[:15]
appl_std250.plot()
plt.show()
>>>
AA AAPL GE IBM JNJ MSFT PEP SPX XOM
1990-02-01 4.98 7.86 2.87 16.79 4.27 0.51 6.04 328.79 6.12
1990-02-02 5.04 8.00 2.87 16.89 4.37 0.51 6.09 330.92 6.24
1990-02-05 5.07 8.18 2.87 17.32 4.34 0.51 6.05 331.85 6.25
1990-02-06 5.01 8.12 2.88 17.56 4.32 0.51 6.15 329.66 6.23
1990-02-07 5.04 7.77 2.91 17.93 4.38 0.51 6.17 333.75 6.33 1990-02-01 NaN
1990-02-02 NaN
1990-02-05 NaN
1990-02-06 NaN
1990-02-07 NaN
1990-02-08 NaN
1990-02-09 NaN
1990-02-12 NaN
1990-02-13 NaN
1990-02-14 0.148189
1990-02-15 0.141003
1990-02-16 0.135454
1990-02-19 0.130502
1990-02-20 0.128690
1990-02-21 0.124108
Freq: B
[Finished in 4.6s]
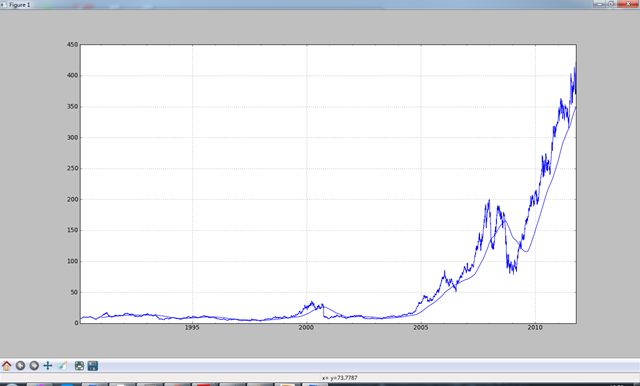
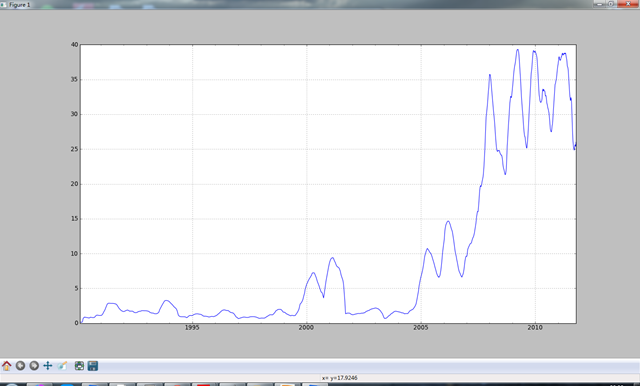
要计算扩展窗口平均(expanding window mean),可以将扩展窗口看作一个特殊的窗口,其长度与时间序列一样,但只需一期或多期即可计算一个值。
#通过rolling_mean定义扩展平均
expanding_mean = lambda x:rolling_mean(x,len(x),min_periods = 1)
#对DataFrame调用rolling_mean(以及其他类似函数)会将转换应用到所有列上
#下面的logy是将纵坐标显示为科学计数法,暂时搞不懂怎么变换的
mean_60 = pd.rolling_mean(close_px,60).plot()
mean_60 = pd.rolling_mean(close_px,60).plot(logy = True) #print mean_60[(len(mean_60) - 20):len(mean_60)]
plt.show()
'''
ts = pd.Series(range(10), index=pd.date_range('1/1/2000', periods=10))
#ts = np.exp(ts.cumsum())
print ts
print np.log(ts)
ts.plot(logy=True)
plt.show()
'''
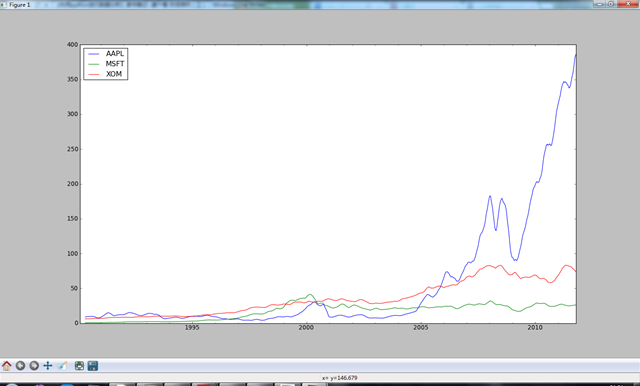
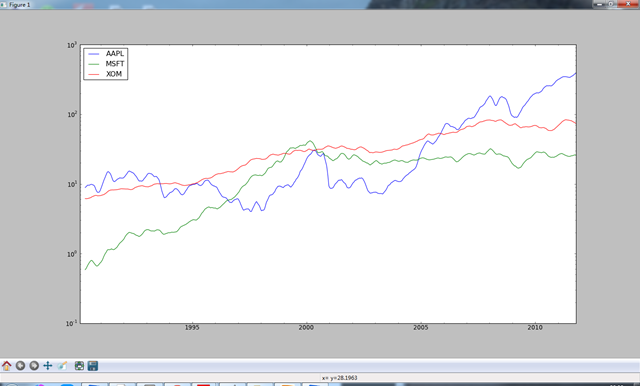

- 指数加权函数
另一种使用固定大小窗口及相等权数观测值的方法是,定义一个衰减因子(decay factor)常量,以便使近期的观测值拥有更大的权数。衰减因子的定义方式有很多,比较流行的是使用时间间隔(span),它可以使结果兼容于窗口大小等于时间间隔的简单移动窗口函数。
fig,axes = plt.subplots(nrows = 2,ncols = 1,sharex = True,sharey = True,figsize = (12,7))
aapl_px = close_px.AAPL['':'']
ma60 = pd.rolling_mean(aapl_px,60,min_periods = 50)
ewma60 = pd.ewma(aapl_px,span = 60) aapl_px.plot(style = 'k-',ax = axes[0])
ma60.plot(style = 'k--',ax = axes[0])
aapl_px.plot(style = 'k-',ax = axes[1])
ewma60.plot(style = 'k--',ax = axes[1])
axes[0].set_title('Simple MA')
axes[1].set_title('Exponentially-weighted MA')
plt.show()
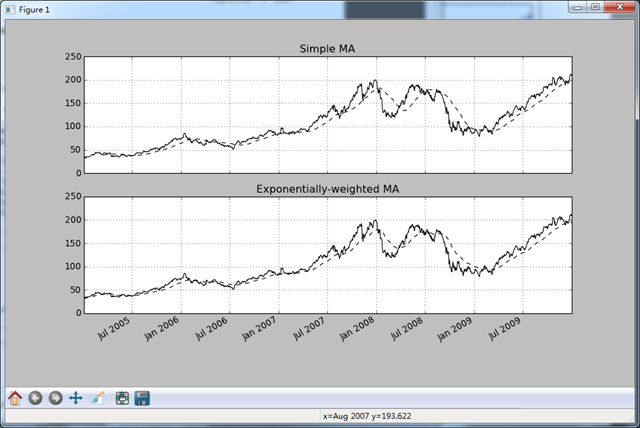
- 二元移动窗口函数
有些统计运算(如相关系数和协方差)需要在两个时间序列上执行。比如,金融分析师常常对某只股票对某个参数(如标普500指数)的相关系数感兴趣。我们可以通过计算百分比变化并使用rolling_corr的方式得到该结果。
#-*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
from pandas import Series,DataFrame
from datetime import datetime
from dateutil.parser import parse
import time
from pandas.tseries.offsets import Hour,Minute,Day,MonthEnd
import pytz #rolling_mean是其中最简单的一个。它接受一个TimeSeries或DataFrame以及一个window(表示期数)
close_px_all = pd.read_csv('E:\\stock_px.csv',parse_dates = True,index_col = 0)
print close_px_all.head(),'\n'
close_px = close_px_all[['AAPL','MSFT','XOM']] spx_px = close_px_all['SPX']
print spx_px
#下面是将spx_px数据后移一位,减1是将数据减1,当然后面的是先除,再减1
#print spx_px.shift(1) - 1
spx_rets = spx_px / spx_px.shift(1) - 1
#看一下,下面的函数是跟上面的一样,作者是为了展示函数才这么写的
#spx_rets_pct_change = spx_px.pct_change()
#print spx_rets_pct_change[:10]
print spx_rets[:10],'\n'
returns = close_px.pct_change()
print returns[:10]
corr = pd.rolling_corr(returns.AAPL,spx_rets,125,min_periods = 100)
corr.plot()
plt.show()
>>>
AA AAPL GE IBM JNJ MSFT PEP SPX XOM
1990-02-01 4.98 7.86 2.87 16.79 4.27 0.51 6.04 328.79 6.12
1990-02-02 5.04 8.00 2.87 16.89 4.37 0.51 6.09 330.92 6.24
1990-02-05 5.07 8.18 2.87 17.32 4.34 0.51 6.05 331.85 6.25
1990-02-06 5.01 8.12 2.88 17.56 4.32 0.51 6.15 329.66 6.23
1990-02-07 5.04 7.77 2.91 17.93 4.38 0.51 6.17 333.75 6.33 1990-02-01 328.79
1990-02-02 330.92
1990-02-05 331.85
1990-02-06 329.66
1990-02-07 333.75
1990-02-08 332.96
1990-02-09 333.62
1990-02-12 330.08
1990-02-13 331.02
1990-02-14 332.01
1990-02-15 334.89
1990-02-16 332.72
1990-02-20 327.99
1990-02-21 327.67
1990-02-22 325.70
...
2011-09-26 1162.95
2011-09-27 1175.38
2011-09-28 1151.06
2011-09-29 1160.40
2011-09-30 1131.42
2011-10-03 1099.23
2011-10-04 1123.95
2011-10-05 1144.03
2011-10-06 1164.97
2011-10-07 1155.46
2011-10-10 1194.89
2011-10-11 1195.54
2011-10-12 1207.25
2011-10-13 1203.66
2011-10-14 1224.58
Name: SPX, Length: 5472
1990-02-01 NaN
1990-02-02 0.006478
1990-02-05 0.002810
1990-02-06 -0.006599
1990-02-07 0.012407
1990-02-08 -0.002367
1990-02-09 0.001982
1990-02-12 -0.010611
1990-02-13 0.002848
1990-02-14 0.002991
Name: SPX AAPL MSFT XOM
1990-02-01 NaN NaN NaN
1990-02-02 0.017812 0.000000 0.019608
1990-02-05 0.022500 0.000000 0.001603
1990-02-06 -0.007335 0.000000 -0.003200
1990-02-07 -0.043103 0.000000 0.016051
1990-02-08 -0.007722 0.000000 0.003160
1990-02-09 0.037613 0.019608 0.003150
1990-02-12 -0.007500 0.000000 -0.023548
1990-02-13 0.015113 0.000000 0.001608
1990-02-14 -0.007444 0.000000 -0.004815
[Finished in 50.8s]
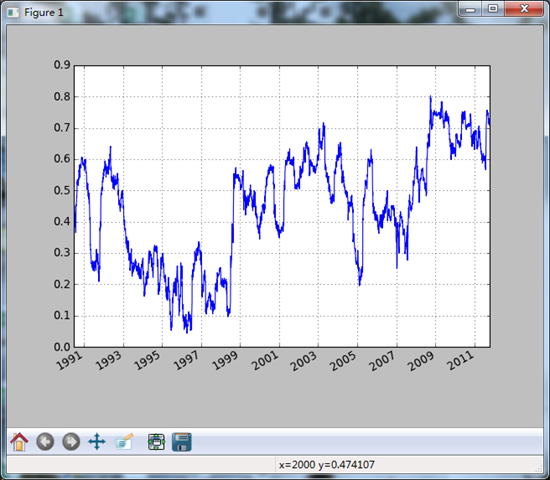
假如现在想同时计算多只股票与标普的相关系数。只需传入一个TimeSeries和一个DataFrame,rolling_corr就会自动计算TimeSeries与DataFrame各列的相关系数。
corr = pd.rolling_corr(returns,spx_rets,125,min_periods = 100)
corr.plot()
plt.show()
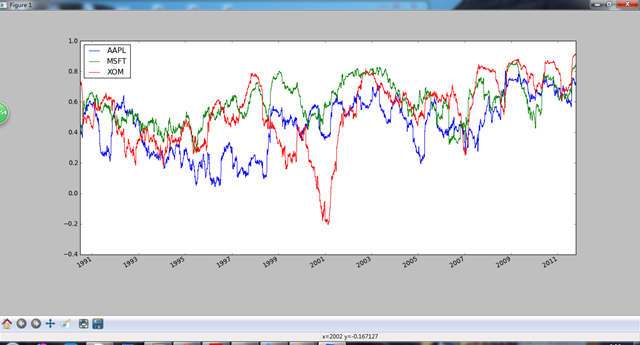
- 用户自定义的移动窗口函数
rolling_apply函数使你能够在移动窗口上应用自己设计的数组函数。唯一的要求就是:该函数要能从数组的各个片段中产生单个值。比如,当用rolling_quantile计算样本分位数时,可能对样本中特定值的百分等级感兴趣。
#-*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
from pandas import Series,DataFrame
from datetime import datetime
from dateutil.parser import parse
import time
from pandas.tseries.offsets import Hour,Minute,Day,MonthEnd
import pytz
from scipy.stats import percentileofscore #rolling_mean是其中最简单的一个。它接受一个TimeSeries或DataFrame以及一个window(表示期数)
close_px_all = pd.read_csv('E:\\stock_px.csv',parse_dates = True,index_col = 0)
close_px = close_px_all[['AAPL','MSFT','XOM']]
returns = close_px.pct_change()
#这里的percentileofscore是指,0.02在x中的位置是x中的百分比
#AAPL %2回报率的百分等级
score_at_2percent = lambda x:percentileofscore(x,0.02)
result = pd.rolling_apply(returns.AAPL,250,score_at_2percent)
result.plot()
plt.show()
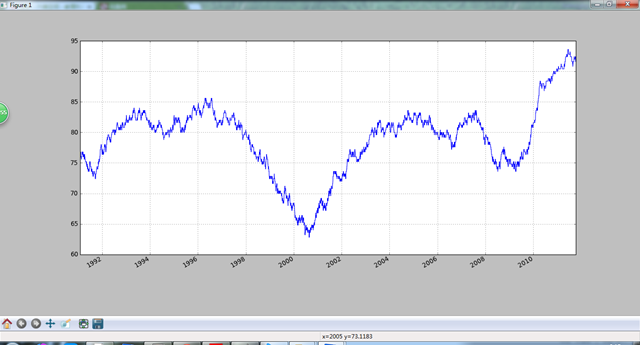
9、性能和内存使用方面的注意事项
TimeSeries和Period都是以64位整数表示的(即NumPy的datetime64数据类型)。也就是说,对于每个数据点,其时间戳需要占用8字节内存。因此,含有一百万个float64数据点的时间序列需要占用大约16MB的内存空间。由于pandas会尽量在多个时间序列之间共享索引,所以创建现有时间序列的视图不会占用更多内存。此外,低频率索引(日以上)会被存放在一个中心缓存中,所以任何固定频率的索引都是该日期缓存的视图。所以。如果你有一个很大的低频率时间序列,索引所占用的内存空间将不会很大。
性能方面,pandas对数据对齐(两个不同索引的ts1 + ts2的幕后工作)和重采样运算进行了高度优化。下面这个例子将一亿个数据点聚合为OHLC:
#-*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
from pandas import Series,DataFrame
from datetime import datetime
from dateutil.parser import parse
import time
from pandas.tseries.offsets import Hour,Minute,Day,MonthEnd
import pytz rng = pd.date_range('1/1/2000',periods = 10000000,freq = '10ms')
ts = Series(np.random.randn(len(rng)),index = rng)
print ts,'\n'
print ts.resample('15min',how = 'ohlc'),'\n'
#下面测试一下代码运行时间,下面运行不成功
#%timeit ts.resample('15min',how = 'ohlc')
#换句话说,聚合的频率越高,耗费时间越多,但是,但是仍然是非常高效的
>>>
2000-01-01 00:00:00 -0.681229
2000-01-01 00:00:00.010000 -1.231560
2000-01-01 00:00:00.020000 0.437656
2000-01-01 00:00:00.030000 2.134065
2000-01-01 00:00:00.040000 0.264029
2000-01-01 00:00:00.050000 -2.273143
2000-01-01 00:00:00.060000 1.519468
2000-01-01 00:00:00.070000 -0.052764
2000-01-01 00:00:00.080000 1.329301
2000-01-01 00:00:00.090000 -1.078996
2000-01-01 00:00:00.100000 -1.121855
2000-01-01 00:00:00.110000 -0.157845
2000-01-01 00:00:00.120000 0.453539
2000-01-01 00:00:00.130000 0.043068
2000-01-01 00:00:00.140000 0.378264
...
2000-01-02 03:46:39.850000 -0.444970
2000-01-02 03:46:39.860000 0.296446
2000-01-02 03:46:39.870000 -1.051884
2000-01-02 03:46:39.880000 0.612868
2000-01-02 03:46:39.890000 0.682818
2000-01-02 03:46:39.900000 0.375605
2000-01-02 03:46:39.910000 -0.843553
2000-01-02 03:46:39.920000 -0.861029
2000-01-02 03:46:39.930000 0.349835
2000-01-02 03:46:39.940000 0.231722
2000-01-02 03:46:39.950000 -0.268164
2000-01-02 03:46:39.960000 -1.537572
2000-01-02 03:46:39.970000 -0.634842
2000-01-02 03:46:39.980000 -1.110032
2000-01-02 03:46:39.990000 0.071214
Freq: 10L, Length: 10000000 open high low close
2000-01-01 00:00:00 -0.681229 -0.681229 -0.681229 -0.681229
2000-01-01 00:15:00 -1.231560 4.113992 -4.589095 -0.241367
2000-01-01 00:30:00 1.171302 4.593611 -4.329438 -0.099641
2000-01-01 00:45:00 -0.720612 4.432697 -4.658295 -2.278497
2000-01-01 01:00:00 0.119403 4.259349 -4.922511 1.899723
2000-01-01 01:15:00 1.168395 4.351551 -4.087221 -0.124419
2000-01-01 01:30:00 1.888486 4.288424 -4.540685 0.337621
2000-01-01 01:45:00 0.263643 4.412893 -4.362212 -1.125978
2000-01-01 02:00:00 1.398256 4.301166 -4.140143 0.693118
2000-01-01 02:15:00 -0.307263 4.353092 -4.417690 -1.647730
2000-01-01 02:30:00 1.028139 4.727692 -4.089063 0.242530
2000-01-01 02:45:00 0.857454 3.946653 -4.745711 0.270212
2000-01-01 03:00:00 -0.925215 4.544331 -4.261408 -0.616690
2000-01-01 03:15:00 -0.008779 3.958481 -4.016185 -1.055645
2000-01-01 03:30:00 0.649988 4.939031 -4.446418 0.118234
2000-01-01 03:45:00 -0.533717 4.685563 -4.205492 0.731999
2000-01-01 04:00:00 0.511450 4.483055 -3.945226 -0.814555
2000-01-01 04:15:00 0.372549 4.449327 -4.087508 0.786998
2000-01-01 04:30:00 -1.015505 4.750429 -4.111374 0.955857
2000-01-01 04:45:00 -0.450577 4.155395 -4.628542 0.621572
2000-01-01 05:00:00 0.629534 4.144105 -4.302083 1.567992
2000-01-01 05:15:00 0.843481 4.092661 -4.509020 -0.997818
2000-01-01 05:30:00 1.026566 4.004000 -4.330091 -0.745961
2000-01-01 05:45:00 0.523910 4.286510 -4.147153 -0.334644
2000-01-01 06:00:00 1.481702 4.437908 -4.198872 0.309824
2000-01-01 06:15:00 -0.530256 4.551381 -4.218254 0.112050
2000-01-01 06:30:00 -1.224188 4.245407 -4.198838 0.973066
2000-01-01 06:45:00 0.114000 4.286166 -4.070633 -1.024489
2000-01-01 07:00:00 -2.148906 4.198777 -4.213584 2.137635
2000-01-01 07:15:00 2.716069 4.308833 -4.432955 0.196065
2000-01-01 07:30:00 -0.902512 4.315467 -4.376366 -1.944492
2000-01-01 07:45:00 0.978385 4.482707 -4.343861 -0.161608
2000-01-01 08:00:00 0.028728 4.334193 -4.995541 -1.409060
2000-01-01 08:15:00 0.254613 3.944059 -4.263927 1.022247
2000-01-01 08:30:00 -2.153415 4.282622 -4.681402 0.133295
2000-01-01 08:45:00 0.361382 4.332683 -4.124674 -1.810247
2000-01-01 09:00:00 0.218621 4.087920 -4.878364 -0.247444
2000-01-01 09:15:00 1.541770 4.709500 -4.100887 0.263939
2000-01-01 09:30:00 0.302456 4.072987 -4.402301 -0.695389
2000-01-01 09:45:00 0.758779 4.854449 -4.292967 -0.098260
2000-01-01 10:00:00 -1.033195 4.412930 -4.319737 -1.078443
2000-01-01 10:15:00 -0.702287 4.687409 -4.242148 0.108918
2000-01-01 10:30:00 2.040476 4.167678 -4.069875 -0.271023
2000-01-01 10:45:00 -1.719918 4.414900 -4.003430 0.178522
2000-01-01 11:00:00 -2.003960 4.681189 -4.407995 -1.532938
2000-01-01 11:15:00 2.071234 4.691175 -4.203442 -0.000271
2000-01-01 11:30:00 -0.335169 4.577745 -4.383428 -0.356682
2000-01-01 11:45:00 0.837294 4.158462 -4.667864 -1.214194
2000-01-01 12:00:00 -0.593185 4.491041 -4.229999 -0.906558
2000-01-01 12:15:00 -0.757815 4.283729 -4.824929 0.461968
2000-01-01 12:30:00 -0.627753 4.465840 -4.382329 1.758057
2000-01-01 12:45:00 -0.582081 4.248387 -5.043421 -1.665271
2000-01-01 13:00:00 -0.232743 4.151332 -4.197010 -1.040030
2000-01-01 13:15:00 -0.099233 4.065889 -4.025087 0.400879
2000-01-01 13:30:00 0.560333 4.441687 -4.372460 -1.212408
2000-01-01 13:45:00 0.442710 4.105972 -4.284578 -0.756200
2000-01-01 14:00:00 1.280060 4.613177 -4.435858 0.793312
2000-01-01 14:15:00 0.849877 4.445931 -4.143685 -1.522613
2000-01-01 14:30:00 1.084148 4.750917 -4.196053 0.154898
2000-01-01 14:45:00 1.055437 4.320318 -4.673456 1.022639
2000-01-01 15:00:00 0.708564 4.573142 -4.251478 -0.420195
2000-01-01 15:15:00 -2.163962 4.332879 -4.207693 0.909637
2000-01-01 15:30:00 0.316790 4.269409 -4.110165 0.698051
2000-01-01 15:45:00 -0.811775 4.356382 -4.576847 1.465054
2000-01-01 16:00:00 -0.000181 4.101318 -4.549553 -0.161170
2000-01-01 16:15:00 0.293171 4.565994 -4.279151 0.574916
2000-01-01 16:30:00 1.284430 4.438795 -4.384199 -0.357597
2000-01-01 16:45:00 0.922512 4.270791 -4.365019 -0.089139
2000-01-01 17:00:00 -1.434599 4.216443 -4.599743 -0.993626
2000-01-01 17:15:00 -2.289424 4.447081 -4.129147 -0.770931
2000-01-01 17:30:00 0.235515 4.122913 -3.901979 1.107505
2000-01-01 17:45:00 0.121232 4.316179 -4.294560 -0.325761
2000-01-01 18:00:00 1.406108 4.909856 -4.380683 -1.371316
2000-01-01 18:15:00 -0.330192 4.092084 -4.433832 0.451967
2000-01-01 18:30:00 0.069717 4.602332 -4.814984 1.041939
2000-01-01 18:45:00 -2.441102 4.077937 -4.477974 -0.284751
2000-01-01 19:00:00 1.117306 4.669111 -4.433551 1.887700
2000-01-01 19:15:00 0.482482 4.545320 -4.231923 2.098973
2000-01-01 19:30:00 0.146878 4.230201 -4.738262 0.260756
2000-01-01 19:45:00 0.491376 5.230373 -5.069700 -0.936606
2000-01-01 20:00:00 -1.075473 4.701905 -4.245575 2.898905
2000-01-01 20:15:00 1.728790 4.291821 -4.145234 -0.735600
2000-01-01 20:30:00 0.680025 4.509368 -4.176570 0.346777
2000-01-01 20:45:00 -0.603546 4.479395 -4.033444 1.901963
2000-01-01 21:00:00 -0.893833 4.472098 -4.658866 0.026791
2000-01-01 21:15:00 -0.571074 4.066533 -4.773198 0.719510
2000-01-01 21:30:00 -1.109575 4.377526 -4.154108 -0.419939
2000-01-01 21:45:00 -1.109197 4.244968 -4.476610 0.625287
2000-01-01 22:00:00 -0.500703 4.204465 -4.695903 -0.205293
2000-01-01 22:15:00 -0.474312 4.278451 -4.261542 -0.605803
2000-01-01 22:30:00 -0.929173 4.679216 -4.243371 -0.389516
2000-01-01 22:45:00 0.625107 4.588921 -3.944369 0.051261
2000-01-01 23:00:00 0.223470 4.300131 -4.556017 0.411957
2000-01-01 23:15:00 2.834194 4.669853 -4.894633 -0.172413
2000-01-01 23:30:00 0.271214 4.468473 -4.059279 -0.144921
2000-01-01 23:45:00 1.005364 4.311476 -4.373045 -0.532617
2000-01-02 00:00:00 -0.177777 4.288976 -4.784412 1.279124
2000-01-02 00:15:00 1.767240 4.268321 -4.964638 0.978593
2000-01-02 00:30:00 0.874845 4.114844 -4.735220 0.755658
2000-01-02 00:45:00 0.139810 4.480646 -4.530709 1.861165
2000-01-02 01:00:00 -1.633137 4.237701 -4.465151 1.502397
2000-01-02 01:15:00 0.497876 4.056503 -4.348021 -0.019043
2000-01-02 01:30:00 0.183521 4.369899 -4.264499 0.725734
2000-01-02 01:45:00 -0.365043 4.257799 -4.003001 -0.197835
2000-01-02 02:00:00 1.389697 4.463931 -4.166211 1.310472
2000-01-02 02:15:00 -0.829049 4.360859 -5.347301 -0.719968
2000-01-02 02:30:00 -0.257339 4.156498 -4.481656 0.804225
2000-01-02 02:45:00 -0.112207 4.238031 -4.277917 -1.851001
2000-01-02 03:00:00 1.024404 4.315122 -4.296867 1.567366
2000-01-02 03:15:00 1.506557 4.440672 -4.429984 -1.569164
2000-01-02 03:30:00 0.292707 4.088439 -3.877321 -0.169247
2000-01-02 03:45:00 -1.838429 4.056206 -4.687052 0.679375
2000-01-02 04:00:00 0.469589 3.651325 -3.386148 0.071214 [Finished in 2.6s]
《利用python进行数据分析》读书笔记--第十章 时间序列(三)的更多相关文章
- 《利用Python 进行数据分析》 - 笔记(4)----json
解决方案: 读写文本格式的数据: pandas 提供了一些用于将表格型数据读取为DataFrame对象的函数 pandas 中的解析函数 函数的选项可以划分为以下几个大类 索引:将一个或多个列当做返回 ...
- 【python】《利用python进行数据分析》笔记
[第三章]ipython C-a 到行首 C-e 到行尾 %timeit 测量语句时间,%time是一次,%timeit是多次. %pdb是自动调试的开关. %debug中,可以用b 12在第12行设 ...
- 《利用Python进行数据分析》笔记---第6章数据加载、存储与文件格式
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第5章pandas入门
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第4章NumPy基础:数组和矢量计算
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--1880-2010年间全美婴儿姓名
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--MovieLens 1M数据集
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--来自bit.ly的1.usa.gov数据
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 利用Python进行数据分析-Pandas(第七部分-时间序列)
时间序列(time series)数据是一种重要的结构化数据形式,应用于多个领域,包括金融学.经济学.生态学.神经科学.物理学等.时间序列数据的意义取决于具体的应用场景,主要有以下几种: 时间戳(ti ...
随机推荐
- Swift游戏实战-跑酷熊猫 11 欢迎进入物理世界
物理模拟是一个奇妙的事情,以此著名的游戏有愤怒的小鸟.我们在这节将会一起来了解如何设置重力,设置物理包围体,碰撞的检测. 要点: 设置物理检测的代理: 让主场景遵循SKPhysicsContactDe ...
- PostgreSQL Replication之第十四章 扩展与BDR
在这一章中,将向您介绍一个全新的技术,成为BDR.双向复制(BDR),在PostgreSQL的世界里,它绝对是一颗冉冉升起的新星.在不久的将来,许多新的东西将会被看到,并且人们可以期待一个蓬勃发展的项 ...
- 转:python webdriver API 之对话框处理
页面上弹出的对话框是自动化测试经常会遇到的一个问题:很多情况下对话框是一个 iframe,如上一节中介绍的例子,处理起来稍微有点麻烦:但现在很多前端框架的对话框是 div 形式的,这就让我们的处理变得 ...
- .NET: WPF Template
Data Template: 要做一个listBox,里面有车子的简单信息,点了里面的item后就会显示详细信息. car class: using System; using System.Coll ...
- 自己使用Fresco时遇到的相关问题
Fresco是facebook推出的一款强大的android图片处理库,github地址:https://github.com/facebook/fresco 里面有官方的使用配置文档,而且是中文的. ...
- kafka监控工具kafkaOffsetMoniter的使用
简介 KafkaOffsetMonitor是由Kafka开源社区提供的一款Web管理界面,用来实时监控Kafka的Consumer以及Partition中的Offset,可以在web界面直观的看到每个 ...
- 转:Order&Shipping Transactions Status Summary
详细内容: http://blog.csdn.net/pan_tian/article/details/7696528 WSH_DELIVERY_DETAILS.Release_Status can ...
- Debian类系统必做——将【你的用户】加入sudoers用户组
切换到root:su root 修改sudoers nano /etc/sudoers 在root ALL=(ALL:ALL) ALL下,加入:liz ALL=(ALL:ALL ...
- JS中数组的操作
1.数组的创建 var arrayObj = new Array(); //创建一个数组 var arrayObj = new Array([size]); //创建一个数组并指定长度,注意不是上限, ...
- javascript和jquery中获取列表的索引
网页中的图片预览一般都需要获取图片列表的索引,或则图片对应的标签的索引,以此达到点击相应的标签获取索引,显示相应的图片 列表有很多种表达的方式,一种是 <ul> <li>苹果& ...