over-fitting、under-fitting 与 regularization
机器学习中一个重要的话题便是模型的泛化能力,泛化能力强的模型才是好模型,对于训练好的模型,若在训练集表现差,不必说在测试集表现同样会很差,这可能是欠拟合导致;若模型在训练集表现非常好,却在测试集上差强人意,则这便是过拟合导致的,过拟合与欠拟合也可以用 Bias 与 Variance 的角度来解释,欠拟合会导致高 Bias ,过拟合会导致高 Variance ,所以模型需要在 Bias 与 Variance 之间做出一个权衡。
过拟合与欠拟合
使用简单的模型去拟合复杂数据时,会导致模型很难拟合数据的真实分布,这时模型便欠拟合了,或者说有很大的 Bias,Bias 即为模型的期望输出与其真实输出之间的差异;有时为了得到比较精确的模型而过度拟合训练数据,或者模型复杂度过高时,可能连训练数据的噪音也拟合了,导致模型在训练集上效果非常好,但泛化性能却很差,这时模型便过拟合了,或者说有很大的 Variance,这时模型在不同训练集上得到的模型波动比较大,Variance 刻画了不同训练集得到的模型的输出与这些模型期望输出的差异。 模型处于过拟合还是欠拟合,可以通过画出误差趋势图来观察。若模型在训练集与测试集上误差均很大,则说明模型的 Bias 很大,此时需要想办法处理 under-fitting ;若是训练误差与测试误差之间有个很大的 Gap ,则说明模型的 Variance 很大,这时需要想办法处理 over-fitting。
模型处于过拟合还是欠拟合,可以通过画出误差趋势图来观察。若模型在训练集与测试集上误差均很大,则说明模型的 Bias 很大,此时需要想办法处理 under-fitting ;若是训练误差与测试误差之间有个很大的 Gap ,则说明模型的 Variance 很大,这时需要想办法处理 over-fitting。

一般在模型效果差的第一个想法是增多数据,其实增多数据并不一定会有更好的结果,因为欠拟合时增多数据往往导致效果更差,而过拟合时增多数据会导致 Gap 的减小,效果不会好太多,多以当模型效果很差时,应该检查模型是否处于欠拟合或者过拟合的状态,而不要一味的增多数据量,关于过拟合与欠拟合,这里给出几个解决方法。
解决欠拟合的方法:
- 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
- 尝试非线性模型,比如核SVM 、决策树、DNN等模型;
- 如果有正则项可以较小正则项参数 $\lambda$.
- Boosting ,Boosting 往往会有较小的 Bias,比如 Gradient Boosting 等.
解决过拟合的方法:
- 交叉检验,通过交叉检验得到较优的模型参数;
- 特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间。
- 正则化,常用的有 $L_1$、$L_2$ 正则。而且 $L_1$ 正则还可以自动进行特征选择。
- 如果有正则项则可以考虑增大正则项参数 $\lambda$.
- 增加训练数据可以有限的避免过拟合.
- Bagging ,将多个弱学习器Bagging 一下效果会好很多,比如随机森林等;
交叉检验
当数据比较少是,留出一部分做交叉检验可能比较奢侈,还有只执行一次训练-测试来评估模型,会带有一些随机性,这些缺点都可以通过交叉检验克服,交叉检验对数据的划分如下:

交叉检验的步骤:
1)将数据分类训练集、验证集、测试集;
2)选择模型和训练参数;
3)使用训练集训练模型,在验证集中评估模型;
4)针对不同的模型,重复2)- 3)的过程;
5)选择最佳模型,使用训练集和验证集一起训练模型;
6)使用测试集来最终测评模型。
关于正则
在模型的损失函数中引入正则项,可用来防止过拟合,于是得到的优化形式如下:
\[\mathbf{w}^*=arg\min_{\mathbf{w}} L(y,f(\mathbf{w},\mathbf{x})) + \lambda \Omega (\mathbf{w})\]
这里 $\Omega(w)$ 即为正则项, $\lambda$ 则为正则项的参数,通常为 $L_p$ 的形式,即:
\[ \Omega(w) = ||w||^p \]
实际应用中比较多的是 $L_1$ 与 $L_2$ 正则,$L_1$ 正则是 $L_0$ 正则的凸近似,这里 $L_0$ 正则即为权重参数 $\mathbf{w}$ 中值为 0 的个数,但是求解 $L_0$ 正则是个NP 难题,所以往往使用 $L_1$ 正则来近似 $L_0$ , 来使得某些特征权重为 0 ,这样便得到了稀疏的的权重参数 $\mathbf{w}$。关于正则为什么可以防止过拟合,给出三种解释:
正则化的直观解释
对于规模庞大的特征集,重要的特征可能并不多,所以需要减少无关特征的影响,减少后的模型也会有更强的可解释性;$L_2$ 正则可以用来减小权重参数的值,当权重参数取值很大时,导致其导数或者说斜率也会很大,斜率偏大会使模型在较小的区间里产生较大的波动。加入$L_2$ 正则后,可使得到的模型更平滑,比如说下图所示曲线拟合,展示了加入$L_2$ 正则与不加 $L_2$ 的区别:
正则化的几何解释
我们常见的正则,是直接加入到损失函数中的形式,其实关于 L1 与 L2 正则,都可以形式化为以下问题:
\begin{aligned}
L_1: \min_{\mathbf{w}} L(y,f(\mathbf{w},\mathbf{x})) \ \ \ \ &s.t. ||\mathbf{w}||_2^2 <C \\
L_2: \min_{\mathbf{w}} L(y,f(\mathbf{w},\mathbf{x})) \ \ \ \ &s.t. ||\mathbf{w}||_1^1 <C \\
\end{aligned}
至于两种形式为什么等价呢,运用一下拉格朗日乘子法就好,这里也即通常说的把 $\mathbf{w}$ 限制在一个ball 里,对于 $l_p –ball $ 的形式如下图所示:

对于 $L_1$ 与 $L_2$ 正则,分别对应$l_1 –ball $ 与 $l_2 –ball $ ,为了方便看,这里给出 $l_1 –ball $ 与 $l_2 –ball $ 在二维空间下的图:\begin{aligned}
l_1-ball:& \ |\mathbf{w}_1|+|\mathbf{w}_2| <C \\
l_2-ball:& \ \mathbf{w}_1^2+\mathbf{w}_2^2 <C
\end{aligned}下图中的等高线即为模型的损失函数,上式中的两个约束条件则变成了一个半径为 $C$ 的 norm-ball 的形式,等高线与 norm-ball 相交的地方即为最优解:

可以看到,$l_1-ball$ 和每个坐标轴相交的地方都有“角”出现,而目标函数除非位置非常好,大部分时候都会在角的地方相交。注意到在角的位置即导致某个维度为 0 ,这时会导致模型参数的稀疏,这个结论可自然而然的推广到高维的情形;相比之下,$l_2-ball$ 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。
正则化的贝叶斯解释
正则化的另一种解释来自贝叶斯学派,在这里可以考虑使用极大似然估计 MLE 的方式来当做损失函数,对于 MLE 中的参数 $\mathbf{w}$ ,为其引入参数为 $\alpha$ 的先验,然后极大化 likelihood $\times$ prior,便得到了 MLE 的后验估计 MAP 的形式:
\begin{aligned}
MLE: &L(w) = p(y|x, w) \\
MAP: &L(w) = p(y|x , w)p( w|\alpha)
\end{aligned}
对于 $L_2$ 正则,是引入了一个服从高斯分布的先验,而对于 $L_1$ 正则,是引入一个拉普拉斯分布的先验,两个分布分别如下:
\begin{aligned}
Gussian : &p(x,\mu,\sigma) = \frac{1}{\sqrt{2\pi}\sigma}exp\left (-\frac{(x-\mu)^2}{2\sigma^2} \right ) \\
Laplace: &p(x,\mu,b) = \frac{1}{2b }exp\left (-\frac{|x-\mu|}{b} \right )
\end{aligned}
两种分布的概率密度的图形如下所示:
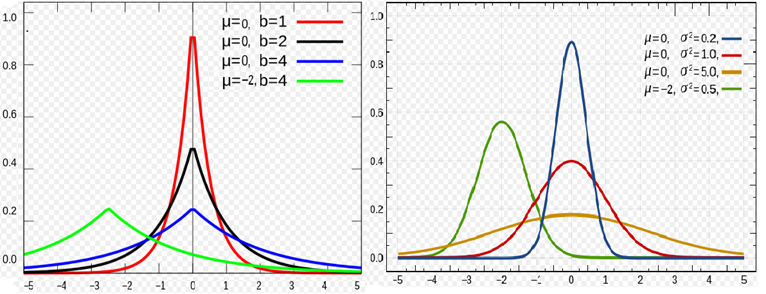
下面为参数 $\mathbf{w}$ 引入一个高斯先验,即 $\mathbf{w} \sim \mathcal{N}(0, \alpha^{-1} I) $:
\[p(\mathbf{w}|\alpha) = \mathcal{N}(\mathbf{w}|0, \alpha^{-1}\mathbf{I}) = \left (\frac{\alpha}{2 \pi} \right )^{n/2}\exp(-\frac{\alpha}{2}\mathbf{w}^T\mathbf{w})\]
这里的 $n$ 即为参数 $\mathbf{w}$ 的维度,所以得到其 MAP 形式为:
\begin{align*}
L(\vec w) & = p(\vec{y}|X;w)p(\vec w)\\
& = \prod_{i=1}^{m} p(y^{(i)}|\mathbf{x}^{(i)}; \mathbf{w})p( \mathbf{w} | \mathbf{0} ,a ^{-1}\mathbf{I})\\
& = \underbrace{\prod_{i=1}^{m} \frac{1}{\sqrt{2\pi}\delta}\exp\left( -\frac{(y^{(i)} - \mathbf{w}^T\mathbf{x}^{(i)})^2}{2\delta^2} \right)}_{\mathbf{likelihood}} \underbrace{ \frac{\alpha}{2\pi}^{n/2} \exp\left( -\frac{ \mathbf{w}^T \mathbf{w}}{2\alpha} \right)}_{\mathbf{prior}}
\end{align*}
其 $\log$ 似然的形式为:
\begin{align*}
\log L(w) & = m \log \frac{1}{\sqrt{2\pi}\delta}+ \frac{n}{2} \log \frac{a}{2\pi} - \frac{1}{\delta^2}\cdot \frac{1}{2} \sum_{i=1}^{m} (y^{(i)} - \mathbf{w}^T\mathbf{x}^{(i)})^2 - \frac{1}{\alpha}\cdot \frac{1}{2} \mathbf{w}^T\mathbf{w}\\
\Rightarrow & \mathbf{w_{MAP}} = \arg \underset{\mathbf{w}}{\min} \left( \frac{1}{\delta^2}\cdot \frac{1}{2} \sum_{i=1}^{m} (y^{(i)} - \mathbf{w}^T\mathbf{x}^{(i)})^2 + \frac{1}{\alpha}\cdot \frac{1}{2} \mathbf{w}^T\mathbf{w} \right) \end{align*}
这便等价于常见的 MAP 形式:
\[J(\mathbf{w}) = \frac{1}{N} \sum_i(y^{(i)} - \mathbf{w}^T\mathbf{x}^{(i)})^2 + \lambda ||\mathbf{w}||_2\]
同理可以得到引入拉普拉斯的先验的形式便为 $L_1$ 正则.具体的计算可见参考文献$^8$。
L1 产生稀疏解的数学解释
对于样本集合 $\left \{ (\mathbf{x}_{i},y_{i}) \right \}_{i=1}^n $, 其中 $x_i \in \mathbb{R} ^p$ ,换成矩阵的表示方法:
\[X \cdot \mathbf{w}= \mathbf{y}\]
上式的含义即为求解参数 $\mathbf{w}$ ,当 $p>n$ 时即数据量非常少,特征非常多的情况下,会导致求解不唯一性,加上 $L_1$ 约束项可以得到一个确定的解,同时也导致了稀疏性的产生, $L_1$ 正则的形式如下:
\[L(\mathbf{w}) = f(\mathbf{w}) + \lambda ||\mathbf{w}||_1 \]
这里损失函数采用了均方误差损失,即:
\[f(\mathbf{w}) =||X \cdot \mathbf{w}- \mathbf{y}||^2\]
有唯一解的 $L_1$ 正则是一个凸优化问题,但是有一点,是不光滑的凸优化问题,因为在尖点处的导数是不存在的,因此需要一个 subgradient 的概念:
对于在 $p$ 维欧式空间中的凸开子集 $U$ 上定义任意的实值函数 $f: U \rightarrow \mathbb{R}$ , 函数 $f$ 在点 $w_0 \in U$ 处的 subgradient 满足:
\[f(\mathbf{w}) – f(\mathbf{w}_0) \ge g \cdot (\mathbf{w} – \mathbf{w}_0)\]
$g$ 构成的集合即为再点 $\mathbf{w}_0$ 处的 subgradient 集合,如下图右的蓝色线所示:

比如说对于一维情况,$f(w) = |w|$ ,该函数在 0 点不可导,用 subgradient 可以将其导数表示为:
\[f'(w) =\left \{ \begin{aligned}
\left \{ 1 \right \},\ \ \ \ \ &if \ w > 0\\
[-1,1], \ \ &if \ w = 0\\
\left \{ -1 \right \}, \ \ \ &if \ w < 0
\end{aligned}\right .\]
接下来对损失函数求导即可:
\begin{aligned}
&\nabla_{w_j}L(\mathbf{w}) = a_jw_j - c_j + \lambda \cdot \mathrm{sign}(w_j) \\
\\
&\mathbf{where}: \\
& \ \ \ \ \ \ \ \ \ \ \ a_j = 2 \sum_{i=1}^nx_{ij}^2 \\
& \ \ \ \ \ \ \ \ \ \ \ c_j = 2 \sum_{i=1}^nx_{ij}(y_i - w_{\neg j}^T x_{i \neg j})
\end{aligned}
因为 $L_1$ 正则的形式是根据拉格朗日乘子法得到的,拉格朗日法则需要满足 KKT 条件,即 $\nabla_{w_j}L(w) = 0$ ,因此另导数得 0 ,并且使用 subgradient 的概念,可以得到 $w_j$ 在尖点的导数取值范围:
\[\nabla_{w_j}L(\mathbf{w}) = a_jw_j - c_j + \lambda \cdot \mathrm{sign}(w_j) = 0 \]
利用 可得如下的形式:
\[a_j w_j- c_j \in \left \{ \begin{aligned}
\left \{ \lambda \right \}, \ if \ w_j < 0 \\
\left [-\lambda, \lambda \right ], \ if \ w_j = 0 \\
\left \{ -\lambda \right \}, \ if \ w_j > 0
\end{aligned} \right .\]
分几下几种情况:
1) 若 $c_j < -\lambda$ ,则 $c_j$ 与残差负相关,这时的 subgradient 为 0即: $\hat{w}_j = \frac{c_j + \lambda}{a_j} < 0$
2) 若 $c_j \in [-\lambda ,+ \lambda]$,此时与残差弱相关,且得到的 $\hat{w}_j = 0$
3) 若 $c_j > \lambda$, 此时 $c_j$ 与残差正相关, 且有$\hat{w}_j = \frac{c_j – \lambda}{a_j} > 0$
综上可得:
\[\hat{w}_j = \left \{ \begin{aligned}
(c_j+ \lambda)/a_j, \ \ &if \ c_j < - \lambda \\
0 \ \ \ \ \ \ \ , \ \ &if \ c_j \in[- \lambda,\lambda] \\
(c_j- \lambda)/a_j, \ \ &if \ c_j > \lambda
\end{aligned} \right .\]
可见 $c_j$ 的取值正是导致稀疏性的由来,下图可以见到 $c_j$ 与 $w_j$ 的关系:

参考文献:
1.http://www.cnblogs.com/ooon/p/5522957.html
2.http://breezedeus.github.io/2014/11/15/breezedeus-feature-processing.html 特征组合
3.http://docs.aws.amazon.com/machine-learning/latest/dg/model-fit-underfitting-vs-overfitting.html
4.http://blog.csdn.net/vividonly/article/details/50723852
5.https://www.quora.com/What-is-the-difference-between-L1-and-L2-regularization Quora 上的回答
6.http://freemind.pluskid.org/machine-learning/sparsity-and-some-basics-of-l1-regularization/
7.http://blog.csdn.net/zouxy09/article/details/24971995/
8.http://charlesx.top/2016/03/Regularized-Regression/ 正则化的 贝叶斯解释,另附详细的 MAP 计算
9.PRML MLAPP(P432,P433)
10.http://blog.csdn.net/myprograminglife/article/details/43015835 对 mlapp 的翻译
11.http://www.di.ens.fr/~fbach/mlss08_fbach.pdf very nice ppt
over-fitting、under-fitting 与 regularization的更多相关文章
- 过拟合和欠拟合(Over fitting & Under fitting)
欠拟合(Under Fitting) 欠拟合指的是模型没有很好地学习到训练集上的规律. 欠拟合的表现形式: 当模型处于欠拟合状态时,其在训练集和验证集上的误差都很大: 当模型处于欠拟合状态时,根本的办 ...
- [matlab工具箱] 曲线拟合Curve Fitting
——转载网络 我的matlab版本是 2016a 首先,工具箱如何打开呢? 在 apps 这个菜单项中,可以找到很多很多的应用,点击就可以打开具体的工具窗口 本文介绍的工具有以下这些: curve F ...
- machine learning(13) -- solving the problem of overfitting:regularization
solving the problem of overfitting:regularization 发生的在linear regression上面的overfitting问题 发生在logistic ...
- A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python)
A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python) MACHINE LEARNING PYTHON ...
- 深度学习笔记(十二)车道线检测 LaneNet
论文:Towards End-to-End Lane Detection: an Instance Segmentation Approach 代码:https://github.com/MaybeS ...
- (4)opencv在android平台上实现 物体跟踪
最近项目时间很紧,抓紧时间集中精力去研究android平台的opencv里的物体跟踪技术 其他几篇文章有时间再去完善吧 从网上找到了一些实例代码,我想采取的学习方法是研究实例代码和看教程相结合,教程是 ...
- OpenCV 编程简单介绍(矩阵/图像/视频的基本读写操作)
PS. 因为csdn博客文章长度有限制,本文有部分内容被截掉了.在OpenCV中文站点的wiki上有可读性更好.而且是完整的版本号,欢迎浏览. OpenCV Wiki :<OpenCV 编程简单 ...
- Git命令以及常见注意事项
命令: git init -> 初始化一个git仓库 git clone -> 克隆一个本地库 git pull -> 拉取服务器最新代码 git fetch –p -> 强行 ...
- 读书笔记 Bioinformatics Algorithms Chapter5
Chapter5 HOW DO WE COMPARE DNA SEQUENCES Bioinformatics Algorithms-An_Active Learning Approach htt ...
- 训练集,验证集,测试集(以及为什么要使用验证集?)(Training Set, Validation Set, Test Set)
对于训练集,验证集,测试集的概念,很多人都搞不清楚.网上的文章也是鱼龙混杂,因此,现在来把这方面的知识梳理一遍.让我们先来看一下模型验证(评估)的几种方式. 在机器学习中,当我们把模型训练出来以后,该 ...
随机推荐
- HDU 1796 How many integers can you find (状态压缩 + 容斥原理)
题目链接 题意 : 给你N,然后再给M个数,让你找小于N的并且能够整除M里的任意一个数的数有多少,0不算. 思路 :用了容斥原理 : ans = sum{ 整除一个的数 } - sum{ 整除两个的数 ...
- HDU4003 Find Metal Mineral 树形DP
Find Metal Mineral Problem Description Humans have discovered a kind of new metal mineral on Mars wh ...
- lintcode:买卖股票的最佳时机 IV
买卖股票的最佳时机 IV 假设你有一个数组,它的第i个元素是一支给定的股票在第i天的价格. 设计一个算法来找到最大的利润.你最多可以完成 k 笔交易. 注意事项 你不可以同时参与多笔交易(你必须在再次 ...
- JLink 软件复位、Halt及运行小工具
调试硬件时常常需要复位目标芯片,每次断电上电太麻烦,又不喜欢总打开segger的命令行,于是就搞了这个小工具: QT绿色软件,解压即可运行,打开JLinkRST.exe,点击Connect即可通过 ...
- 关于模态/非模态对话框不响应菜单的UPDATE_COMMAND_UI消息(对对WM_INITMENUPOPUP消息的处理)
对于模态非模态对话框默认是不响应菜单的UPDATE_COMMAND_UI消息的,需要增加对WM_INITMENUPOPUP消息的处理以后,才可以响应UPDATE_COMMAND_UI. void CX ...
- 284. Peeking Iterator
题目: Given an Iterator class interface with methods: next() and hasNext(), design and implement a Pee ...
- Centos挂载windows共享文件夹
1.windows7共享一个文件夹(1)新建一个用户:devin,密码:admin123(2)在E盘新建一个文件夹,share,并设置共享 对用户devin共享,并让其权限为:读取和写入. 2.lin ...
- Android 禁止进入activity自动弹出键盘
在Manifest.xml中设定activity的属性 android:windowSoftInputMode="stateHidden|stateUnchanged" 附相关属性 ...
- C# 设计基础(一)
(一) C#项目的组成结构 项目结构 .config ---配置文件(存放配置参数文件) .csproj ---项目文件(管理文件项) .sln ---解决方案文件(管理项目) .cs - ...
- 截取usb数据包,控制usb设备----Relay设备
在项目开发当中,我们需要一个usb转继电器的设备当开关控制无线发射设备,采购部采购时并未详细了解Relay设备的运行环境就买了一批设备,之后发现设备厂家只提供了windows库,而我们是要在linux ...