Spark 1.6.1分布式集群环境搭建
一、软件准备
scala-2.11.8.tgz
spark-1.6.1-bin-hadoop2.6.tgz
二、Scala 安装
1、master 机器
(1)下载 scala-2.11.8.tgz, 解压到 /opt 目录下,即: /opt/scala-2.11.8。
(2)修改 scala-2.11.8 目录所属用户和用户组。
|
1
|
sudo chown -R hadoop:hadoop scala-2.11.8 |
(3)修改环境变量文件 .bashrc , 添加以下内容。
|
1
2
3
|
# Scala Envexport SCALA_HOME=/opt/scala-2.11.8export PATH=$PATH:$SCALA_HOME/bin |
运行 source .bashrc 使环境变量生效。
(4) 验证 Scala 安装

2、Slave机器
slave01 和 slave02 参照 master 机器安装步骤进行安装。
三、Spark 安装
1、master 机器
(1) 下载 spark-1.6.1-bin-hadoop2.6.tgz,解压到 /opt 目录下。
(2) 修改 spark-1.6.1-bin-hadoop2.6 目录所属用户和用户组。
|
1
|
sudo chown -R hadoop:hadoop spark-1.6.1-bin-hadoop2.6 |
(3) 修改环境变量文件 .bashrc , 添加以下内容。
|
1
2
3
|
# Spark Envexport SPARK_HOME=/opt/spark-1.6.1-bin-hadoop2.6export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin |
运行 source .bashrc 使环境变量生效。
(4) Spark 配置
进入 Spark 安装目录下的 conf 目录, 拷贝 spark-env.sh.template 到 spark-env.sh。
|
1
|
cp spark-env.sh.template spark-env.sh |
编辑 spark-env.sh,在其中添加以下配置信息:
|
1
2
3
4
5
|
export SCALA_HOME=/opt/scala-2.11.8export JAVA_HOME=/opt/java/jdk1.7.0_80export SPARK_MASTER_IP=192.168.109.137export SPARK_WORKER_MEMORY=1gexport HADOOP_CONF_DIR=/opt/hadoop-2.6.4/etc/hadoop |
JAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录。
将 slaves.template 拷贝到 slaves, 编辑其内容为:
|
1
2
3
|
masterslave01slave02 |
即 master 既是 Master 节点又是 Worker 节点。
2、slave机器
slave01 和 slave02 参照 master 机器安装步骤进行安装。
四、启动 Spark 集群
1、启动 Hadoop 集群
Hadoop 集群的启动可以参见之前的一篇文章 Hadoop 2.6.4分布式集群环境搭建,这里不再赘述。启动之后,可以分别在 master、slave01、slave02 上使用 jps 命令查看进程信息。



2、启动 Spark 集群
(1) 启动 Master 节点
运行 start-master.sh,结果如下:

可以看到 master 上多了一个新进程 Master。
(2) 启动所有 Worker 节点
运行 start-slaves.sh, 运行结果如下:

在 master、slave01 和 slave02 上使用 jps 命令,可以发现都启动了一个 Worker 进程


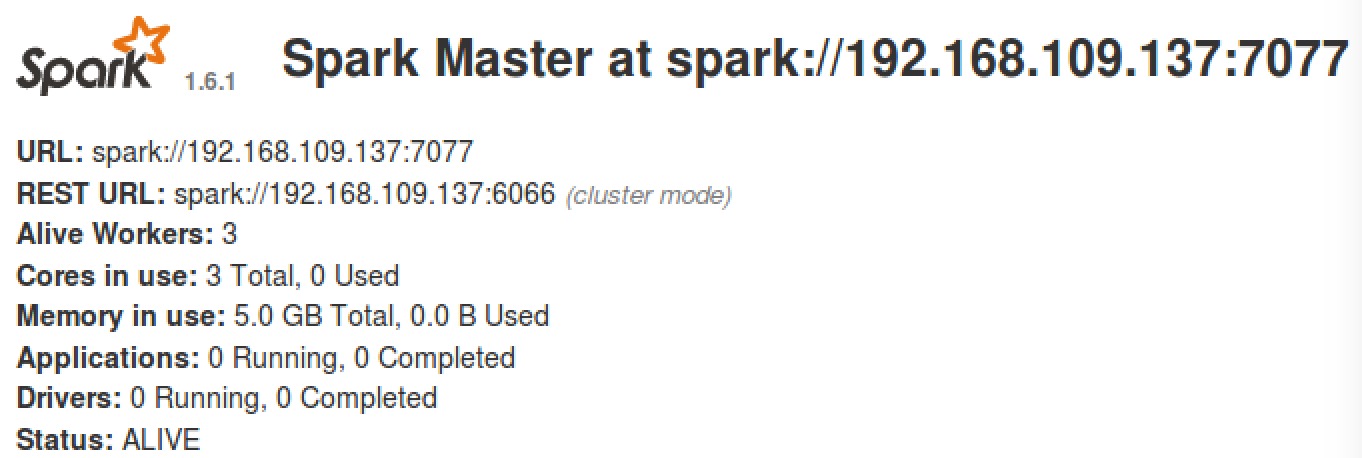
(3) 浏览器查看 Spark 集群信息。
访问:http://master:8080, 如下图:

(4) 使用 spark-shell
运行 spark-shell,可以进入 Spark 的 shell 控制台,如下:

(5) 浏览器访问 SparkUI
访问 http://master:4040, 如下图:

可以从 SparkUI 上查看一些 如环境变量、Job、Executor等信息。
至此,整个 Spark 分布式集群的搭建就到这里结束。
五、停止 Spark 集群
1、停止 Master 节点
运行 stop-master.sh 来停止 Master 节点。

使用 jps 命令查看当前 java 进程
可以发现 Master 进程已经停止。
2、停止 Worker 节点
运行 stop-slaves.sh 可以停止所有的 Worker 节点

使用 jps 命令查看 master、slave01、slave02 上的进程信息:
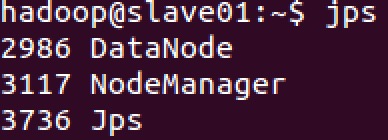
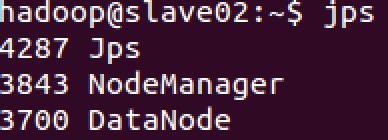
可以看到, Worker 进程均已停止,最后再停止 Hadoop 集群。
六、遗留问题
设置的 SCALA_HOME 没有生效,Spark 启动时用的是自带的 Scala 2.10.5 版本。
Spark 1.6.1分布式集群环境搭建的更多相关文章
- Spark 2.2.0 分布式集群环境搭建
集群机器: 1台 装了 ubuntu 14.04的 台式机 1台 装了ubuntu 16.04 的 笔记本 (机器更多时同样适用) 1.需要安装好Hadoop分布式环境 参照:Hadoop分类 ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- Kafka 完全分布式集群环境搭建
思路: 先在主机s1上安装配置,然后远程复制到其它两台主机s2.s3上, 并分别修改配置文件server.properties中的broker.id属性. 1. 搭建前准备 示例共三台主机,主机IP映 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
一.环境说明 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下: Hostname IP ...
- zookeeper伪分布式集群环境搭建
step1.下载 下载地址:http://zookeeper.apache.org/releases.html 将下载的压缩包放到用户家目录下(其他目录也可以) step2.解压 $tar –zxvf ...
随机推荐
- Careercup - Microsoft面试题 - 5204967652589568
2014-05-11 23:57 题目链接 原题: identical balls. one ball measurements ........ dead easy. 题目:9个看起来一样的球,其中 ...
- Netsharp快速入门(之1) 介绍及需求说明
作者:秋时 杨昶 时间:2014-02-15 转载须说明出处 第一章 快速入门介绍 Netsharp是一个企业基础业务管理平台,介绍Netsharp分三个系列,分别是: 1. N ...
- [poj 1741]Tree 点分治
题意 求树上距离不超过k的点对数,边权<=1000 题解 点分治. 点分治的思想就是取一个树的重心,这种路径只有两种情况,就是经过和不经过这个重心,如果不经过重心就把树剖开递归处 ...
- TGL 月光精品教程整理
月光站群培训班目录(不定时更新中) wordpress快速配置,插件,模板知识汇总(不定期更新) 适合国人的英文站思维(1) 英语思维-送给正在苦于学英语的童鞋 做seo的重要心态 seo排名难易度分 ...
- PHP:汉字转拼音类(全拼与首字母)
[php] <?php class GetPingYing { private $pylist = array( 'a'=>-20319,'ai'=>-20317,'an'=> ...
- 系统使用 aspose.cell , 使得ashx第一次访问会变很慢
网站放在IIS后, 在网站第一次访问后. 回收应用程序池 第一次访问aspx页面还是比较快. 但第一次访问ashx会很慢. 后发现原因: aspose.cell的5.3...版本. 的原 ...
- WinHex分析PE格式(1)
最近在一直努力学习破解,但是发现我的基础太差了,就想学习一下PE结构.可是PE结构里的结构关系太复杂,看这老罗的WiN32汇编最后一章 翻两页又合上了..把自己的信心都搞没了.感觉自己的理解能力不行, ...
- delphi的socket通讯 多个客户端 (转)
ClientSocket组件为客户端组件.它是通信的请求方,也就是说,它是主动地与服务器端建立连接. ServerSocket组件为服务器端组件.它是通信的响应方,也就是说,它的动作是监听以及被动接受 ...
- poj 3903 Stock Exchange(最长上升子序列,模版题)
题目 #include<stdio.h> //最长上升子序列 nlogn //入口参数:数组名+数组长度,类型不限,结构体类型可以通过重载运算符实现 //数组下标从1号开始. int bs ...
- Android Source Code
一. Android 框架 http://elinux.org/Master-android Android框架层级 : Android 自下 而 上 分为 4层; -- Linux内核层; -- 各 ...