计算机程序的思维逻辑 (40) - 剖析HashMap
本系列文章经补充和完善,已修订整理成书《Java编程的逻辑》,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http://item.jd.com/12299018.html

前面两节介绍了ArrayList和LinkedList,它们的一个共同特点是,查找元素的效率都比较低,都需要逐个进行比较,本节介绍HashMap,它的查找效率则要高的多,HashMap是什么?怎么用?是如何实现的?本节详细介绍。
字面上看,HashMap由两个单词组成,Hash和Map,这里Map不是地图的意思,而是表示映射关系,是一个接口,实现Map接口有多种方式,HashMap实现的方式利用了Hash。
下面,我们先来看Map接口,接着看如何使用HashMap,然后看实现原理,最后我们总结分析HashMap的特点。
Map接口
基本概念
Map有键和值的概念,一个键映射到一个值,Map按照键存储和访问值,键不能重复,即一个键只会存储一份,给同一个键重复设值会覆盖原来的值。使用Map可以方便地处理需要根据键访问对象的场景,比如:
- 一个词典应用,键可以为单词,值可以为单词信息类,包括含义、发音、例句等。
- 统计和记录一本书中所有单词出现的次数,可以以单词为键,出现次数为值。
- 管理配置文件中的配置项,配置项是典型的键值对。
- 根据身份证号查询人员信息,身份证号为键,人员信息为值。
数组、ArrayList、LinkedList可以视为一种特殊的Map,键为索引,值为对象。
接口定义
Map接口的定义为:
- public interface Map<K,V> {
- V put(K key, V value);
- V get(Object key);
- V remove(Object key);
- int size();
- boolean isEmpty();
- boolean containsKey(Object key);
- boolean containsValue(Object value);
- void putAll(Map<? extends K, ? extends V> m);
- void clear();
- Set<K> keySet();
- Collection<V> values();
- Set<Map.Entry<K, V>> entrySet();
- interface Entry<K,V> {
- K getKey();
- V getValue();
- V setValue(V value);
- boolean equals(Object o);
- int hashCode();
- }
- boolean equals(Object o);
- int hashCode();
- }
Map接口有两个类型参数,K和V,分别表示键(Key)和值(Value)的类型,我们解释一下其中的方法。
保存键值对
- V put(K key, V value);
按键key保存值value,如果Map中原来已经存在key,则覆盖对应的值,返回值为原来的值,如果原来不存在key,返回null。key相同的依据是,要么都为null,要么equals方法返回true。
根据键获取值
- V get(Object key);
如果没找到,返回null。
根据键删除键值对
- V remove(Object key);
返回key原来对应的值,如果Map中不存在key,返回null。
查看Map的大小
- int size();
- boolean isEmpty();
查看是否包含某个键
- boolean containsKey(Object key);
查看是否包含某个值
- boolean containsValue(Object value);
批量保存
- void putAll(Map<? extends K, ? extends V> m);
保存参数m中的所有键值对到当前Map。
清空Map中所有键值对
- void clear();
获取Map中键的集合
- Set<K> keySet();
Set是一个接口,表示的是数学中的集合概念,即没有重复的元素集合,它的定义为:
- public interface Set<E> extends Collection<E> {
- }
它扩展了Collection,但没有定义任何新的方法,不过,它要求所有实现者都必须确保Set的语义约束,即不能有重复元素。关于Set,下节我们再详细介绍。
Map中的键是没有重复的,所以ketSet()返回了一个Set。
获取Map中所有值的集合
- Collection<V> values();
获取Map中的所有键值对
- Set<Map.Entry<K, V>> entrySet();
Map.Entry<K,V>是一个嵌套接口,定义在Map接口内部,表示一条键值对,主要方法有:
- K getey();
- V getValue();
keySet()/values()/entrySet()有一个共同的特点,它们返回的都是视图,不是拷贝的值,基于返回值的修改会直接修改Map自身,比如说:
- map.keySet().clear();
会删除所有键值对。
HashMap
使用例子
HashMap实现了Map接口,我们通过一个简单的例子,来看如何使用。
在随机一节,我们介绍过如何产生随机数,现在,我们写一个程序,来看随机产生的数是否均匀,比如,随机产生1000个0到3的数,统计每个数的次数。代码可以这么写:
- Random rnd = new Random();
- Map<Integer, Integer> countMap = new HashMap<>();
- for(int i=0; i<1000; i++){
- int num = rnd.nextInt(4);
- Integer count = countMap.get(num);
- if(count==null){
- countMap.put(num, 1);
- }else{
- countMap.put(num, count+1);
- }
- }
- for(Map.Entry<Integer, Integer> kv : countMap.entrySet()){
- System.out.println(kv.getKey()+","+kv.getValue());
- }
一次运行的输出为:
- 0,269
- 1,236
- 2,261
- 3,234
代码比较简单,就不解释了。
构造方法
除了默认构造方法,HashMap还有如下构造方法:
- public HashMap(int initialCapacity)
- public HashMap(int initialCapacity, float loadFactor)
- public HashMap(Map<? extends K, ? extends V> m)
最后一个以一个已有的Map构造,拷贝其中的所有键值对到当前Map,这容易理解。前两个涉及两个两个参数initialCapacity和loadFactor,它们是什么意思呢?我们需要看下HashMap的实现原理。
实现原理
内部组成
HashMap内部有如下几个主要的实例变量:
- transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
- transient int size;
- int threshold;
- final float loadFactor;
size表示实际键值对的个数。
table是一个Entry类型的数组,其中的每个元素指向一个单向链表,链表中的每个节点表示一个键值对,Entry是一个内部类,它的实例变量和构造方法代码如下:
- static class Entry<K,V> implements Map.Entry<K,V> {
- final K key;
- V value;
- Entry<K,V> next;
- int hash;
- Entry(int h, K k, V v, Entry<K,V> n) {
- value = v;
- next = n;
- key = k;
- hash = h;
- }
- }
其中key和value分别表示键和值,next指向下一个Entry节点,hash是key的哈希值,待会我们会介绍其计算方法,直接存储hash值是为了在比较的时候加快计算,待会我们看代码。
table的初始值为EMPTY_TABLE,是一个空表,具体定义为:
- static final Entry<?,?>[] EMPTY_TABLE = {};
当添加键值对后,table就不是空表了,它会随着键值对的添加进行扩展,扩展的策略类似于ArrayList,添加第一个元素时,默认分配的大小为16,不过,并不是size大于16时再进行扩展,下次什么时候扩展与threshold有关。
threshold表示阈值,当键值对个数size大于等于threshold时考虑进行扩展。threshold是怎么算出来的呢?一般而言,threshold等于table.length乘以loadFactor,比如,如果table.length为16,loadFactor为0.75,则threshold为12。
loadFactor是负载因子,表示整体上table被占用的程度,是一个浮点数,默认为0.75,可以通过构造方法进行修改。
下面,我们通过一些主要方法的代码来看下,HashMap是如何利用这些内部数据实现Map接口的。先看默认构造方法。需要说明的是,为清晰和简单起见,我们可能会忽略一些非主要代码。
默认构造方法
代码为:
- public HashMap() {
- this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
- }
DEFAULT_INITIAL_CAPACITY为16,DEFAULT_LOAD_FACTOR为0.75,默认构造方法调用的构造方法主要代码为:
- public HashMap(int initialCapacity, float loadFactor) {
- this.loadFactor = loadFactor;
- threshold = initialCapacity;
- }
主要就是设置loadFactor和threshold的初始值。
保存键值对
下面,我们来看HashMap是如何把一个键值对保存起来的,代码为:
- public V put(K key, V value) {
- if (table == EMPTY_TABLE) {
- inflateTable(threshold);
- }
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key);
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- addEntry(hash, key, value, i);
- return null;
- }
如果是第一次保存,首先会调用inflateTable()方法给table分配实际的空间,inflateTable的主要代码为:
- private void inflateTable(int toSize) {
- // Find a power of 2 >= toSize
- int capacity = roundUpToPowerOf2(toSize);
- threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
- table = new Entry[capacity];
- }
默认情况下,capacity的值为16,threshold会变为12,table会分配一个长度为16的Entry数组。
接下来,检查key是否为null,如果是,调用putForNullKey单独处理,我们暂时忽略这种情况。
在key不为null的情况下,下一步调用hash方法计算key的哈希值,hash方法的代码为:
- final int hash(Object k) {
- int h = 0
- h ^= k.hashCode();
- h ^= (h >>> 20) ^ (h >>> 12);
- return h ^ (h >>> 7) ^ (h >>> 4);
- }
基于key自身的hashCode方法的返回值,又进行了一些位运算,目的是为了随机和均匀性。
有了hash值之后,调用indexFor方法,计算应该将这个键值对放到table的哪个位置,代码为:
- static int indexFor(int h, int length) {
- return h & (length-1);
- }
HashMap中,length为2的幂次方,h&(length-1)等同于求模运算:h%length。
找到了保存位置i,table[i]指向一个单向链表,接下来,就是在这个链表中逐个查找是否已经有这个键了,遍历代码为:
- for (Entry<K,V> e = table[i]; e != null; e = e.next)
而比较的时候,是先比较hash值,hash相同的时候,再使用equals方法进行比较,代码为:
- if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
为什么要先比较hash呢?因为hash是整数,比较的性能一般要比equals比较高很多,hash不同,就没有必要调用equals方法了,这样整体上可以提高比较性能。
如果能找到,直接修改Entry中的value即可。
modCount++的含义与ArrayList和LinkedList中介绍一样,记录修改次数,方便在迭代中检测结构性变化。
如果没找到,则调用addEntry方法在给定的位置添加一条,代码为:
- void addEntry(int hash, K key, V value, int bucketIndex) {
- if ((size >= threshold) && (null != table[bucketIndex])) {
- resize(2 * table.length);
- hash = (null != key) ? hash(key) : 0;
- bucketIndex = indexFor(hash, table.length);
- }
- createEntry(hash, key, value, bucketIndex);
- }
如果空间是够的,不需要resize,则调用createEntry添加,createEntry的代码为:
- void createEntry(int hash, K key, V value, int bucketIndex) {
- Entry<K,V> e = table[bucketIndex];
- table[bucketIndex] = new Entry<>(hash, key, value, e);
- size++;
- }
代码比较直接,新建一个Entry对象,并插入单向链表的头部,并增加size。
如果空间不够,即size已经要超过阈值threshold了,并且对应的table位置已经插入过对象了,具体检查代码为:
- if ((size >= threshold) && (null != table[bucketIndex]))
则调用resize方法对table进行扩展,扩展策略是乘2,resize的主要代码为:
- void resize(int newCapacity) {
- Entry[] oldTable = table;
- int oldCapacity = oldTable.length;
- Entry[] newTable = new Entry[newCapacity];
- transfer(newTable, initHashSeedAsNeeded(newCapacity));
- table = newTable;
- threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
- }
分配一个容量为原来两倍的Entry数组,调用transfer方法将原来的键值对移植过来,然后更新内部的table变量,以及threshold的值。transfer方法的代码为:
- void transfer(Entry[] newTable, boolean rehash) {
- int newCapacity = newTable.length;
- for (Entry<K,V> e : table) {
- while(null != e) {
- Entry<K,V> next = e.next;
- if (rehash) {
- e.hash = null == e.key ? 0 : hash(e.key);
- }
- int i = indexFor(e.hash, newCapacity);
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- }
- }
- }
参数rehash一般为false。这段代码遍历原来的每个键值对,计算新位置,并保存到新位置,具体代码比较直接,就不解释了。
以上,就是保存键值对的主要代码,简单总结一下,基本步骤为:
- 计算键的哈希值
- 根据哈希值得到保存位置(取模)
- 插到对应位置的链表头部或更新已有值
- 根据需要扩展table大小
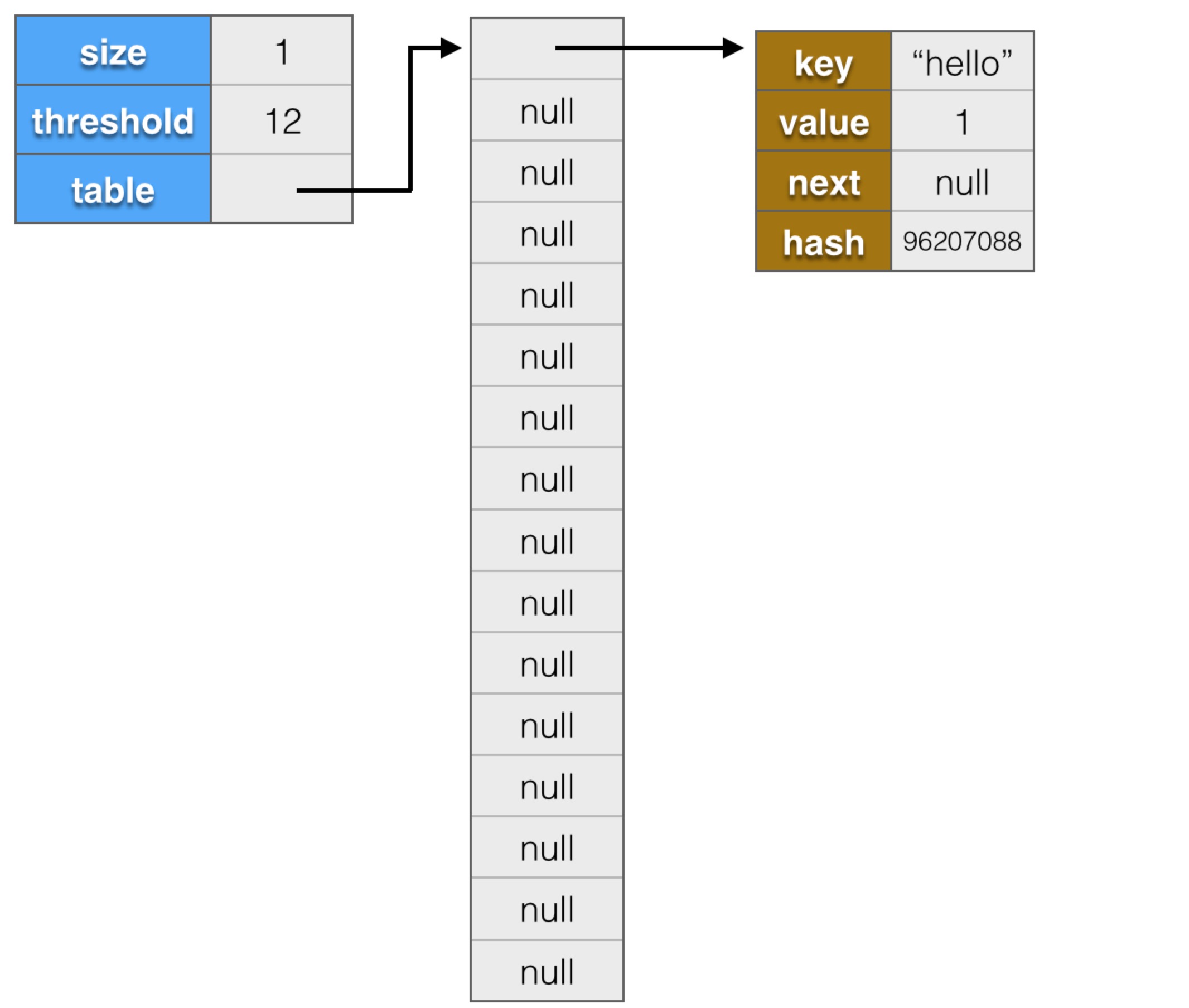
以上描述可能比较抽象,我们通过一个例子,用图示的方式,再来看下,代码是:
- Map<String,Integer> countMap = new HashMap<>();
- countMap.put("hello", 1);
- countMap.put("world", 3);
- countMap.put("position", 4);
在通过new HashMap()创建一个对象后,内存中的图示结构大概是:

接下来执行
- countMap.put("hello", 1);
"hello"的hash值为96207088,模16的结果为0,所以插入table[0]指向的链表头部,内存结构会变为:
"world"的hash值为111207038,模16结果为15,所以保存完"world"后,内存结构会变为:

"position"的hash值为771782464,模16结果也为0,table[0]已经有节点了,新节点会插到链表头部,内存结构会变为:

理解了键值对在内存是如何存放的,就比较容易理解其他方法了,我们来看get方法。
根据键获取值
代码为:
- public V get(Object key) {
- if (key == null)
- return getForNullKey();
- Entry<K,V> entry = getEntry(key);
- return null == entry ? null : entry.getValue();
- }
HashMap支持key为null,key为null的时候,放在table[0],调用getForNullKey()获取值,如果key不为null,则调用getEntry()获取键值对节点entry,然后调用节点的getValue()方法获取值。getEntry方法的代码是:
- final Entry<K,V> getEntry(Object key) {
- if (size == 0) {
- return null;
- }
- int hash = (key == null) ? 0 : hash(key);
- for (Entry<K,V> e = table[indexFor(hash, table.length)];
- e != null;
- e = e.next) {
- Object k;
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- return e;
- }
- return null;
- }
逻辑也比较简单:
1. 计算键的hash值,代码为:
- int hash = (key == null) ? 0 : hash(key);
2. 根据hash找到table中的对应链表,代码为:
- table[indexFor(hash, table.length)];
3. 在链表中遍历查找,遍历代码:
- for (Entry<K,V> e = table[indexFor(hash, table.length)];
- e != null;
- e = e.next)
4. 逐个比较,先通过hash快速比较,hash相同再通过equals比较,代码为:
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
查看是否包含某个键
containsKey的逻辑与get是类似的,节点不为null就表示存在,具体代码为:
- public boolean containsKey(Object key) {
- return getEntry(key) != null;
- }
查看是否包含某个值
HashMap可以方便高效的按照键进行操作,但如果要根据值进行操作,则需要遍历,containsValue方法的代码为:
- public boolean containsValue(Object value) {
- if (value == null)
- return containsNullValue();
- Entry[] tab = table;
- for (int i = 0; i < tab.length ; i++)
- for (Entry e = tab[i] ; e != null ; e = e.next)
- if (value.equals(e.value))
- return true;
- return false;
- }
如果要查找的值为null,则调用containsNullValue单独处理,我们看不为null的情况,遍历的逻辑也很简单,就是从table的第一个链表开始,从上到下,从左到右逐个节点进行访问,通过equals方法比较值,直到找到为止。
根据键删除键值对
代码为:
- public V remove(Object key) {
- Entry<K,V> e = removeEntryForKey(key);
- return (e == null ? null : e.value);
- }
removeEntryForKey的代码为:
- final Entry<K,V> removeEntryForKey(Object key) {
- if (size == 0) {
- return null;
- }
- int hash = (key == null) ? 0 : hash(key);
- int i = indexFor(hash, table.length);
- Entry<K,V> prev = table[i];
- Entry<K,V> e = prev;
- while (e != null) {
- Entry<K,V> next = e.next;
- Object k;
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k)))) {
- modCount++;
- size--;
- if (prev == e)
- table[i] = next;
- else
- prev.next = next;
- e.recordRemoval(this);
- return e;
- }
- prev = e;
- e = next;
- }
- return e;
- }
基本逻辑为:
1. 计算hash,根据hash找到对应的table索引,代码为:
- int hash = (key == null) ? 0 : hash(key);
- int i = indexFor(hash, table.length);
2. 遍历table[i],查找待删节点,使用变量prev指向前一个节点,next指向下一个节点,e指向当前节点,遍历结构代码为:
- Entry<K,V> prev = table[i];
- Entry<K,V> e = prev;
- while (e != null) {
- Entry<K,V> next = e.next;
- if(找到了){
- //删除
- return;
- }
- prev = e;
- e = next;
- }
3. 判断是否找到,依然是先比较hash,hash相同时再用equals方法比较
4. 删除的逻辑就是让长度减小,然后让待删节点的前后节点连起来,如果待删节点是第一个节点,则让table[i]直接指向后一个节点,代码为:
- size--;
- if (prev == e)
- table[i] = next;
- else
- prev.next = next;
e.recordRemoval(this);在HashMap中代码为空,主要是为了HashMap的子类扩展使用。
实现原理小结
以上就是HashMap的基本实现原理,内部有一个数组table,每个元素table[i]指向一个单向链表,根据键存取值,用键算出hash,取模得到数组中的索引位置buketIndex,然后操作table[buketIndex]指向的单向链表。
存取的时候依据键的hash值,只在对应的链表中操作,不会访问别的链表,在对应链表操作时也是先比较hash值,相同的话才用equals方法比较,这就要求,相同的对象其hashCode()返回值必须相同,如果键是自定义的类,就特别需要注意这一点。这也是hashCode和equals方法的一个关键约束,这个约束我们在介绍包装类的时候也提到过。
HashMap特点分析
HashMap实现了Map接口,内部使用数组链表和哈希的方式进行实现,这决定了它有如下特点:
- 根据键保存和获取值的效率都很高,为O(1),每个单向链表往往只有一个或少数几个节点,根据hash值就可以直接快速定位。
- HashMap中的键值对没有顺序,因为hash值是随机的。
如果经常需要根据键存取值,而且不要求顺序,那HashMap就是理想的选择。
小结
本节介绍了HashMap的用法和实现原理,它实现了Map接口,可以方便的按照键存取值,它的实现利用了哈希,可以根据键自身直接定位,存取效率很高。
根据哈希值存取对象、比较对象是计算机程序中一种重要的思维方式,它使得存取对象主要依赖于自身哈希值,而不是与其他对象进行比较,存取效率也就与集合大小无关,高达O(1),即使进行比较,也利用哈希值提高比较性能。
不过HashMap没有顺序,如果要保持添加的顺序,可以使用HashMap的一个子类LinkedHashMap,后续我们再介绍。Map还有一个重要的实现类TreeMap,它可以排序,我们也留待后续章节介绍。
本节提到了Set接口,下节,让我们探讨它的一种重要实现类HashSet。
----------------
未完待续,查看最新文章,敬请关注微信公众号“老马说编程”(扫描下方二维码),从入门到高级,深入浅出,老马和你一起探索Java编程及计算机技术的本质。用心原创,保留所有版权。

计算机程序的思维逻辑 (40) - 剖析HashMap的更多相关文章
- 计算机程序的思维逻辑 (29) - 剖析String
上节介绍了单个字符的封装类Character,本节介绍字符串类.字符串操作大概是计算机程序中最常见的操作了,Java中表示字符串的类是String,本节就来详细介绍String. 字符串的基本使用是比 ...
- 计算机程序的思维逻辑 (48) - 剖析ArrayDeque
前面我们介绍了队列Queue的两个实现类LinkedList和PriorityQueue,LinkedList还实现了双端队列接口Deque,Java容器类中还有一个双端队列的实现类ArrayDequ ...
- 计算机程序的思维逻辑 (51) - 剖析EnumSet
上节介绍了EnumMap,本节介绍同样针对枚举类型的Set接口的实现类EnumSet.与EnumMap类似,之所以会有一个专门的针对枚举类型的实现类,主要是因为它可以非常高效的实现Set接口. 之前介 ...
- 计算机程序的思维逻辑 (30) - 剖析StringBuilder
上节介绍了String,提到如果字符串修改操作比较频繁,应该采用StringBuilder和StringBuffer类,这两个类的方法基本是完全一样的,它们的实现代码也几乎一样,唯一的不同就在于,St ...
- 计算机程序的思维逻辑 (31) - 剖析Arrays
数组是存储多个同类型元素的基本数据结构,数组中的元素在内存连续存放,可以通过数组下标直接定位任意元素,相比我们在后续章节介绍的其他容器,效率非常高. 数组操作是计算机程序中的常见基本操作,Java中有 ...
- 计算机程序的思维逻辑 (43) - 剖析TreeMap
40节介绍了HashMap,我们提到,HashMap有一个重要局限,键值对之间没有特定的顺序,我们还提到,Map接口有另一个重要的实现类TreeMap,在TreeMap中,键值对之间按键有序,Tree ...
- 计算机程序的思维逻辑 (53) - 剖析Collections - 算法
之前几节介绍了各种具体容器类和抽象容器类,上节我们提到,Java中有一个类Collections,提供了很多针对容器接口的通用功能,这些功能都是以静态方法的方式提供的. 都有哪些功能呢?大概可以分为两 ...
- Java编程的逻辑 (40) - 剖析HashMap
本系列文章经补充和完善,已修订整理成书<Java编程的逻辑>,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http:/ ...
- 计算机程序的思维逻辑 (38) - 剖析ArrayList
从本节开始,我们探讨Java中的容器类,所谓容器,顾名思义就是容纳其他数据的,计算机课程中有一门课叫数据结构,可以粗略对应于Java中的容器类,我们不会介绍所有数据结构的内容,但会介绍Java中的主要 ...
随机推荐
- Git Bash的一些命令和配置
查看git版本号: git --version 如果是第一次使用Git,你需要设置署名和邮箱: $ git config --global user.name "用户名" $ gi ...
- Nhibernate的Session管理
参考:http://www.cnblogs.com/renrenqq/archive/2006/08/04/467688.html 但这个方法还不能解决Session缓存问题,由于创建Session需 ...
- SQL Server-聚焦NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL性能分析(十八)
前言 本节我们来综合比较NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL的性能,简短的内容,深入的理解,Always to review the basics. ...
- [.NET] 利用 async & await 的异步编程
利用 async & await 的异步编程 [博主]反骨仔 [出处]http://www.cnblogs.com/liqingwen/p/5922573.html 目录 异步编程的简介 异 ...
- UWP开发之Mvvmlight实践九:基于MVVM的项目架构分享
在前几章介绍了不少MVVM以及Mvvmlight实例,那实际企业开发中将以那种架构开发比较好?怎样分层开发才能节省成本? 本文特别分享实际企业项目开发中使用过的项目架构,欢迎参照使用!有不好的地方欢迎 ...
- Oracle 数据库语句大全
Oracle数据库语句大全 ORACLE支持五种类型的完整性约束 NOT NULL (非空)--防止NULL值进入指定的列,在单列基础上定义,默认情况下,ORACLE允许在任何列中有NULL值. CH ...
- [内核笔记1]内核文件结构与缓存——inode和对应描述
由来:公司内部外网记录日志的方式现在都是通过Nginx模块收到数据发送到系统消息队列,然后由另外一个进程来从消息队列读取然后写回磁盘这样的操作,尽量的减少Nginx的阻塞. 但是由于System/V消 ...
- ASP.NET MVC学习之母版页和自定义控件的使用
一.母板页_Layout.cshtml类似于传统WebForm中的.master文件,起到页面整体框架重用的目地1.母板页代码预览 <!DOCTYPE html> <html> ...
- Function.prototype.toString 的使用技巧
Function.prototype.toString这个原型方法可以帮助你获得函数的源代码, 比如: function hello ( msg ){ console.log("hello& ...
- 开源发布:VS代码段快捷方式及可视化调试快速部署工具
前言: 很久前,我发过两篇文章,分别介绍自定义代码版和可视化调试: 1:Visual Studio 小技巧:自定义代码片断 2:自定义可视化调试工具(Microsoft.VisualStudio.De ...