Kafka学习(一)
链接:https://www.zhihu.com/question/53331259/answer/1321992772
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的、多副本的,基于zookeeper协调的分布式消息系统。
它最大的特性就是可以实时处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志、消息服务等等。
Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
01 kafka的定义和特征
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要用来解决应用解耦、异步消息、流量削峰等问题。
3个特点:
- 类似消息系统,提供事件流的发布和订阅,即具备数据注入功能
- 存储事件流数据的节点具有故障容错的特点,即具备数据存储功能
- 能够对实时的事件流进行流式地处理和分析,即具备流处理功能
02 Kafka的架构
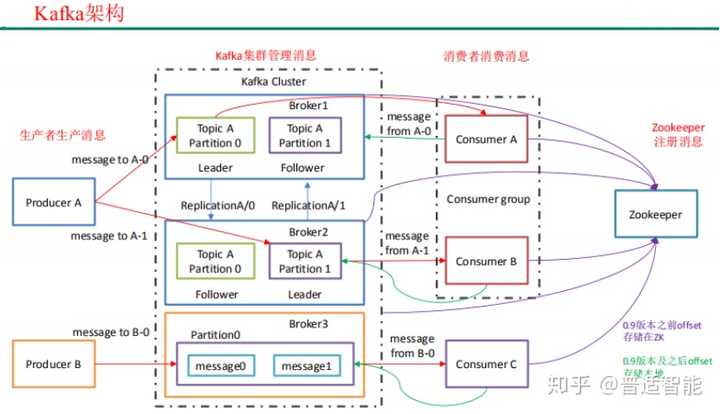
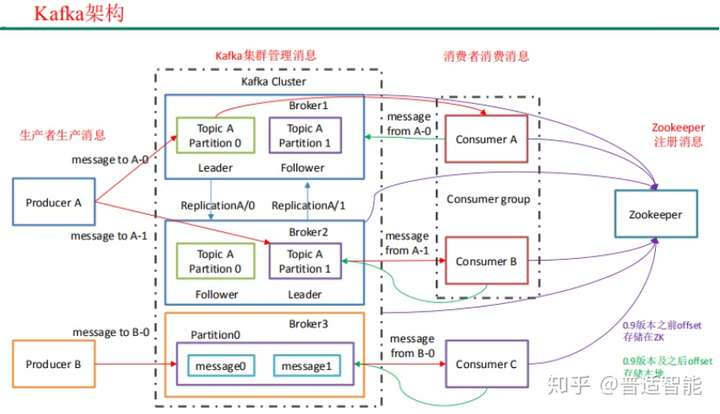
- Producer:消息生产者,就是向 kafka broker 发消息的客户端
- Consumer:消息消费者,就是向 kafka broker 取消息的客户端
- Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broke 组成。一个 broker 可以容纳多个 topic
- Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响
- Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务 器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据 不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower
- leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数 据的对象都是 leader
- follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader数据 的同步。leader 发生故障时,某个 follower 会成为新的 follower
03 生产者
(1) 数据可靠性保证
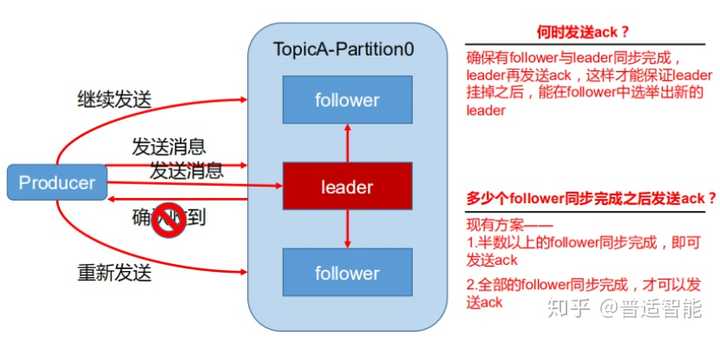
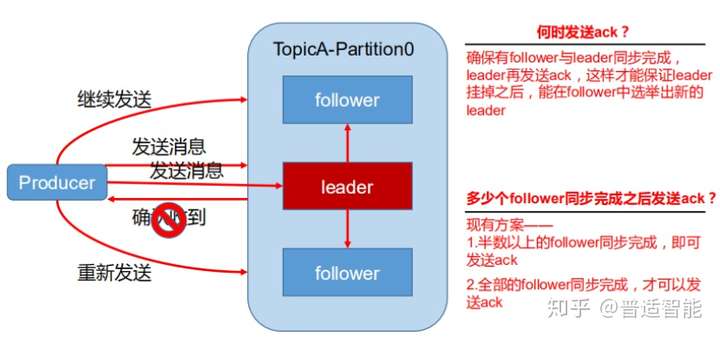
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic的每个 partition收到 producer发送的数据后,都需要向 producer发送ack(acknowledgement确认收到),如果 producer收到 ack,就会进行下一轮的发送,否则重新发送数据。
(2) Ack应答机制
- Ack=0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据
- Ack=1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower 同步成功之前 leader 故障,那么将会丢失数据
- Ack=-1:producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落 盘成功后才 返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复
(3) 故障处理
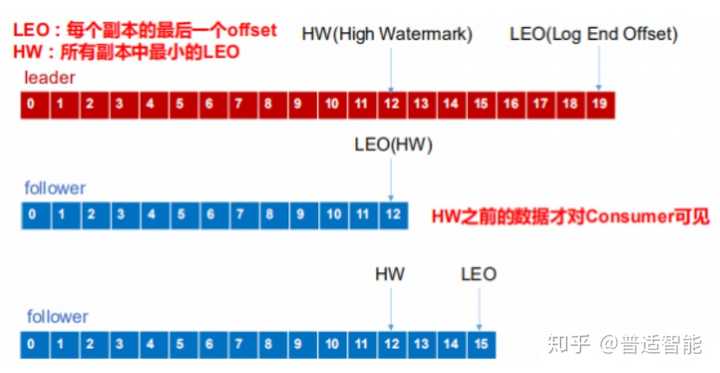
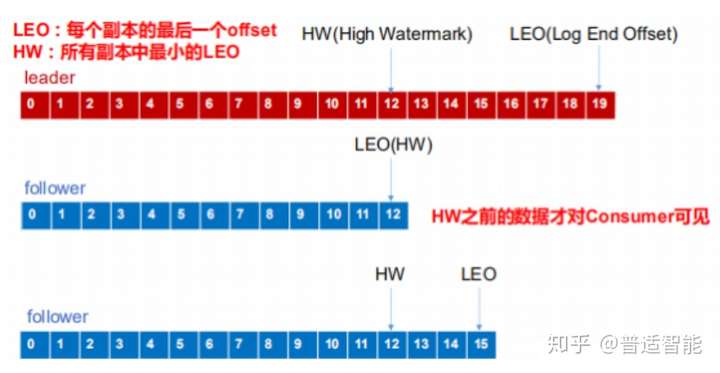
- follower 故障
follower发生故障后会被临时踢出ISR,待该follower 恢复后,follower会读取本地磁盘 记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。
等该follower的LEO大于等于该Partition的HW,即 follower 追上 leader 之后,就可以重新加入ISR 了。
- leader 故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
04 消费者
(1) 消费方式
consumer 采用 pull(拉) 模式从 broker 中读取数据。push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。
它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。
而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。
针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer 会等待一段时间之后再返回,这段时长即为 timeout。(2) Offset的维护
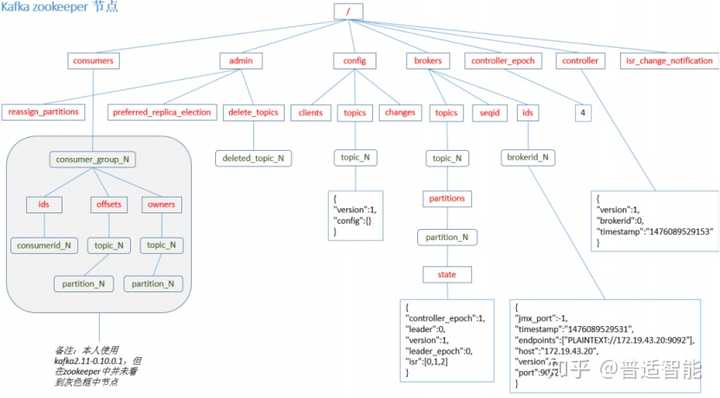
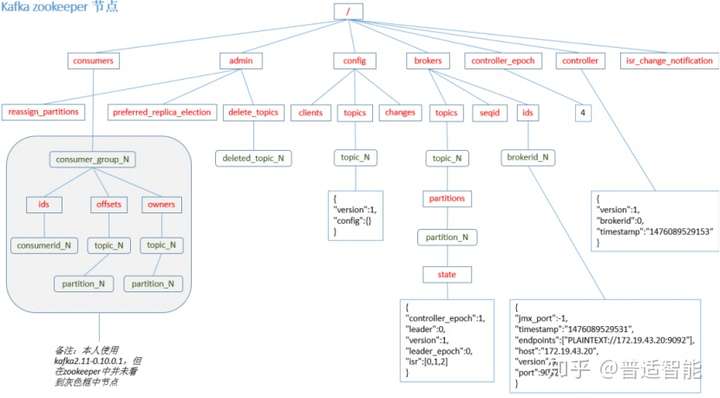
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。
总结:
Kafka是一个分布式、支持分区的、多副本的,基于zookeeper协调的分布式消息系统,是当前大数据解决方案的标配,广泛用于大数据框架间的数据发布和订阅,所以深入理解Kafka内部机制就非常必要。 - 完 -
Kafka学习(一)的更多相关文章
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- Kafka学习-简介
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.S ...
- Kafka学习-入门
在上一篇kafka简介的基础之上,本篇主要介绍如何快速的运行kafka. 在进行如下配置前,首先要启动Zookeeper. 配置单机kafka 1.进入kafka解压目录 2.启动kafka bin\ ...
- Kafka学习之路
一直在思考写一些什么东西作为2017年开篇博客.突然看到一篇<Kafka学习之路>的博文,觉得十分应景,于是决定搬来这“他山之石”.虽然对于Kafka博客我一向坚持原创,不过这篇来自Con ...
- kafka学习2:kafka集群安装与配置
在前一篇:kafka学习1:kafka安装 中,我们安装了单机版的Kafka,而在实际应用中,不可能是单机版的应用,必定是以集群的方式出现.本篇介绍Kafka集群的安装过程: 一.准备工作 1.开通Z ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- kafka 学习资料
kafka 学习资料 kafka 学习资料 网址 kafka 中文教程 http://orchome.com/kafka/index
- 【译】Kafka学习之路
一直在思考写一些什么东西作为2017年开篇博客.突然看到一篇<Kafka学习之路>的博文,觉得十分应景,于是决定搬来这“他山之石”.虽然对于Kafka博客我一向坚持原创,不过这篇来自Con ...
- Kafka学习之(六)搭建kafka集群
想要搭建kafka集群,必须具备zookeeper集群,关于zookeeper集群的搭建,在Kafka学习之(五)搭建kafka集群之Zookeeper集群搭建博客有说明.需要具备两台以上装有zook ...
- Kafka学习总结
Kafka学习总结 参考资料: 1.http://kafka.apachecn.org/, kafka官方文档 2.https://www.cnblogs.com/likehua/p/3999538. ...
随机推荐
- MySQL架构原理之运行机制
所谓运行机制即MySQL内部就如生产车间如何进行生产的.如下图: 1.建立连接,通过客户端/服务器通信协议与MySQL建立连接.MySQL客户端与服务端的通信方式是"半双工".对于 ...
- 攻防世界Web_python_template_injection
题目: 就一句话啥也没有.python 模板注入.刚学菜鸡还不知道python模板有哪些注入漏洞,上网查一下.又学到一个知识点. python常用的web 模板有 Django,Jinja2,Torn ...
- [自动化]基于kolla部署的openstack自动化巡检生成xlsx报告
自动化巡检介绍 此巡检项目在kolla-ansible部署的openstack环境上开发,利用ansible-playbook编排的功能,对巡检的任务进行编排和数据处理.主要巡检的对象有IaaS平台和 ...
- Dell服务器通过IDRAC9收集TSR日志排查故障
登陆IDRAC9 WEB管理界面,在菜单栏< 维护>下选择 在联网的情况下推荐完成SupportAssist的注册,根据提示安装ISM并进行信息登记.如暂不注册,则点击取消继续. 进入S ...
- 彻底关闭 win10家庭版 杀毒软件windows defender
下面开始今天的教程, 第一步,我们先在windows安全中心将相关的设置关闭一下,具体方法如下: 我们右键点击windows 10开始菜单,点击"设置", 点击"设置&q ...
- kafka 事务代码实现(生产者到server端的事务)
kafka的事务指的是2个点 ① 生产者到kafka服务端的事务保障 ②消费者从kafka拉取数据的事务 kafka提供的事务机制是 第①点, 对于第②点来说 只能自己在消费端实现幂等性. ...
- Qt:使用SqlQuery进行查询时size总是-1
原因:SQL语句没有符合格式,特别是在换行写一个SQL语句时,不同行之间没有写空格
- httpHelper 从URL获取值
/// <summary> /// 从URL获取值(字符串) /// </summary> public static string GetValueFromUrl(strin ...
- 超简单的集成表达式树查询组件,Sy.ExpressionBuilder 使用说明
Sy.ExpressionBuilder是一套依赖于表达式树上的集成的查询组件.设计的初衷没别的,就为了少写代码,让查询业务可以变得更加模式化.目前可以从nuget 获取到该组件. 来到查询,查询实体 ...
- mysql什么时候会发生file sort
看了网上很多排名很靠前的博客,发现好多都讲错了!我开始按照博客来,没有怀疑,直到自己试了一下才发现是错的. file sort在面试中有时候会问到,这个其实挺能区分是不是真的了解order by的执行 ...